


Tiered Storage 101
The idea behind KIP-405 is to simply store most of the cluster’s data in another service.
As we covered in detail in the last article - it’s a simple-sounding idea that goes a very long way.
This other server where the data gets stored is pluggable. KIP-405 was designed in such a way to make Kafka seamlessly extensible to store its data in any kind of external store through a solid interface.
With KIP-405, Kafka now has two tiers of storage:
- Local (hot) data kept in the broker’s disk
- Remote (cold) data kept in the external store
This is an internal detail that’s completely abstracted away from the producer and consumer clients. However, for the responsible Kafka administrator, understanding these details is crucial. In this article, we will be exploring the inner workings of Tiered Storage.
Plugin
To examine the complete end-to-end paths, we will need to choose a plugin, as the logic is distributed across both Kafka’s codebase and the plugin.
We are going to be focusing on the only one Apache-licensed open source plugin for KIP-405 that supports all three major cloud object stores - Aiven’s. Said plugin is used throughout Aiven’s Kafka fleet, which makes it the most battle-tested out there.
Aiven was always a firm believer in the impact that Tiered Storage could make on Kafka. They started working on the plugin as an internal experiment in March 2021, just a few weeks after KIP-405 was approved. KIP-405’s development slowed and so did the plugin’s, but in 2023 work was resumed with the plan of ensuring the community will have a production-grade plugin by the time KIP-405 releases. After investing over 4,000 engineering hours to enable Tiered Storage on its platform, Aiven donated the plugin to the community by open sourcing it with an Apache V2 license. Their idea behind this was to reinforce the strength of open-source Kafka.
Basics
Simply put, the way Tiered Storage works is it asynchronously tiers data to an external store. Because of that, it temporarily keeps both a local and a remote copy for a subset of the data.
Reads can come from either the external store or the local data, with preference always being the local one. In other words - if the data is still locally on the broker, the read will be served from there.
How does this tiering happen?
A new RemoteLogManager class is responsible for managing the log at remote locations. It runs on every broker.
- leader replicas: It persists old log segments to the tiered store. It deletes expired data from the tiered store.
- leader & follower replicas: It reads the log from the tiered store to serve consumers reading historical data.
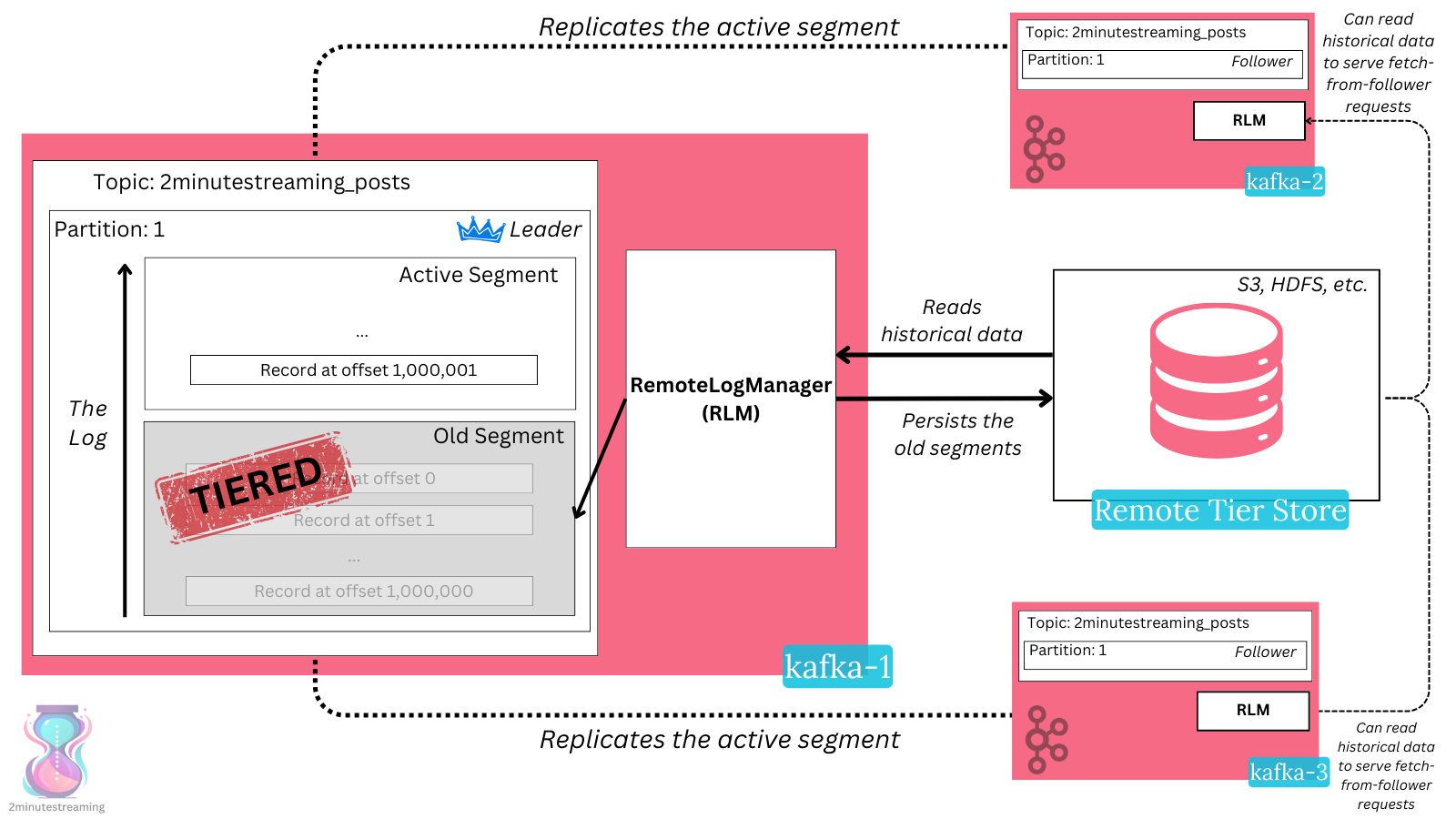
Common configurations ensure that the data retained locally is much smaller (7-14x) than the one kept in the remote store. With KIP-405, a new set of retention settings denote how long a local log (on the broker) should be kept:
local.retention.ms/local.retention.bytesdenote the local log retention.
The original retention settings we’re all familiar with (retention.ms and retention.bytes) now denote how long the data should be kept in the remote store.
Glossary
Throughout this article, we'll be using a few terms that are good to define in a single, easy to refer paragraph.
We’re going to be using a few words throughout this article, so it’s best to have a single place to refer to them:
- Tiered Storage - the feature that KIP-405 introduces.
- External Store - the secondary cold storage system to which the data gets tiered. This is most commonly a cloud object store like S3, Google Cloud Storage, or Azure Blob Store.
- Segment- a regular log file in Kafka that stores the partition’s data.
