


Introduction
In this article, we will be continuing our series of deep dives into KIP-405. Previously, we covered:
- 16 ways tiered storage makes Kafka simpler, better and cheaper
- The internals behind the KIP-405 writes and metadata flow
Now, we turn our attention to the internals of the read and delete paths. Just like we did for the write and metadata, here we will also be focusing on Aiven’s battle-tested Apache-licensed KIP-405 plugin. What makes the read path particularly interesting is how it delivers latency comparable to local disk or memory systems despite leveraging external object storage—let's dive in!
Tiered Storage Deletes
As we covered in the previous piece, there is a new set of local retention configs that denote how long the data is kept on the broker’s local disk, and the general retention settings we’re all familiar with apply to the remote storage.
How do Local Deletes Work?
The way local on-disk data gets deleted hasn’t changed significantly. There are only two differences that apply when KIP-405 is enabled for a topic:
- A new set of retention configs denote how long the data stays on the local disk -
local.retention.msandlocal.retention.bytes.
a. They work just like the existing retention settings - the stricter of the two gets applied, and it applies only on non-active segments that are above the LSO. (although keep an eye on KAFKA-16414)
b. It is customary to configure the local settings to a much smaller value than the overall retention policy. (that’s the whole point of KIP-405)
c. Both settings default to the sentinel value of “-2”, which makes Kafka fall back to the general retention settings. - Local data is deleted according to the local retention policy only if it has successfully been tiered.
The original retention settings we’re all familiar with (retention.ms and retention.bytes) now denote how long the data should be kept overall in the system. In the edge case where the segment doesn’t get uploaded in the external store for whatever reason, the regular retention settings will still kick in and delete the data when appropriate.
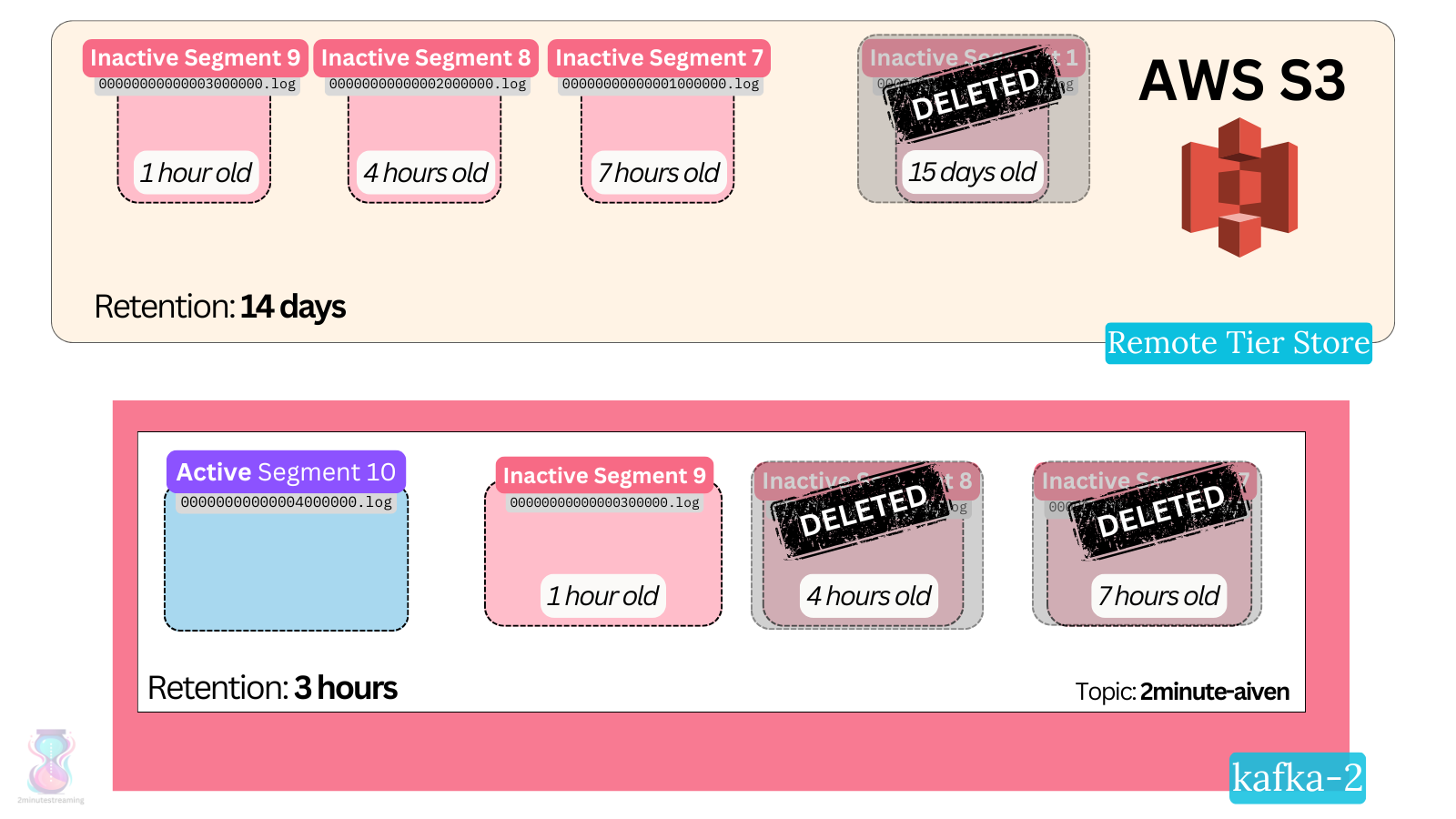
Common configurations ensure that the data retained locally is much smaller (10x-20x) than the one kept in the remote store. Nevertheless, if the external store is down for an extended period of time, the broker can still accumulate a significant amount of data locally. That is a simple matter of preparing a runbook for when things go wrong.
How do Remote Deletes Work?
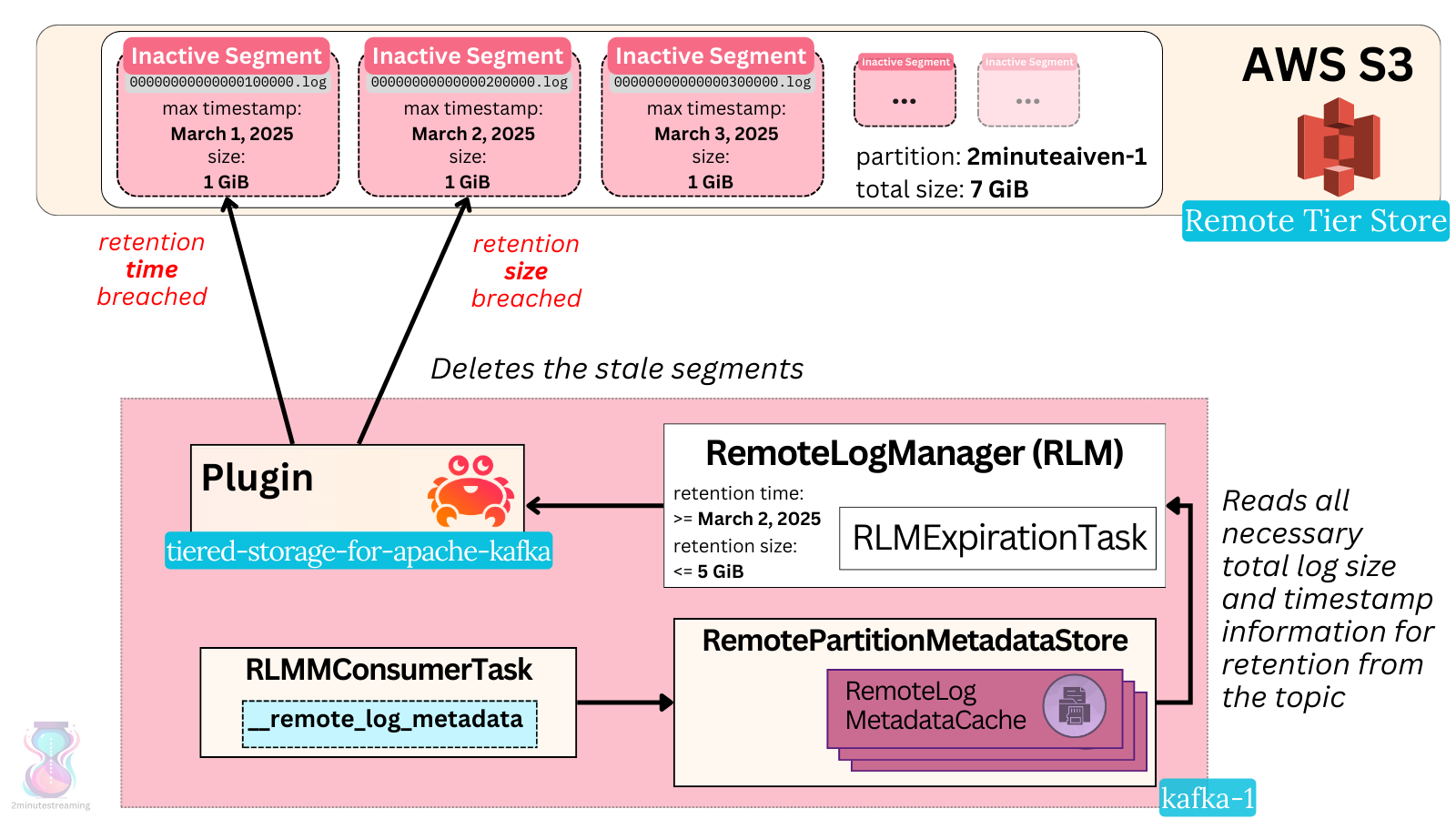
There is a separate thread pool that handles the delete operations - the RLM expiration thread pool (defaulting to ten threads like most others). One RLMExpirationTask per leader replica for user partitions on the broker is run there every 30 seconds.
