


Tiered Storage for Apache Kafka® is a simple idea that goes a longway.
At its bare bones, it basically means: store most of the Kafka broker’s data in another server, e.g AWS S3.
On the surface, it sounds insignificant—like a minor architectural tweak with minimal impact.
The truth is that it is a groundbreaking new feature that, amidst other benefits, significantly eases difficult operational work, unlocks 13-115x faster recovery from incident scenarios, lowers latency all the while reducing your Kafka cluster’s storage costs by 3-9x.
In this article, we will dive beneath the surface and prove these claims that sound too good to be true.
The feature recently GA'd with Kafka 3.9 in November 2024.
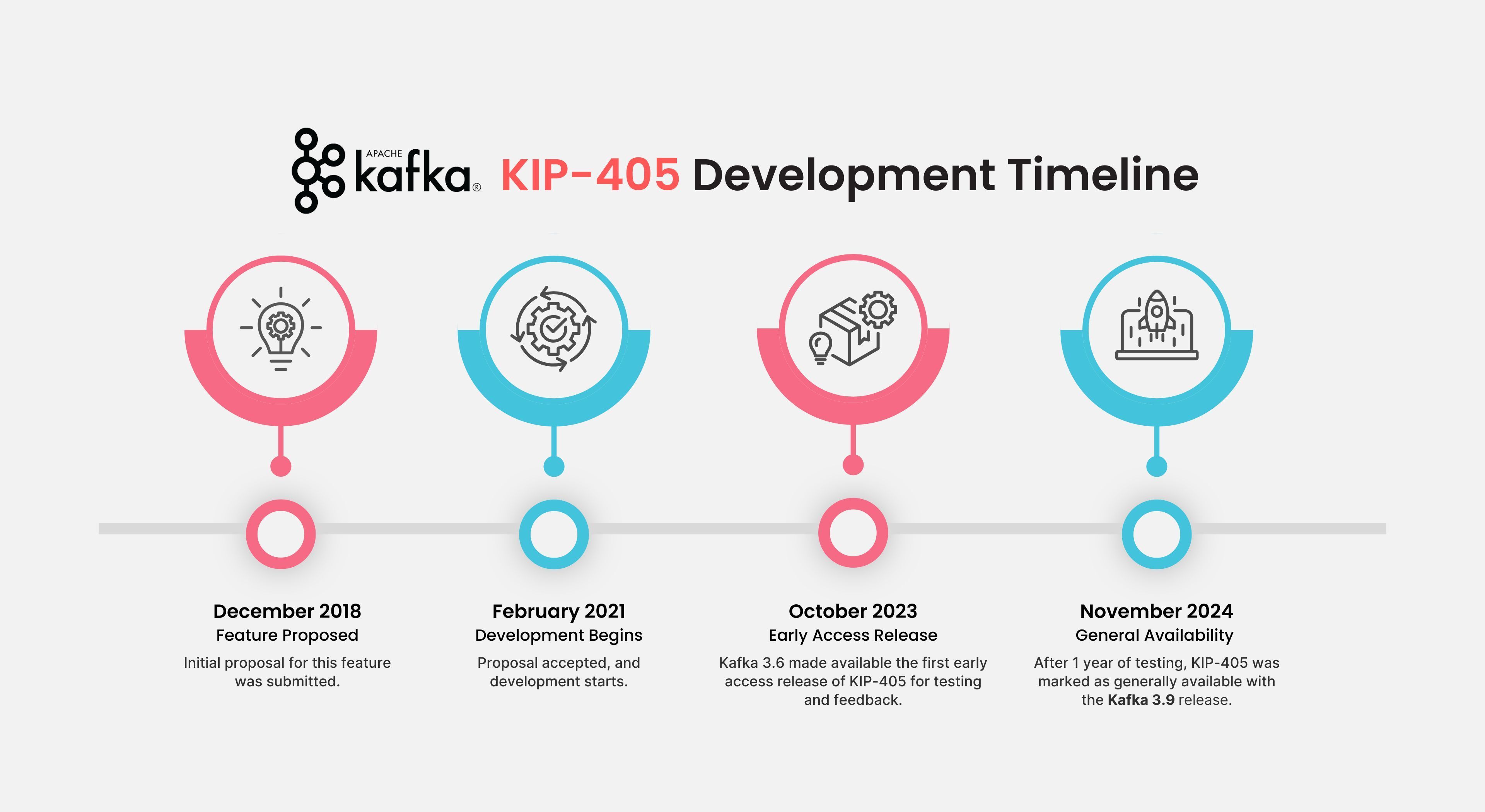
Despite the relatively recent release, the feature has been maturing for some time now. Industry leaders like Apple, Datadog, and Slack helped out and tested not only the core Kafka Tiered Storage functionality but also the open source plugin that was being developed for AWS S3. KIP-405 has been operating at GB/s scale in Aiven and is known within the community to have surpassed 150 GB/s in certain deployments.
To celebrate this release, we will publish a three-part educational series on the feature. In this first part, we will explain why the feature is, without exaggeration, groundbreaking. We will focus on the exact benefits of the feature.
Claims that tiered storage "won't fix Kafka" are simply untrue. While some vendors have claimed this and dismissed its impact, others, like Aiven, have recognized its potential and invested heavily in developing this feature.
In the next part of the series, we will focus on the technical internals and break down how it works. Finally, we will round off the series with an in-depth look at the massive cost savings the feature offers.
Grab a coffee and lock in.
Local storage no more
Unlike what some calculators make you believe, Kafka was made to run on HDDs. The idea was to run on inexpensive commodity hardware and scale horizontally. Storing a lot of data on an SSD works only if you have an unlimited budget. For the rest of us, it's not the best option.
One problem that was made apparent throughout the years is that this setup does not scale easily.
Modern cloud-native deployment models leveraging platforms like Kubernetes focused on stateless applications for good reason. They’re way easier to operate, elastically scale up/down to meet demand, and faster to restart for upgrades.
Kafka is fundamentally different - it's stateful, it has to be restarted/upgraded in a certain way and brokers aren’t exactly fungible - there’s only one leader your client can connect to.
While these fundamentals can’t be easily changed - you can still make a large difference by reducing the amount of state. It doesn’t make the system cloud-native, but it makes it more cloud native than before.
Both open source and proprietary projects learned from this overly-stateful mistake and began shipping their own form of separation of storage and compute.
So we get to the first benefit:
✅ 1. Tiered Storage allows you to scale your storage and CPU/throughput separately.
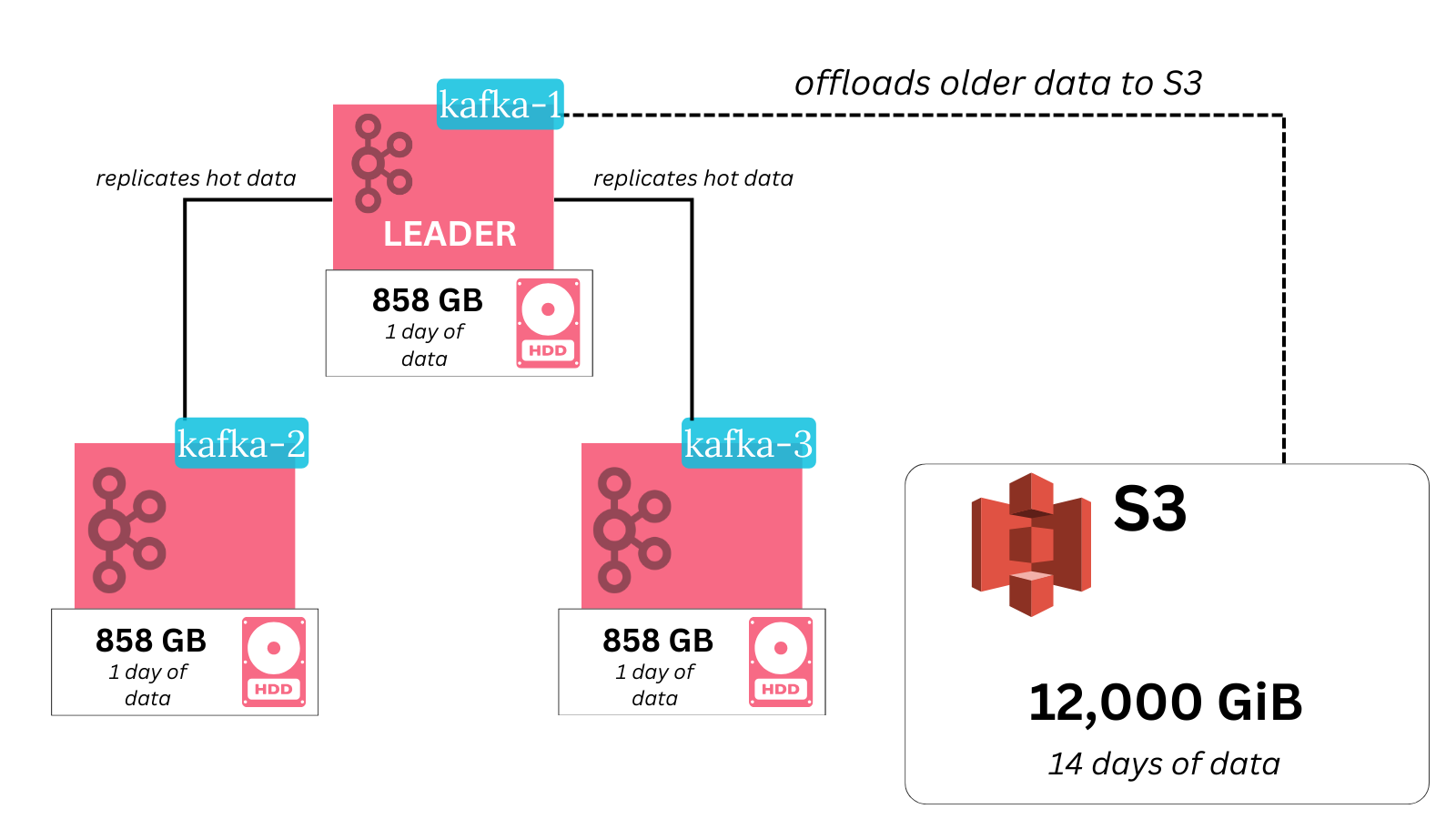
This is achieved by leveraging the wonderful nature of S3 and other blob stores. They’re exceptional pieces of engineering with a well-proven track record of storing ungodly amounts of data, while offering attractive features like unlimited capacity that scales elastically.
