


TL;DR;
KIP-1150 proposes a new class of topics in Apache Kafka that delegates replication to object storage. With disks out of the hot path, the usual pains— cluster rebalancing, hot partitions and IOPS limits are gone, while cross‑zone network fees and pricey local disks drop by as much as 80%. Because data now lives in both local disks and object storage, users can dial latency up or down per topic, spin brokers in or out in seconds, and inherit low‑cost geo‑replication for disaster‑recovery at no extra effort.
This can be achieved by modifying just 1.7% of the Kafka codebase (≈23k lines) and without changing any client APIs. You still keep your familiar sub‑100ms topics for latency‑critical pipelines, and opt-in ultra‑cheap diskless streams for logs, telemetry, or batch data—all in the same cluster. Flexible replication means Kafka stays future-proof — no matter the cloud pricing model thrown at it.
Getting started with diskless is one line:
Loading code...
If you’d rather skip the opinions and jump straight to the deep-dive design, check out the public KIP.
Awakening the Sleeping Giant
Why did Kafka win? For a long time, it stood at the very top of the streaming taxonomy pyramid—the most general-purpose streaming engine, versatile enough to support nearly any data pipeline: from event-driven architectures, logs, and metrics, to emerging use cases like queues and middleware.
Kafka didn't just win because it is versatile—it won precisely because it used disks. Unlike memory-based systems, Kafka uniquely delivered high throughput and low latency without sacrificing reliability. It handled backpressure elegantly by decoupling producers from consumers, storing data safely on disk until consumers caught up. Most competing systems held messages in memory and would crash as soon as consumers lagged, running out of memory and bringing entire pipelines down.
Ironically, the same disks that initially made Kafka unstoppable have now become its Achilles' heel in the cloud. Modern diskless architectures emerged, offering dramatic cost reductions and simplified operations by eliminating disks away entirely.
With Diskless Topics, Kafka's story comes full circle. Rather than eliminating disks altogether, Diskless abstracts them away—leveraging object storage (like S3) to keep costs low and flexibility high. Kafka can now offer the best of both worlds, combining its original strengths with the economics and agility of the cloud.
We have observed the market innovate with diskless designs, two years have passed since the first announcements and momentum has only picked up!
Although new to Apache Kafka, Diskless Topics isn't the first solution aiming at cost-efficient, higher-latency Kafka—it joins a crowded market of similar offerings. Yet, it's essential that Kafka embraces this approach to stay competitive and ensure the open-source community benefits directly.
As engineers, we don’t need to reinvent the wheel. We deeply appreciate the startups that paved the way before this KIP, solving many of the challenges we’ll face in the implementation. With Diskless, we have the opportunity to bring such proven efficiency gains directly into Kafka—and into the mainstream.
Diskless fixes two problems in Kafka
Pace of Innovation: Diskless could prove that even a giant, community‑run codebase can take a bold architectural leap now, rather than waiting years for a trickle of incremental updates.
Cloud Pricing Model: By removing disks from the replication hot path, we offer the flexibility to eliminate the most expensive components of running Kafka in the cloud.
Think about it: Up to 80% of Kafka’s total cost of ownership (TCO) in the cloud is tied to networking overhead (Warpstream has a killer writeup). Meanwhile, leading analysts like Gartner estimate the total dollars spent for streaming globally to be at least $50 billion. Put these two data points together, and it’s clear that if Diskless Topics become the default Kafka deployment model, the community stands to save billions on network and storage expenses. That’s an immediate ROI so large, it’s hard for us to ignore.
So we asked ourselves: can one of the biggest open source projects innovate like a startup? Can Kafka become drastically cheaper and autoscale as if it were built natively for the cloud from first principles? Can we save the community billions of dollars?
Let’s grab a coffee, and dive in to see how we're waking up the sleeping giant.
Who Says Giants Can’t Fly?
Apache Kafka is one of the most prolific open source projects in the world— yet being a community project it’s also an easy target. You’ve probably heard it all:
- “Kafka is slow — ours is 10x faster!”
- “Kafka is dead — KIPs take years to ship!”
- “Kafka is expensive — ours is 10x cheaper!”