It uses the cached state of each partition (fetched via the remote log metadata internal topic we covered in the last deep dive article) to check if the tiered segments are eligible for deletion.
The expiry task determines whether the remote retention time or remote retention size settings are breached - and if so, asks the plugin to delete the data. The Aiven plugin issues a delete request to the object store to delete that particular segment file and its associated indices/manifest files in S3.
What About Unreferenced Files
As we mentioned in the last piece when discussing the COPY_STARTED metadata record, an edge case that needs to be handled is when a broker fails during a segment upload. Depending on what precise point in time the broker fails at, a full segment could be stored in S3 without ever getting properly marked as complete.
Practically the files associated with the segment end up as unreferenced, because the broker will never use them again. The new broker that takes over the segment upload task will upload everything anew.
In such cases, Kafka needs to clean up after itself. The way it does it is subtle and easily missed, so pay attention.
Leader Epoch 101
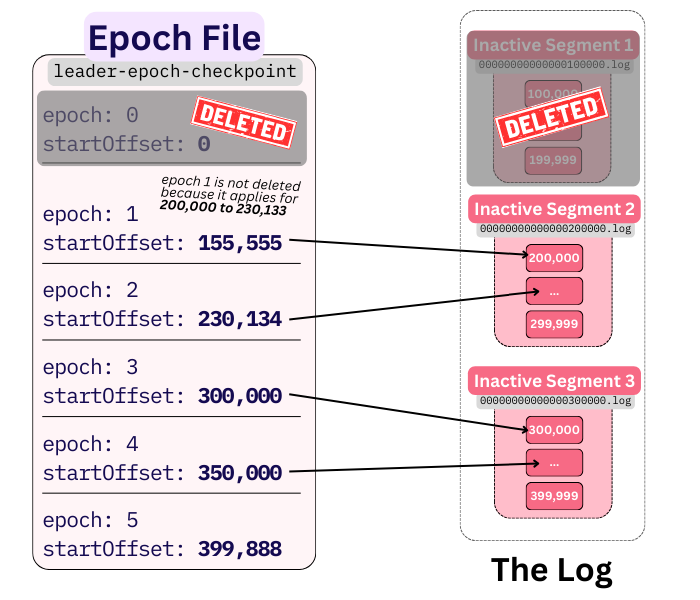
Unreferenced remote store files get evaluated for deletion based on the partition’s leader epoch checkpoint file (leader-epoch-checkpoint).
The leader epoch file is a sparse index of checkpoints which indicates at what offset of a partition’s data a given leader epoch started applying:
Loading code...
A snapshot of this data (at the time of upload) is tiered with every remote segment. It is also persisted in the internal remote log metadata topic.
Kafka brokers regularly trim the leader epoch file when segments are deleted (be it with or without KIP-405). This is done so that any epochs lower than the maximum epoch of the currently-deleted file are removed. By definition, said lower epochs are not referenced anywhere anymore. As a simple example - Kafka doesn’t have any use for a leader epoch generated one year ago, when the partition’s retention is only 7 days.
Deleting Unreferenced Files
With a base understanding of the leader epoch, we can now see how unreferenced file deletion is done.
The easiest way to explain it is through an example - imagine the following scenario:
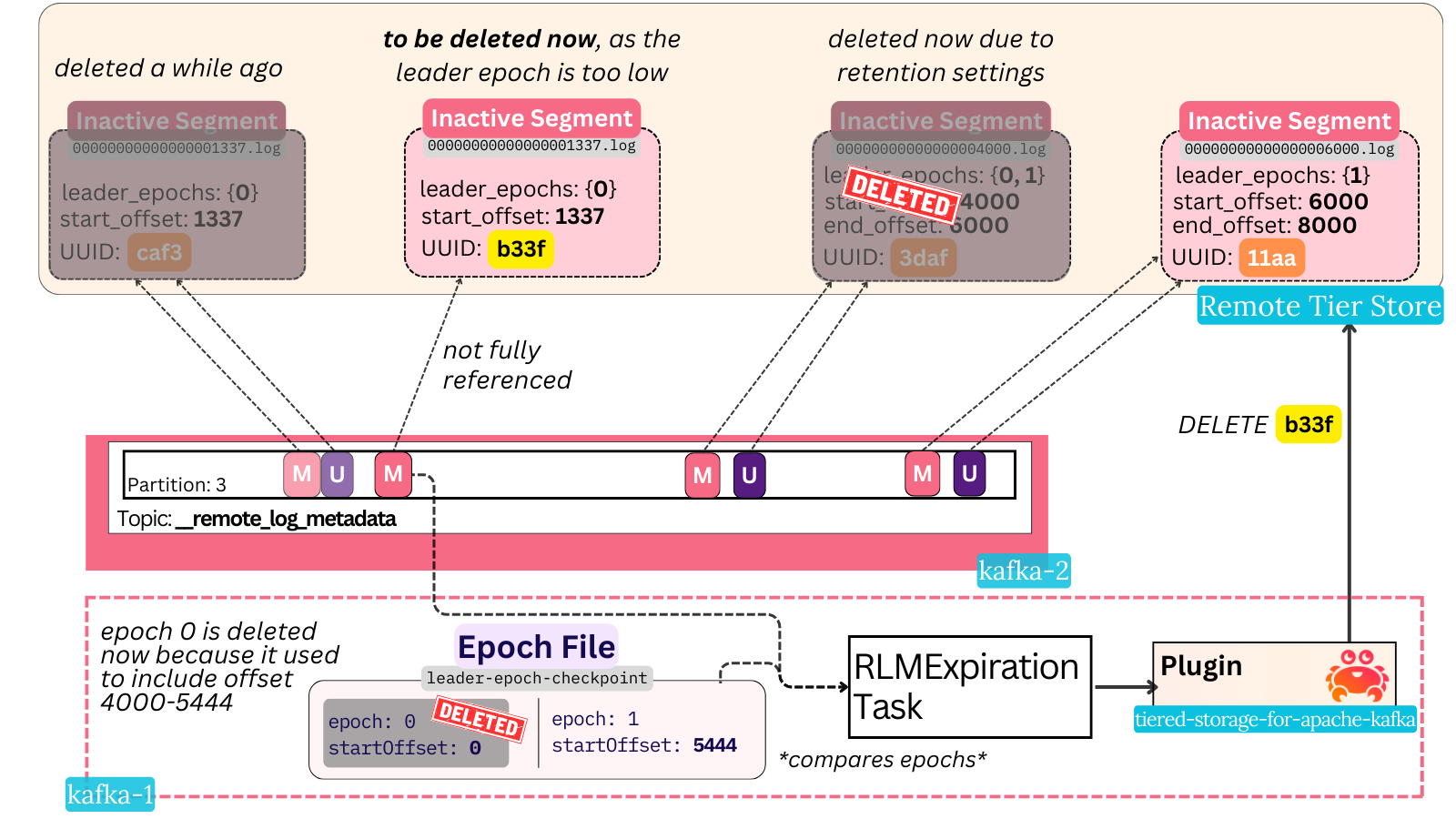
two brokers - A and B. A leads topic-partition 2minuteaiven-1 with leader epoch 0, B is a follower.