Now you’re able to scale your long-term data storage by doing … nothing. Just store more data in there. S3 is a bottomless pit - it automatically expands. This is significantly easier than adding new brokers with attached disks and rebalancing replicas to them.
Operations
Kafka didn’t get it wrong. Running on commodity cheap hardware is still a good idea. That’s how S3 works under the hood after all!
The only problem is that managing this state can be incredibly complex, riddled with pitfalls and gotchas. If you can outsource it to your cloud provider at a fair price - that’s a great trade. We now get to the second benefit:
✅ 2. Makes Kafka significantly simpler operationally.
Managing disks at non-trivial size is hard. It requires a lot of careful capacity planning which involves answering non-obvious questions like how much free space do I leave per broker? How do I ensure the free space is maintained?
Less local data
Having less local data per broker results in quite a few less troubles:
Fast recovery from failures
Everything in your Kafka cluster can fail.
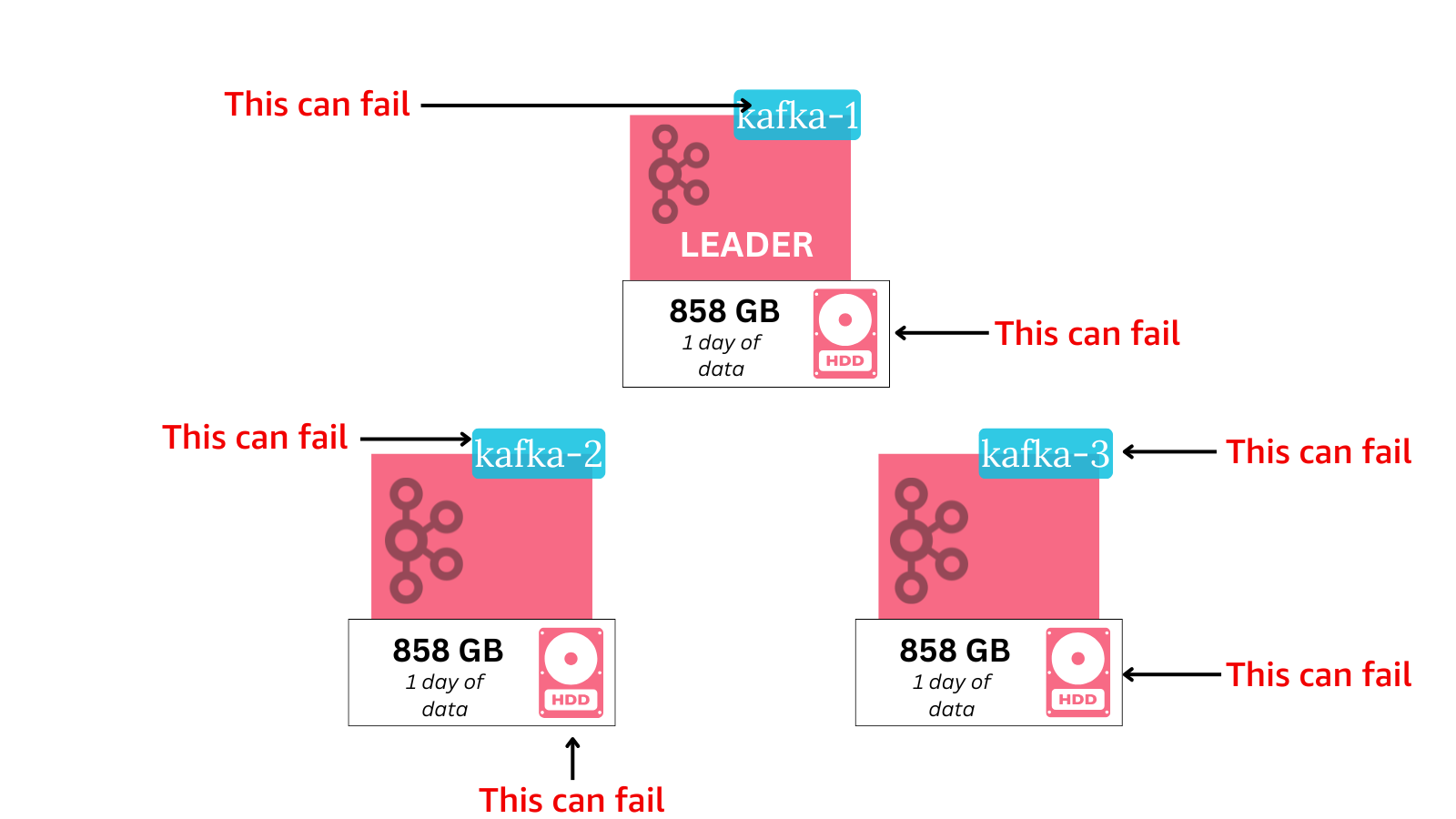
And each failure can take a long time to recover from - precisely because of the statefulness (and its size).
The recovery time is directly proportional to the amount of disk space stored.
✅ 3. Fast recovery from broker failure.
When the broker starts up from an ungraceful shutdown, it has to rebuild all the local log index files associated with its partitions in a process called log recovery. With a 10TB disk, this would take many hours.
✅ 4. Fast recovery from disk failure.
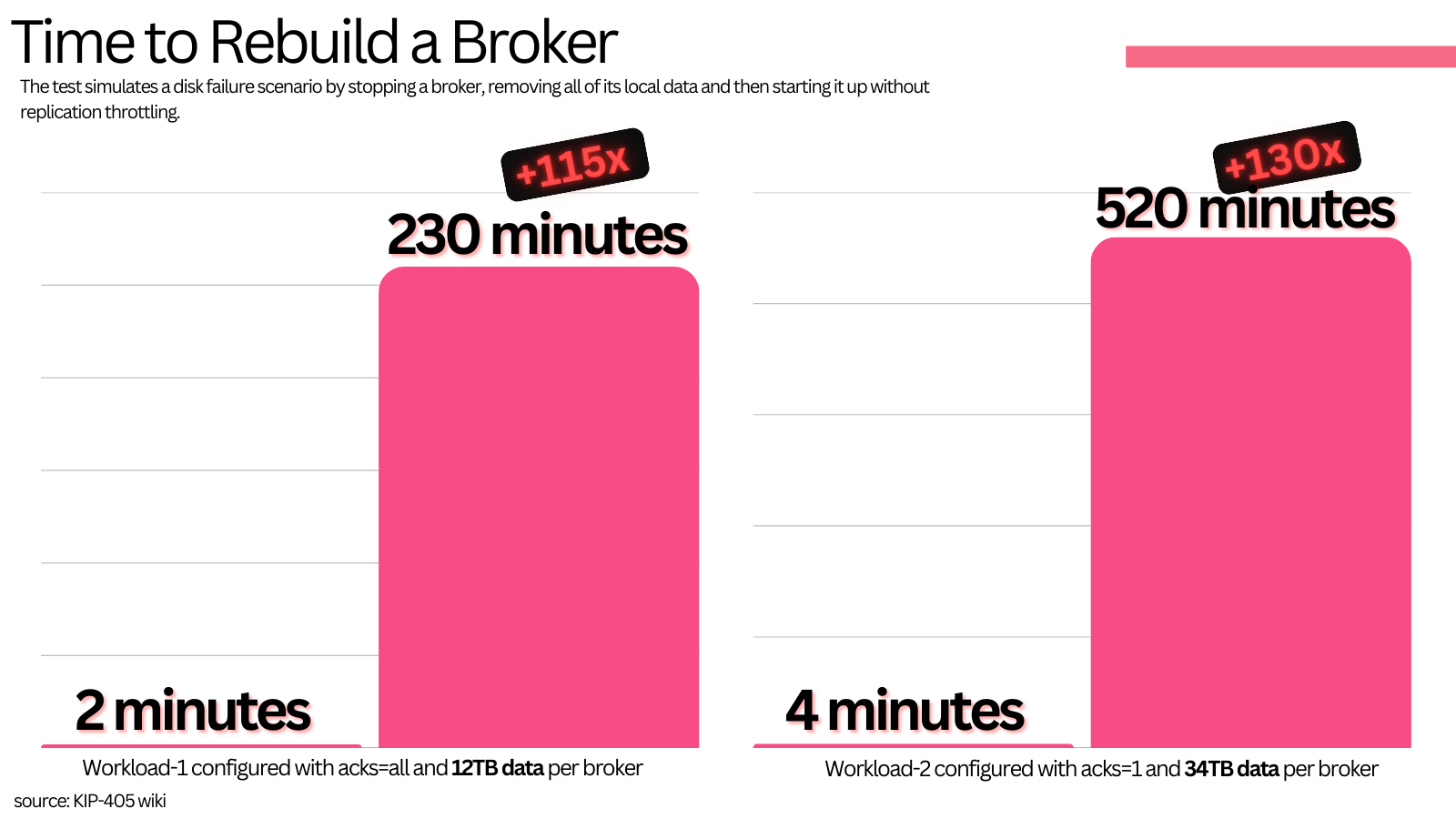
Similarly, if a broker’s disk becomes corrupt - it needs to be restarted with an empty disk. It therefore needs to replicate all the data it previously had from other brokers. This can be very concerning as it causes extra IOPS and general strain on the cluster. With a 10TB disk, this would take more than a day at a 100MB/s replication rate.