- Chunk - one small part of a segment - a subset of its data. (e.g 4 MiB out of the 1 GiB segment). It is a concept that is specific and internal to Aiven’s Tiered Storage plugin.
Tiered Storage Writes
To best understand the system end to end, let’s start from the entry point. How does data enter the remote store?
Recall that in Kafka, the log is split into multiple files (called segments).
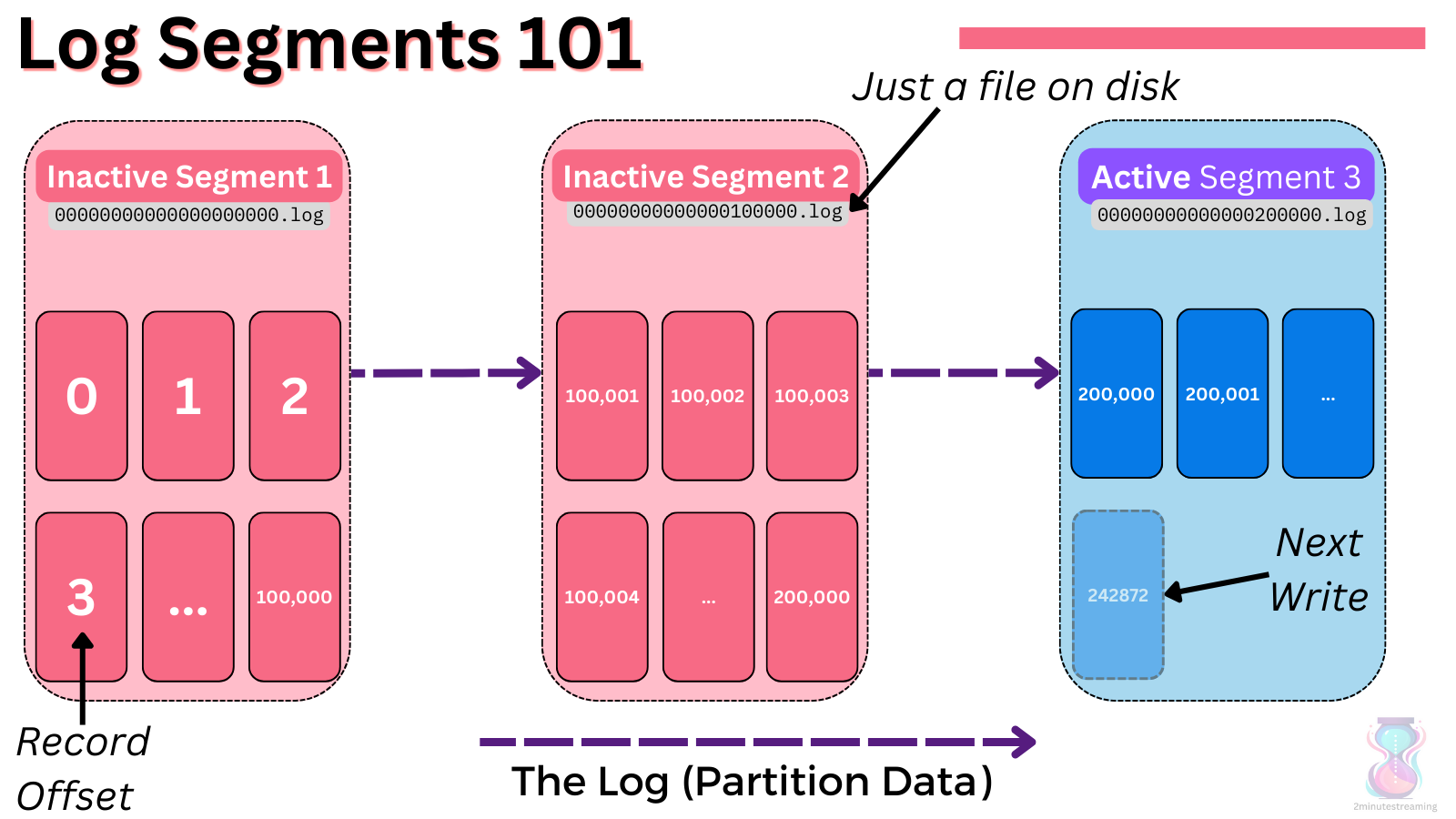
At any one time, there is only one so-called “active” segment. This is the open file that the latest data is appended to. After a configurable size/time threshold passes, the segment gets “closed”, and a new active one is created.
When to Upload
Tiered Storage only considers non-active segments for tiering. These files are uploaded in a sequential manner per partition - there can be no gaps in segments that are uploaded. (e.g for segment 4 to be in the remote storage, segments 1,2,3 must have been uploaded already)
The class that does this is the RemoteLogManager. For every leader partition in the broker, every 30 seconds, a RLMCopyTask runs in a special copier thread pool that’s used for uploading to the external store. It, just like all the other thread pools we will mention today, defaults to ten threads.
The RLMCopyTask tries to upload the data to the remote store, if the requirements to do so are satisfied.
The requirements to upload a segment to the external store are as follows:
- It must not be an active segment. (You can’t have producers actively writing to it).
- Has all of the required index files created - the time index file, the offset index file, the producer snapshot index, the leader epoch index, and the transaction index.
- Has not been uploaded to the external store before (obviously).
- The Last Stable Offset (LSO) must have advanced beyond this file’s largest offset.
- Reminder: the LSO is a composite of the High Watermark and the last (highest) committed offset for transactions - it represents the minimum of both. It basically represents the highest (latest) offset that should be visible to consumers
- It’s used to ensure that all in-sync brokers have replicated the data by the time we tier it, as well as ensure that all transactions up to that point have been committed.
The RLMCopyTask checks the partition’s files for all of these, and if they satisfy the requirements, starts uploading the data to the external store. This check and upload happens every 30 seconds. In practice, this means Kafka tiers a closed segment to the external store very quickly.
This quick tiering behavior means that you practically won’t have more than two untiered segments at any time during stable operations. Since the copy task runs every 30 seconds and the default segment size in Kafka is 1 GiB, by the time the active segment gets closed - the previous one will likely have been uploaded.
Why does this matter?
Because it means you can afford to quickly prune the local disk data while knowing it’s stored safely in S3, reducing overall broker state, which translates to easier operations and lower costs.
Quotas
Given the design, the external store upload rate can be quite bursty.
Once a segment closes and becomes eligible for upload, the Kafka broker will start uploading it within 30 seconds. If it lacks any configured quotas, the broker would upload the files as fast as its threads can handle, which can result in very bursty and high resource usage in terms of:
- Network bandwidth - the plugin sends the data to the external storage over the wire.
- Disk bandwidth - the plugin needs to read the data it’s about to tier from disk.
- CPU time - compressing and encrypting data can take up CPU, but even reading for disk and uploading to the external storage takes CPU, because it is not zero copy.
This bursty resource usage can have adverse effects on cluster stability.