A uploads a segment of the partition, with start offset 1337, to S3. It generates a remote segment UUID of b33f and persists a metadata record to mark the start of the upload.
A then issues a lot of multipart PUT requests and uploads the full segment. Before it could persist a metadata update record to the topic in order to mark the completion, broker A fails.
We now have an initial metadata record and the segment in S3, but no record marking it as completed.
As per Kafka’s usual leader failover, B becomes the new leader and bumps its leader epoch to 1. The new leader epoch 1 is associated with offset 5444, simply because this was the end offset of the log at the moment of leader election.
B begins its own copy task for the segment with offset 1337 - it generates a different remote segment UUID (caf3) and persists the metadata record.
It uploads successfully, then persists the update metadata record, sealing the upload process.
At this point, we have two files in S3:
- One referenced segment (caf3)
- One unreferenced segment (b33f)
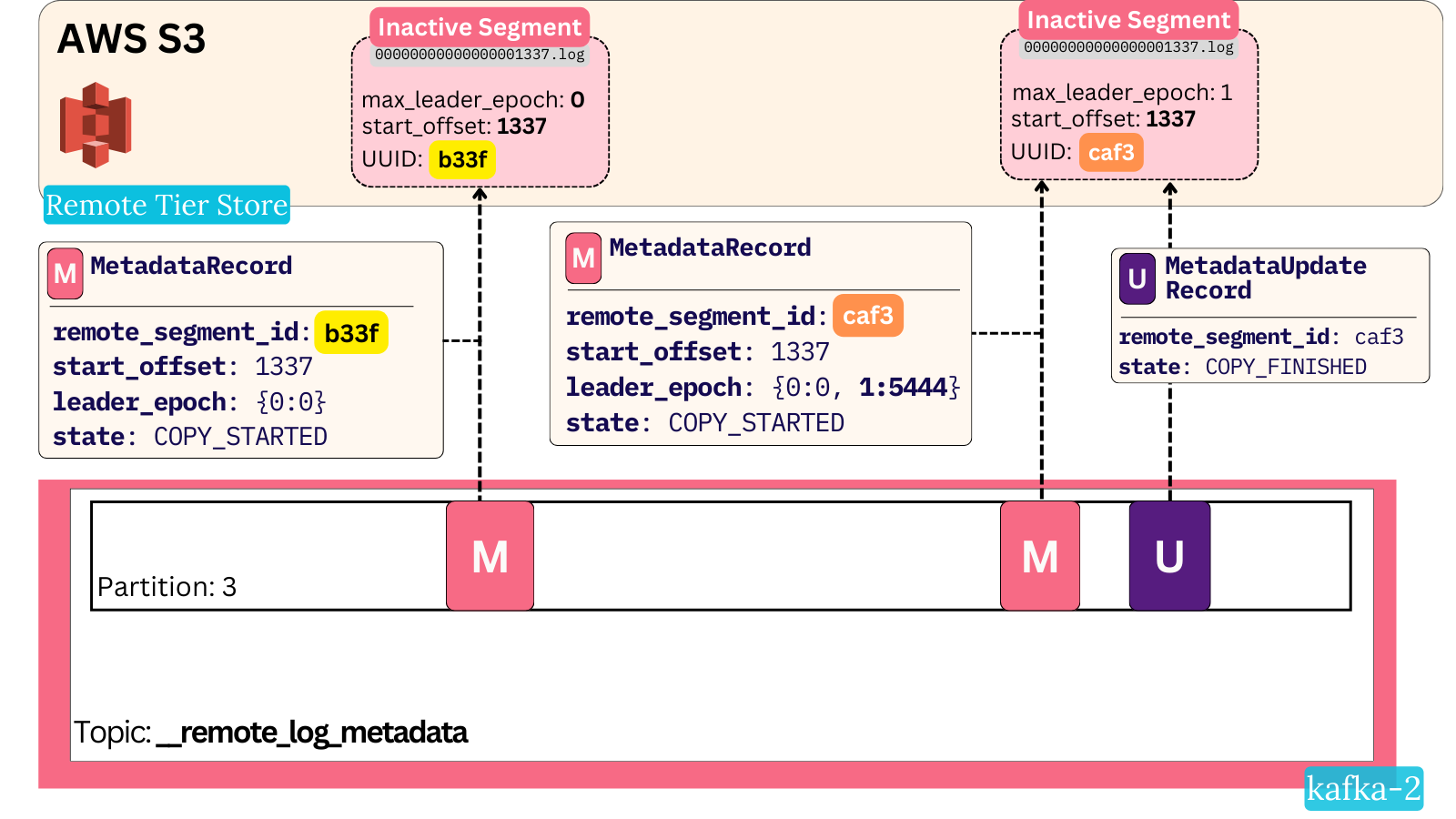
Both segments contain the exact same byte-for-byte content (the segment file was closed, so it could have never had new data appended to it). But only one file is properly referenced from the system and will be the subject of reads.
How will both files get deleted in time?
- caf3 will get deleted based on the regular retention time and size thresholds, as we described in the previous section.
- b33f will get deleted based on the leader epoch file. When the epoch file stops referencing the max leader epoch in the b33f remote segment, it will get deleted.
Let’s move forward in time a bit. Imagine broker B has kept successfully tiering up to offset 10,000, and it just deleted a segment with offsets 4000 to 6000. Because the 0->1 leader epoch election happened at offset 5444, the 4000-6000 segment was the last segment that had records associated with leader epoch 0 in it.
After this deletion, leader epoch 0 is no longer referenced in any partition data. The leader epoch file is now trimmed to omit the zero epoch entry (0 0).
The broker’s RLMExpirationTask notices that the unreferenced segment’s highest leader epoch (0) is lower than the current lowest leader epoch for the partition (1). It then rightly concludes that the file cannot possibly be needed and deletes it via the plugin.
Tiered Storage Reads
As we have covered so far in our series, the writes and deletes are entirely asynchronous tasks that don’t block any of the critical paths. Further - they are only executed on the leader broker.
For reads - it’s a different story. Reads can be served from follower brokers and do block the critical read path.
Broker-Side
Consumers send FetchRequests to brokers, asking them for data for multiple topic partitions, each starting from a particular offset. As a quick reminder, the maximum size of a FetchResponse is governed by two configs:
fetch.max.bytes- this config denotes the maximum size of data a consumer response can carry. The default is 50 MiB. This applies to the whole request.max.partition.fetch.bytes- this config denotes the maximum size of data a consumer response can carry for any single partition. Its default is a measly 1 MiB.
The broker naturally serves the data from the local pagecache/disk if it’s present there. If the data isn’t local, on the other hand, the broker needs to fetch it from the object store.
Max One Remote Read
There is a big gotcha with KIP-405 as of writing and it is that the broker only fetches remote data for one partition in a given FetchRequest. A fetch request will first try to populate its response with local data. For partitions whose requested offset isn’t present locally - a OffsetOutOfRange error is handled in the code. While you would expect this error to be handled by serving the data via a remote read, it is only done so for the first partition that encounters it.