Tests from KIP-405 showed that such disk failure scenarios can be 11400% slower (2m → 230m) and can worsen produce latencies by up to 1160% (23ms → 290ms).
Faster state movement
State in Kafka comes from the partition replica.
A broker cannot serve reads or writes for a replica it isn’t hosting. And that’s what limits what clients can connect to the broker.
The ability to shift load across brokers is therefore dependent on your ability to move this state across brokers. And tiered storage definitely helps a lot here:
✅ 5. Tiered storage gives you fast reassignments.
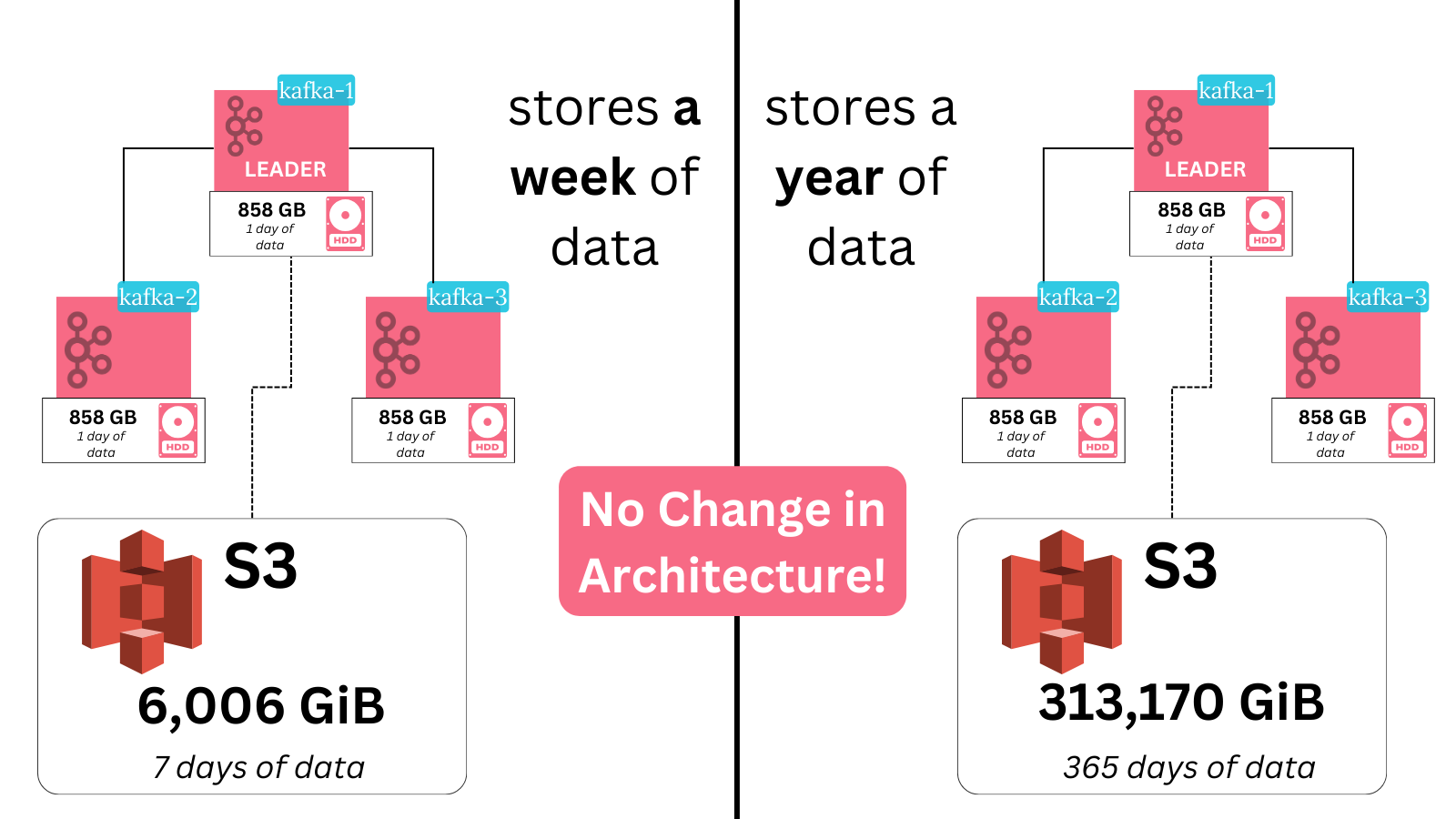
Because the vast majority of data is stored in the remote store, reassigning a partition can have you move just 7% of its total data (for example, if you have a 12 hour local retention rate and 7 day total retention rate)
If you want to reassign partitions, you have to move all the data associated with them.
With tiered storage, you only need to move the local hot data associated with it.
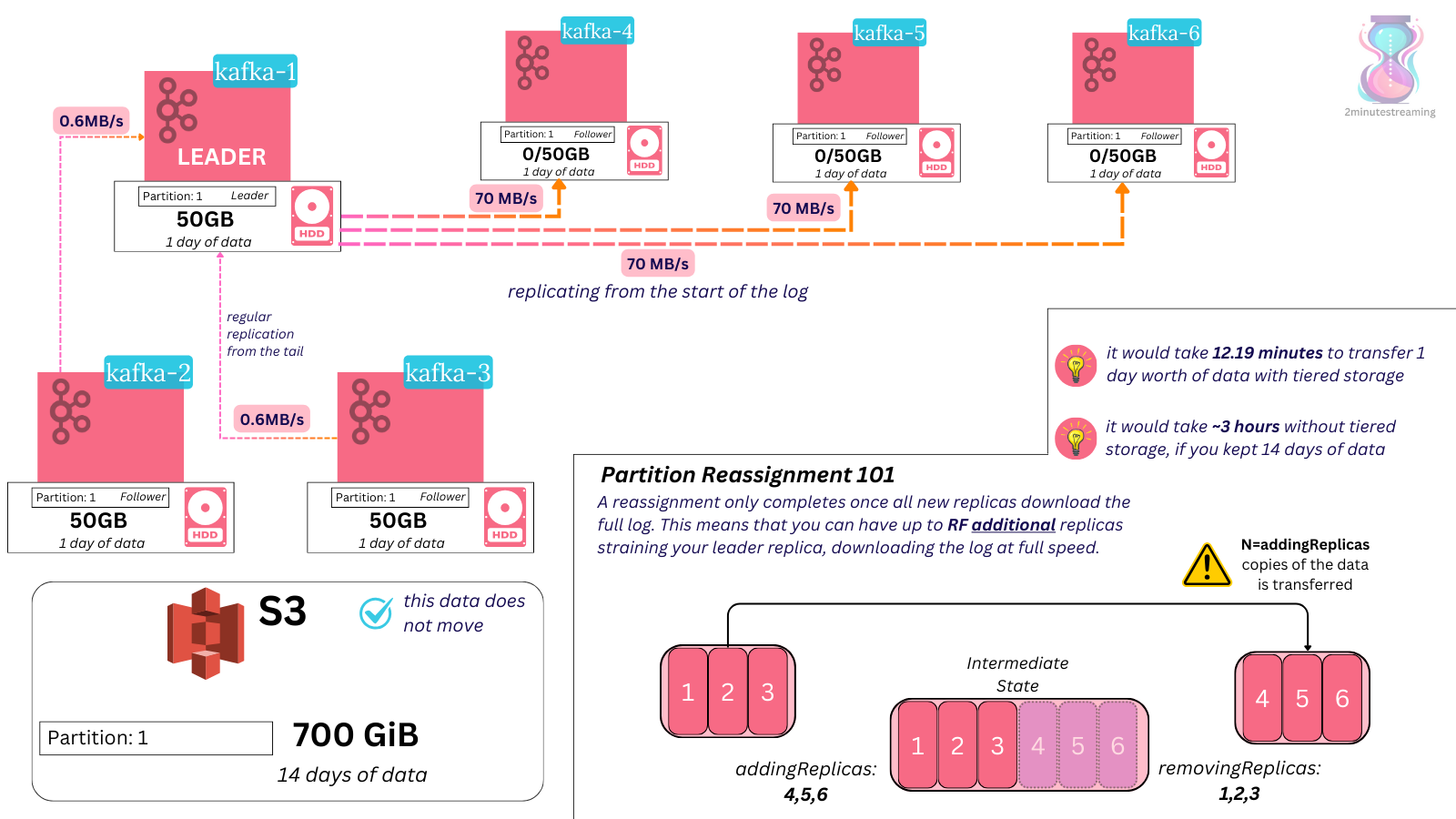
In the example above, a particular partition has 14 days worth of retention. With 0.6MB/s of data coming to it at all times, that’s 50GB of local storage and 700GB of remote.
