


Many engineering teams rely on Aiven for PostgreSQL® to store critical data and perform advanced analytics. PostgreSQL’s reliability, consistency guarantees, and familiar SQL syntax make it a natural fit for production workloads.
But when it comes to AI and machine learning (ML) applications - like similarity search or recommendation systems - teams often move data to external vector databases. This adds complexity, latency, and maintenance overhead.
With the pgvector extension, you can now perform PostgreSQL vector search directly in your existing database. You can store and query embeddings right alongside relational data, enabling seamless similarity search with standard SQL - no new systems required.
What You Will Learn Today
- Solving the "Data Silo" Problem: How to eliminate complex ETL pipelines by bringing vector search directly to your data.
- Leveraging SQL for AI How to combine semantic search with standard filters, joins, and ACID-compliant transactions,.
- Mastering Performance: Strategies for optimizing high-dimensional queries using IVFFlat indexing and parallel execution.
- Making the Right Choice: A critical comparison of PostgreSQL versus dedicated vector databases to help you choose the right tool.
- Real-World Application: Exploring practical use cases, from recommendation engines to anomaly detection.
- Hands-On Tutorial: A step-by-step guide to enabling extensions, creating vector tables, and running your first similarity search on Aiven.
Executive Summary: Key Takeaways
| Core Advantage | Business & Technical Impact |
|---|---|
| Unified Architecture | Eliminates the need for complex ETL pipelines and data synchronization by storing vector embeddings directly alongside relational data. |
| Enterprise Reliability | Maintains full ACID compliance, ensuring data consistency, durability, and support for point-in-time recovery (PITR), features often lacking in dedicated vector databases. |
| Hybrid Search Power | Enables developers to use standard SQL to combine vector similarity search with traditional filters (e.g., WHERE category = 'electronics') and table JOINs for richer context. |
| Optimized Performance | Mitigates the high computational cost of vector math using Approximate Nearest Neighbor (ANN) indexing (IVFFlat) and parallel query execution. |
| Scalable & Accessible | Available across all major clouds (AWS, Google Cloud, Azure) via Aiven, with a Developer Tier starting at $5 USD/month for low-risk prototyping. |