This means that a single request asking for historical data (not present locally) from 50 partitions will only receive one partitions’ worth of data in its response, and the other 49 will be empty. In essence, under default configurations, it means a fetch response will never contain more than 1 MiB of historical data.
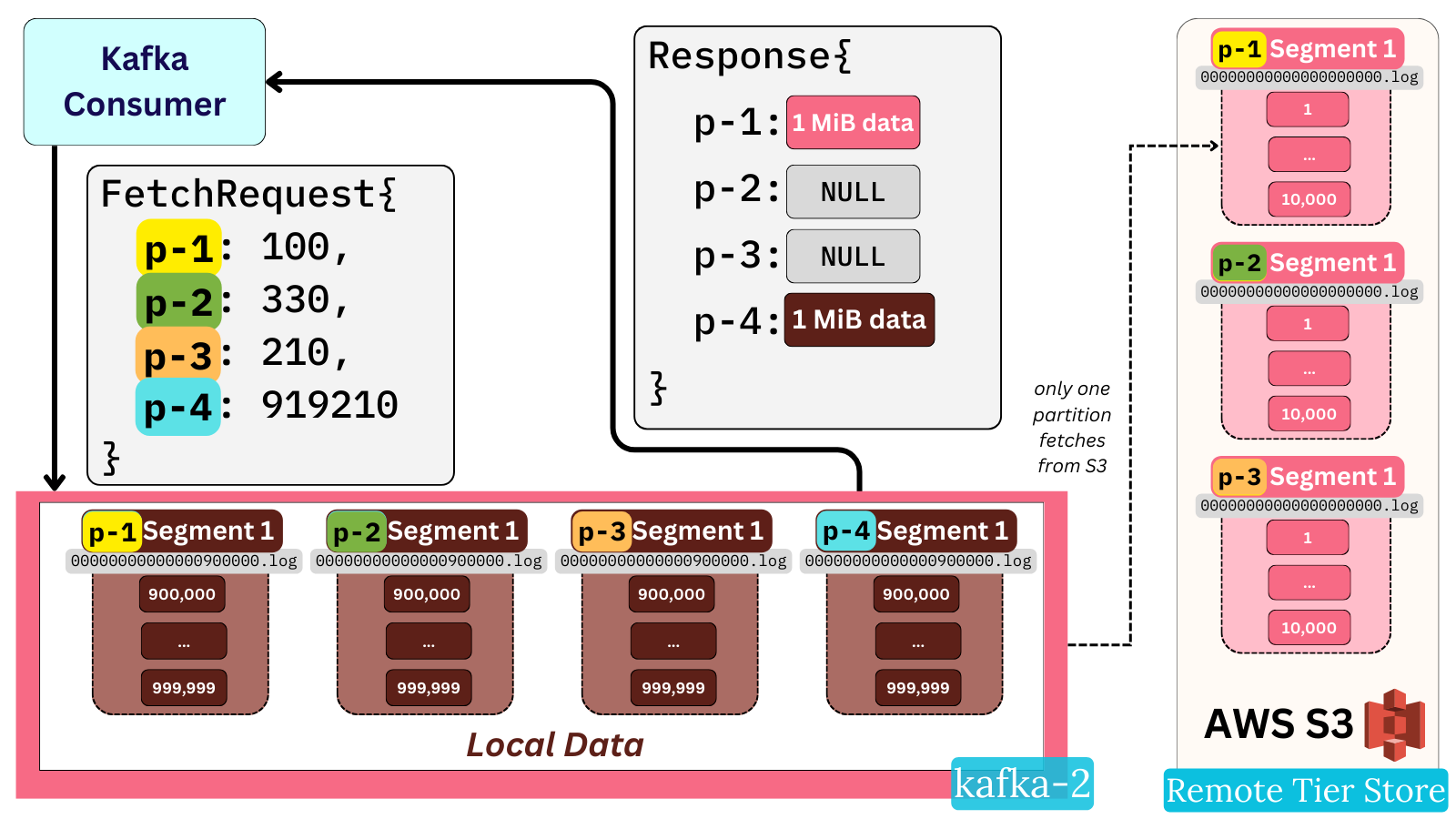
The direct implications of this are that the client throughput may be limited. It is recommended users keep this in mind and tweak the max.partition.fetch.bytes config to achieve the desired throughput for historical workloads.
It’s worth noting that this is a current limitation in Kafka and will be improved in the future (KAFKA-14915). We discovered this behavior was scarcely documented as part of writing this blog post, and have since [opened a PR to change that].
(https://github.com/apache/kafka/pull/19336).
EDIT 16 July 2026: This limitation has been fixed as of Kafka 4.2.0.
Exiled in Purgatory
As to how this one read is done - there is yet another thread pool inside RemoteLogManger for this remote fetching - a reader pool. Any reads from the object store get executed there.
The Kafka broker calls the async read from its usual request-handling thread (the IO thread) in ReplicaManager and places the read in its purgatory map.
The purgatory map is essentially one of Kafka's internal request queues, though it has a weird name. It serves as a waiting area for requests that the broker cannot immediately respond to. These requests usually require some additional external work to be done, like:
- A ProduceRequest with
acks=allrequires waiting for acknowledgements from all follower replicas before responding. - A FetchRequest reading from the end of the log with
fetch.max.wait.msandfetch.min.bytesrequires waiting (up to the max time) until it builds up the minimum bytes for a response.
This is where Tiered Storage reads come in too. A FetchRequest that wants to read a portion of the log from the external storage will end up in purgatory. It will stay there until the asynchronous remote reader thread fetches the data.
The asynchronous remote reader thread will proceed with everything necessary, including reading the data via the plugin, removing the request from the purgatory and sending out the fetch response.
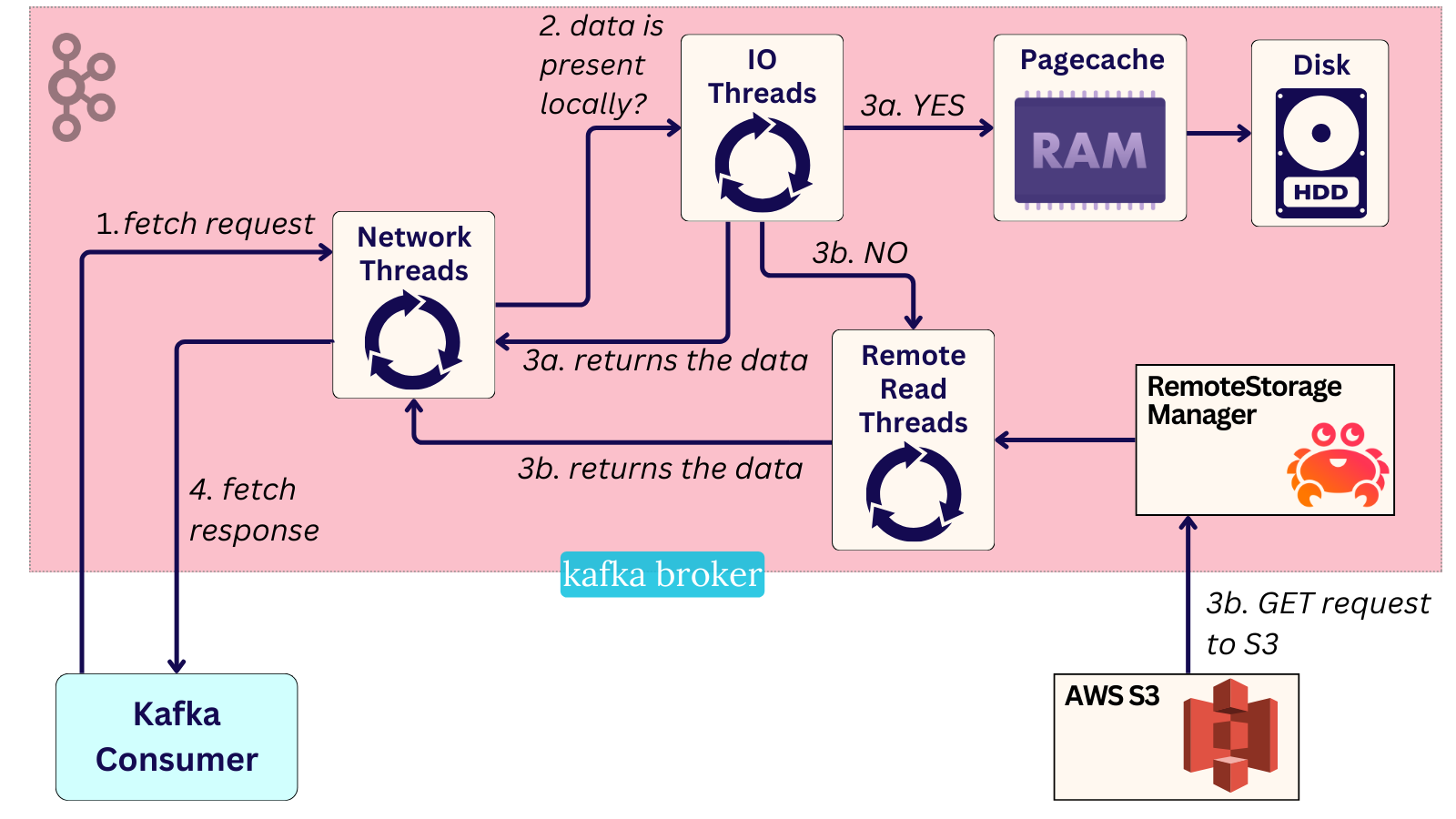
In practice, what all this machinery simply does is allow the Fetch request to block for longer without impacting other work.
