What is Apache Kafka®?
Have you ever been confused by all this talk about kafkas and streaming? Get the basics in this article full of information and resources.
Apache Kafka®: the basics
Definition and uses
Apache Kafka® is often described as an event streaming platform (if you don't know what that is, this may help). And this is true, but at its core it’s simpler: Apache Kafka is really just a way to move data from one place to another. That's what makes it the swiss army knife of data infrastructure.
You can use it to move data between your own applications, between your applications and data stores (like PostgreSQL or Amazon S3), or between those data stores. Apache Kafka makes applications independent from each other, so that one application can pass data on without needing to wait for the other application to deal with the situation.
The easiest way to try Apache Kafka is to sign up for a managed service and give it a spin. Sign up for Aiven today and start a free trial to test it out!
Apache Kafka is glue for your application
When we describe Apache Kafka as an event streaming platform, what we mean is that it acts as a bridge or as glue between different aspects of your application. Kafka lets you set up some services in your application as producers, and others as subscribers. Producers send messages and subscribers receive them. Apache Kafka manages the relationships between these services and ensures that messages arrive in a specific order.
As a widely-used open source project, Apache Kafka also has many client and tooling options. Whether it's high-level APIs and libraries help you build your own applications, or off-the-shelf "glue" between data stores, or helpful management interfaces to show you what's happening inside Apache Kafka, there will be something already available in the ecosystem.
In some ways, Apache Kafka is rather like a cross between a messaging system and a database. It shares features with both, but it's more than a message queue and different from a database. The fact that almost any system can act as a producer or consumer means that Apache Kafka's core use is as a conduit for systems to talk to each other and share data. There's no need for a complex network of connectors and pipelines between systems - they are decoupled and independent of each other. This has profound implications not just for the speed and reliability of data delivery but also for the breadth of use cases that Kafka can be put to.
Benefits of Apache Kafka in an event driven architecture
One of the key things that Apache Kafka enables is the building of applications that use event driven architecture. Event driven architectures are applications where when something happens in one area of the system, it emits an event which triggers actions in another part of the system.
We've talked about the benefits of an event driven architecture with Apache Kafka on the Aiven Blog, but let's quickly run through why you'd want to use Apache Kafka for your event based data architecture.
Speed through structure
Once upon a time, you had to choose between a fast messaging platform or a durable one. This is because "fast" was often implemented as "messages are only in memory", and the thought of writing messages onto disk was derided as being too slow. Apache Kafka changed all of that by re-thinking how storage is used. When messages are arranged into topics and topics into append-only partitions, it’s possible to have a messaging platform that’s both fast and durable.
...and compression
Another contributor to Kafka’s fast throughput is that Kafka itself doesn't care about the structure of the data - as far as it is concerned, data is just a series of bytes. The producers and consumers however should agree on the structure of the data, or otherwise they won't understand it. This is often handled by a separate component called a schema registry (for example, Karapace) where the producers (or even the system architects) can store the structure of a message, and the consumers can read the structure and have an expectation of which fields etc will be in the messages on a given topic. Where possible this also compresses the messages - the field names don't need to be sent with each message if they are already in a schema registry, which the consumer can query to "re-hydrate" the full message.
As a result, Kafka's scalable, fault-tolerant, publish-subscribe messaging platform is nearly ubiquitous across vast internet properties like Spotify, LinkedIn, Square, and Twitter.
Quickly in, quickly out
Kafka also has a fast throughput because it decouples writing data from reading it. Data doesn't have to be received at its final destination(s), it only has to be written to the broker by the producer. Similarly, consumers read data as and when it suits them, not acting as a roadblock to the producers.
Future-proofing with scalability
Kafka’s scalability offers tangible business benefits. Its partitioned log model allows data to be distributed across multiple brokers, allowing immense amounts of data to reside in the same platform but on different servers. It’s also trivial to make Kafka geographically resilient using MirrorMaker 2, which will replicate the data between two different clusters (potentially in different regions or even different clouds) - resistant to interruption and without any data loss.
Safety through copies
Because Kafka replicates data across servers, data centers and clouds, with the correct configuration the data is safe even if a server or region fails. With replication configured per-topic, Kafka keeps track of which servers are the "owners" of the data and which servers have replica copies to use in the event of failure. While manually restoring the data in Kafka after an issue might not be a meaningful concept, care must be taken to ensure that settings like the "replication factor" are correct for your requirements. You can read more in data and disaster recovery.
How does Kafka work?
Kafka works around the concept of messages. When used in an event-driven world, Kafka sees each event as a different message. In this case, an event always happens at a certain time (timestamp), concerns a specific thing (key), and states what happened regarding that thing (value). It may also contain additional information (metadata headers).