New: With our Developer Tier for PostgreSQL (starting at $5 USD), you can try vector search - ideal for testing, prototyping, and small-scale AI apps.
What Is PostgreSQL Vector Search?
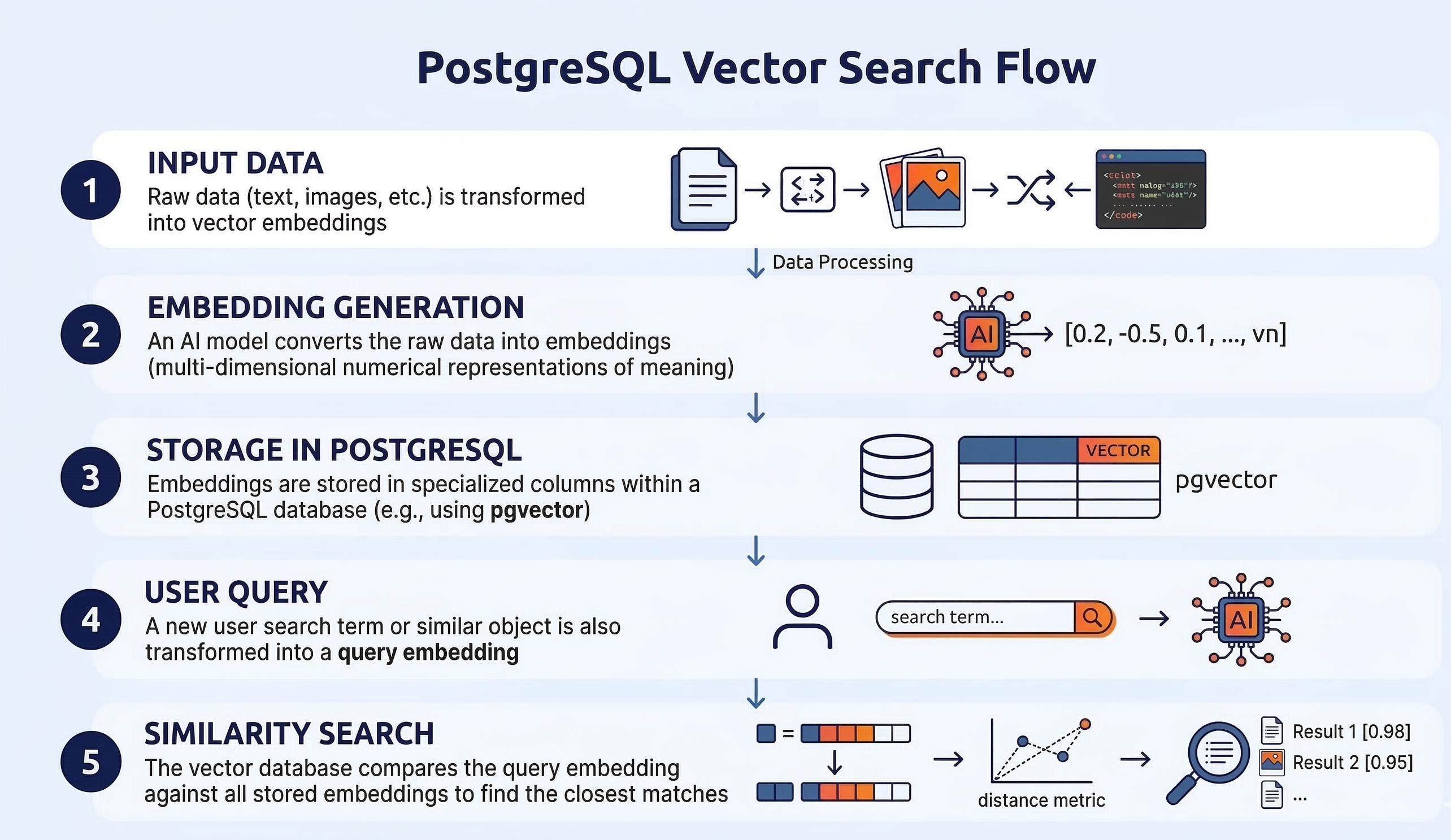
PostgreSQL vector search uses the pgvector extension to store and compare vector embeddings within the database.
A vector, often called an embedding in machine learning and natural language processing (NLP), represents data as a list of numerical features. These vectors encode semantic meaning, enabling comparisons based on similarity rather than exact matches.
With PostgreSQL vector search, developers can:
- Store embeddings directly in PostgreSQL tables.
- Measure similarity between vectors using distance metrics like Euclidean or cosine distance.
- Find results that share semantic characteristics with a given query.
By using indexes, such as IVFFlat, you can dramatically speed up these similarity searches while balancing performance and accuracy. The result: vector search queries that scale with manageable overhead.
Advantages of Using PostgreSQL for Vector Search
While dedicated vector databases focus purely on vector storage and retrieval, PostgreSQL with pgvector provides a more versatile and reliable foundation for developers who want both structured and unstructured data in the same system. Here’s why this approach stands out:
1. Unified Storage: Vectors + Relational Data in One Place
One of the biggest advantages of PostgreSQL vector search is the ability to store embeddings alongside relational data.
Instead of maintaining a separate database for vectors, developers can keep their product catalogs, user profiles, or document metadata in the same PostgreSQL tables as the embeddings derived from them.
This unified model reduces:
- Data synchronization overhead: No ETL pipelines between systems.
- Latency: Queries run in place without cross-database lookups.
- Complexity: One schema, one language (SQL), one data model.
In short, you can embed vector-based intelligence directly into your transactional database.
2. Built-In Reliability and ACID Guarantees
PostgreSQL’s strongest advantage is its ACID compliance (Atomicity, Consistency, Isolation, Durability).
This ensures that every vector operation, from insertion to similarity search, obeys the same transactional rules as any SQL query.
Benefits include:
- Data integrity: Vector and relational data are always in sync.
