



TL;DR;
KIP-1150 isn’t a distant, strange planet; it just reroutes Kafka’s entire replication pathway from broker disks to cloud object storage. Flip one topic flag and your data bypasses local drives altogether:
- No disks to babysit: Hot-partition drama, IOPS ceilings, and multi-hour rebalances vanish—freeing up time (for more blog posts).
- Cloud bill trimmed by up to 80%: Object storage replaces triple-replicated setups with pricey SSDs and every byte of cross‑zone replication, erasing the “cloud tax".
- Scale in real time: With nothing pinned to brokers, you can spin brokers up (or down) in seconds to absorb traffic spikes.
Because Diskless is built into Kafka (no client changes, no forks), we had to solve a 4D puzzle: How do you make a Diskless topic behave exactly like a Kafka one—inside the same cluster—without rewriting Kafka? This blog unpacks the first‑principles, deep dive into the thought process,and trade‑offs that shaped the proposal.
What’s Under the Hood of KIP-1150?
As we discussed in our previous post, the super‑power of Diskless isn’t a clever algorithm — it’s the decision to stand on the shoulders of clouds. S3, GCS, DynamoDB and Spanner: each are maintained by teams with hundreds of talented engineers. Instead of out‑engineering them, KIP‑1150 lets Kafka draft in their slipstream, inheriting low-costs, planet‑scale durability and zone‑redundancy “for free.” That framing flips the usual trade‑off on its head: we get lower bills and fewer issues, yet keep the strict ordering guarantees that made Kafka the streaming lingua franca in the first place.
To turn that ambition into an upgrade path rather than a rewrite, we anchored Diskless on three foundational principles:
- No API changes, built-in Kafka: users will flip a switch per topic to write through to object storage. This builds on top of Kafka regardless of the underlying framework or vendor.
- Upgrade, not Migrate: As a result of Diskless being built-in Kafka, users just need to upgrade their clusters and start creating Diskless topics alongside their existing streams. Eliminating costly migrations and tradeoffs.
- No breakaway forks: Diskless is specifically designed to be upstreamed with minimal merge-conflicts. If Kafka is diskless, this concentrates the efforts on a single solution—just like Tiered Storage, which united the community for everyone’s benefit.
Keep those three in mind. Because of them, a Diskless stream is wire-identical to a classic one—your Flink jobs or JDBC connectors will never know their data now lives in object storage.
The principles explain why we split the work into mini‑KIPs, why the Batch Coordinator is a single source of truth rather than a thicket of micro‑services. In the next sections you’ll see each principle surface again—sometimes as a design constraint, sometimes as the catalyst for a delightful side‑effect—but always as the north star that keeps Diskless Kafka feeling, well… like Kafka.
That singular intent produced our proposal— or as we call it a motivation‑KIP. It proposes no code changes at all; instead, it stakes out the architectural ground‑rules that every followup KIP should respect. The logic is simple:
- Extend, don’t rewrite. Diskless arrives as a second topic type. You can combine the good old disk-backed topics with diskless streams in one cluster without touching client code or CLIs.