For example:
- On 2 February 2022 at 16:37 (timestamp) a pulled-oat sandwich (key) was purchased (value) at Tania’s Deli (metadata).
- On 3 February 2022 (timestamp) ten (value) pulled-oat sandwiches (key) were delivered at Tania’s Deli (metadata).
Pub/sub
Events are written, or published, to Kafka by client applications called producers. Other applications, called consumers, read events from Kafka, often as input that triggers another action.
This is called a publish-subscribe model, or pub/sub - the producers are not aware of, or care at all about, the consumers which are reading the events.
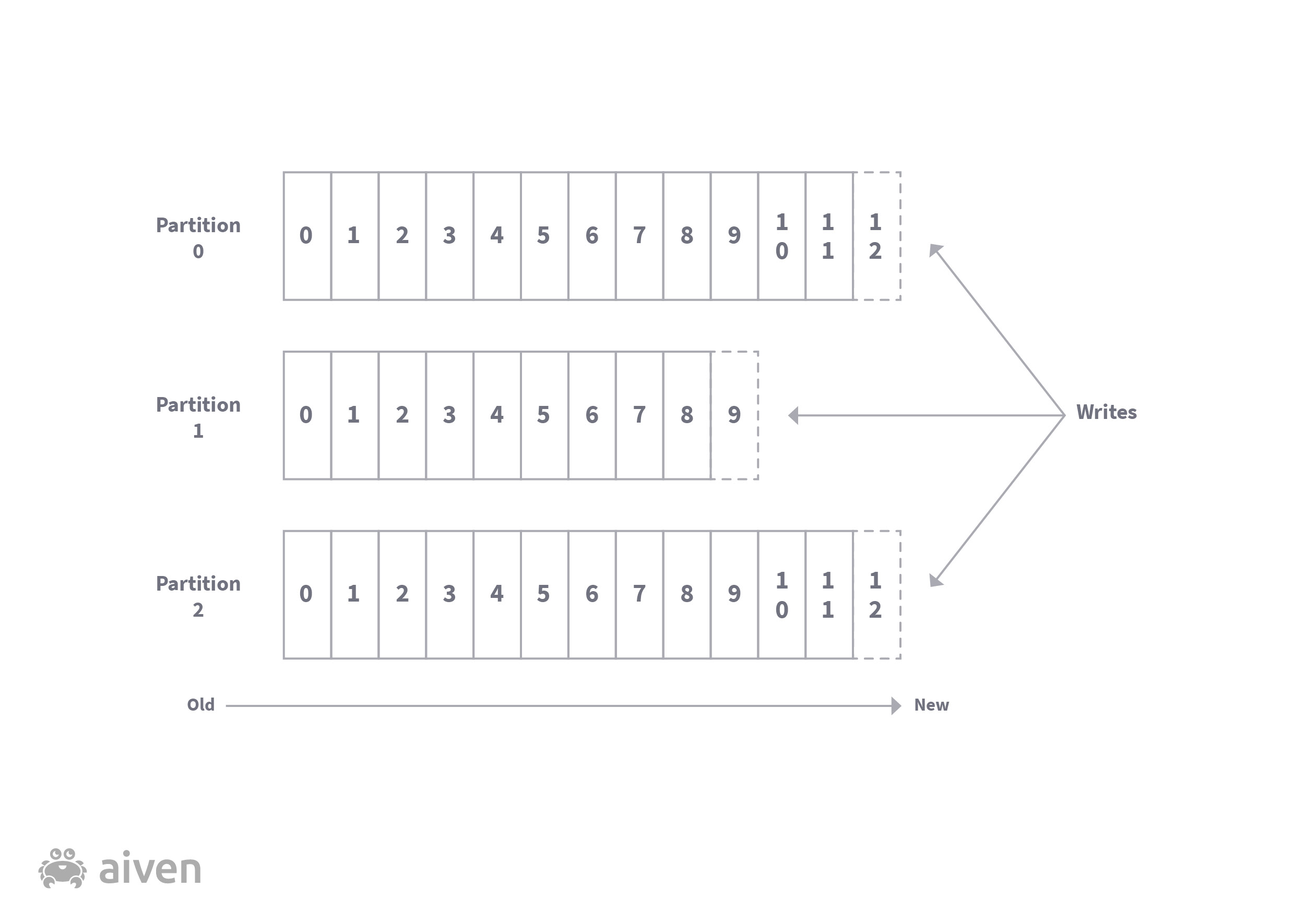
Kafka organizes streams of events into a number of topics, which are basically category-named data feeds, and are usually themselves split into partitions for scaling. Producers write event records by appending them to the sequence of events in a given topic, resulting in an ordered series (remember that ordering is only preserved within a partition, not across partitions).