- Point-in-time recovery (PITR): Restore databases to any state with built-in backup and recovery mechanisms.
- Concurrency control: Multiple vector queries can run safely without race conditions or partial updates.
Dedicated vector databases often sacrifice these guarantees for performance, but PostgreSQL provides both safety and speed, in one environment.
3. SQL Power: JOINs, Filters, and Complex Queries
With pgvector, vector similarity becomes just another operator in your SQL toolkit.
You can perform hybrid queries that combine embeddings with traditional filters and joins - something many vector-only databases cannot natively do.
For example:
Loading code...
This flexibility means you can:
Filter by metadata (price, category, tags) and similarity.
Join vector data with other tables (e.g., users, inventory, or reviews).
Use standard PostgreSQL indexing and query planning tools to optimize performance.
4. Seamless Integration and Ecosystem Support
Because pgvector is a PostgreSQL extension, it inherits the full ecosystem:
Works with ORMs (SQLAlchemy, Prisma, Django ORM).
Compatible with PostgreSQL drivers for Python, Node.js, Java, and Go.
Easily integrated with existing analytics tools like Grafana, Metabase, or Superset.
This makes PostgreSQL an attractive choice for developers who already use it as their system of record. Vector search simply extends its capabilities without adding new infrastructure.
5. Comparing PostgreSQL Vector Search vs. Native Vector Databases
| Feature / Capability | PostgreSQL + pgvector | Dedicated Vector Databases |
|---|---|---|
| Data Model | Unified vectors + relational data in the same tables | Separate vector-only data model |
| Query Language | Standard SQL with <-> operator | Proprietary APIs or SDKs |
| ACID Transactions | Fully supported | Often limited or non-existent |
| JOINs and Filters | Native SQL JOINs and WHERE clauses | Typically requires external logic |
| Point-in-Time Recovery (PITR) | Built-in | Rarely supported |
| Scalability | Horizontal scaling via PostgreSQL extensions | Varies by vendor |
| Operational Overhead | Low (single system) | Higher (multiple specialized systems) |
| Use Case Fit | Best for hybrid analytical + transactional workloads | Best for pure vector retrieval at massive scale |
In essence, PostgreSQL with pgvector excels when your vector search needs are closely tied to structured, transactional data.
Dedicated vector databases may outperform it in ultra-high-dimensional or billion-vector scenarios, but for most AI-augmented applications, PostgreSQL delivers the best of both worlds: simplicity, reliability, and flexibility.
Key Takeaway
Using PostgreSQL for vector search allows engineering teams to integrate AI capabilities directly into their existing data workflows, without compromising on transactional integrity or maintainability.
It’s not just a vector engine, it’s a full-featured, enterprise-grade data platform that now understands embeddings.
Challenges in PostgreSQL Vector Search
While PostgreSQL vector search with pgvector unlocks powerful capabilities, it’s important to recognize that vector search itself is inherently computationally expensive.
Understanding these challenges (and how PostgreSQL mitigates them) helps developers design performant and scalable systems from the start.
1. Vector Search Is Computationally Expensive by Nature
Vector similarity search involves comparing high-dimensional numerical data, often hundreds or thousands of dimensions, across many records.
Unlike standard indexed lookups (e.g., WHERE id = 123), similarity queries must calculate distance metrics (such as Euclidean or cosine distance) between vectors.
This can lead to:
High CPU usage, especially for large datasets or high-dimensional embeddings.
Increased query latency, since every vector must be compared until filtered or indexed.
Memory pressure, when processing many vectors concurrently.
These are not PostgreSQL-specific issues, they are intrinsic to vector math and similarity search.