Here is an example visualization of what the network bandwidth could look like with and without quotas:
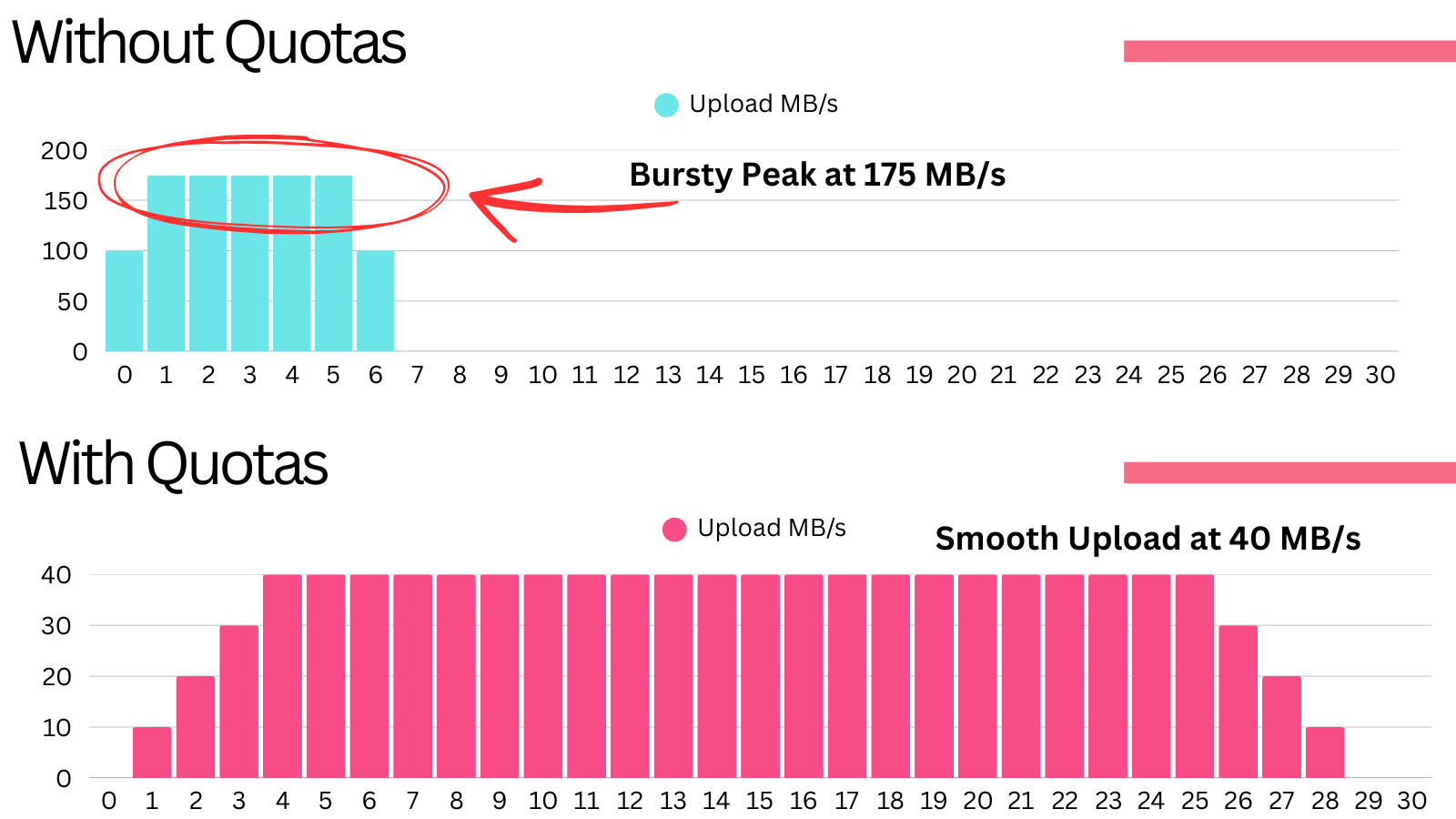
To combat this, both KIP-405 and the plugin offer configurable quotas:
- Kafka broker:
remote.log.manager.copy.max.bytes.per.seconddenotes the maximum global upload rate, applying to all partitions at once. - Plugin:
upload.rate.limit.bytes.per.secondalso denotes the maximum global upload rate, applying to all partitions at once.
While these configs may appear duplicate on first glance - there is an important distinction.
- The broker config can only throttle at the segment level - the broker only controls the decision of whether to ask the plugin to upload more segments at any given time. It cannot control whether the segment is uploaded at a high rate or not.
- The plugin config has finer-grained control to limit the upload at the buffer-level of any given segment.
The two configs are complementary to each other. A sample configuration may use the coarser-grained broker config to control the number of segments that would fight for utilizing the finer-grained plugin config:
- Copy threads (
remote.log.manager.copier.thread.pool.size): you could have 10 copy threads configured, meaning at most 10 segments could be uploaded concurrently - Plugin rate limit (
upload.rate.limit.bytes.per.second: could be 100 MB/s - Broker rate limit (
remote.log.manager.copy.max.bytes.per.second): could be double the plugin rate, so as to limit the amount of files that will make it through to the plugin and compete between each other at the plugin rate limit.
The Upload
RLMCopyTask packages all of the relevant files - the offset index file, the time index file, the producer snapshot index, the leader epoch file, the transaction index and of course the log segment data file itself - into a single LogSegmentData.
The copy task then calls the plugin’s RemoteStorageManager interface to upload the packaged segment data to the external store.