If this partition gets reassigned to other brokers, and each new broker’s reassignments are running at a decent 70MB/s rate - you’re looking at 12 minutes total for the reassignment with tiered storage and close to 3 hours without.
This 15x decrease in reassignment times helps in both simple cases like moving a few partitions out of a broker that’s running out of disk as it helps in composite cases like adding new brokers or removing brokers from your cluster. 💡
✅ 6. Fast scale up/down: Moving less data per partition allows you to react to changes faster and have an elastic cluster that scales up and down according to workload.
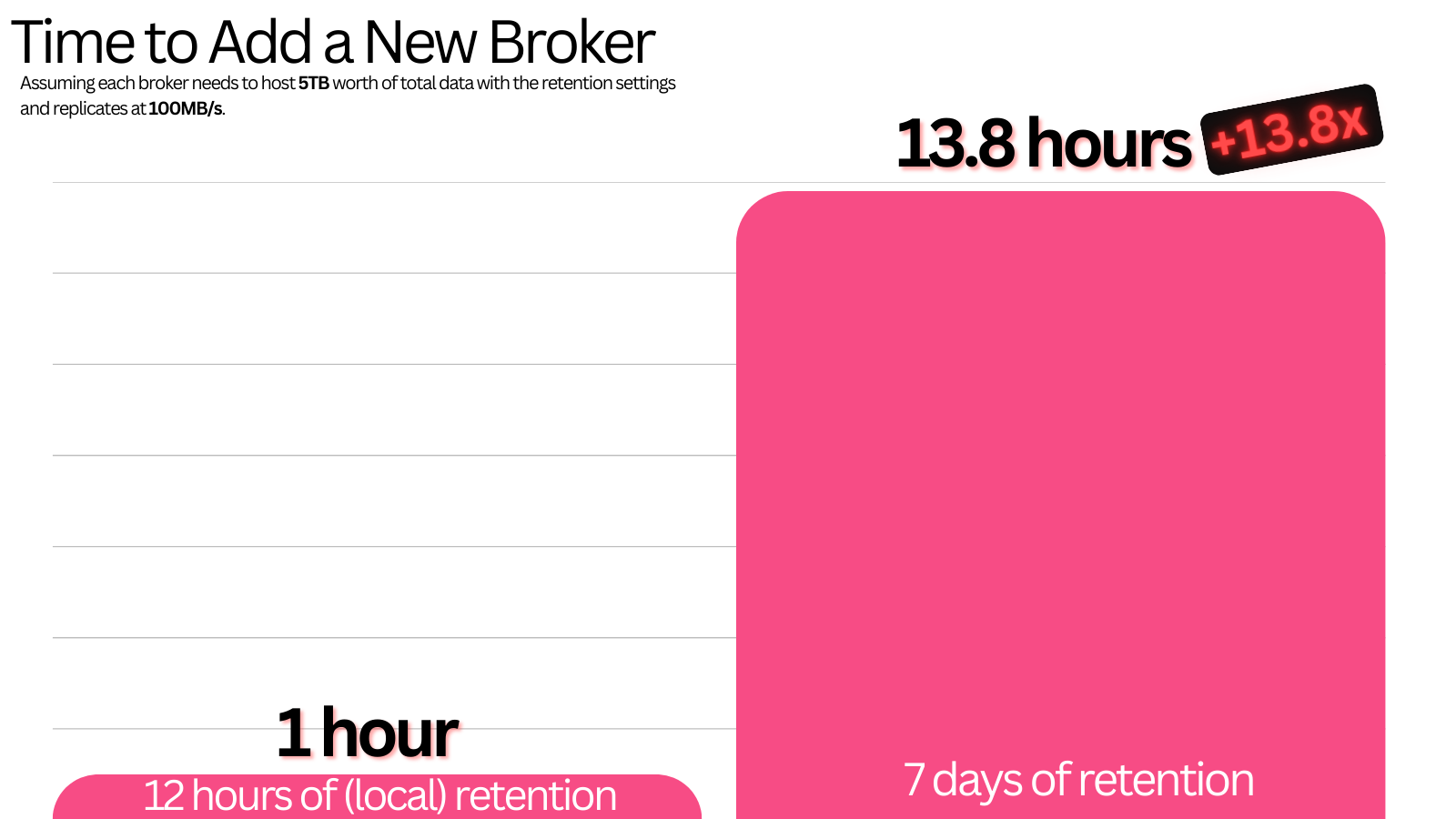
A simple 5TB disk on a broker can take 13.85 hours to move its data at a decent 100MB/s replication rate. You cannot react timely to any workload change with that.
In comparison, it would take just 1 hour with tiered storage. (or even less, if you opt for a more aggressive local retention rate). This timing allows for much better reaction to workload changes.
A worthwhile thing to note is that the cluster is under heavier load during these reassignments. While you can (and should) have reassignment throttles present, the new followers are still hammering the old leader for data all the time.
When reassigning more than just one partition, it ends up such that every broker is under additional strain. The faster you can get out of this situation - the better.
Local data minimalism FTW!
And just so, we showed how having less local data results in real ten-fold improvements in 4 very common operational issues that any Kafka operator has to deal with - broker failure recovery, disk failure recovery, single-partition reassignments and broker scale ups/downs.
There is a massive difference in something taking 10x less time to achieve.
The longer something runs under strain - the more chance for things to go wrong. This can require babysitting, taking away from key initiatives, and spending valuable (limited) engineering hours. More importantly, it reduces reliability risk. And not to forget - it unlocks new use cases that were previously unthinkable, like scaling up/down elastically based on near-term demand.
But the improvements don’t stop there.
Hard Drives
What made Kafka special was its ability to horizontally scale on cheap, commodity hardware - hard drives.
Throughout their inception, HDDs have evolved spectacularly.
In 1956, a 3.75MB HDD cost $9,000.
Today, you can buy 26TB drives where 1TB is worth ~$11.
But this benefit can also be an Achilles heel.
IOPS
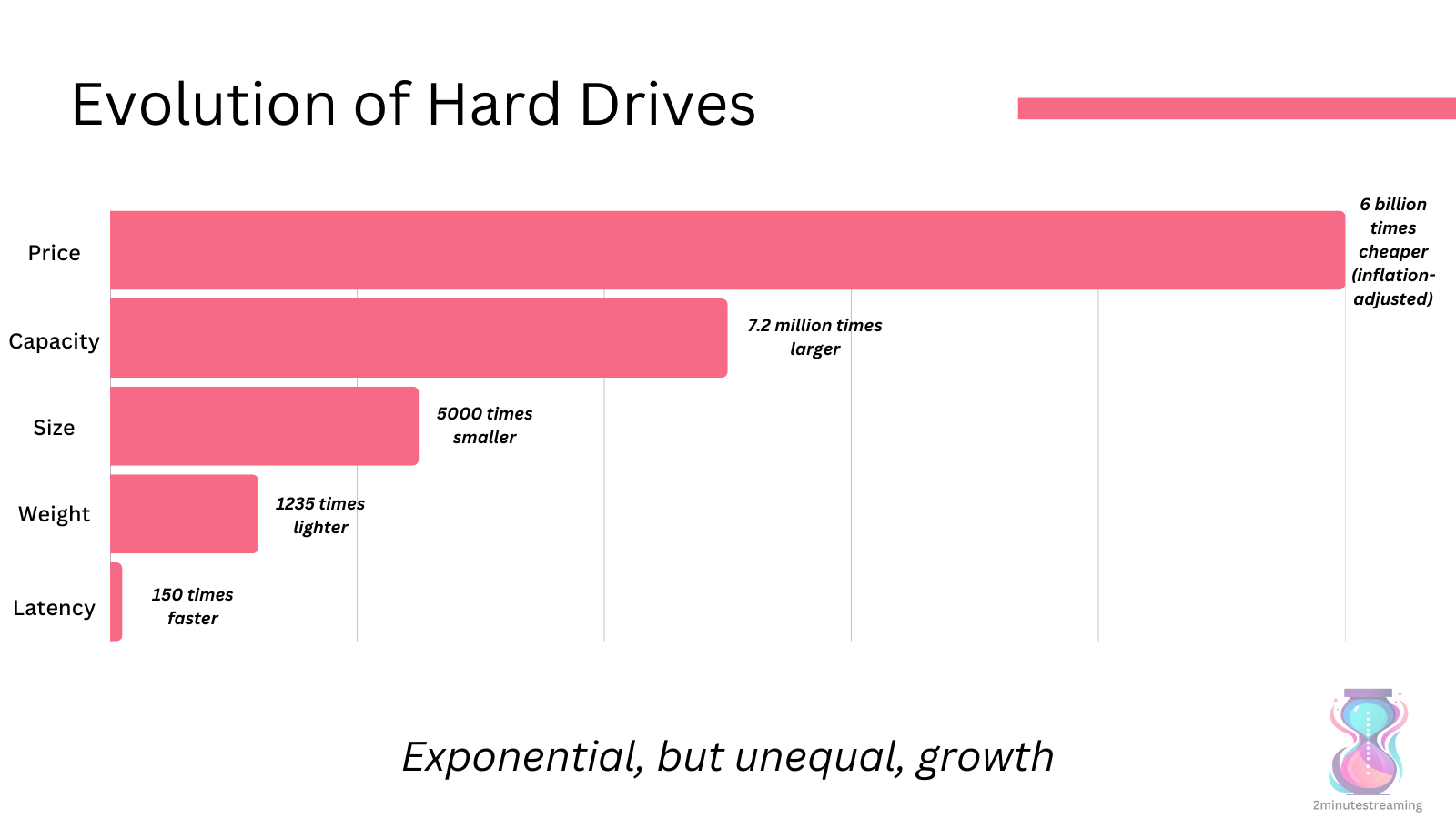
HDDs have improved exponentially, but not in all dimensions.
