


Here’s a quick History of Apps:
- The Ancients: monolithic application architecture, providing absolutely everything from data store to user interface.
- The Enlightenment: service-oriented architecture, dividing an application into a few more or less independent chunks of separate services.
- The Modern Era: microservice architecture, further dividing services into their component parts in order to increase flexibility and resistance to failure.
If you’ve developed or updated any kind of cloud-based application in the last few years, chances are you’ve done so using a microservice architecture, rather than the more dated service-oriented architecture. So, what’s the difference?
What are microservices?
Microservices are a software development method where applications are structured as small, loosely coupled services. The services themselves are minimal atomic units which together comprise the functionality of an entire app. A microservice does one thing — only one thing — and does it well.
Microservices can be thought of as minimal units of functionality, can be deployed independently, are reusable, and communicate with each other via various network protocols like HTTP (More on that in a moment).
Today, most cloud-based applications that expose a REST API are built on microservices, (or may actually be one themselves). These architectures are called microservice architectures.
Benefits and challenges
Advantages of microservices
More granular service structure brings with it enormous upsides. The isolation between microservices means that when a single module fails, the larger application complex may not even notice it; critical components can be built in a highly-available way, and non-critical ones will not bring down the whole system.
Microservices are interdependent in a sense, but they use well-defined APIs instead of point-to-point custom connections. This brings unparallelled flexibility for scaling and updating.
Replacing individual microservices is quicker and easier than replacing big chunks of your system at once. This allows you to experiment with new technologies, and avoid getting locked into a tech stack that eventually stops meeting your needs.
During development, working with little chunks of software means that you can finally start reeling in the big benefits of Continuous Integration and Deployment.
Disadvantages of microservices
But it’s not all sweetness and light in microservice land. When something breaks, someone has to comb through the logs, and lots of microservices equals lots of logs. Lots and lots of logs.
Testing and deployment get more complicated as each microservice has to be verified as functional individually and then together. This needs orchestrated effort and proper processes. As a result, smaller companies may struggle to bring together everything needed to develop such a highly granular application.
These are all by and large people challenges. They can all be conquered by increasing available resources and coordinating properly. There is, however, one challenge that is primarily technical: the need for the microservices to communicate.
No microservice can do its job without its fellow microservices; they’re quite like people in that regard. And just like with people, communication is key. You have to do all you can to avoid latency and communication disruption, and your codebase may have to expand to accommodate the processing of requests.
Let’s next take a look at some communication patterns used in microservice implementations and how to accommodate them.
Some microservice communication patterns
In her article “Introduction to Microservices Messaging Protocols,” Sarah Roman provides an excellent breakdown of the taxonomy of communication patterns used by and between microservices:
Synchronous
Synchronous communication is when the sender of the event waits for processing and some kind of reply, and only then proceeds to other tasks. This is typically implemented as REST calls, where the sender submits a HTTP request, and then the service processes this and returns a HTTP response. Synchronous communication suggests tight coupling between services.
Asynchronous
Asynchronous communication means that a service doesn’t need to wait on another to conclude its current task. A sender doesn’t necessarily wait for a response, but either polls for results later or records a callback function or action. This is typically done over message buses like Apache Kafka and/or RabbitMQ. Asynchronous communication actually invokes loose coupling between component services, because there can be no time dependencies between sending events and a receiver acting on them.
Single Receiver
In this case, each request has one sender and one receiver. If there are multiple requests, they should be staggered, because a single receiver cannot receive and process them all at once. Again, this suggests tight coupling between sender and receiver.
Multiple Receivers
As the category indicates, there are multiple receivers processing multiple requests.
We believe that, while each of these methods (in combination) have their purpose within an MSA, the most loosely coupled arrangement of all is when microservices within a distributed application communicate with each other asynchronously, and via multiple receivers. This option implies that there are no strict dependencies between sender, time of send, protocol and receiver.
Pub-Sub
The pub-sub communication method is an elaboration on this latter method. The sender merely sends events — whenever there are events to be sent— and each receivers choose, asynchronously, which events to receive.
Apache Kafka may be one of the more recent evolutions of pub/sub. Apache Kafka works by passing messages via a publish-subscribe model, where software components called producers publish (append) events in time-order to distributed logs called topics (conceptually a category-named data feed to which records are appended).