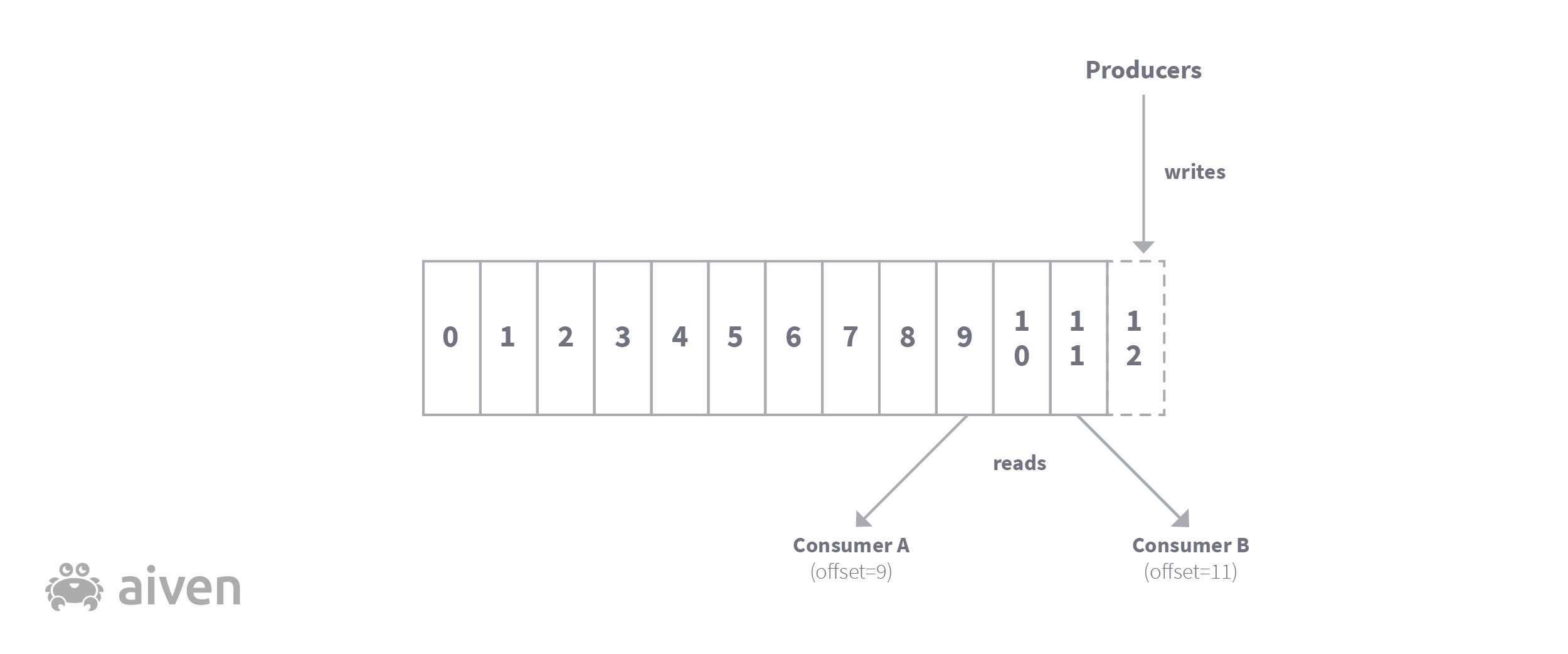
Consuming from topics - the importance of offsets
Consumers consume records from specific topics, starting from a given offset (the record number in the topic). This makes it easy to consume the records asynchronously while still retaining the correct order. The last-known offset for a given consumer (or group of consumers) is usually also stored in Apache Kafka, so that when a consumer re-attaches after some kind of interruption it can seamlessly pick up from where it left off.
What is event streaming?
So if Kafka is an event streaming platform, what is event streaming? Event streaming is services publishing events in a continuous stream for other systems to read and process elsewhere. Importantly, events happen in order, and the producer of the events does not care about who or what is reading the events. It’s a great way to decouple different applications from each other, so that any given application can just focus on what it does best.
What is event streaming used for?
Event streaming is used to separate applications which are actively doing a task (e.g. reading from a sensor or charging a credit card) from applications which are observing and acting-on the results of that task (e.g. switching the air-con off or shipping a package) - it’s a stream of data about things which have happened and often need to be processed further. Here are some common uses:
- Monitoring infrastructure and detecting anomalies - keeping up to date with your own systems. (See how Aiven does it!)
- Triggering related business processes - for example, when someone registers a new account, trigger a background fraud detector
- Metrics with real-time counters, moving averages and more - applications in e.g. fintech and climate applications
- Creating dashboards - anywhere that humans want to run an eye over the numbers, like traffic monitoring and leaderboards.