Through executing the blocking call in a separate thread within the purgatory map, the slower remote reads do not affect any other Kafka operation because they aren’t run in the shared IO threads.
Plugin-Side
We are now halfway through the article and have covered both how deletes work and how the broker code handles remote reads at a high level.
The other half of the article is dedicated to the juicy details - how does the plugin actually execute the remote storage read? Hint: it’s more complex than you’d think.
Chunk by Chunk
As we mentioned in the last piece - a chunk is a concept specific to the Aiven Tiered Storage plugin. It is literally a small piece (range of bytes) from the overall segment.
To avoid sluggish performance, the plugin utilizes object stores’ byte-ranged GET feature to fetch a particular chunk of the overall segment log.
This type of GET is a simple feature offered by all cloud object stores - it allows you to fetch a particular range of bytes from a file, instead of the whole thing. In Kafka’s case, instead of downloading a 1 GiB segment to read 12 MiBs out of it - you can just directly fetch 12 MiB.
The size of this range (how much MiB you receive per GET call) is controlled by the chunk.size config used by the plugin. It defaults to 4 MiB, but the documentation recommends benchmarking it in order to find the right number for your workload. The plugin will never read less nor more than one chunk with a single byte-ranged GET.
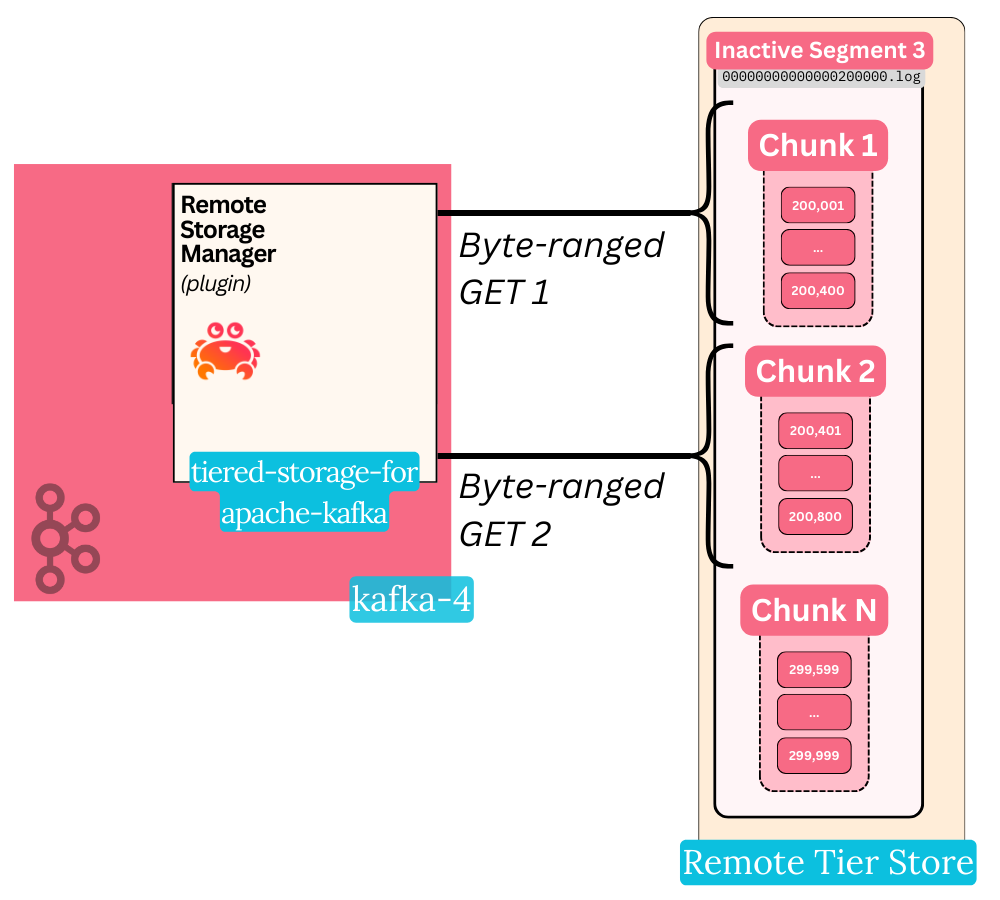
The chunk’s size has implications on how many S3 API calls you rack up. Each GET request has a cost - S3 charges you 40 cents per million GET calls, for example. Granted, this is relatively cheap - but still a cost to be aware of.
The chunk size does influences the maximum throughput you can reach per partition, especially when caching and prefetching come into the picture (as we will explore in a few paragraphs).
Which Chunk?
The consumer API doesn’t request chunks - it requests offsets and bytes. The Fetch request has two fields denoting this:
- FetchOffset - the offset it wants to start reading from (for a partition)
- PartitionMaxBytes - the maximum amount of bytes it wants to read (for a partition)
The mapping of offset to the correct byte position in the remote segment exists in the offset index file. If you recall, this was stored in object storage alongside the segment.
To avoid having to issue yet another remote GET call to the object store for the index file, a memory cache (1 GiB by default) is kept in the broker. The cache is populated with the index data the first time the particular index file is requested.
This cache leverages the popular Caffeine library. It’s worth noting it’s not the regular LRU (least recently used) cache everyone is familiar with. Rather, it is a LFU (least frequently used) cache - a policy that measures and expires based on the amount of times an item is accessed, not when. More specifically, the cache uses the Windowed Tiny LFU algorithm which allows it to store a larger sample size to base frequent access off of. The implication of this is that segments whose chunks are frequently read from the external store are most likely to have their index cached.
In practice, a regular offset index file has a size around 2 MB per segment. This means the default 1 GiB cache settings may store around 500 segments’ worth of index data. This can result in some fetch requests requiring double the round-trip time due to needing to fetch the offset index first - but frequently-accessed partitions should be faster.
Back to the read path: when a Fetch request comes from a consumer, the broker maps the requested offset to the closest lowest offset there is an index entry for in the index cache. The broker now has the associated byte position in the remote file for that offset.
Because the plugin reads whole chunks at once, it cannot simply start reading from the given byte position - it could be in the middle of a chunk. It uses the separate Segment Manifest file it stored in S3 as part of the write to map a given byte position (within a range) to the appropriate chunk number and its start byte position.