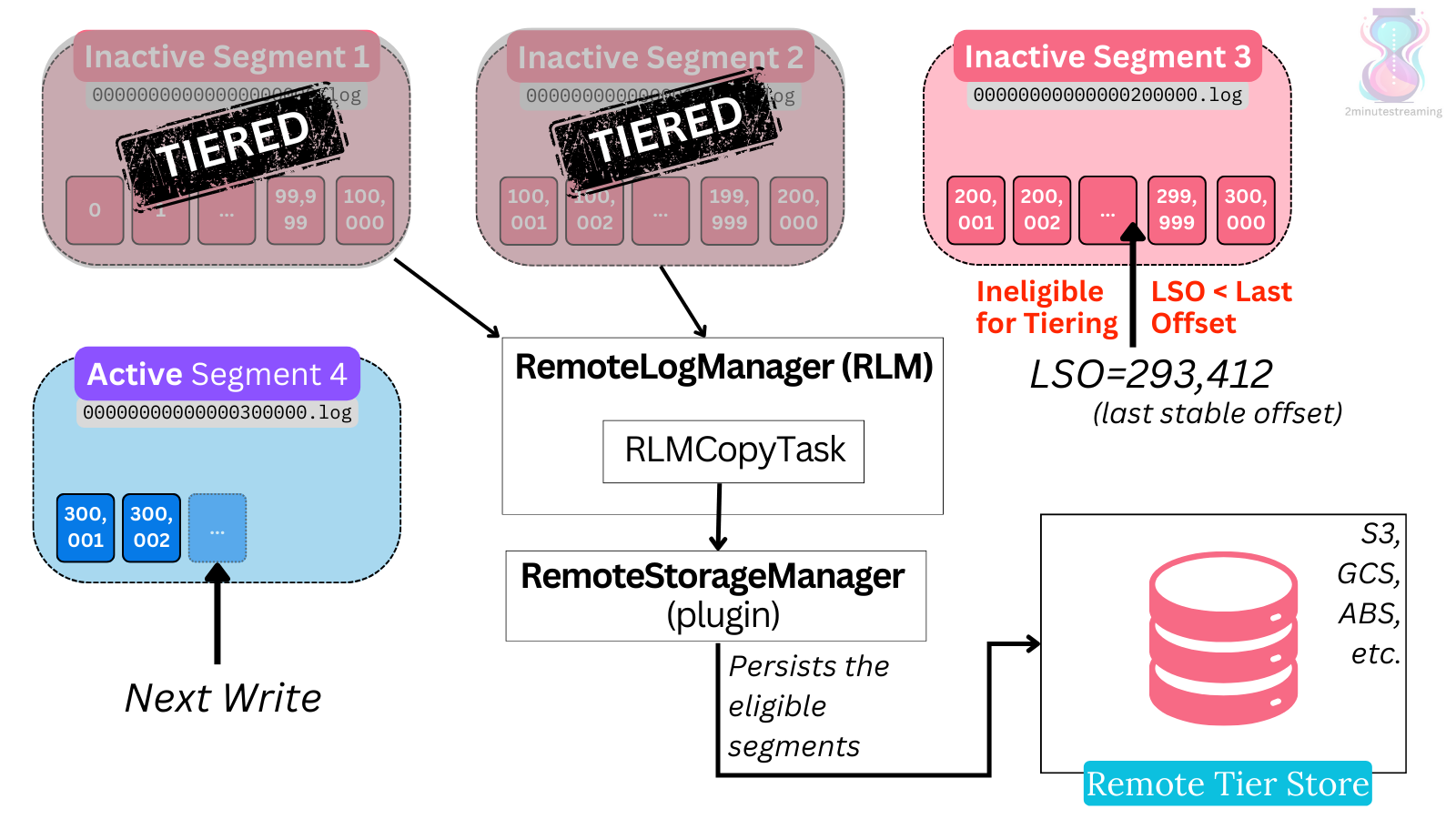
Now it’s the plugin’s turn to perform the actual upload. It’s up to the plugin to define how the data will be structured in the underlying object store. Remember, the contract the plugin must fulfill is to simply persist the data and later return it when asked.
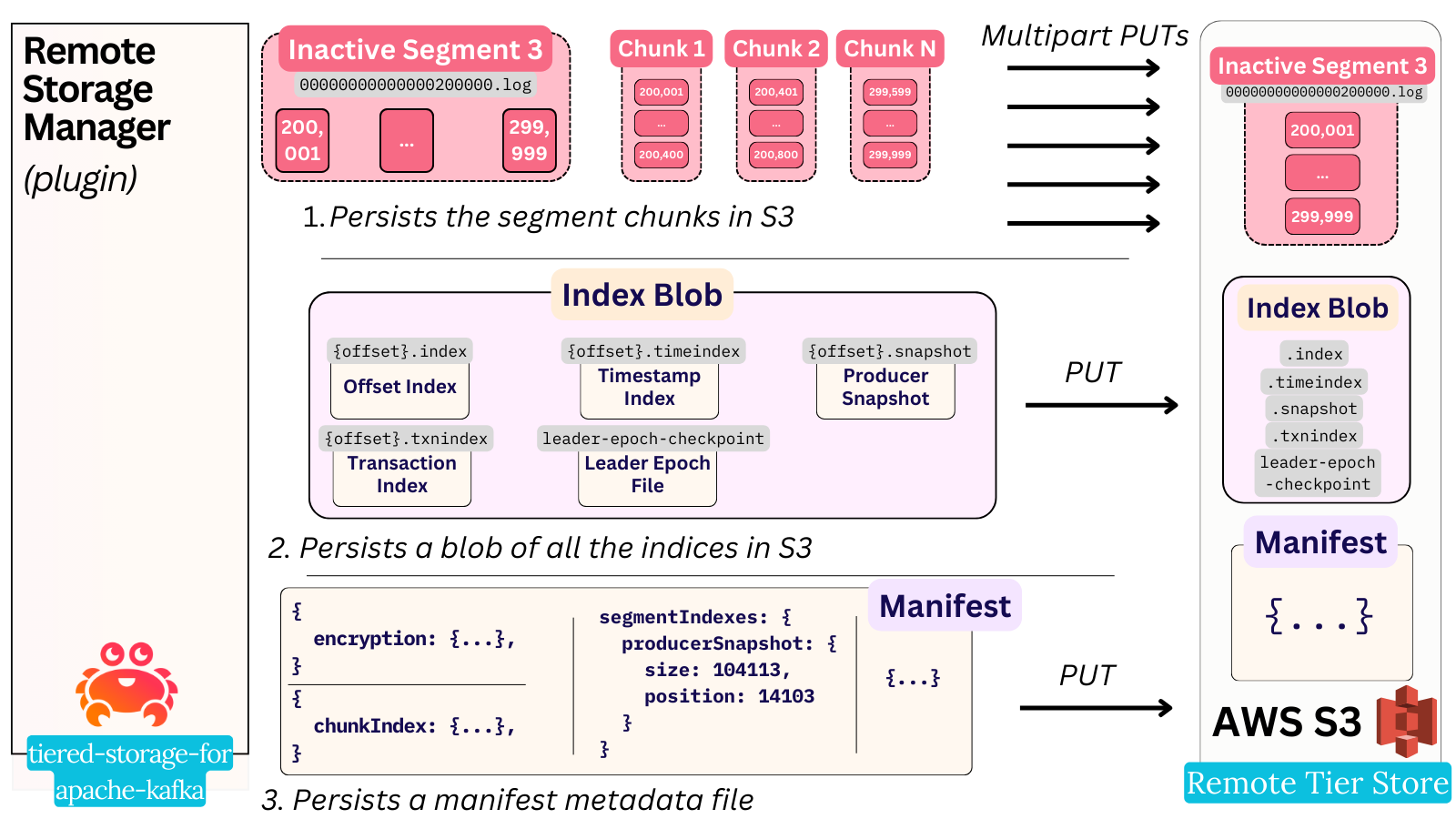
The Aiven plugin uploads it in 3 steps:
- Uploads the segment file (uploadSegmentLog)
a. The segment is broken down into multiple parts (called a “chunk”), and the whole segment is uploaded via multi-part puts, chunk by chunk.
b. This chunking approach plays a vital role in the caching strategy that becomes important later during read operations.