2. How PostgreSQL Addresses These Challenges
PostgreSQL and the pgvector extension include several mechanisms to reduce computational cost and improve performance:
| PostgreSQL Feature | How It Helps with Vector Search | Practical Impact |
|---|---|---|
| Approximate Nearest Neighbor (ANN) Indexing | Uses IVFFlat or HNSW indexes to cluster vectors and limit comparisons to relevant partitions. | Greatly improves query speed with minimal loss of accuracy. |
| Parallel Query Execution | Splits vector operations across multiple CPU cores when possible. | Enhances throughput for large datasets and concurrent queries. |
| Hybrid Filtering (Relational + Vector) | Combines standard SQL filters (e.g., WHERE category = 'laptop') before similarity comparison. | Reduces the number of vectors that need to be compared. |
| Index Maintenance and Vacuuming | Regular maintenance via VACUUM and ANALYZE keeps statistics and index structures efficient. | Sustains stable performance over time. |
3. Tips and Best Practices to Optimize Vector Search in PostgreSQL
To get the best performance out of your PostgreSQL vector search, consider these practical recommendations:
a. Choose the right distance metric
Use cosine distance for text embeddings (e.g., OpenAI, SentenceTransformers).
Use Euclidean for dense numerical data or physical measurements.
Align your vector normalization (unit length vs. raw) with the metric you choose.
b. Tune IVFFlat parameters
Adjust lists (number of clusters) and probes (search depth) to balance accuracy and performance.
Example:
Loading code...
c. Filter before you compare
Add metadata conditions in your query to reduce the number of candidates:
Loading code...
This approach is significantly faster than searching across the entire dataset.
d. Monitor query performance
Use tools like EXPLAIN (ANALYZE) to understand how PostgreSQL executes vector queries, identify full scans, and tune indexes accordingly.
e. Scale smartly with Aiven
Aiven for PostgreSQL provides automatic scaling options, high-performance SSD storage, and monitoring integrations that simplify tuning and resource optimization for vector workloads.
4. When to Consider a Specialized Vector Database
While PostgreSQL with pgvector suits most AI-driven use cases, from semantic search to recommendations, dedicated vector databases might be more efficient for:
- Extremely large datasets (hundreds of millions of vectors)
- Ultra-low-latency search across many concurrent users
- Specialized approximate algorithms (e.g., HNSW, PQ, or GPU acceleration)
However, for 80–90% of practical applications, PostgreSQL offers a balanced trade-off: the simplicity of a single data platform combined with strong consistency, flexibility, and integration options.
Key Takeaway
Vector search is inherently demanding, but with pgvector, PostgreSQL makes it approachable, performant, and reliable.
By leveraging indexing, smart query design, and the scalability of managed services like Aiven, developers can achieve near-native vector search efficiency without sacrificing SQL’s robustness or ACID guarantees.
Use Cases: How Developers Use PostgreSQL Vector Search
Vector search unlocks new ways to analyze and retrieve information directly from PostgreSQL. Common use cases include:
| Use Case | Description | Recommendation |
|---|---|---|
| Recommendation systems | Suggest products relevant to a user’s preferences while filtering for availability using relational joins. | Suggests products based on similarity scores. |
| Anomaly detection | Identify outliers by comparing vectorized behavioral data. | Detects patterns that deviate from the norm. |
| NLP search | Enable semantic queries across documents or chat data using embeddings and LLMs. | Perfect for RAG (Retrieval-Augmented Generation). |
| Image and object recognition | Store embeddings for visual similarity queries directly in PostgreSQL. | Eliminates the need for separate image metadata DBs. |
Whether you work in e-commerce, SaaS, or healthcare, **pgvector ** empowers developers to build AI-driven features using their existing PostgreSQL architecture.
How pgvector Enhances PostgreSQL’s Vector Search
While PostgreSQL provides the foundation for reliability, consistency, and flexibility, it’s the pgvector extension that transforms it into a capable vector database, enabling AI-powered search, semantic retrieval, and similarity matching directly within SQL.
1. Extending PostgreSQL for Vector Data
The pgvector extension adds a new native data type (vector) to PostgreSQL.
This allows developers to store high-dimensional numerical data (embeddings) directly in their tables alongside existing relational columns.
For example:
Loading code...
Each row can now hold an embedding generated by a machine learning model such as OpenAI, Hugging Face, or SentenceTransformers, enabling semantic understanding of your data without introducing a new system.
Key benefits:
- Embeddings can be stored, indexed, and queried like any other PostgreSQL column.