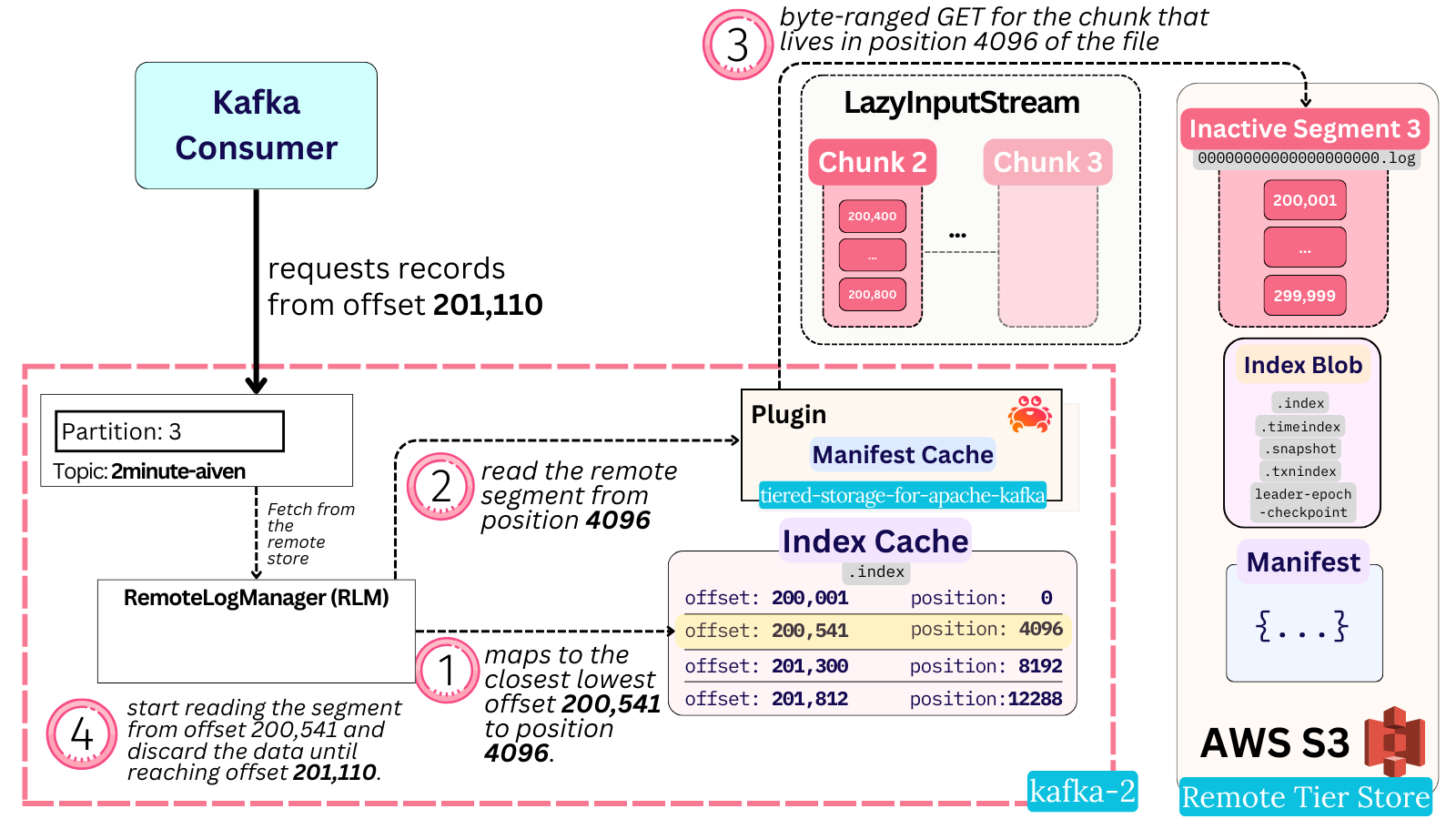
The Input Stream
The plugin is passed the index-file-derived byte position, maps it to the appropriate chunk and returns a chained lazy input stream. This stream begins from the given chunk and ends at the end of the log segment file. Internally, the input stream issues one byte-ranged GET for each chunk’s worth of data. Because it is a lazy stream, only the minimum amount of remote store GET calls happen just in time, as they’re needed.
The broker code reads through the input stream until it either reaches the end of the stream, or exhausts its byte read allowance. Notably, because the offset index likely doesn’t point to the exact offset the consumer is requesting - the broker reads and discards data from the input stream until it advances to the requested fetch offset. It is after this fetch offset that the byte read allowance starts counting and the actual data is stored in memory to be sent out.
The broker reads up whatever data it can, parses the bytes into records and executes a callback which removes the fetch request from purgatory and issues out a response to the consumer.
What About Latency?
Careful readers will notice that this lazy chunk-by-chunk byte-ranged fetching could, in theory, result in quite the high serial latency cost!
An object store GET can have relatively high latency - 50-100ms is standard. If a Fetch request wanted to read 3 chunks worth of data for a partition, it would call these 3 GETs sequentially one after the other due to the nature of the input stream. That could result in an aggregate wait time of above 300ms!
In practice, this does not result in high latency fetch requests because of 4 factors:
- The broker only fetches one partition from tiered storage
- The fetch request size cap
- Read Caching
- Pre-fetching
Let’s dive into these one by one:
1. One Partition Limit
As mentioned earlier, only one partition is fetched from the remote store. This limits the number of serial GET request chains a broker must issue to just one, which reduces the risk of tail latency amplification.
2. Fetch Request Size Cap
Consumer requests aren’t limitless - they have a maximum configurable byte size threshold. As mentioned earlier, the max.partition.fetch.bytes config denotes the maximum per-partition data returned by broker.
Its default setting of 1 MiB, paired with the KIP-405 default chunk size config of 4 MiB, means that in most cases, no default consumer request will ever require the broker to read from more than one chunk to serve it. Whether the broker needs to fetch two chunks depends on whether the requested offset is at the end of a chunk (spilling over to the next one) and what the offset index file points to as the position of the earliest offset (e.g pointing to an earlier chunk).
This limit is why, in practice, the plugin never needs to read too many chunks in serial order for the same partition. Of course, one could always change the consumer’s settings - but that should mean they change the chunk size setting appropriately too.
3. Read Caching
Even a single GET request can increase the total request latency to above a hundred milliseconds. It’s common wisdom that this is the simple tradeoff you make by storing your data in object storage - you gain a lot of benefits but experience higher latency. Surprisingly, this is largely avoidable!
The simple age-old solution of caching data you’ve already read can avoid having duplicate fetch requests pay the same latency cost. When paired with pre-fetching (later on), it can apply to non-duplicate requests too.
The Aiven plugin supports two caches via its fetch.chunk.cache.class config:
DiskChunkCache- when a chunk of the log is read, it is written to the local disk as a cache.MemoryChunkCache- when a chunk of the log is read, it is stored in memory.
These caches use Caffeine’s LFU. They are both configured to hold up to a maximum number of bytes as per their respective config.
They work by wrapping the object store fetching logic: if the requested data is cached, it’s served immediately; if not - it’s fetched and cached for future use. Caching without prefetching is less ideal, but still ensures duplicate reads are fast. The first read for a given piece of data won’t be fast (it will be served from the remote store), but any subsequent ones requesting the same data will. Caching alone makes sense in times where you’re expecting more consumers to read the same offset.
Concurrent Reads
Something any caching system needs to handle is concurrency. If, at roughly the same time, two consumer Fetch requests ask for the same chunk of data (e.g offset 100-200) and it isn’t present in the cache - the system would do well to ensure that only one S3 request is sent out to fetch the underlying data.
The way Aiven’s plugin achieves this is by leveraging Caffeine’s AsyncCache class. It is a thread-safe performant cache that stores keys mapped to completable future objects. The cache has map-like semantics, meaning each key has only one value associated with it.
In this context, the key is a chunk’s id and the value is a function that issues a byte-ranged GET to the object store to fetch the chunk. All chunk reads from all the input streams the plugin returns go through this single cache map object. The result is that there are never any duplicate concurrent byte-ranged GETs issued to the underlying remote store for the same chunk.
4. Pre-Fetching
Read caching shines the most when pre-fetching is enabled. A quick definition:
- pre-fetch: reading in advance of the requested part of the log, in the assumption that the consumer will ask for the subsequent part after.