- “Kafka is old — JVM is outdated!”
Though these narratives are expertly crafted, they're largely untrue—akin to watching a flat, two-dimensional movie in a genuinely three-dimensional world. They lack the depth and accuracy to truly capture reality. But we get it - we all need marketing and are fighting for eyeballs. So here is what our read of those is:
- While Kafka isn’t blazingly fast, many use-cases are happy with 100ms latencies and this can be tuned to less than 10ms
- Some KIPs can take a long time to ship, while others come fast - the important thing is that they ship, stay reliable, and are free (Open Source).
- Kafka can be expensive, but oftentimes vendors inflate the projected Kafka costs and compare disparagingly in order to stand out.
- Java is still the standard in enterprise software, and is seeing a lot of modernization
And here is the kicker - Kafka might not have a marketing team, but the Open Source implementation is the most used one with over 100k companies relying on it daily. In fact, if we go back to that >$50 billion spent on streaming , and given the vast majority of those organizations use Kafka, it’s safe to say Kafka has more bite than bark. Still, one issue has been undeniable: as the ecosystem grows, cloud costs for disk-based replication grow with it. And Kafka’s conservative-moving governance means truly game-changing features can take years to appear—if they arrive at all.
The truth is, most open source users face a tough choice: either shoulder the soaring costs of running Kafka in the cloud as-is, build a bespoke solution internally (assuming they’re lucky enough to have an amazing Kafka engineering team), or shell out and get locked into a Kafka-compatible system. None of these paths feel good to us — they all feed those disparaging narratives that Kafka is too expensive, too rigid, or simply stuck in the past. As more companies gravitate to specialized alternatives or custom hacks, Kafka’s position as the “universal” streaming engine grows increasingly tenuous.
Why Open Source Diskless?
Diskless will greatly benefit Aiven. We run one of the biggest Kafka fleets in the cloud with more than 3.7k dedicated Kafka clusters, streaming at >46 GiB/s. We need Diskless because it will save us millions of dollars in networking and disks just by upgrading our Kafka fleet.
So why would we bother to help the open source community since some of our leads are actually coming from Open Source Kafka? It’s about incentives - at Aiven we are not using Open Source Kafka, we ARE Open Source Kafka, so for us the answer is obvious - if Kafka does well, Aiven does well. Thus, if our Kafka managed service is reliable and the cost is attractive, many businesses would prefer us to run Kafka for them. We charge a management fee on top - but it is always worthwhile as it saves customers more by eliminating the need for dedicated Kafka expertise. Whatever we save in infrastructure costs, the customer does too! Put simply, KIP-1150 is a win for Aiven and a win for the community.
But the idea of the KIP goes beyond our immediate incentive. From an open source perspective, there’s a lot of wisdom in letting the market innovate first. Commercial vendors can act as Kafka’s unofficial R&D team, testing risky new architectures and spreading the cost of experimentation across many implementations. Once a concept proves viable, it can flow back into Kafka itself—much like how Tiered Storage started as a differentiator, then evolved into a core feature of open source Kafka.
Diskless Topics, in our view, is the next inevitable leap. We’d rather help the community stay ahead of the trend than scramble to catch up later. By absorbing market-proven features, Apache Kafka remains competitive and retains its powerful network effect, which in turn supports every vendor building on top of it.
It is our sincere hope that the KIP creates shared “turf” on which engineers will collaborate. We aim to foster an environment where everyone feels comfortable that they're tackling the same challenge.
The keen eye will notice that we took great care in writing the proposal, splitting it into multiple smaller KIPs. This was done with intent to reduce friction and accelerate conversations on the different components of the improvement proposal. We don't want perfection to be the enemy of good - we want a good solution to reach the hands of as many open source practitioners as possible, ASAP.
We truly believe that with enough velocity and a runway long enough even giants can soar.
Money Doesn’t Grow on Clouds: Fixing Kafka’s Sky-High TCO
Let’s cut to the chase: running Kafka in the cloud isn’t cheap—and inter-AZ replication is the biggest culprit. There are excellent write-ups on the topic, our favorite one is Stan’s. We won’t bore you with yet-another-cost-analysis of Apache Kafka - we all agree it costs A LOT!