There are three main reasons they’re disfavored today:
- Their seek latency is high (speed is physically limited)
- They’re physically fragile.
- Most importantly - they’re constrained for IOPS.
While their capacity has grown multi-fold and their price has decreased alongside - HDDs have been stuck at around 120 IOPS for the last 2 decades.
What does this mean?
Per byte, hard drives are becoming slower.
The IO simply hasn’t grown to keep up with the capacity.
You may have a lot of data, but you’re becoming ever more limited in how you can read it
Kafka’s Use of IOPS
In the interest of brevity, we won’t go into much detail here. Succinctly said:
Kafka uses IOPS when it has to write to or read from the disk.
Writing to disk while producing/replicating is inevitable and takes up precious IO.
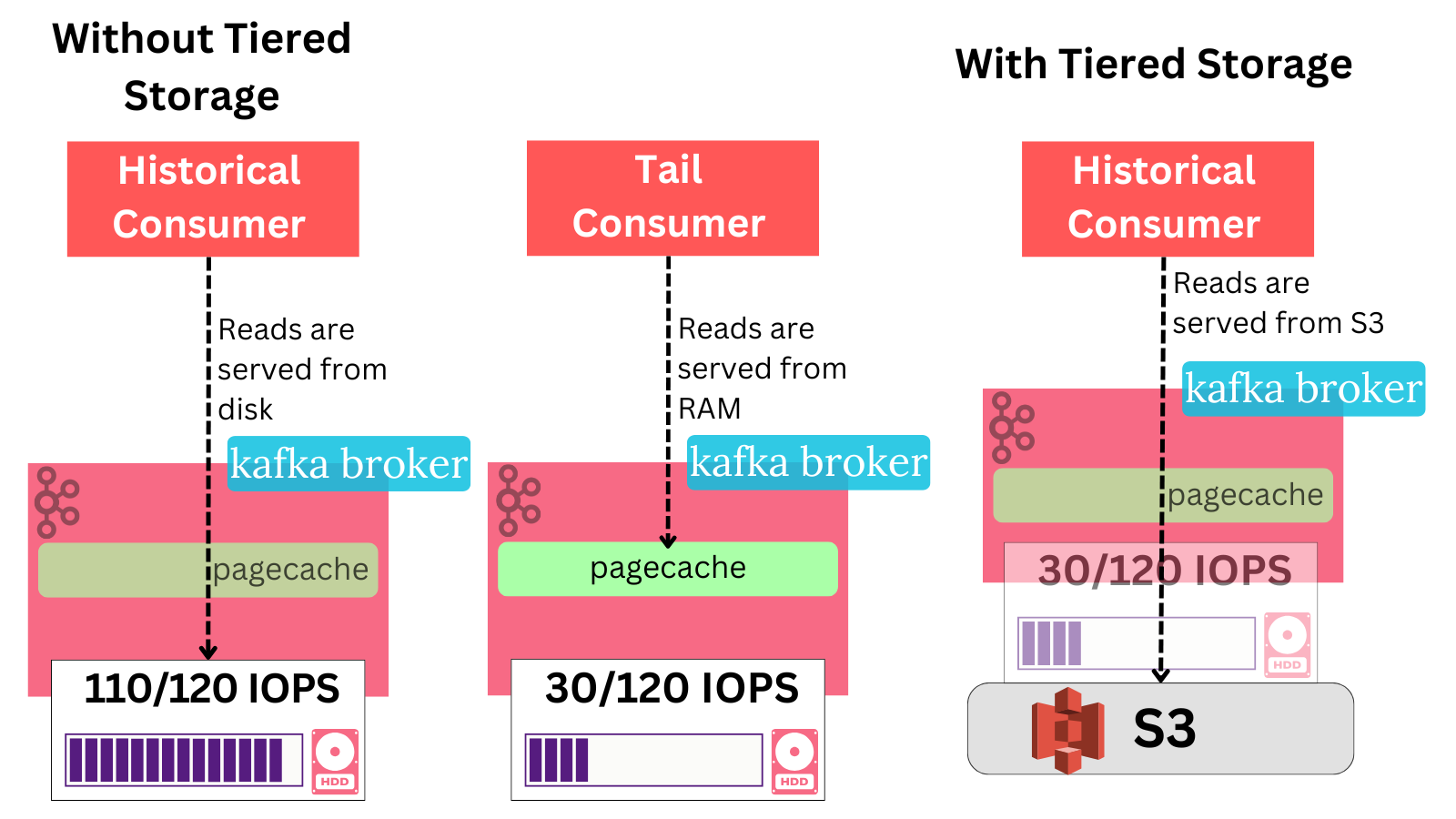
Reading from disk is more avoidable, as the log’s tail data that was just written is stored in the page cache by the OS and reads for that data can come from memory.
This is a reason why Kafka is deployed with a lot of spare RAM. Don't be fooled by the fact that the Kafka JVM doesn't use much memory - the OS is allocating the rest to page cache.
This memory also allows the OS to batch writes efficiently to use less IOs on the write side.
Why does this matter?
Because when you have just 120 IOPS per broker, you better make sure you’re not using too much!
When you run out of IOPS, latency starts growing massively. This can result in partitions’ follower replicas not being able to write to disk in time to keep up, and therefore falling out of sync. That then results in unavailability for your producers. Worse off - once you fall into such a situation, it’s not trivial to get out of it.
So with this short explanation out of the way - what can cause us to run out of IOPS and how does tiered storage help us?
Death by a Thousand Reads
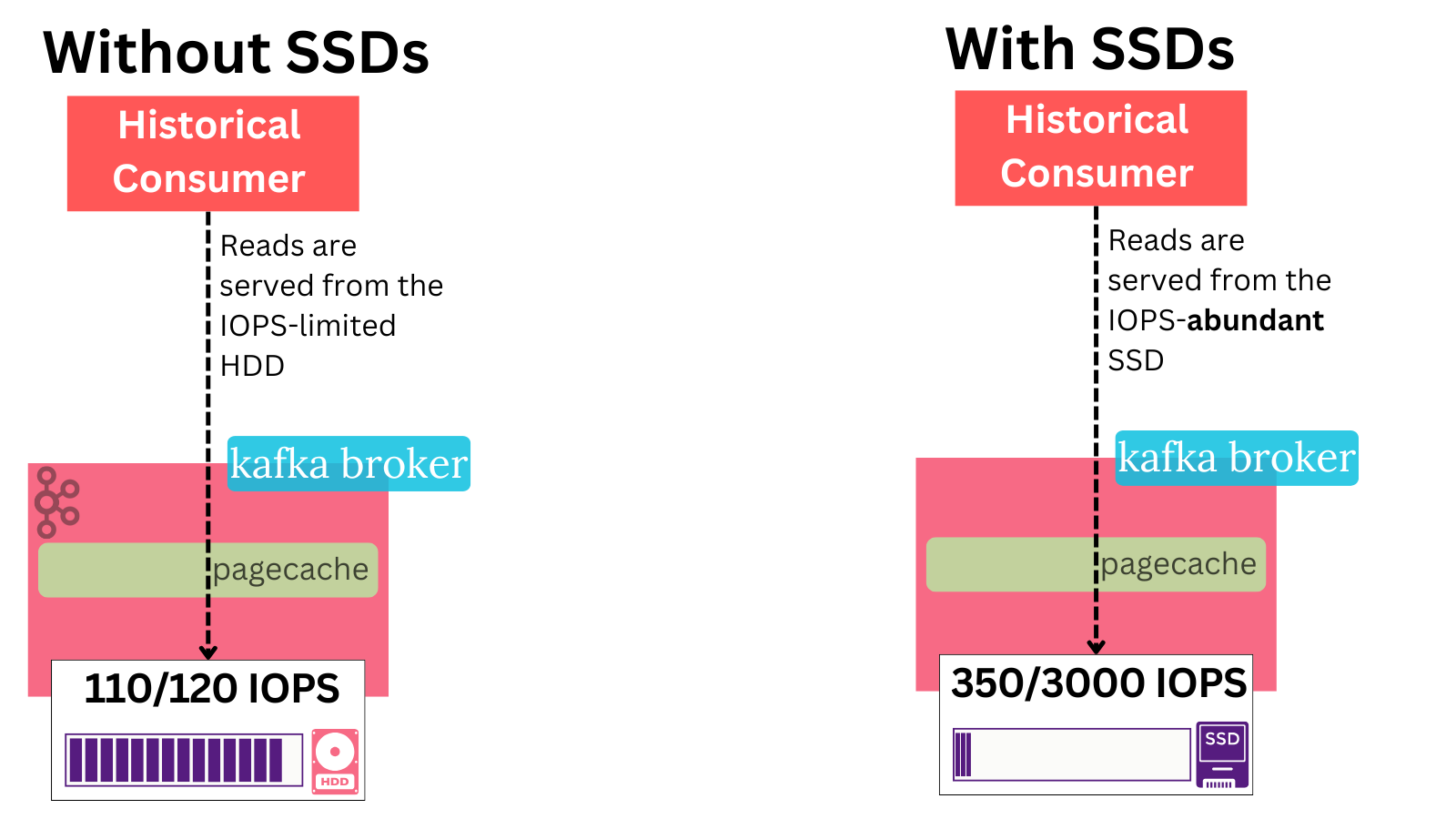
When a consumer requests records from an older part of the log that isn’t in the page cache - the Kafka broker is forced to read from its local HDD.