Consumers are configured to separately subscribe from these topics by offset (the record number in the topic). This latter idea — the notion that consumers simply decide what they will consume — removes the complexity of having to configure complicated routing rules into the producer or other components of the system at the beginning of the pipe.
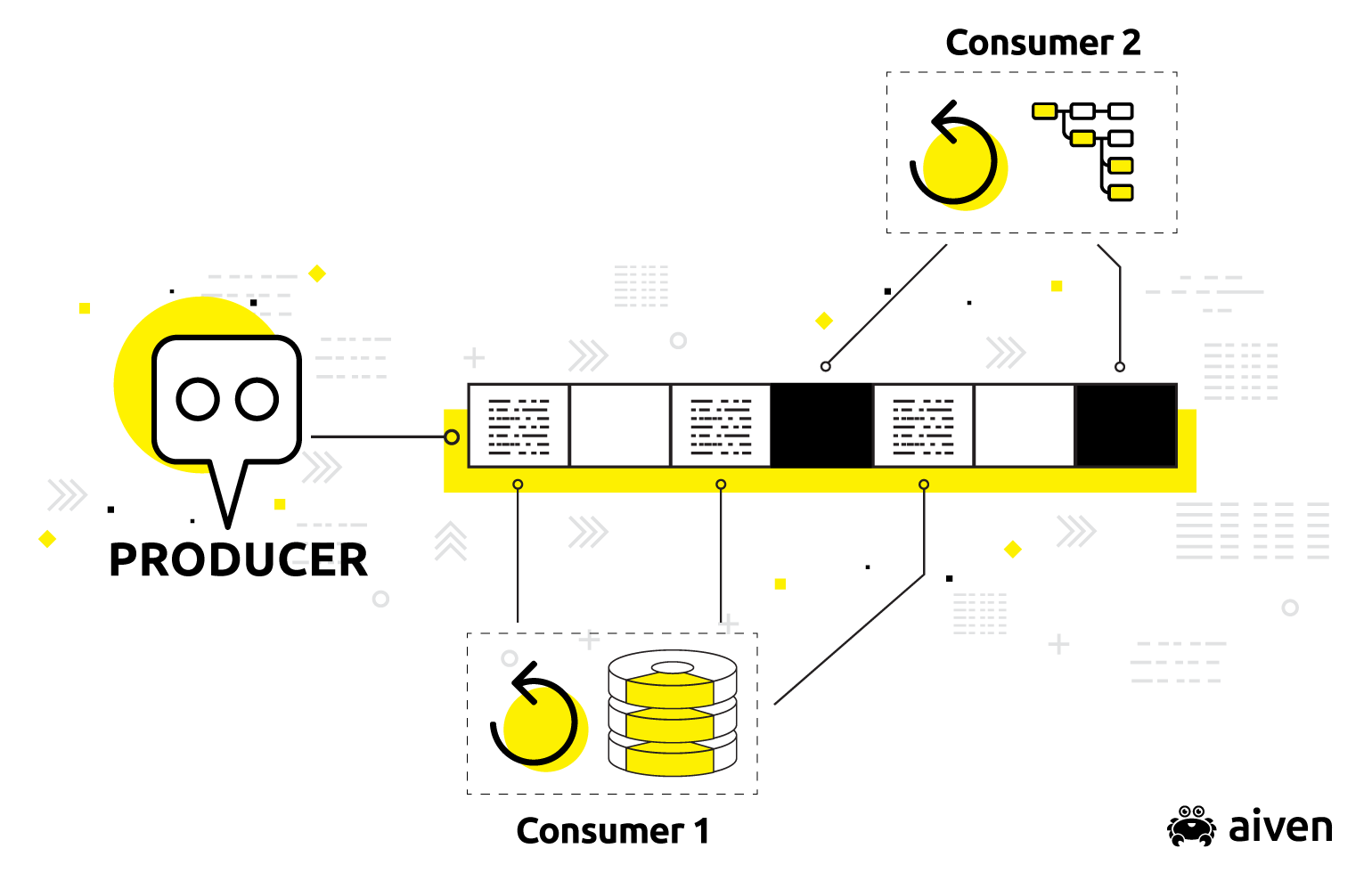
When asynchronous communication to multiple receivers is required, Apache Kafka is a promising way to go.