Kafka consumers’ read patterns are highly predictable and thus easy to optimize for. If the broker receives a request to read a chunk of the log with offsets 100-200, there is a high likelihood that the subsequent request will ask for data starting from offset 200.
Pre-fetching takes advantage of this idea and begins to fetch these subsequent offsets asynchronously, with the sole goal of caching this data in memory so that the next request can be served fast.
If you configure things properly, your consumers can read from S3 with the exact same latency that it takes to read the data from memory!
How Pre-Fetching Works
It is implemented very simply - when the prefetch.max.size config is set, the plugin will eagerly fetch prefetch.max.size bytes’ worth of chunks and cache them according to the set caching strategy (disk/memory). This fetching occurs in a separate thread pool maintained by the cache and happens whenever a fetch request is handled by the plugin.
The eager fetch’s start position is the end position of the current chunk the plugin is reading. Because the plugin can serve multiple chunks for a consumer’s fetch request, this means the pre-fetching can apply intra-request as well as inter-request.
Let us visualize an example and run through it step by step. Imagine this:
- 200 records == 1 MiB
- 1 chunk == 2 MiB (equal to 400 records)
- Prefetch size == 4 MiB (equal 800 records)
- 1 consume request requests 600 offsets from the same partition (3 MiB)
Note that the default configuration numbers are 4 MiB for a chunk, zero for the prefetch size and a maximum of 1 MiB per partition in a fetch request. We are changing them to odd numbers here to more concisely illustrate how the caching works.
-
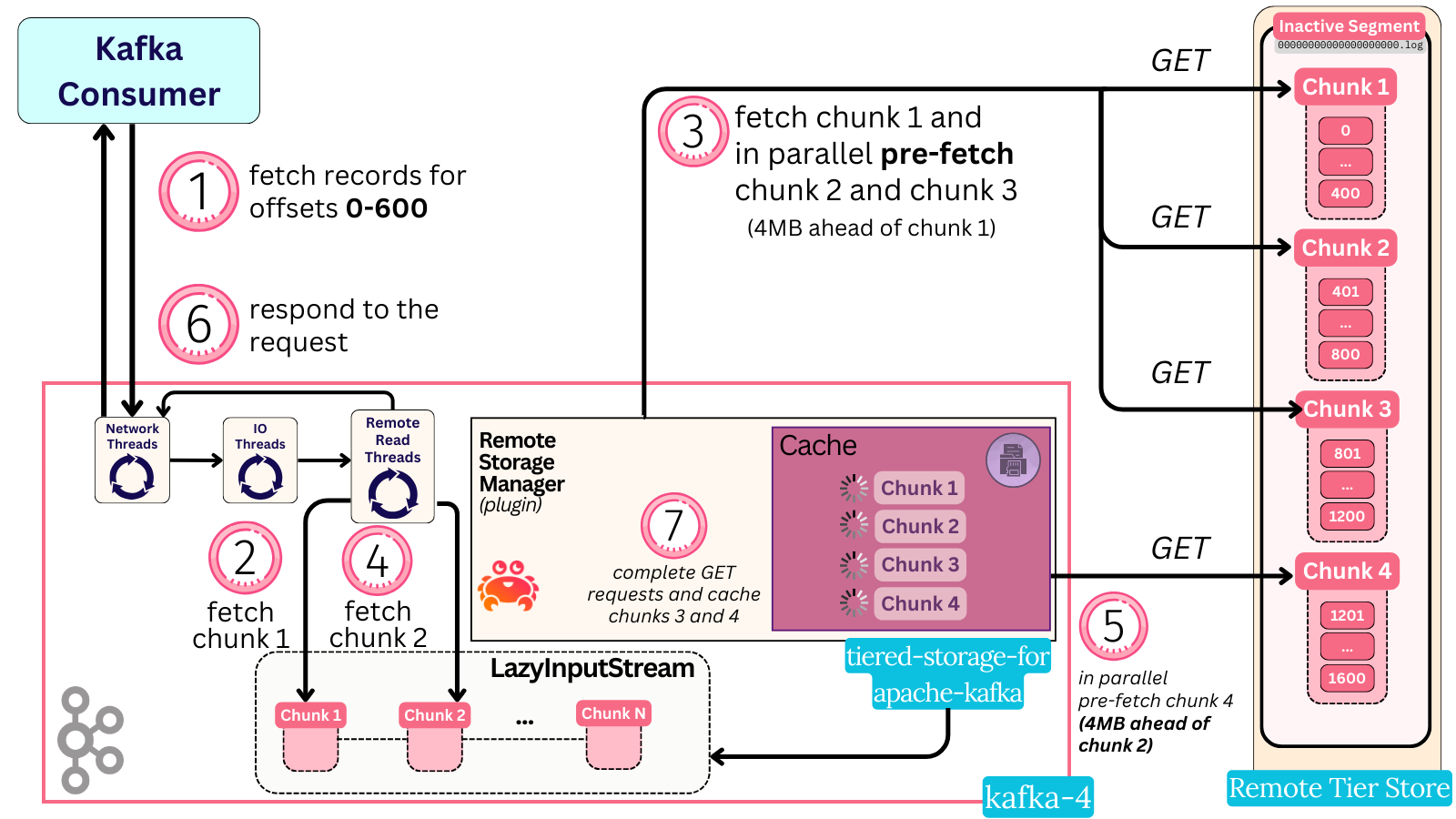
A consume request comes for offsets 0-600. The broker requests it from the plugin and receives an input stream of chunks, which it starts consuming.
-
The broker calls for the first element (chunk) of the lazy input stream. The call forces the plugin code to request chunk 1 from S3. Because pre-fetching is enabled, the plugin in parallel issues more requests to S3 to fetch 4 MiB worth of pre-fetch data. Since each chunk is 2 MiB, this results in two S3 requests fetching chunk 2 and 3.
-
At this point, there are three parallel byte-ranged GET requests flying out to S3. All three are run in the cache’s thread pool.
-
The chunk one request returns, and the broker gets its first element of the lazy input stream (chunk 1) returned. It now has records 0-400 in memory. It immediately iterates and asks for the next element of the input stream (chunk 2). This action kicks in pre-fetching again, and the plugin tries to pre-fetch two more future chunks (chunks 3 and 4)
-
Requests for chunks 2 and 3 were already sent as part of the last iteration’s prefetching. No new fetches are called for them. Instead, the already-existing future objects are simply awaited. In parallel, a new prefetch is called for chunk 4.
-
The chunk 2 S3 request returns a few milliseconds after. The broker reads half of chunk 2 to get the last 400-600 records. The fetch request has now collected all 3 MiBs, is fulfilled, and a response to it is sent back.
-
Asynchronously, the chunk 3 and 4 requests complete too, and their results are cached via the configured strategy (memory or disk)
Let’s pause here.
The benefit of this approach was that instead of waiting for two S3 GET round-trips (potentially 2x 100ms), the request was served in roughly the time of one S3 GET due to the parallelism.
What’s even better is that this was the slowest fetch out of them all! Going forward, future requests can be served instantly:
-
A new consume request comes for offsets 600-1200.
a. The records reside in chunk 2 (offset 600-800), and chunk 3 (800-1200), both of which are already cached from the last fetch request. They’re instantly served from the cache. -
On each cache invocation (chunk 2 and 3), future chunks are pre-fetched in parallel.
a. Chunk 2’s cache invocation tries to pre-fetch chunks 3 and 4 (both of them are already in the cache, so this is a no-op).
b. Chunk 3’s cache invocation tries to pre-fetches chunks 4 and 5. Chunk 4 is in the cache, so it’s a no-op. A GET is sent asynchronously for chunk 5. -
A new consume request comes for offsets 1200-1800. They reside in Chunk 3 (1200-1600) and Chunk 4 (1600-1800). Both are already present in the cache, so the records are served instantly. A new asynchronous prefetch is sent for Chunk 6.
-
Rinse and repeat for each new consumer request. All consumer data continues to be served fresh from the cache.