Simple, day-to-day batch processes that routinely read the full historical data in the log from the start to end can therefore put a real dent on the cluster’s performance. As an example, public tests from KIP-405 showed a 43% producer performance decrease when historical consumers were present without tiered storage.
With tiered storage, these reads directly go to S3 and skip the disk. This reduced p99 produce latency by 30%.
✅ 7. Tiered Storage makes historical consumer workloads less impactful: Because the reads no longer hit the disk and exhaust IOs, these workloads are less operationally impactful.
All 4 previous operational pain points we mentioned - broker failure recovery, disk failure recovery, single-partition reassignment and cluster scale-up/down (whole-broker reassignment) also take up precious IOs.
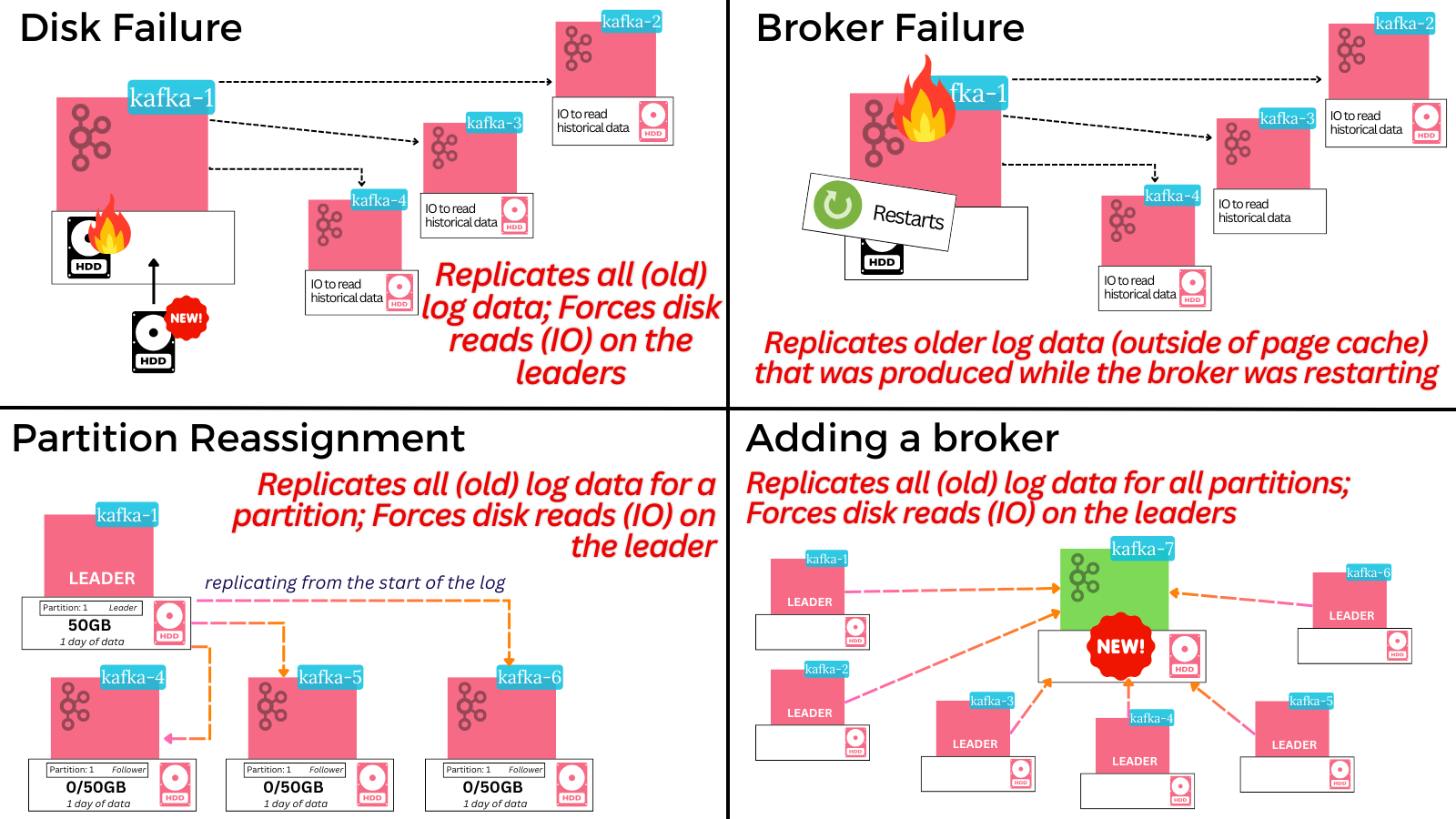
As Tiered Storage makes these faster - your cluster is IOPS constrained for less time.
✅ 8. Reduced IOPS impact window: The less data you move, the less time your cluster is strained for IOPS.
SSDs
Ok, so you’ve significantly reduced the amount of local storage on every broker and with that decreased the duration of the period in which your IOPS is impacted.
This also means you no longer need to keep 16TB drives on each broker just to store the data.
You can go down to 1TB or 500GB.
Apart from the HDD trend of price depreciation, there is another important tailwind trend to keep abreast of. SSDs are also in the middle of experiencing massive price deflation.
In the last 10 years, SSD costs have went down by more than 10x.
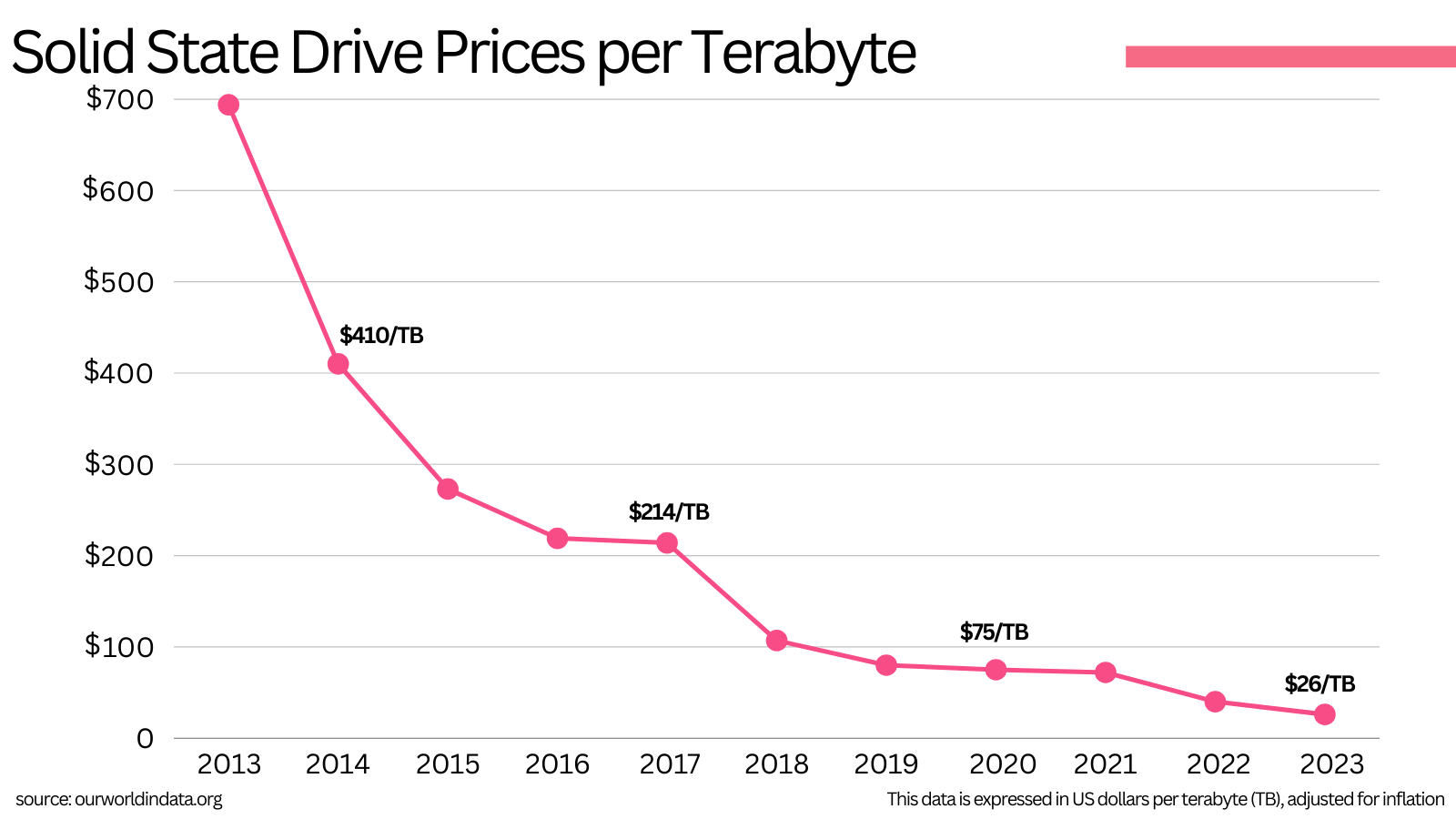
Today’s SSD prices are essentially equivalent to what HDD’s prices were when Kafka was first created 14 years ago.