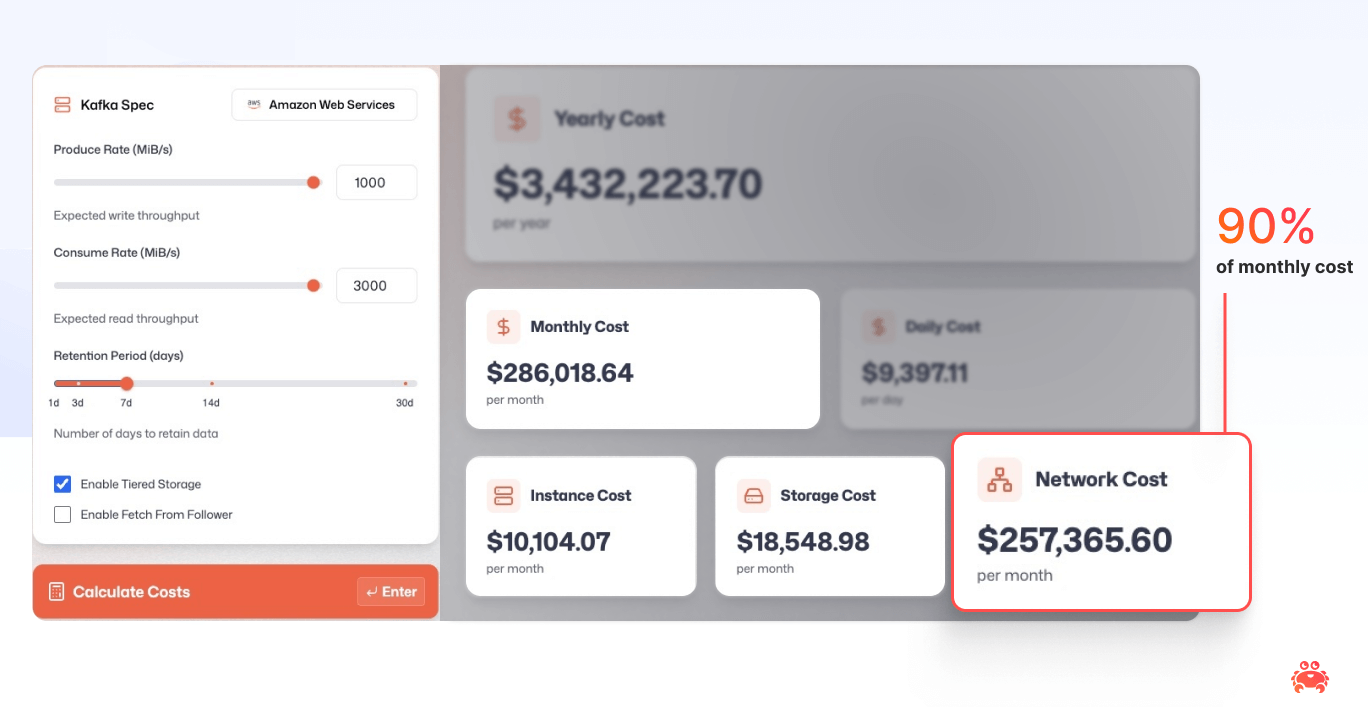
But why is Kafka so expensive in the cloud? As engineers we are trained to think about the problem behind the problem, so if we squint, is Kafka's replication model the real problem here? We don’t think so - it's been a great architecture and enabled Kafka to dominate the market for over a decade. Unfortunately what made Kafka so good also happens to be heavily taxed by the cloud providers. The real culprit is the cloud pricing model itself. Today, we pay through the nose for cross-zone traffic; tomorrow, that might change. Who knows? Maybe block storage will magically offer multi-zone durability at a fraction of the cost. That’s why we want to keep good old topics around—Kafka should survive no matter how the cloud’s pricing models evolve.