- Moving data from the incoming event stream to longer-term storage for offline analytics and queries.
- Enabling an event-driven architecture (EDA)
Use cases with event driven architecture
Event driven architecture is frequently used for applications where lots of data comes in very quickly. Social media, online shopping and IoT applications are great examples, but depending on scale it might also include things like inventory management.
Take a look at our page for case studies featuring a Kafka-centric architecture.
Apache Kafka in your architecture
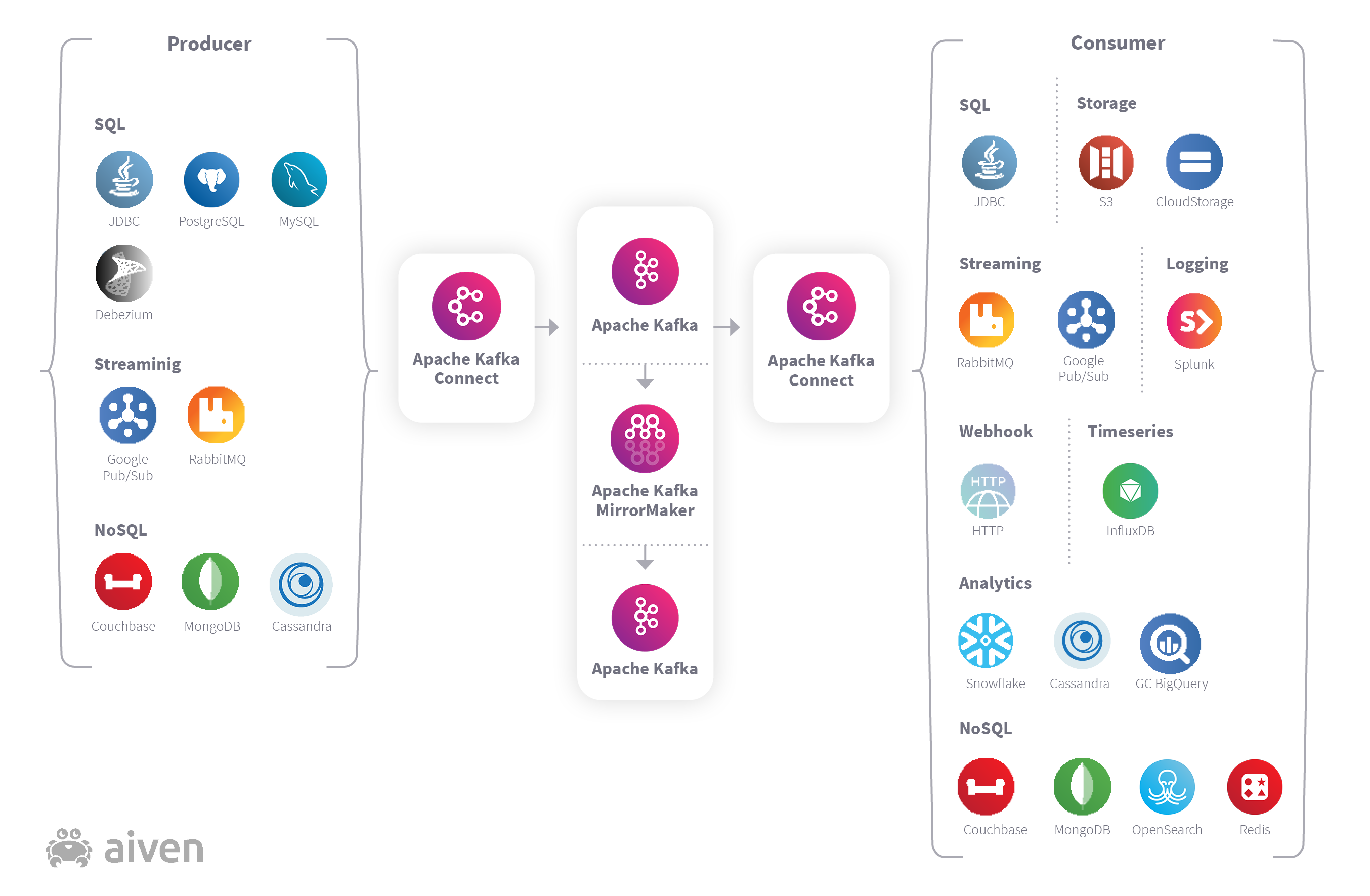
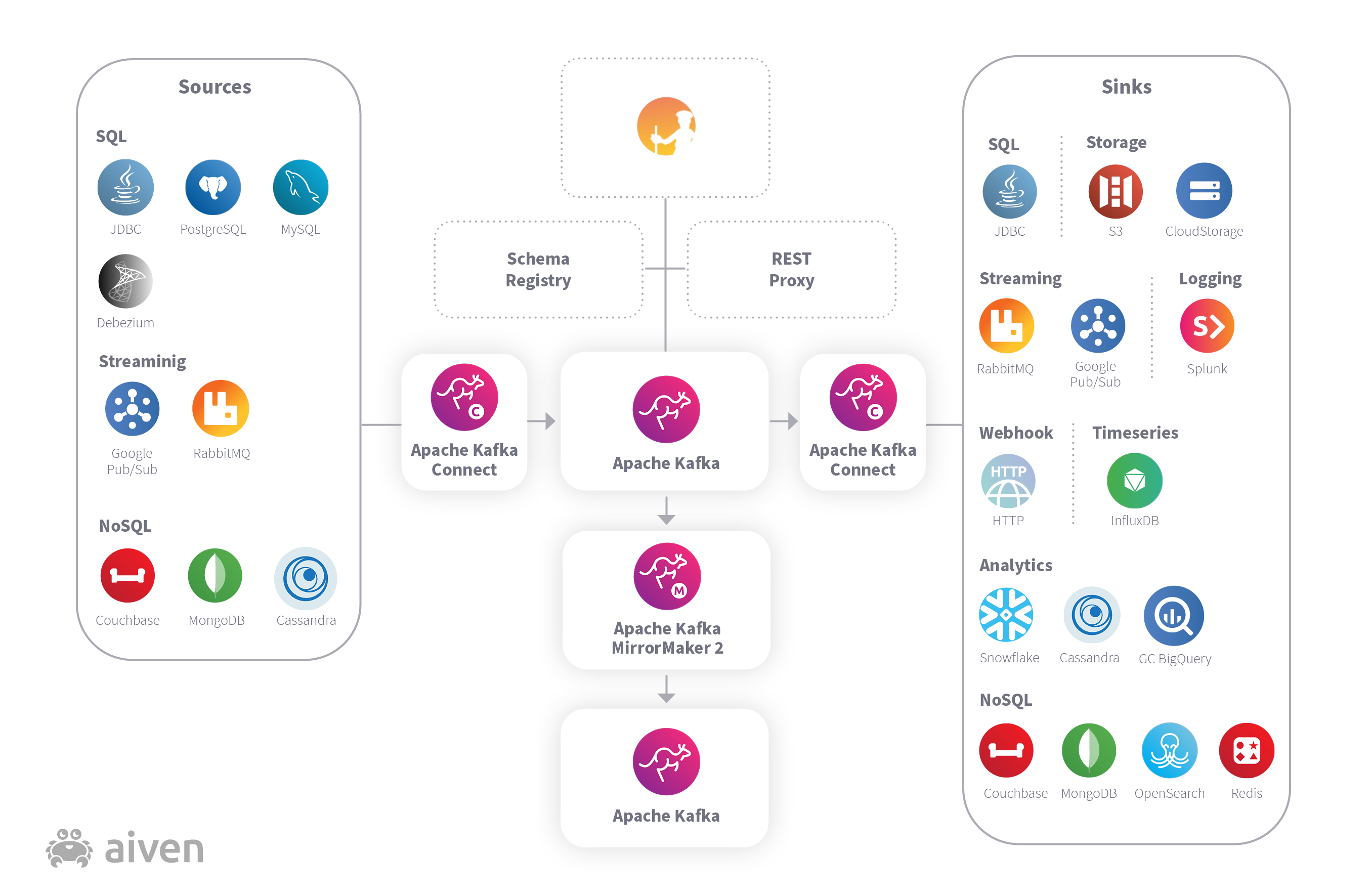
Where does Apache Kafka fit in? In brief, it goes in the middle of all your systems. There are multiple open source options for producers and consumers, many of them with existing connectors to Kafka. Remember that Kafka itself isn’t performing any application logic, it is simply an ordered store of messages - it has no knowledge of what is contained within the messages although it does allow producers to separate metadata about the messages into message headers.
Typically, Apache Kafka acts as a kind of pipeline, streaming data from one place to another (or many others). Consumers can choose whether to start from the latest message in a topic (and only get the new messages after that), or to start from the beginning of the topic (and get as many messages as are still on the topic), or somewhere in between. Kafka tracks the position of a message on a topic, called the “offset”, adding new messages to the end. Consumers track the offset that they last saw (or that they want next), although that detail is often hidden inside of libraries used by the clients.
Apache Kafka APIs: connecting to Kafka
Utterly unsurprisingly, Kafka interfaces with other systems via APIs. Kafka’s Java client offers five core APIs:
- The Admin API for inspecting and managing Kafka objects like topics and brokers.