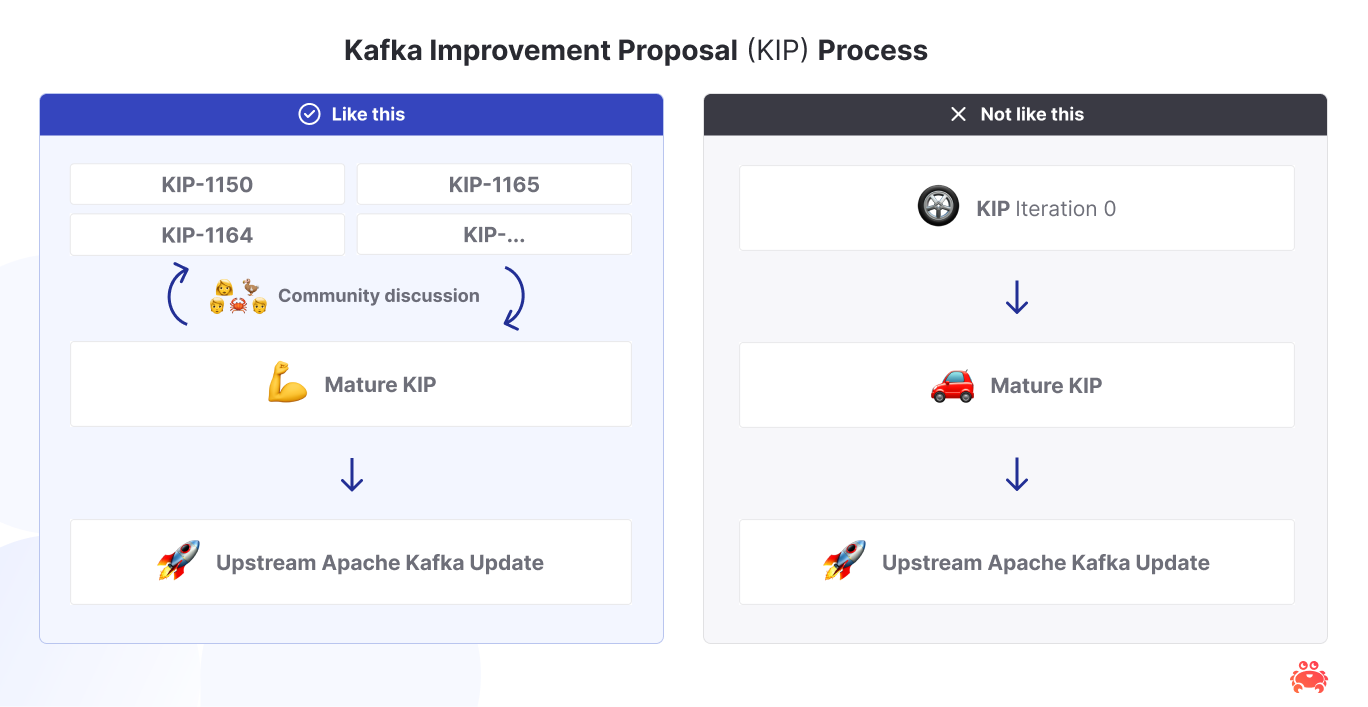
- Ship in slices. Instead of one 800‑page tome, we split the work into laser‑focused KIPs—KIP-1163: Core , KIP-1164: Batch Coordinator, KIP-1165: Object Compaction, and more queued up. Each mini‑KIP can be designed, argued, and approved on its own clock, so real code lands sooner.
- Stay boringly compatible. Accepting 1150 changes zero APIs today; it only establishes the feature’s mandate. Every followup KIP must prove it keeps upgrades painless and upholds the other principles.
Why the bureaucracy? Because upstream Kafka moves when consensus moves. By carving the work into chunks, reviewers can chew one bite at a time—friction drops, velocity improves, and the community could get something useful long before it’s perfect.
Here’s how we see the process going forward:
Kafka’s Cross-Zone Data Transfer: the Tollbooth We All Ignore
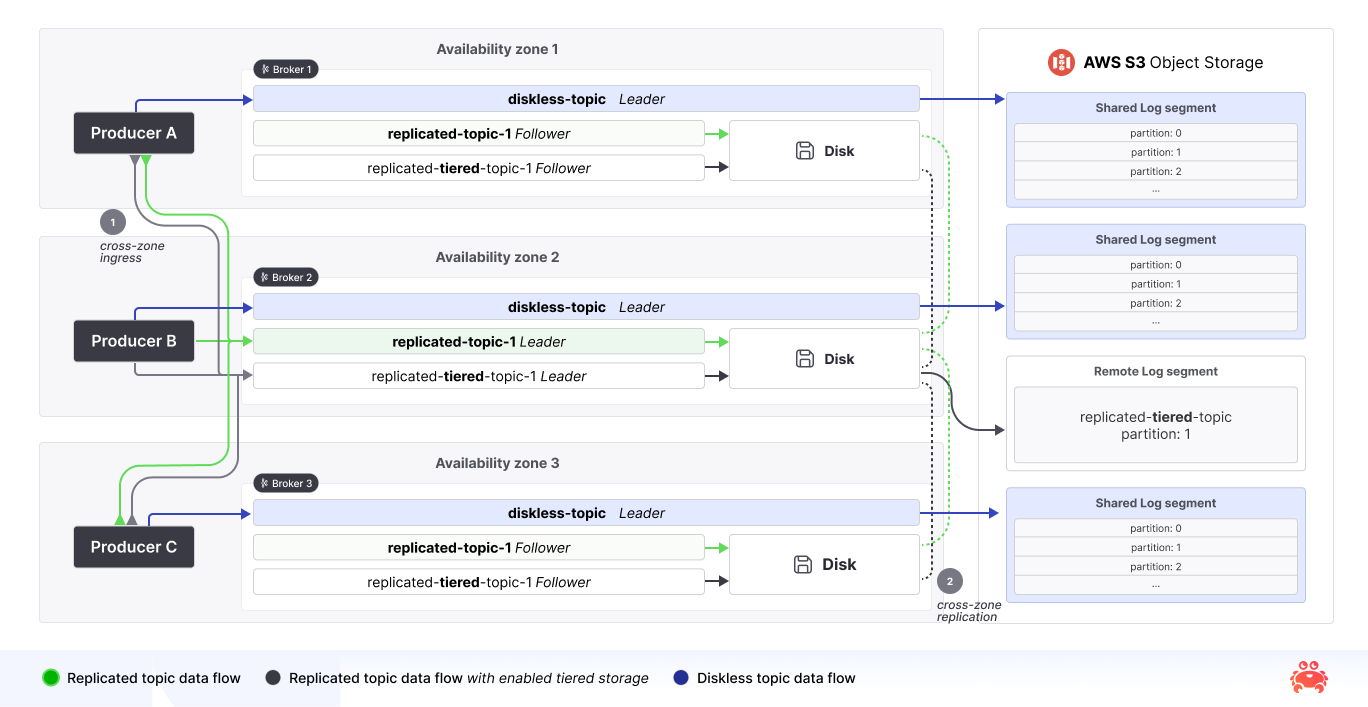
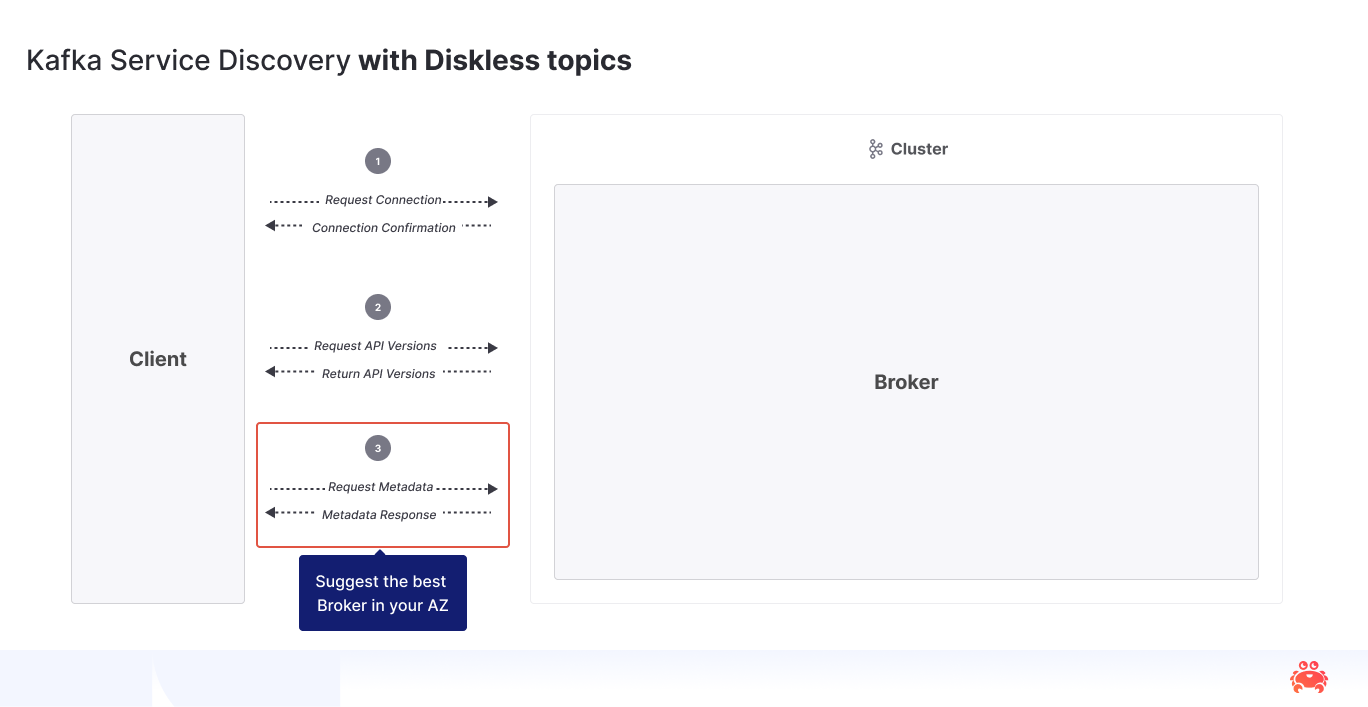
A Kafka client boots, hits a bootstrap broker, then issues a metadata call that tells it exactly which broker is the leader for each partition. Every subsequent produce must cross the wire to that single leader; every fetch must hit a replica that owns those bytes. That’s fine in a single AZ or in a private data center, but in the cloud the moment that leader sits in another AZ - you pay up to $0.02/GB each direction—and you pay it four times. In the default 3-zone distribution setup, data crosses availability zones through four paths - producer → leader, leader → first follower, leader → second follower and leader → consumer. Turn that firehose up and you can watch your wallet empty in real time.