Why Apache Kafka?
What makes Apache Kafka a good communication solution? It solves the problem of tight-coupling between components and communication, is monitorable, and facilitates breaking up larger components into atomic, granular, independent, reusable services.
Routing rules configured by consumer
When the routing rules are configured by consumer (a feature of pub-sub and Apache Kafka generally), there is no need to build additional complexity into the data pipe itself. This decouples components from the message bus (and each other) and lets you develop and test them independently, without worrying about dependencies.
Built-in Support for asynchronous messaging
All of the above make it reasonably simple to decouple components, and focus on a specific part of the application. Asynchronous messaging, when used correctly, removes yet another point of complexity by letting your services be ready for events without being synced to them.
High throughput/low latency
It’s easier to have peace of mind about breaking up larger services into smaller, more atomic ones when you don’t have to worry about communication latency issues. Aiven's managed Kafka services have been benchmarked and feature the highest throughput and lowest latency of any hosted service in the industry.
No really - why not Apache Kafka?
Let’s face it, Apache Kafka isn’t the easiest system to set up and maintain. We’re here to just gently remind you that you don’t need to go it alone - Aiven offers a fully hosted and managed Apache Kafka, complete with add-ons and all the goodies.
Grab a copy of our ebook and learn the basic concepts of Apache Kafka first-hand!
Learn more about what makes Apache Kafka so great, and how it differs from other event streaming tools.
Download ebookManaged Apache Kafka makes your life easier
Apache Kafka can be challenging to set up. There are many options to choose from, and these vary widely depending on whether you are using an open-source version or a proprietary one, free or paid. What are your future requirements?
If you’re choosing a bundled solution, then your choice of version and installation type, for example, may come back to haunt you in the future as your business needs change.
These challenges alone may serve as a compelling argument for a managed version. With the deployment, hardware outlay costs and configuration effort out of your hands, you can focus entirely on the development for which you originally intended your Kafka deployment.
What’s more, managed is monitorable. Are you tracking throughput? You need not worry about where the integration points are in your app to instrument custom logging and monitoring; simply monitor each of your atomic services’ throughput via your provider’s Kafka backend and metrics infrastructure.
Auto-scaling
What sort of problems can you expect when your application scales? Bottlenecks? Race conditions? A refactoring mess to accomodate for them?
A managed Kafka solution can scale automatically for you when the size of your data stream grows. As such, you needn’t worry when it’s time to refactor your services atomically, and you needn’t force your teams to maintain blob-style, clustered services with complicated dependencies just for the sake of avoiding latency between them.
High availability
Apache Kafka is already known for its high availability, so you never have to worry about your services being unable to communicate because a single node supporting your middleware is down.
Kafka’s ability to handle massive amounts of data and scale automatically lets you scale your data processing capabilities as your data load grows. And a managed solution has redundancy built right in.
Centralized, no-fuss management
If you’re managing your own cluster, you can expect to be tied down with installs, updates, managing version dependencies and related issues. A managed solution like Aiven for Apache Kafka® handles all of that for you, so you can focus on your core business.
Wrapping up
Aiven for Apache Kafka® is a fully-managed, high throughput distributed messaging system with built-in monitoring which lets you decouple your services from the communication method, simplify your development and focus on your core application.
Not using Aiven services yet? Sign up now for your free trial at https://console.aiven.io/signup!
In the meantime, make sure you follow our changelog and blog RSS feeds or our LinkedIn and Twitter accounts to stay up-to-date with product and feature-related news.

Table of contents
- What are microservices?
- Benefits and challenges
- Advantages of microservices
- Disadvantages of microservices
- Some microservice communication patterns
- Synchronous
- Asynchronous
- Single Receiver
- Multiple Receivers
- Pub-Sub
- Why Apache Kafka?
- Routing rules configured by consumer
- Built-in Support for asynchronous messaging
- High throughput/low latency
- No really - why not Apache Kafka?
- Managed Apache Kafka makes your life easier
- Auto-scaling
- High availability
- Centralized, no-fuss management
- Wrapping up