- The Producer API for writing (publishing) to topics.
- The Consumer API for reading (subscribing to) topics.
- The Kafka Streams API to provide access for applications and microservices to higher-level stream processing functions.
- The Kafka Connect API for creating import and export connectors to external systems and applications.
Which API you use to connect to Apache Kafka and how exactly you do it depends on things like which technologies you are using, what type of activity you want to do (produce message, consume messages, manage the Kafka brokers, etc), how “high-level” you want the connection to be (do you want your code to specify all of the individual details about messages / partitions / headers / etc, do you want your consumer to keep track of its latest offsets, do you want to describe how a stream should be processed and let the library setup the message flows, do you want to avoid writing any code at all and just use Kafka to join together other datastores?).
Some producers and consumers
Low-level libraries
For full control over the data flowing onto and off a Kafka topic, there are client libraries available for many different programming languages. The Apache Kafka project itself maintains the Java APIs, but commonly-used libraries in other languages include:
- Sarama for Go
- Kafka-go for Go
- Kafka-python for Python
- Librdkafka for C/C++ (and wrappers for Go, Python, etc)
These consumers allow you to do things like target particular partitions for a message, send arbitrary bytes for the message body, and use any data structure for the key. Note that most of these will need to be carefully synchronized between the producers and the consumers, otherwise the consumers will likely misunderstand the message (e.g. it might be on an unexpected partition or not conform to the expected structure).
Higher-level client libraries
Getting slightly higher, these libraries also allow some more standard options to be used. For example, automatically selecting the partition based on a hash of the message key, or using a schema registry to make sure that the message structure conforms to expectations.
For consumers, a big concern is keeping track of whereabouts in the stream of messages a consumer has processed up to. Low-level consumers might store their own offset somewhere (for example in ZooKeeper or KRaft), but it’s more normal to let Kafka manage that for you so an application can happily restart and pick up where it left off. By default, Kafka uses a dedicated topic called consumer_offsets for this.
Even higher-level client libraries
Getting even higher-level, a common need is to coordinate many different instances of an application, so that each message is only handled once even though there could be many different servers running an application. To help coordinate which applications are consuming from which topics, what offset they are all up to, and to spread load around in case of application failure, Kafka lets you model a group of consumers as a single entity.
When an application connects to Kafka and requests to consume from a given topic, it can declare itself as a member of a particular consumer group --or link to consumer groups section--, and it will be given messages from the correct offset in a subset of partitions depending on how many other applications are also in that consumer group.
Really high level clients
Instead of dealing with every individual detail of each message, you can opt for higher-level clients that simplify the whole message process.
Stream processing
Kafka Streams is a Java library which allows you to model how you want to deal with a stream of messages in your application. It lets you create a fluent pipeline in your code, defining a stream of transformations (e.g. “extract these fields from the message”, “combine the message with a lookup from a DB table”, “if this field contains a number bigger than 10, then publish the message onto a different stream and raise an alert”), and then the Kafka Streams library figures out what needs to be wired together to deploy the overall process.
Apache Kafka Connect®
If you don’t want to write any code at all, or maybe just write some “glue” code to extract data from some other datastore, you can use Apache Kafka Connect to create a single source pipeline into Kafka and a single sink pipeline out of it. It is important to note that Kafka Connect is nothing special from Kafka’s point of view, it is simply an external application which produces and consumes messages, but it is a convenient way to get data into or out of an external datastore (e.g. a PostgreSQL database).
Apache Kafka Connect is an application which hosts one or more “connectors”, which themselves fall into one of two categories: a “source” which extracts data from an external source and publishes it onto a Kafka topic, or a “sink” which consumes data from a Kafka topic and pushes it out to something external. Sometimes, these are used together in order to move data between two external datastores, using Kafka purely as a transit between the two connectors.
With Kafka Connect, you can also perform simple transformations to message fields in individual messages.
(Curious to know what Kafka Connectors Aiven provides? Here's a list of Aiven's Apache Kafka connectors in the developer docs.
Source connector examples
- Pulling data from a relational database, either as a single bulk extract or as ongoing changes. There are various implementations of this, common ones being Debezium which pretends to be a read-only replica database (e.g. using CDC) or Aiven’s JDBC source which can either repeatedly dredge a whole table at a time or follow an incrementing column like an ID or a timestamp to figure out what has been changed.
- Watching for changes in an AWS S3 bucket
- Subscribing to another message broker, e.g. the Stream Reactor MQTT connector from Lenses.io
Sink connector examples
- Writing data to a relational database
- Calling an external API
- Sending a webhook to notify clients that something has happened
- Streaming events into a data warehouse for storage and analytics
If the system you want to connect to Kafka doesn’t have a ready-made connector, you can use the
Kafka Connect API to make one.