Diskless nukes the leadership model, to eliminate cross-zone taxes
We set out to delete the leadership model entirely, so any broker that’s local to the client can:
- Buffer & upload batches to object storage
- Ship coordinates (object ID + byte range) to a cluster‑wide Batch Coordinator which acts as a centralized order-preserving sequencer
- Get global offsets back; inject them; respond
But how do we eliminate cross-zone traffic? Diskless topics delegate data durability to the storage layer. With classic topics, data durability relies on replication of the same data into different brokers (which should sit in different availability zones). Object storage in all major clouds is a highly available and a durable solution making durability concerns a thing from the past.
Eliminating Cross-Zone Clients
And thanks to KIP-1123 - Rack-aware partitioning for Kafka Producer (still under discussion) we can have this without any further changes on the client libraries - not only for Diskless topics, but also for Kafka topics that do not rely on strict partitioning. As you can see in the following diagram, this is the exact same flow as with Kafka topics.
Eliminating Cross-Zone Replication
Traditionally, any experienced user would recommend a replication factor of 3, this means each single message is copied over the wire two additional times (and those being inter-zone traffic). Diskless topics make all this traffic redundant. With Diskless topics, data is only written once to the object storage of your preference, there are no more copies travelling around between brokers. Durability is managed by object storage and not a concern for Kafka anymore when using this topic type.
Reads follow the same pattern in reverse. Because ordering now lives in metadata—not a broker log— the log’s data never needs to leave the AZ where it originated from, and object storage handles durability across zones behind a single endpoint.
Elasticity as a side-effect
The leaderless architecture of diskless topics provides a significant benefit: seamless cluster scaling. Because data resides in object storage, new brokers do not undergo replica synchronization to retrieve existing data. This decoupling from local storage enables near-instant scalability – not to mention saves on further cross-zone transfer costs.
Additionally, when a specific broker is too busy, producers (or consumers) can be easily and instantly redirected to another broker in the same availability zone to alleviate the load.
The (hot) path not taken
As we discussed, Kafka’s original replication is beautifully simple: a client learns which broker leads a partition, funnels every write to that single machine, and trusts the local SSDs spread across the replica set to keep data safe. That pattern survived two data‑center generations, and keeps the data extremely safe. Unfortunately, it frays in the cloud, where every hop across an Availability Zone is metered and suddenly a popular partition can cook its leader’s networking bill in minutes.