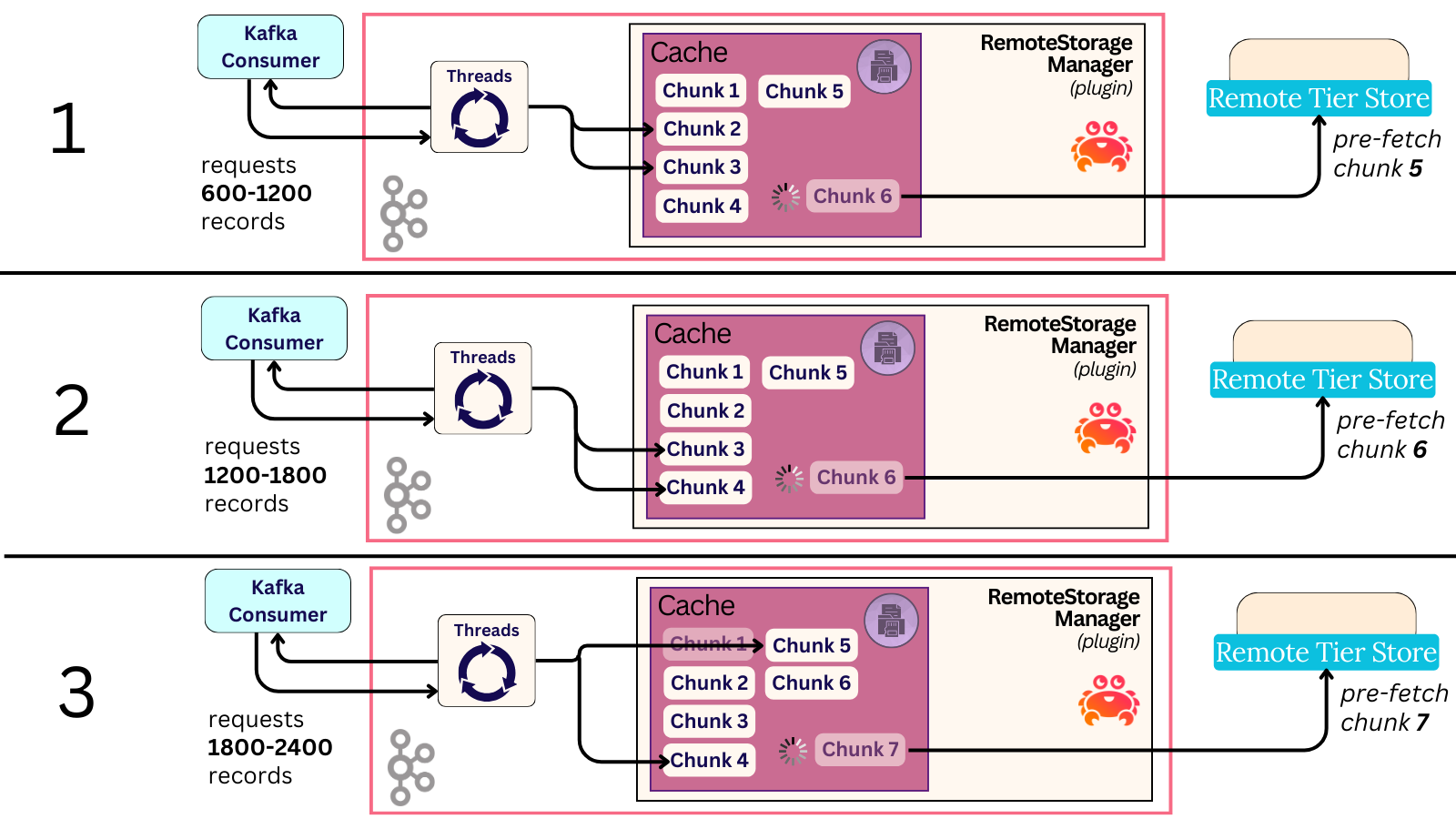
In table format, the happy path would look roughly like this:
| Consume Req | Served From | New Async GET Prefetch |
|---|---|---|
| Req 1 | Externally via GET. (chunk1 & chunk2) | chunk2, chunk3, chunk4 |
| Req 2 | Locally via the Cache. (chunk2 & chunk3) | chunk5 |
| Req 3 | Locally via the Cache. (chunk3 & chunk4) | chunk6 |
| Req 4 | Locally via the Cache. (chunk4 & chunk5) | chunk7 |
| Req 5 | Locally via the Cache. (chunk5 & chunk6) | chunk8 |
| Req 6 | Locally via the Cache. (chunk6 & chunk7) | chunk9 |
| Req 7 | Locally via the Cache. (chunk7 & chunk8) | chunk10 |
In practice, if your consumer application is fast, it can catch up to data that’s beyond the cache. Specifics can vary, and this is why proper tuning and benchmarking is so important.
In conclusion, when properly configured, prefetching plus caching allow local disk-like latency performance from remote storage on the read path.
Recap
We’ve now traced the full path of how Kafka reads from remote storage, handles caching and prefetching, and safely deletes expired or orphaned data. A quick, referenceable recap of what we covered is below.
Deletes
- Local data retention is handled by the new
local.retention.msandlocal.retention.bytessettings, usually set to a value tens of times smaller than the general retention. - Local data is deleted according to the local retention policy only if it has successfully been tiered.
- Remote data is deleted by the partition leader through a RLMExpirationTask that checks for delete eligibility every 30 seconds. When eligible, the plugin issues deletion requests to remove all associated data with a remote log segment
- Orphaned segments are cleaned up once their max leader epoch falls out of the leader epoch checkpoint file.
Reads
- Brokers serve data from the local disk first. If not found, they are served from the remote store.
- Remote reads are kept in purgatory and are executed by a separate thread pool for remote reads.
- Only one partition per fetch request is fetched from the remote store — a known limitation (KAFKA-14915).
- The plugin fetches exactly one chunk (not more, not less) via object stores’ byte-ranged GET feature. The size of the chunk is controlled by the
chunk.sizeconfig. - To figure out the exact byte position in the remote file to read from, the broker utilizes the offset index for the remote segment. This is fetched from the remote store and cached locally via a Caffeine W-TinyLFU cache so as to reduce round trips.
- Internally, a lazy input stream consisting of a chain of chunks is returned by the plugin. The broker reads each element (chunk) as it needs to.
- If enabled, any data read gets cached according to the plugin’s policy (disk/memory).
- If enabled, each input stream element invocation triggers pre-fetching, which caches data for anticipated future reads.
Conclusion
With the read and delete flows now uncovered, we’ve completed the deep dive into the full lifecycle of Kafka’s KIP-405 Tiered Storage internals — from upload to eviction and everything in between.
Thanks for reading. Special thanks goes out to Aiven's engineering team for building and maintaining a production-grade plugin for AWS, GCP, and Azure, and for reviewing this piece.
Tune in for our next piece, which will be a data-backed breakdown of how much money Tiered Storage can save you. It will feature hard numbers, intricate details, real-world configs and one spicy twist: why SSDs – counterintuitively – end up as the cheapest option of them all (while being more performant).
Tune in for our next piece, which will cover how much real money Tiered Storage can save you.
—
Check out the OSS plugin to start testing how tiered storage can revolutionize how you run Kafka. It's being used at petabyte scale in some of the biggest Kafka clusters around the world.
Review our last blog post in this series to see [16 ways that Tiered Storage Makes Apache Kafka Simpler, Better, and Cheaper](https://aiven.io/blog/16-ways-tiered-storage-makes-kafka-better).

Table of contents
- Introduction
- Tiered Storage Deletes
- How do Local Deletes Work?
- How do Remote Deletes Work?
- What About Unreferenced Files
- Leader Epoch 101
- Deleting Unreferenced Files
- Tiered Storage Reads
- Broker-Side
- Max One Remote Read
- Exiled in Purgatory
- Plugin-Side
- Chunk by Chunk
- Which Chunk?
- The Input Stream
- What About Latency?
- 1. One Partition Limit
- 2. Fetch Request Size Cap
- 3. Read Caching
- Concurrent Reads
- 4. Pre-Fetching
- How Pre-Fetching Works
- Recap
- Conclusion