Coordinating message schemas
Since Kafka is a tool to decouple producers and consumers, it also removes their opportunity to agree on the structure of the messages. How does the producer know that the consumers are able to understand the messages it is publishing?
There is no opportunity for the various applications to coordinate which fields they are expecting, or whether they expect a particular field to be an actual integer or a string containing an integer - a common situation experienced by anyone investigating a new API.
To solve this problem, it is common to use an external tool such as Karapace which acts as a repository for the schema of the messages being published onto a particular topic. The publisher writes its message schema into the registry, including all of the fields and what data type they are, and consumers can read the schema and align their expectations accordingly.
If the schema is not as they are expecting, then they could raise an exception and avoid consuming any messages from the topic, or they could flag that perhaps a software version upgrade is needed as the schema has evolved.
The other benefits of having a message schema
There are more benefits of having a message schema. It is necessary for schemas to evolve - rarely do we know all of the future requirements when first writing a piece of software - but the schema registry can inform (or enforce!) us whether a new schema is compatible with the previous version. For example if a new schema version is just adding fields but not removing any, then chances are good that consumers will still be able to understand the messages even if they don’t yet know how to handle the new fields.
Another benefit is that the consumer might not need to send the field names with every message. If using a serialization format which preserves the order of fields (e.g. Avro instead of JSON) then the producer can tell the registry that e.g. “the first field is a numerical ID, the second field is the username” and then it just needs to serialize the field values - the consumer already knows that the first field will never be the username.
Contrast that with a format that does not require fields to stay in order, which will still need the field name to be sent with each field. Kafka clients which can also use a schema registry will re-create the full message structure based on the data in the message and the schema from the registry, whilst being transparent to the application.
Common schema registries include the open-source Karapace and the Confluent Schema Registry.
Building microservices with Apache Kafka
Given that Apache Kafka excels at enabling applications to decouple from each other, it is commonly found at the center of a microservice architecture. This means that an application has been broken up into several smaller applications, each one focusing on its own task as part of the bigger picture but generally unaware of the other parts. Microservices using Kafka can either be consumers or producers, or often both, using Kafka to receive data or instructions, and then publishing the results back onto Kafka for other applications to use or for storing in a data warehouse.
As much as microservice architectures bring benefits in terms of simpler individual applications which can each be scaled as needed, they also add complexity to the overall picture. Now, instead of a single piece of software, there could be many different applications - easy to test individually, but the interactions between them need a solid set of integration tests. If not carefully planned, what was thought to be decoupled applications can quickly become accidentally dependent on each other, such that if one application starts to struggle or has a critical bug then the others around it fall like dominoes. Getting back control of such a situation can be complex, so effort should be invested to ensure that independence of each microservice is preserved.
Good use of Apache Kafka, however, can make this easier than it may seem. Combined with a schema registry like Karapace, the chance of unexpected messages arriving into a microservice is kept under control, and good integration tests keep the application behaviors well understood.
To read more about the challenges and opportunities of building a microservice architecture, see How are your microservices talking.
Event driven architecture with Apache Kafka: variations
Since Apache Kafka goes together with so many apps, it stands to reason that Kafka-centric architectures come in a range of flavors. Take a look at these cases, for example:
- Building a streaming SQL pipeline with Flink and Kafka
- Near real-time ELT with Kafka + Snowflake
- Optimizing data streaming pipelines
Updating legacy architecture with Apache Kafka
Kafka is actually a good option for dealing with database migration. But you can use it for more than just migration: Kafka can seamlessly join the elements of an old architecture together and allow you to expand and scale it. It also makes it easy to join new types of elements to existing ones.
Here are some things we prepared earlier...
- Updating an old app-to-database architecture for Kafka
- Streaming event data while modernising legacy architecture
- Moving from a provider of mechanical slot machines to an online hybrid gaming infrastructure
- A supply chain and inventory management system with a cloud-based, unified model of data
Managing Apache Kafka
Beyond the initial startup configuration files, there are also various activities needed to manage Apache Kafka as it is running (e.g. creating new topics, updating consumer group offsets, or triggering new elections for which broker is the leader of a partition), but it doesn’t come out of the box with a handy web interface for administration. Instead, there is Apache Kafka's Admin API, along with a Java client library and a set of command-line scripts to help call the API for a variety of management tasks.
If you have downloaded Kafka from the Apache website, look in the “bin/” directory for useful shell scripts to cover a whole variety of administration tasks.