- Developers can use standard SQL tools and connectors, no new query language needed.
- pgvector integrates seamlessly into PostgreSQL’s transaction model and backup system.
2. Vector Data Types and Similarity Metrics
The vector type supports configurable dimensions, depending on the size of your embedding model (e.g., 768 for BERT, 1536 for OpenAI models).
Once stored, you can perform similarity calculations directly in SQL using specialized operators.
| Operator | Description | Use Case Example |
|---|---|---|
<-> | L2 distance (Euclidean) between two vectors | Ideal for numeric or spatial data where the absolute magnitude of the vectors matters. |
<#> | Inner product similarity | Often used when vectors are not normalized and you need to account for vector length. |
<=> | Cosine distance (1 - cosine similarity) | Best for text and semantic embeddings where the angle between vectors is the primary metric. |
Example:
Loading code...
This query returns the most semantically similar documents to the given vector, a core building block of AI-powered search and recommendation systems.
3. Nearest Neighbor Search and Vector Indexing
For larger datasets, pgvector enables high-performance nearest neighbor (NN) and approximate nearest neighbor (ANN) search through specialized indexing strategies.
| Index Type | Description | When to Use |
|---|---|---|
| Brute-force (Sequential Scan) | Compares all vectors directly. | Suitable for small datasets (up to a few thousand rows). |
| IVFFlat (Approximate Nearest Neighbor) | Partitions vectors into clusters and searches within a subset. | Recommended for larger datasets; balances accuracy and speed. |
Example:
Loading code...
This index clusters vectors into 100 lists and searches the 10 most relevant lists for each query, dramatically improving performance while maintaining acceptable precision.
Key capabilities:
Perform nearest neighbor searches directly within SQL
Combine ANN queries with filters and joins for hybrid vector + metadata search
Leverage PostgreSQL’s planner for parallel execution and query optimization
4. Real-World Impact: From SQL to Semantic Search
By extending PostgreSQL with pgvector, developers can turn their existing database into a semantic engine that understands meaning, not just values.
This enables features like:
- Contextual product recommendations based on embeddings of descriptions or user behavior
- Natural language document retrieval, where users query data semantically instead of keyword matching
- Hybrid filtering, combining similarity with SQL logic (e.g., category, date, or region filters)
Because all data (vectors, metadata, and relations) live in the same system, pgvector enhances PostgreSQL without the need for additional infrastructure or ETL pipelines.
Key Takeaway
pgvector turns PostgreSQL into a hybrid relational–vector database, enabling AI-native capabilities like semantic search and similarity matching while preserving all the strengths of SQL (transactions, indexing, and reliability).
It bridges the gap between traditional databases and modern AI applications, empowering developers to build intelligent systems on the database they already trust.
Why Choose Aiven for PostgreSQL for Vector Workloads
Running pgvector on Aiven for PostgreSQL gives you the power of vector search with the simplicity of a managed service:
| Advantage | How It Helps Developers |
|---|---|
| Accelerate ML adoption | Vector search becomes just another SQL query, no need to deploy new databases. |
| No data movement | Store embeddings and transactional data in the same system, reducing ETL complexity. |
| Empower existing architectures | Add pgvector to PostgreSQL instantly without redesigning your stack. |
| Combine filters and vectors | Blend similarity search with standard SQL filters for richer results. |
| Enterprise reliability | Enjoy ACID guarantees, high availability, and managed backups from Aiven. |
Tutorial: How to Enable and Test pgvector on Aiven
pgvector is available on all Aiven for PostgreSQL instances running version 13 or later.
Follow these steps to get started:

1. Enable the Extension
Connect to your instance via SQL (for example, with psql and run:
Loading code...
2. Create a Table with a Vector Column
Define columns of type VECTOR and specify the dimensionality:
Loading code...
3. Insert Data
Loading code...
4. Perform a Similarity Search
Use the <-> operator to compute L2 distance distance:
Loading code...
Result:
PostgreSQL returns colors ranked by similarity to the pink vector [255,153,204].