Chunking is also crucial for supporting encryption and compression efficiently. - Uploads the indices (uploadIndexes)
a. They are all packaged into a single index blob file and uploaded with a single put. - Uploads a segment manifest
a. The manifest is an additional metadata file specific to the Aiven plugin - it consists of:
i. A chunk index file that includes the critical information of how big each chunk and the overall file are, before and after transformations like compression/encryption are applied.
ii. Metadata about the segment index blob - i.e what position of the blob which type of index starts at.
iii. Metadata about the compression and encryption of the files.
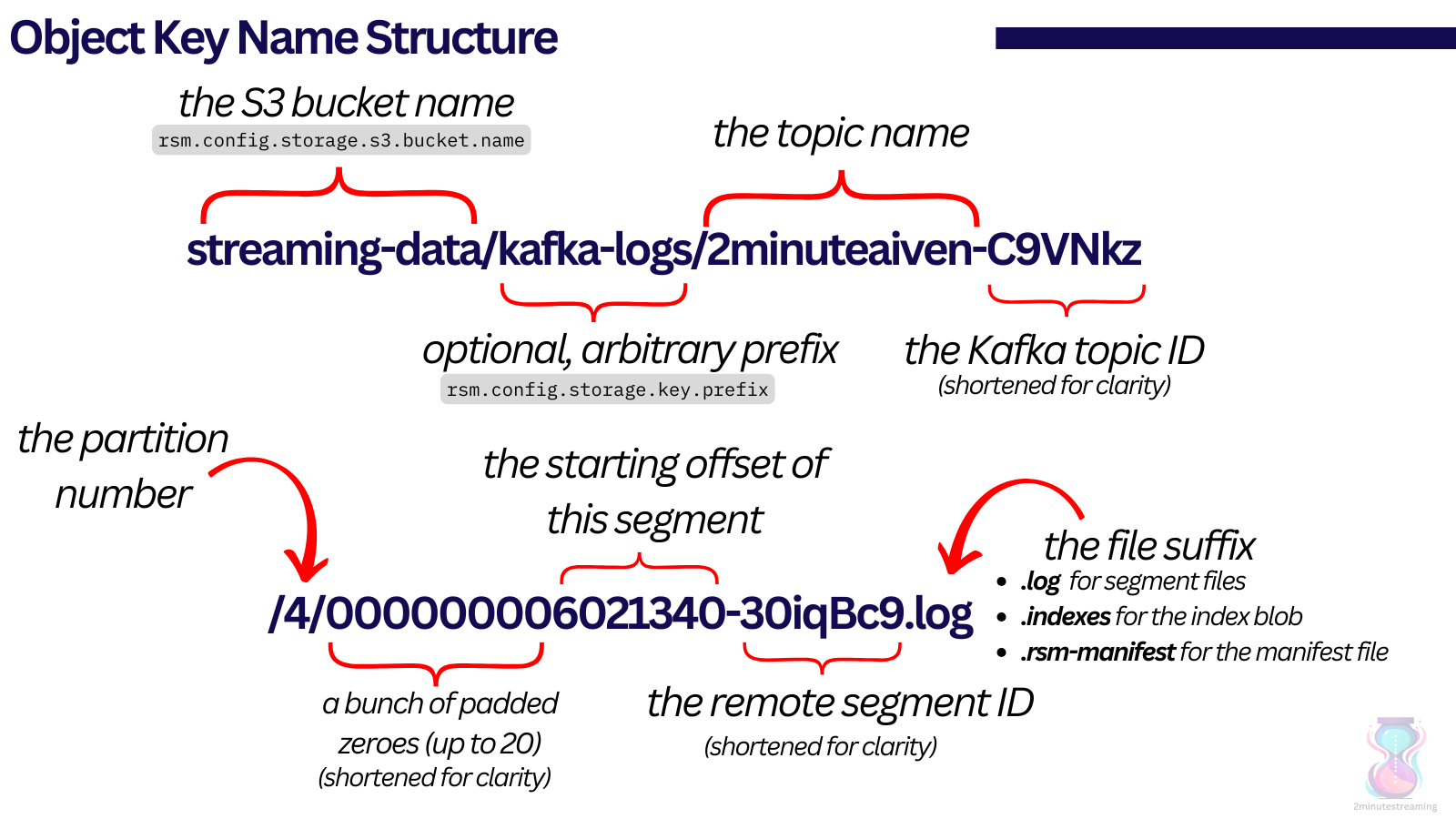
For completeness, the full object key paths look something like this:
- streaming-data/kafka-logs/2minuteaiven-C9VNkzgcQb2UpS7dyDgLjg/0/00000000000006021340-30iqBc9lSWy67gMkPGNbsA.log
- streaming-data/kafka-logs/2minuteaiven-C9VNkzgcQb2UpS7dyDgLjg/0/00000000000006021340-30iqBc9lSWy67gMkPGNbsA.indexes
- streaming-data/kafka-logs/2minuteaiven-C9VNkzgcQb2UpS7dyDgLjg/0/00000000000006021340-30iqBc9lSWy67gMkPGNbsA.rsm-manifest
Writing Metadata
Careful readers will notice that we haven’t mentioned how this action is handled in a fault-tolerant way.
What happens if, for example, the broker fails during this tiering process? Without proper handling, this could result in unreferenced files in S3 that take up storage but never see use, leading to unnecessary costs.
Any sort of tiered storage upload has its metadata durably persisted via a metadata manager. The only OSS implementation available today in Kafka is a local topic storage option - TopicBasedRemoteLogMetadataManager, meaning the metadata is stored in a Kafka topic called remote_log_metadata.
When Kafka itself is a persistent store, it becomes pretty trivial to choose where it should store its metadata in a fault-tolerant way!
The metadata upload consists of two parts:
- Before segment tiering - a metadata record referring to the remote segment is persisted. This initiates the upload process.
- After segment tiering - a metadata update record is persisted. This “seals” the upload process and signals that the remote segment is ready to be read.