Observability and Apache Kafka
Apache Kafka is notoriously tricky to manage at scale, due to needing various configs to be tuned to cope with the potentially massive volumes of data flowing across its topics and all of those data being written to disk. Without good insight into Kafka’s internals, knowing which dials to tune would be impossible and operators would be relying on blind luck to keep Kafka running smoothly. The Java ecosystem provides a standard interface for exposing metrics about the internals of an application, JMX, and Kafka uses JMX to expose a whole host of useful information about what is going on.
It is common practice to ingest metrics from Apache Kafka into a time-series database (for example M3) and use a visualization tool like Grafana to watch trends over time.
Kafka and data safety
Kafka doesn’t really do data backups, because the data it contains is by nature ephemeral. So if a cluster drops offline, how can you be sure that nothing gets interrupted or lost?
The answer to this is replication, and Apache Kafka has its own replication tool, MirrorMaker 2. There are many reasons to use MirrorMaker 2 but keeping your data safe is perhaps the most important. Think of MirrorMaker as analogous to a special Kafka Connect setup, where the source and the sink are each attached to different Kafka brokers. MirrorMaker is really just a consumer, pulling messages from a Kafka topic, and a producer sending those messages immediately onto another Kafka topic (usually on a different broker). Because Kafka consumers can let Kafka store their offset state, MirrorMaker offers a completely stand-alone way to shovel messages between two independent Kafka brokers. It is common to use this to create a “backup” Kafka cluster, often in a completely different location, without any impact on the “main” Kafka cluster.
Data is power
Streaming architectures like those typically involving Apache Kafka have access to an absolutely massive amount of data. It’s easy to start thinking of data as disposable at best, and as cumbersome at worst. But the truth is, data is, or can be, the most valuable asset you own.
You can slice it and dice it to examine more closely how your services are used and how they perform. Monitoring, scaling, visitor behavior, security, automation… There are so many things that your data can do.
Setting up and managing Kafka isn’t simple
Apache Kafka works incredibly well at all sizes, whether your deployment is small or huge. You should always have at least three brokers, so that if one fails there is still a majority of brokers available to handle the workload. However, this flexibility comes at a cost: it needs to be carefully tuned to work optimally at a given scale.
Even if you use a managed platform like Aiven for Apache Kafka, there are still decisions to be made from the client side:
- How will the topics be used?
- How many partitions per topic?
- How many replicas?
- What retention period to use?
- What compaction policy fits the use case?
Getting these decisions right can be critical, as some of them are not easy to change at a later date without a fair amount of upset to the clients. E.g. increasing or decreasing the number of partitions in a topic will change the key-to-partition distribution (and hence the ordering guarantees), but having too many partitions for a given broker size will have an impact on maximum throughput. Testing under production-level loads, including failure scenarios and on-the-fly operational changes, is critical to having a suitably-tuned setup.
Some words about orchestration and automation
To make the configuration, management and coordination of complex systems (like any system that includes Apache Kafka) easier, you can implement an orchestration system. Orchestration tools like Kubernetes can be set up to automatically perform multi-stage processes. This helps you to streamline and optimize workflows that need to be performed regularly and/or repeatedly. All you need is to be running in containers.
On a related but different note, Terraform allows you to define your infrastructure as code, which makes it easier to provision and manage. You specify the configuration, Terraform takes care of the dependencies and networking.
To find out more about both tools and what they do, read our Kubernetes vs Terraform blog article.
Getting started with Apache Kafka on Aiven
What’s the benefit of using a managed Kafka with the same provider’s managed DBaaS? For one thing, multi-service pipelines are easy to build and manage.
Aiven for Apache Kafka is at your service.
Have a poke around Aiven's developer documentation to take your first steps in the Kafka world, or sign up for a free trial and start playing around.
Further reading
Table of contents
- Apache Kafka®: the basics
- Definition and uses
- Apache Kafka is glue for your application
- Benefits of Apache Kafka in an event driven architecture
- Speed through structure
- ...and compression
- Quickly in, quickly out
- Future-proofing with scalability
- Safety through copies
- How does Kafka work?
- Pub/sub
- Consuming from topics - the importance of offsets
- What is event streaming?
- What is event streaming used for?
- Use cases with event driven architecture
- Apache Kafka in your architecture
- Apache Kafka APIs: connecting to Kafka
- Some producers and consumers
- Higher-level client libraries
- Even higher-level client libraries
- Really high level clients
- Coordinating message schemas
- Building microservices with Apache Kafka
- Event driven architecture with Apache Kafka: variations
- Updating legacy architecture with Apache Kafka
- Managing Apache Kafka
- Observability and Apache Kafka
- Kafka and data safety
- Data is power
- Setting up and managing Kafka isn’t simple
- Some words about orchestration and automation
- Getting started with Apache Kafka on Aiven
- Further reading