It might sound ironic, but object storage (like S3) isn’t just “storage”. It’s a load balancer and a durably replicated system rolled into a single API. That’s why Diskless uses object storage as Kafka’s primary replication engine—chopping out the most expensive piece of cloud overhead: repeated cross-zone block replication. When we benchmarked Diskless, we saw how batch size drives the cost‑latency trade‑off. Small blocks (~100 KB) deliver snappy latencies but rack up thousands of objects‑store PUTs; giant blocks (~10 MB) cut request fees but slow single‑message reads. For many mid‑range Kafka workloads, a 1 MB block lands in the “Goldilocks” zone—about 200‑400 ms end‑to‑end while still trimming cloud costs by roughly 80 % compared with classic replication. We’re still experimenting and will upstream the most sensible defaults to Apache Kafka, but if you want to run the math yourself, this tuning calculator is a great place to start.
Here’s a standout finding from our simulation: Diskless delivers its most dramatic financial advantage for workloads needing minimal data storage after completion. We measured cost reductions reaching up to 90% in these scenarios – effectively eliminating most of the expense for 'run-and-done' type tasks. Cost breakdowns is such an interesting topic of Diskless Kafka that it deserves a dedicated blog post in the future.
Sure, lower bills are amazing. But once replication is flexible, Kafka itself can reach a new level of agility, let's take a look:
- Autoscale in seconds: without persistent data pinned to brokers, you can spin up and tear down resources on the fly, matching surges or drops in traffic without hours (or days) of data shuffling.
- Unlock multi-region DR out of the box: by offloading replication logic to object storage—already designed for multi-region resiliency—you get cross-regional failover at a fraction of the overhead.
- No More IOPS Bottlenecks: Since object storage handles the heavy lifting, you don’t have to constantly monitor disk utilization or upgrade SSDs to avoid I/O contention. In Diskless mode, your capacity effectively scales with the cloud—not with the broker.
- Use multiple Storage Classes (e.g., S3 Express): Alternative storage classes keep the same agility while letting you fine‑tune cost versus performance—choose near‑real‑time tiers like S3 Express when speed matters, or drop to cheaper archival layers when latency can relax.
All this without forcing you to migrate or abandon the Kafka ecosystem you already know and love.
Diskless design principles
On a high level, Diskless doesn’t tear Kafka apart; it carefully extends the existing design by introducing a new topic type that coexists alongside the traditional (replicated) ones. This lets you run both Diskless and Kafka topics in the same cluster, without breaking any of your existing tools or workflows.
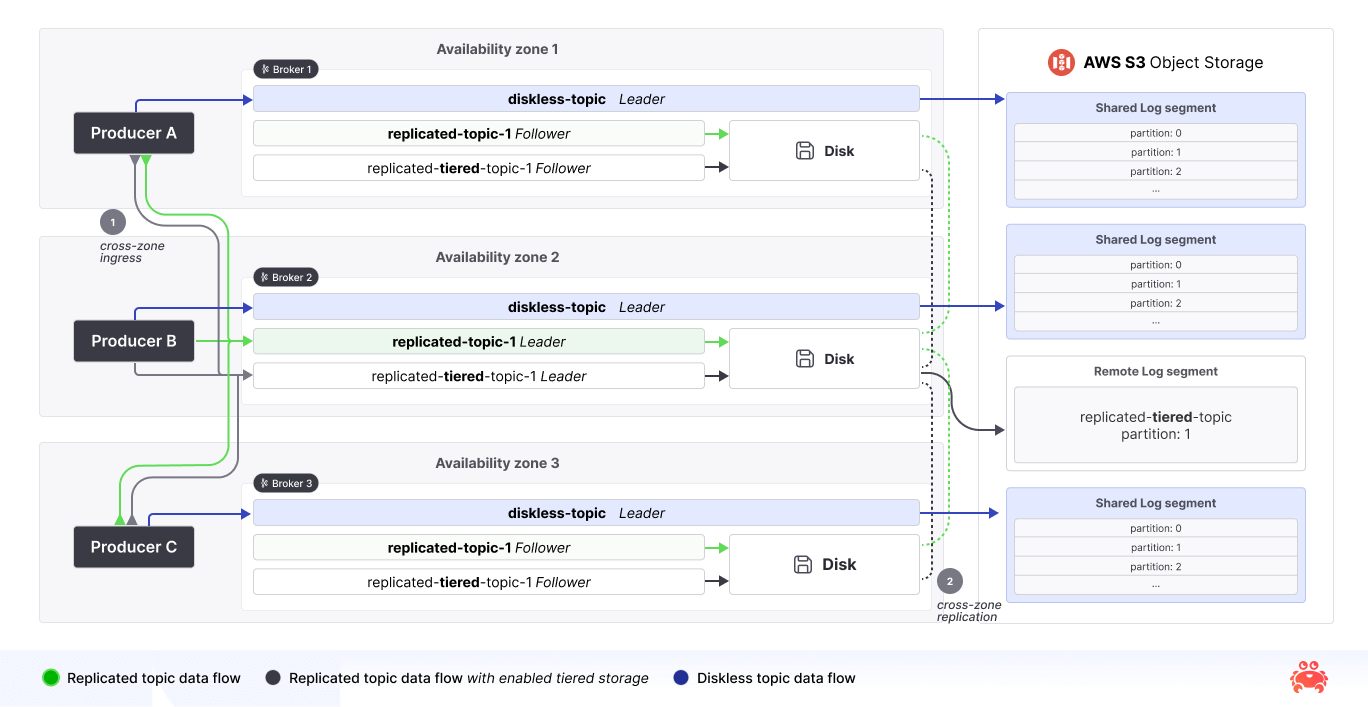