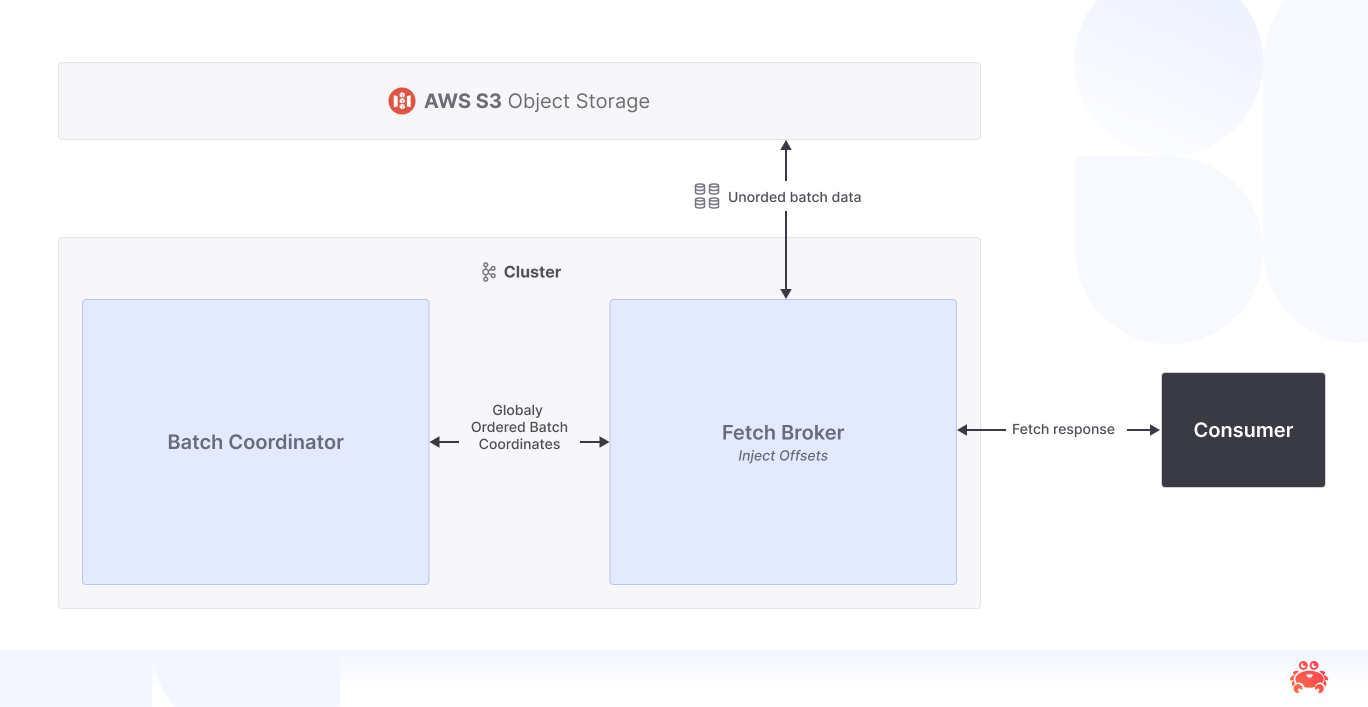
Diskless keeps the surface exactly the same for producers and consumers yet carves an entirely different path underneath. Instead of steering all traffic through a leader, any broker that happens to be in the caller’s zone may accept the write. The trick is a brand‑new component—the Batch Coordinator—that becomes the keeper of order. Brokers buffer incoming records, fuse them into a shared‑log segment about a few megabytes in size (this is tunable), stream that object to S3/GCS/Blob in one cheap PUT, then send the Coordinator a compact “coordinate list” (object ID and byte ranges). The Coordinator applies the only piece of global magic: it merges the many local sequences into one monotonic stream of offsets. Offsets flow back, the broker injects it into the producer response, and the producer receives the same ack it always has.
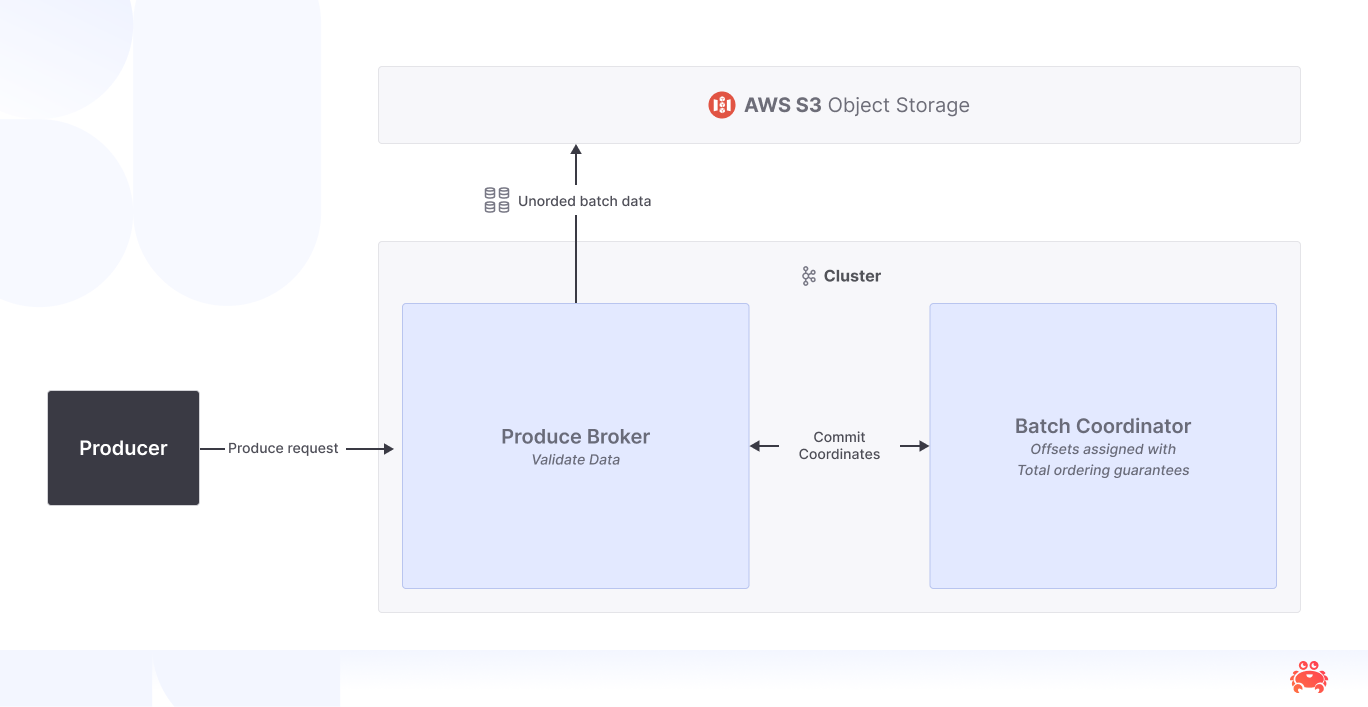
The absence of a leader changes some physics: hot partitions no longer magnetise to a single host because every broker is automatically eligible to receive writes. That flattened load lets us theoretically dramatically increase cluster throughput without touching the client or running a single kafka-preferred-replica-election.sh. It also surfaces new dials. Segment size, for instance, is now an economic knob: tiny segments (<128 KiB) slash latency but explode PUT fees, while jumbo segments (>10 MiB) do the opposite (yes, we will have a whole blog post on costs!)
Reads travel an equally unfamiliar road. A consumer still issues a fetch, but the serving broker begins by asking the Coordinator for the coordinate map that covers the requested offsets.
Armed with that map it pulls the relevant byte ranges from object storage, consults a per‑rack cache to avoid déjà‑vu downloads, stitches the final offsets back into the records, and streams them to the client. The first uncached look‑back, say twenty‑four hours into the past, naturally pays the object‑store round‑trip (about 100 ms in our estimation). The second and third scans of neighbouring offsets, however, are satisfied from RAM and come in <20 ms—fast enough that a team migrating a real‑time fraud pipeline could not tell which partitions were classic kafka and which had quietly been flipped to diskless.