Conclusion
The introduction of pgvector transforms PostgreSQL from a traditional relational system into a powerful hybrid relational, vector database. By bridging the gap between standard database operations and modern AI requirements, it empowers engineering teams to build intelligent features, such as semantic search and recommendation engines, without the operational overhead of maintaining separate infrastructure.
While dedicated vector databases may still be necessary for ultra-high-dimensional or billion-scale datasets, PostgreSQL offers the best trade-off for most applications by combining vector search efficiency with enterprise-grade robustness. With Aiven’s managed service, developers gain immediate access to these capabilities across major clouds, supported by features like automatic scaling and high availability. Ultimately, Aiven for PostgreSQL® with pgvector allows you to integrate AI-native capabilities directly into your trusted data workflows, ensuring simplicity, reliability, and transactional integrity.
Pricing and the Developer Tier for PostgreSQL
Aiven for PostgreSQL is available across AWS, Google Cloud, and Azure in many regions.
The pgvector extension is supported on all Aiven plans (PostgreSQL 13+).
| Plan | Benefits & use cases | Starting Price |
|---|---|---|
| Developer Tier | Low-cost managed PostgreSQL for small projects, testing, and pgvector experiments. | $5 USD/month |
| Business & Premium Tiers | For production workloads with higher storage, throughput, and high availability. | Varies by cloud and region |
| Free Plan (limited) | For minimal learning and testing use cases with constrained resources. | Free |
→ Explore pricing and get started with Aiven for PostgreSQL
FAQ
What’s the difference between scalar and vector search?
Scalar search looks for exact matches (e.g., size = 10).
Vector search finds similar items by comparing vector distances - like “find images that look similar.”
Can I index vectors for better performance?
Yes. pgvector supports approximate nearest neighbor (ANN) indexing such as IVFFlat to improve search speed.
Is PostgreSQL vector search ACID compliant?
Absolutely. Since pgvector runs inside PostgreSQL, it maintains full ACID compliance and transaction integrity.
How does pgvector compare to a dedicated vector database?
Dedicated vector databases can offer advanced indexing and specialized features, but pgvector keeps everything in one system, reducing infrastructure complexity, latency, and cost.
Which Aiven plans support pgvector?
All Aiven for PostgreSQL plans (version 13 and later) support pgvector, including Developer Tier and higher-capacity tiers.
Further reading

Table of contents
- What You Will Learn Today
- Executive Summary: Key Takeaways
- What Is PostgreSQL Vector Search?
- Advantages of Using PostgreSQL for Vector Search
- 1. Unified Storage: Vectors + Relational Data in One Place
- 2. Built-In Reliability and ACID Guarantees
- 3. SQL Power: JOINs, Filters, and Complex Queries
- 4. Seamless Integration and Ecosystem Support
- 5. Comparing PostgreSQL Vector Search vs. Native Vector Databases
- Key Takeaway
- Challenges in PostgreSQL Vector Search
- 1. Vector Search Is Computationally Expensive by Nature
- 2. How PostgreSQL Addresses These Challenges
- 3. Tips and Best Practices to Optimize Vector Search in PostgreSQL
- 4. When to Consider a Specialized Vector Database
- How pgvector Enhances PostgreSQL’s Vector Search
- 1. Extending PostgreSQL for Vector Data
- 2. Vector Data Types and Similarity Metrics
- 3. Nearest Neighbor Search and Vector Indexing
- 4. Real-World Impact: From SQL to Semantic Search
- Why Choose Aiven for PostgreSQL for Vector Workloads
- Tutorial: How to Enable and Test pgvector on Aiven
- 1. Enable the Extension
- 2. Create a Table with a Vector Column
- 3. Insert Data
- 4. Perform a Similarity Search
- Conclusion
- Pricing and the Developer Tier for PostgreSQL
- FAQ
- What’s the difference between scalar and vector search?
- Can I index vectors for better performance?
- Is PostgreSQL vector search ACID compliant?
- How does pgvector compare to a dedicated vector database?
- Which Aiven plans support pgvector?
- Further reading