The key to the KIP is the intention to leverage the scale and reliability of cloud-native engineering marvels like S3, DynamoDB or Spanner—whose teams dwarf our own—we effectively get to have our cake and eat it too: lower costs, fewer operational headaches, and a feature set powered by enterprise-grade cloud services, what's not to like? With this in mind we adhere to six core principles:
Diskless is built-in Kafka: users will just flip a switch per topic to write through to object storage. This builds on top of Kafka regardless of the underlying framework or vendor.
Upgrade, not Migrate: As a result of Diskless being built-in Kafka, users just need to upgrade their clusters and start creating Diskless topics alongside their existing streams. Eliminating costly migrations and tradeoffs.
No breakaway forks: Diskless is specifically designed to be upstreamed with minimal merge-conflicts. If Kafka is diskless, this concentrates the efforts on a single solution—just like Tiered Storage, which united the community for everyone’s benefit.
Diskless topics are Kafka topics: We designed Diskless topics to be indistinguishable from Kafka topics. Streaming apps can be moved from Kafka to Diskless without changing client versions, application code, or experiencing correctness problems.
Diskless replicates in object storage: Diskless topics store data solely in object storage, rather than in segments on broker disks.
Leaderless design: All brokers are capable of interacting with all diskless topics, and no broker is uniquely considered the leader of a partition, enabling fine-grained client balancing while eliminating hot spots and inter-AZ traffic.
It’s still day 1 for Kafka
We’ve covered a lot — some opinions, a short technical overview (our technical deep-dive is coming soon), and perhaps a fresh perspective on the replication path within Kafka itself. If Diskless (KIP-1150) wins community approval it could fundamentally reshape the streaming design space. Crucially, by lowering the cost for streaming, Diskless expands the horizon of what is streamable, making Kafka economically viable for a whole new range of applications. This unlocks capabilities we’re only starting to fully grasp. Imagine unifying file formats across both Diskless and Tiered Storage, making all your streaming data instantly searchable right in object storage. Or spin-up an Iceberg-native topic, eliminating the need for analytics Kafka consumers—possible only because data now lives affordably in an object store, not just local disks. And as cloud pricing inevitably shifts, why not seamlessly "un-diskless" a topic or flip its storage class, perfectly matching cost to need?
A year (or two) from now, we might look back on “Diskless Topics” as the turning point. By solving the cloud inefficiencies and constraints that hamper Kafka on hyperscalers, KIP-1150 could redefine the “standard” Kafka deployment in the cloud. If you’re skeptical, great—this KIP absolutely invites your heated comments, your side-eye, and your war stories about replication meltdown. It’s all part of the process.
But if you’re excited (and you should be), now’s the time to jump in, read the KIP, leave feedback, and help shape the future of Kafka’s replication model.