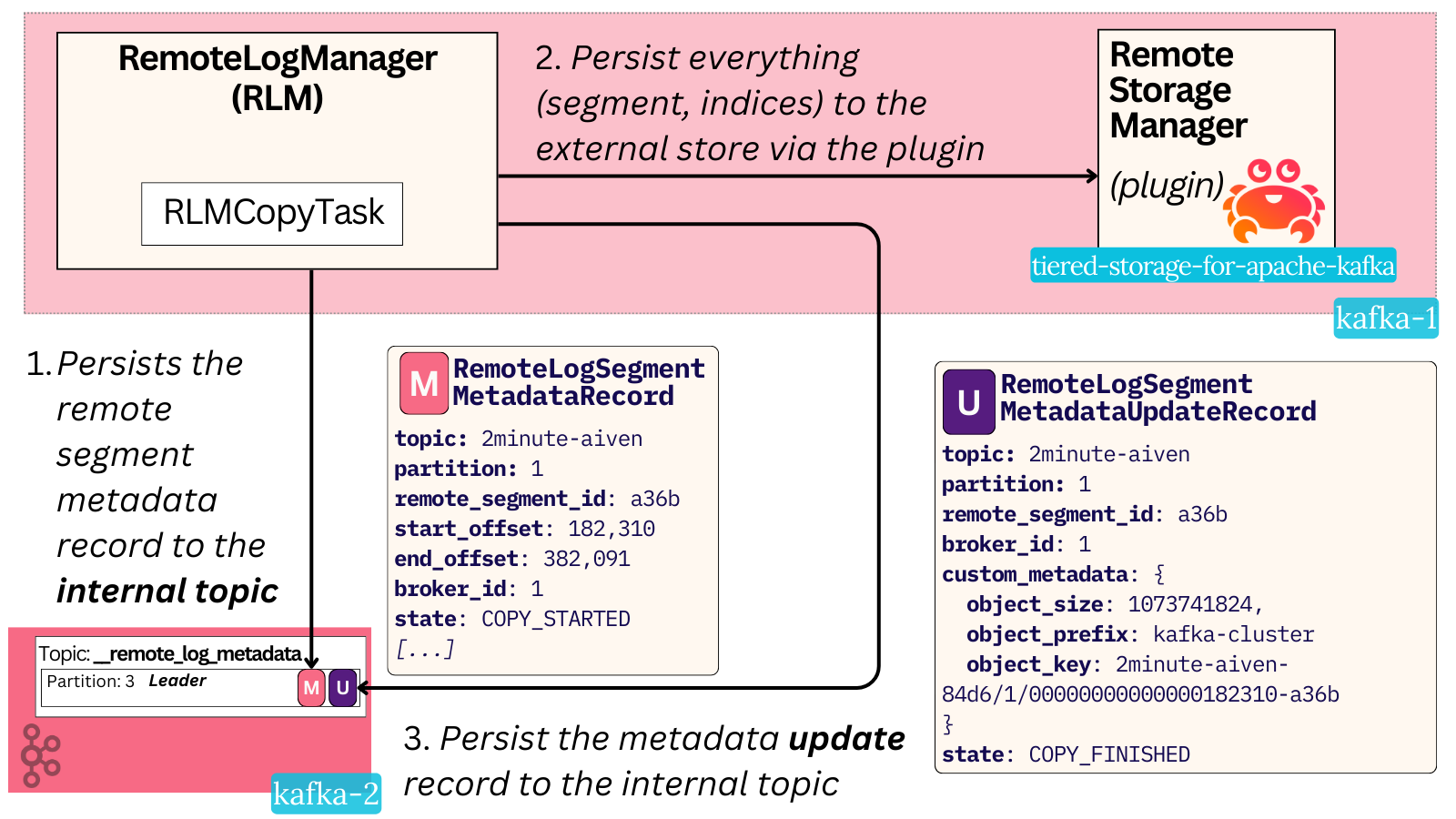
The high-level steps are the following:
- The broker decides it’ll tier a local segment. It creates a unique UUID for the remote log segment. It creates a metadata record with a state of COPY_STARTED and produces it durably to the internal Kafka topic.
- It uploads the data via the plugin. The plugin returns a set of custom metadata specific to the plugin (KIP-917).
- A new record referring to the same remote segment UUID, this time with an updated COPY_FINISHED state, is persisted in the Kafka topic. It also contains the plugin metadata.
In case the broker fails in the middle of these steps, the prudently-persisted metadata allows the system to automatically resume operations, as well as clean up any unnecessary resources. The specific recovery process is tied directly to the data deletion path, which we won't cover here. Make sure to tune in the follow up piece that covers Deletes and Reads to see how this metadata, alongside the partition’s leader epoch, is used to recover from failures!
Records
The initial metadata record consists of things like:
- The unique UUID of the remote segment and the topic-partition it relates to - e.g {topic}-{topic-uuid}-{partition}-{remote-segment-uuid}
- The offsets this segment starts and ends at.
- The broker ID which uploaded it.
- The state of the segment - which can either be COPY_STARTED, COPY_FINISHED or DELETE_STARTED, DELETE_FINISHED. There’s a simple state machine for this.
- An index mapping of offsets to leader epochs in this segment.
- Some extra stuff I won’t mention.
In edge cases where the broker fails during object storage upload, duplicate metadata records referring to the same local segment may exist. The local segment is referred to by its start and end offset.
On duplicate uploads, the new metadata record will differ most significantly by:
- the broker ID of the record (assuming a new leader was elected and it initiated the upload)
- the remote segment UUID (a new random one is generated)
- the leader epoch offset mapping (the new leader will have its epoch added there)
These records refer to the fact that a segment upload was initiated. The signal that it was successfully completed comes from the metadata update record. It consists of:
- The same remote segment and topic-partition IDs
- The (updated) state of the segment - e.g COPY_FINISHED
- The plugin-specific custom metadata. With the Aiven plugin, this consists of the:
- The blob object’s key. It’s in the format of $(topic_name)-$(topic_uuid)/$(partition)/$(000+start_offset length=20)-$(remote_segment_uuid)
- The object prefix (the key.prefix config which denotes a general prefix string for all keys)
- The size of the remote blob (this is relevant when encryption/compression changes it)
To understand the full state of a remote log segment, the broker needs to read both the general and the update record.