Kafka was conceived to run on low cost hardware, and SSD is low-cost hardware today.
The structurally-lower SSD costs and lower need for capacity means that Tiered Storage allows us to completely alleviate the IOPS problem!
By deploying SSDs who have many multiples more of the IOPS capacity the HDD had, the Kafka broker can run with ample IOPS without fear of hitting that bottleneck.
✅ 9. Tiered Storage alleviates scarce IOPS problems by allowing you to deploy SSDs cost-effectively.
Boom! 💥
Just like that, Tiered Storage eliminated another major contention point of Kafka.
- broker/disk recovery
- slow reassignments
- historical reads
- any of the three above leading to IOPS exhaustion and cascading failures
Combined together, this set of problems are probably the most common operational pain points in Kafka.
A lot of other common incidents, like increasing consumer lag, can be downstream of this IOPS issue. At the end of the day, the problem stems from not enough resources. And the most frequent resource that gets bottlenecked in HDD Kafka deployments is precisely the disk.
As if that wasn’t enough - SSDs help us even more.
✅ 10. SSDs give Kafka lower latency for local data - an SSD can be much faster at random access than an HDD.
Most importantly - SSDs don’t suffer from high tail latencies as HDD do.
HDDs can easily result in hundreds of milliseconds of tail latency just like S3.
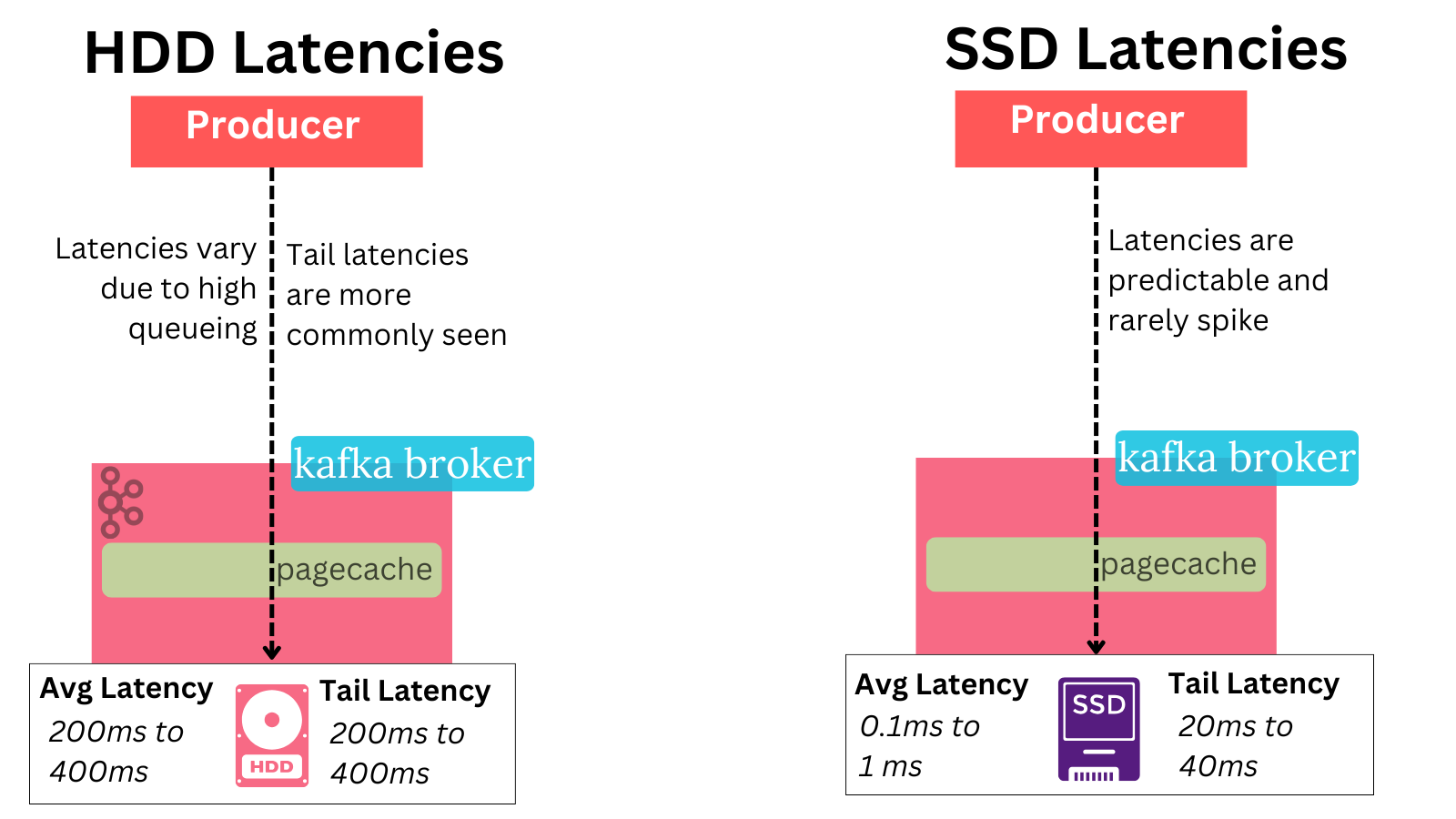
Therefore one should not expect a visible latency degradation when reading old data (that’s not in the page cache) with Tiered Storage. And - you can expect your tail consumers’ latencies to improve with Tiered Storage.
The end result is a net improvement:
- In the event the data is read from page cache, the latency is the same.
- In the event the data is read from local disk, the latency is better.
Scale Limitations
We mentioned in the beginning that Tiered Storage allows you to scale compute and storage separately.
Let’s explore how this affects your Kafka cluster in more detail:
✅ 11. No more maximum storage limit per partition.
Previously, you were limited by how much data you can store on a single partition.
In the extreme case, it could never be above what a single physical disk can handle.
In a more practical case, you couldn’t have partitions be too large because it would limit how many you can host on a single broker - and that can result in suboptimal resource usage on the broker. e.g if 10 large partitions fill up the broker’s disk, but don’t effectively utilize much CPU/IO/Network resources.
To be fair - this is a relatively niche problem. An example would be wanting to store months’ worth of ordered key data in a single partition.
With Tiered Storage, you’re no longer limited by your storage requirements. S3 handles all of this for you.
This leads to another benefit:
✅ 12. Cluster size is no longer determined by storage requirements (resulting in smaller clusters).
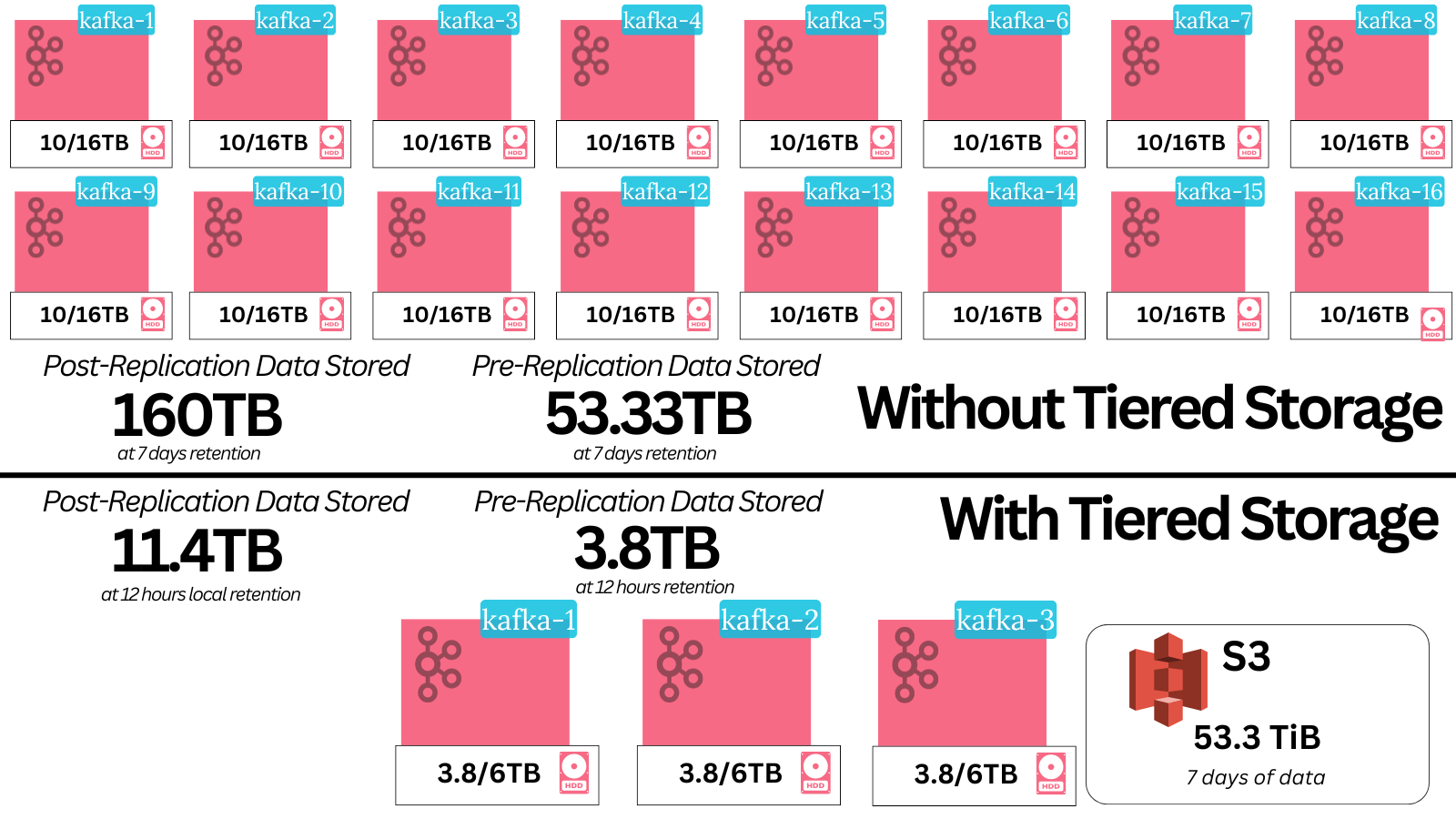
Previously, any deployment storing non-trivial amounts of data would have most likely needed to add more brokers solely because a broker is limited by how much data it can store. For example - most EBS drives go up to just 16TB.