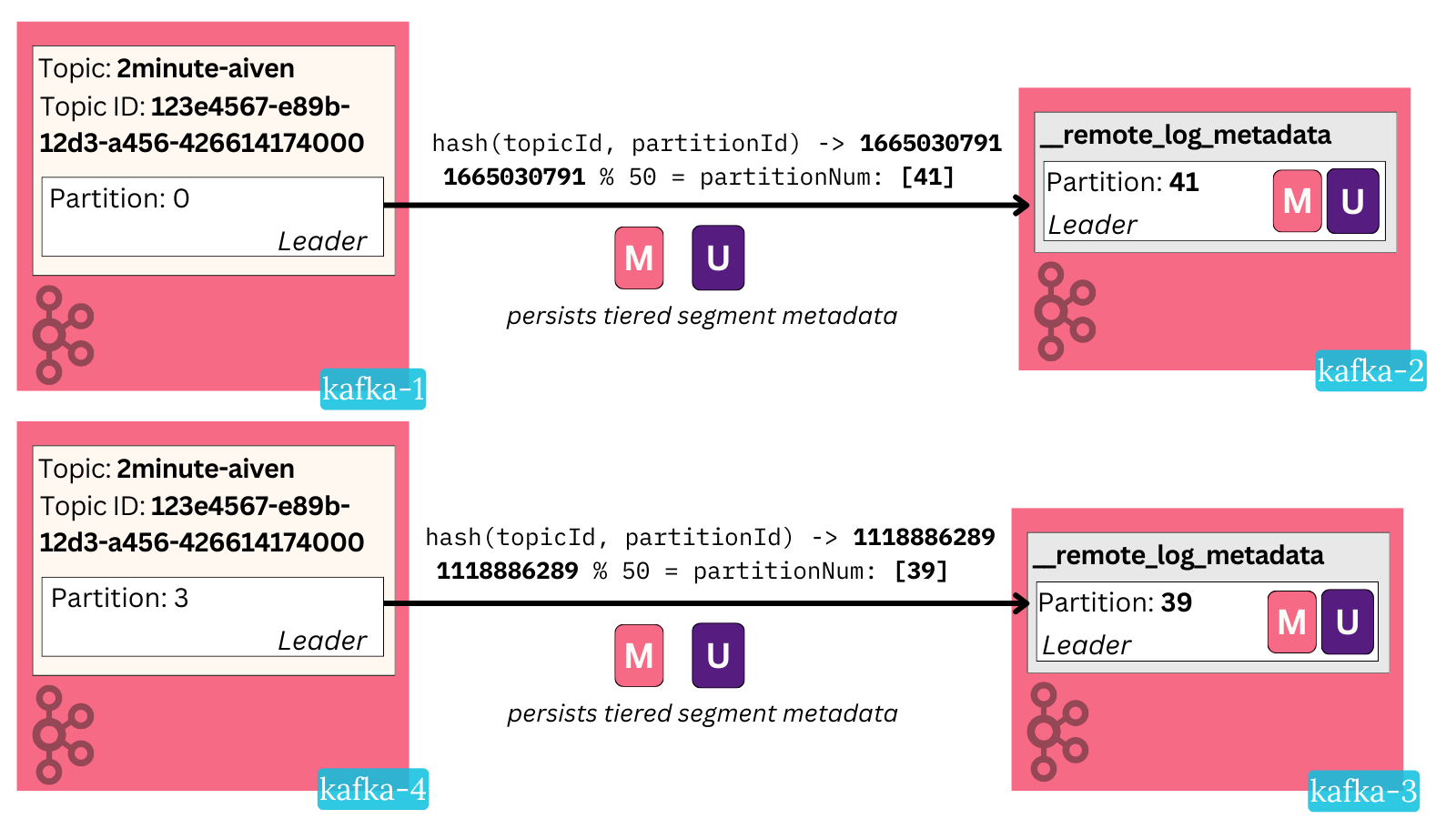
As with any materialization process, the ordering matters! We can’t afford to have an update record be read before a general record. To ensure ordering, Kafka deterministically places metadata records of user topic partitions in the same metadata topic partition.
Let me make the partition distinction clear:
- User Topic Partition: a regular partition of a regular topic, e.g
2minute-aiven-1in the graph above - Metadata Topic Partition: a partition of the internal tiered storage topic, e.g
_remote_log_metadata-1
Internally, Kafka has a partitioner that deterministically maps a user topic partition to a metadata topic partition by hashing the user topic ID and partition number, then modulo dividing it by the number of metadata partitions. The metadata topic defaults to 50 partitions but is configurable.
This ensures that a particular user topic-partition’s state resides in the same metadata partition and that all updates there are serialized in order.
Reading Metadata
Each fully-uploaded segment, therefore, has all the necessary information about its externally-stored data in the Tiered Storage internal topic. This set of records in the tier topic becomes the source of truth of the metadata.
Brokers keep up to date with this metadata via a pull-based model. Similar to KRaft, every broker actively consumes the internal tier topic and materializes the state in memory. There is an active Kafka Consumer running in its own separate thread in every broker called RLMMConsumerTask.
This internal consumer is not configured with a consumer group, does not commit offsets and its auto offset reset policy is set to earliest. The result is that on every Kafka broker restart, the newly-created consumer task will begin reading from the start of every partition and rebuild the latest state in memory.
The broker keeps a separate metadata cache for every metadata partition. The consumer task continuously reads the latest data from every partition and updates the cache.
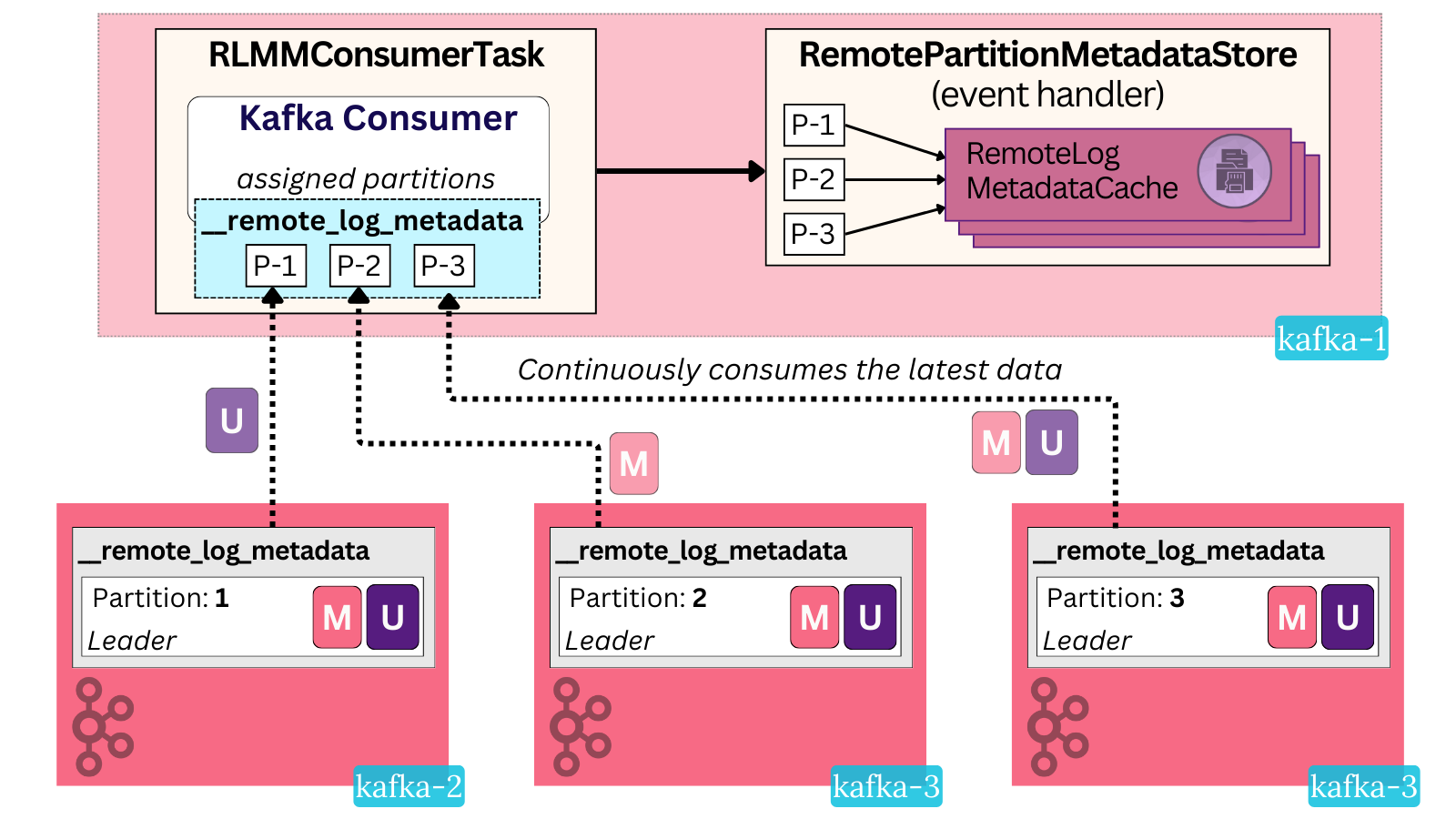
Technically, the broker chooses just the metadata topic partitions that its local user partitions are assigned to. But in practice, in any non-trivial size deployment, every broker will need to subscribe to every metadata partition.
Metadata Extensibility
Since the metadata is stored in a regular Kafka topic, it allows users to build additional custom functionality on top.
Aiven, being a managed Kafka provider, built extra tooling around tiered storage in their control plane. Their system reads the metadata topic from all clusters to build a materialized view per service that powers:
- An overview UI displaying Tiered Storage usage information per cluster
- Anomaly checks that validate that the Kafka metadata and object storage state match (no missing files, no mismatches in size, etc.)
Recap
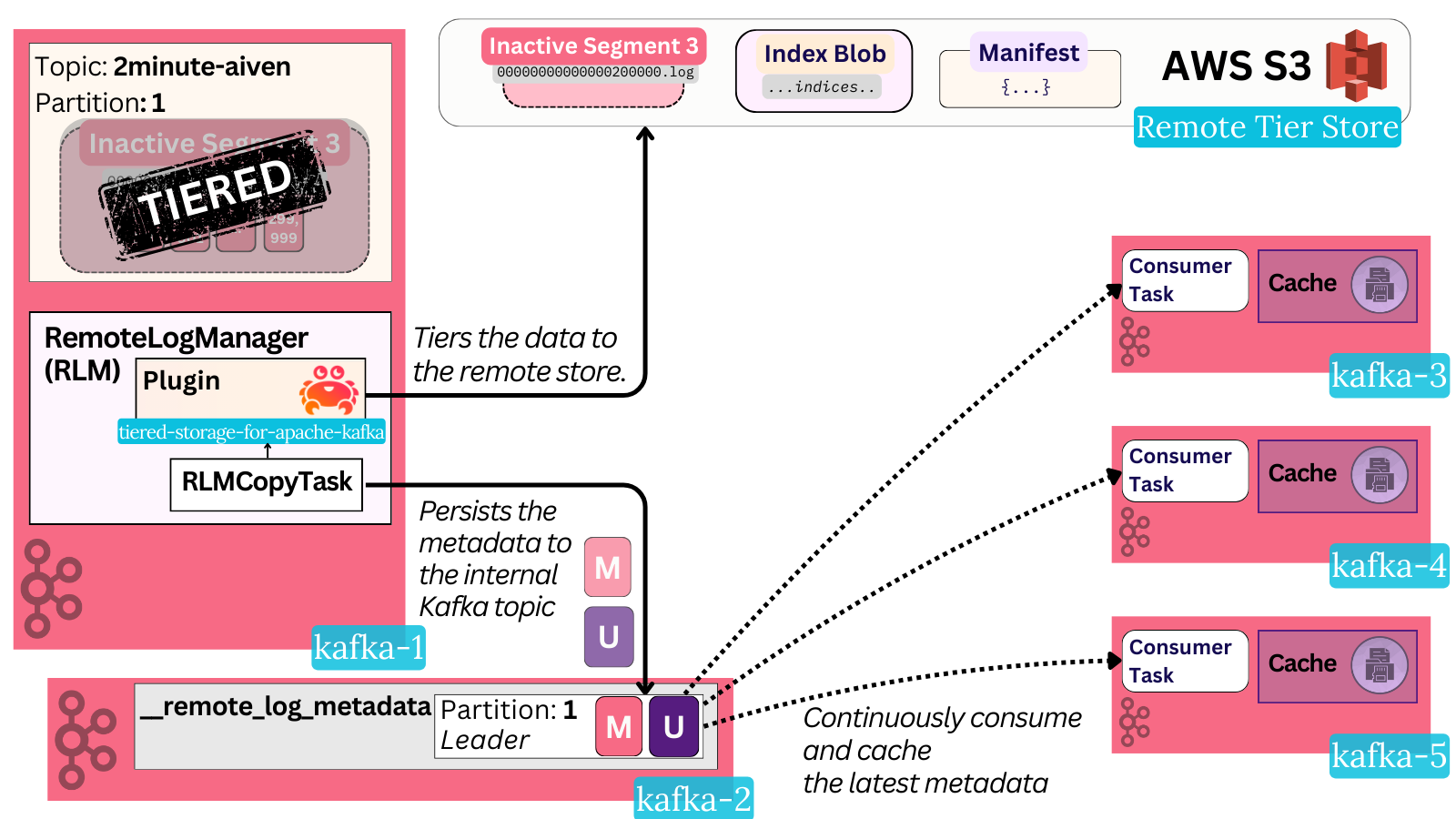
The end result is complex to capture in a single diagram, but it’s a system where:
- Every broker tiers its user partition segments and indices to a remote store
- The tiering happens asynchronously and only once certain requirements are fulfilled (closed segment, LSO, indices present, etc)
- The state of this tiering is kept in an internal topic named
remote_log_metadata. - Before and after tiering, the broker writes the state of the tiering and plugin-specific metadata to the appropriate
remote_log_metadatapartitions. - The Aiven plugin stores the data in three different blobs in object storage:
- The segment file, the largest one, is uploaded in separate chunks via multi-part PUTs.
- A single blob consisting of all the index data, including producer snapshots and leader epoch checkpoints.
- A manifest blob with metadata specific to the plugin, including information about the chunks.
- Every broker leads some
remote_log_metadatapartitions. - Every broker actively consumes all
remote_log_metadatapartitions to build up the latest remote segment state in memory.
Conclusion
Tiered Storage is deceptively simple on the surface - move cold data to cheaper storage - but like most Kafka features, internally, it contains an elegant solution to distributed systems problems. The extensive design discussions in KIP-405 show how the community refined this seemingly simple idea into a robust system.
In this article, we reviewed how KIP-405 handles tiering to the remote store and manages the metadata associated with it through an internal topic. We covered how the Aiven plugin helps achieve this through chunk-based uploads and more.
Part two will cover the read and delete paths, focusing on the plugin’s caching and prefetching mechanisms, along with its approach to managing expired and orphaned data.
Thanks for reading.
Special thanks goes out to Aiven's engineering team for building and maintaining a production-grade plugin for AWS, GCP, and Azure, and for reviewing this piece.
Check out the OSS plugin to start testing how tiered storage can revolutionize how you run Kafka. It's being used at petabyte scale in some of the biggest Kafka clusters around the world.
Review our last blog post in this series about Aiven for Apache Kafka® to see 16 ways that Tiered Storage Makes Apache Kafka Simpler, Better, and Cheaper.