When accounting for free space (e.g 65%), you’re left with just around 10TB of usable storage per broker.
One could use JBOD, but adding more disks to a broker comes at the trade-offs we mentioned in the Local Data section - absurdly slow reassignment times and the recovery operational pain points.
So in most practical cases, you had to horizontally scale your storage by adding new brokers.
This resulted in you paying for extra CPU/memory you didn’t need necessarily need, just so you can attach storage to an instance.
It also came with a higher maintenance burden for those extra nodes.
✅ 13. More flexibility in broker instance types.
The storage limitation prevented Kafka from running on large nodes, because the resources would be overkill when accounting for the total node count.
This was imperfect, because larger nodes give you more value for money and generally result in a cluster that’s easy to operate: a 12 node cluster with beefy machines is many times easier to operate, as well as cheaper, than a 60 node cluster with small machines.
Without the storage bottleneck, you can now deploy larger instances to handle your workload in a more cost-efficient way.
On the other hand, the usage of SSDs cost-effectively give you another type of instance flexibility - the ability to deploy smaller instances.
Kafka brokers can now be deployed with less RAM, resulting in cheaper instances. This is because reading from SSDs is fast and not bottlenecked on IOPS, therefore if their latency characteristics suit your requirements - you can rely on disk reads instead of page cache.
This removes the need for extra RAM, because what the RAM does is simply offloads and optimizes (batches) disk work onto the OS memory buffer so workloads are more IO efficient.
Finally, alleviating the storage bottleneck significantly improves operations:
✅ 14. Scaling up storage is much easier and less operationally burdensome. Storage is now incredibly elastic by using the best in class cloud-native primitive for storage (S3)
What do you do if you’re at the max size of your EBS drives (16TB) and you get a GDPR requirement to increase your retention settings across the cluster?
The cloud provider doesn’t allow you to scale the drives higher, so you’re forced to add new brokers and start reassigning.
You’re suddenly forced to pay for unnecessary extra RAM/CPU in the instances, and engage in a lengthy (potentially days) process of reassignments that result in extra IOPS strain on the cluster, potentially putting the cluster in a vulnerable state for days on end.
In such a case, it could take just one extra incident to topple the cluster over - be it a broker failure, disk failure or simply a heavy historical read workload..
But when storing the data S3, the only change you need to do is bump up the number of days in the remote retention config. The rest is handled automatically by the storage service.
Cost
We focused a lot on operational gains - and for good reason - there are a lot of them!
I want to end this with a bang - so let’s explore the amount of $ saved with tiered storage. Note we will focus more on this cost aspect in the third part of our blog series
✅ 15. Tiered storage gives you 3-9x cheaper storage costs.

S3 is very cheap relative to EBS. An EBS HDD costs $0.015-$0.045/GB whereas S3 is $0.021-$0.023/GB.
But there is a large difference that’s not accounted for - the S3 price is after accounting for replication and free space.
To store data on an HDD durably, you need to replicate the data. This ensures you don’t lose data if a drive or two fail. Kafka does this by replicating the data 3 times (replication factor) by default. This means you must pay for triple the gigabytes, so the HDD cost ends up being $0.045-$0.135/GB.
It doesn’t end there. If you’re managing the disk yourself, then you need to account for ample free space in the disk. This gives your engineers time for reacting to incidents and dealing with the issue before the disk becomes full and everything stalls. Let’s assume the disks are always forced to have 35% of their capacity in free space. This means that for every 1GB of data you store, you’ll need 0.54GB of extra free space. (35% of 1.54GB is 0.54GB).
This free space must be on all brokers, which means that the free space is paid for on each copy of the data.
1GB of producer data then results in 4.62GB of disk capacity - 3GB of replicated data and 1.62GB of free space, both spread across 3 nodes.
The actual cost per GB then results in $0.0693/GB - $0.2079/GB. This is $70.96/TB-$212.88/TB compared to S3’s $21.5/TB-$23.55TB.
The difference ends up being astounding - with EBS HDD being up to 9x more expensive to store the same amounts of data.
| Feature | S3 Storage | EBS HDD Storage (for Kafka) |
|---|---|---|
| Raw Storage Cost/GB | $0.021 - $0.023 | $0.015 - $0.045 |
| Replication | Included | 3x (required for durability) |
| Free Space Overhead | Included | 35% per disk, per replica |
| Effective Cost/GB (after replication & free space) | $0.021 - $0.023 | $0.0693 - $0.2079 |
| Effective Total Cost/TB | $21.5 - $23.55 | $70.96 - $212.88 |
And we haven’t accounted for the ability to reduce instances yet!
✅ 16. Tiered storage saves you money on instance costs when storage capacity is the bottleneck in a cluster.
Let’s run through a quick example for that too:
- Assume you want to store 100TB of data with a retention of 10 days. That’d result in 462TB of total disk capacity to be provisioned.
- Divided by a 16TB limit, that results in 29 instances. let’s use r4.xlarge instances, costing $2,336/yr.
- If you can afford to store 9 days of your data in S3 as opposed to locally, you now only need to store 10TB locally. That’s 46.2TB of total disk capacity.
- Divided by a 16TB limit, that results in just 3 instances. Let’s triple them to 9 instances assuming that’s all the resources we will need.
- Tiered Storage saved you an additional $46,720 a year in extra instance costs.
Conclusion
We went over sixteen benefits of Tiered Storage in this long blog post. Let us recap them quickly. We can group them into three categories:
1) Simpler Operations
Tiered Storage makes Kafka significantly simpler to run operationally, by
- ✅ Unlocking faster, less impactful recovery from broker failures
- ✅ Unlocking faster (115x faster - 230m -> 2m) * ** , less impactful recovery (12.6x faster produce latencies) * ** from disk failures
- ✅ Unlocking 15x**+ decreases in partition reassignment times (3 hours to 12 minutes)**
- ✅ Unlocking 13x**+ faster cluster scale ups and scale downs (13.85 hours to 1 hour)**.
- ✅ Making scaling up long-term storage an operational breeze by leveraging the cloud object store’s best-in-class elasticity. (literally just add more data)
- ✅ Reducing the impact window when straining the cluster by simply moving less data and being in that window for less time. (13-15x less time)**
- ✅ Alleviate common IOPS bottleneck problems by using SSDs cost-effectively (their price has gone down ~26x in the last 10 years)
- ✅ Reduces the number of brokers to manage when storage is the bottleneck. (e.g. 60 small nodes down to 12 beefy nodes)**
2) Better Service
Tiered Storage makes Kafka better by:
- ✅ Offering faster latency for local data - an SSD can be much faster than an HDD
- ✅ Alleviating limits on maximum data per partition.
3) Cheaper Kafka
Last but not least, Tiered Storage makes Kafka less expensive to run:
-
✅ Lowered storage costs by 3-9x** simply due to using a cheaper storage solution.
-
✅ Lowered instance costs (less instances) when storage was the bottleneck.
-
✅ Unlocked more flexibility in the instance type we choose for a broker. Essentially further unlocked the ability to vertically scale therefore getting more value for your dollar.
These numbers sound way too good to be true. But they are true: Tiered Storage makes Kafka simpler, better, and cheaper.
*- The above numbers are based on the official KIP-405 proposal document's test results
** - The above numbers are based on the example calculations we provide in this blog post.
Without exaggeration, when understanding the mechanics mentioned above, you cannot refute that Tiered Storage is a groundbreaking feature for Kafka that you need to be capitalizing on.
How often do you have one feature offer you this many benefits?
KIP-405 is a strong testament to the power of community and open source. We want to take this moment to thank all the contributors to the feature.
Together we can continue to make open source Kafka better.
We hope this article convinced you that it is a prudent decision to adopt KIP-405 today.
Adopt Tiered Storage today and check out the OSS plugin which is being used already at petabyte scale in some of the biggest Kafka clusters in the world.
Further reading