The design is intentionally more conservative than other object‑storage systems. Those systems often push batching logic into the client library or shard coordination across a fleet of tiny consensus nodes—great for green‑field stacks, painful if you already run thousands of Kafka clients written in half a dozen languages. By hiding every new concept behind the existing wire protocol we kept the upgrade path to a single topic flag.
Of course, every shortcut charges a toll elsewhere. Exactly‑once semantics still work but will stay in preview until the follow‑up KIP lands; cold-start fetches pay the price in object-store Round Trip Time (RTT); and the Coordinator’s SQLite‑backed state must fit in a compact SSD or else spill to tiered storage snapshots (we may have better designs as the KIP progresses). Yet even those caveats feel small against the payoff: no inter‑AZ replication traffic, no hot‑partitions, and an elasticity story that spins a brand‑new broker into full production traffic before your coffee finishes pouring. Now is the moment for the community to pressure-test these limits and refine the design—every idea, sketch, or war-story moves us closer to a polished release.
The path we didn’t take—local disks plus three‑way replication—turns out to have been the costliest lane in the cloud. Diskless gives Kafka a better road and does so without asking users to pick up a new map.
How Diskless Packs Its WAL
Kafka’s atomic unit is the record batch. Traditionally, these batches are grouped into contiguous files on disk; as a reminder for Diskless topics, we apply the same concept — except the “disk” is now one bottomless shared location called object storage.
One key difference between Kafka topics and Diskless topics is how these batches are grouped.
- Kafka Topics: Each segment is tied to a single partition.
- Diskless Topics: Segments are “shared,” bundling batches from multiple diskless topics and partitions.
Why share the Segments?
By mixing data from multiple partitions into one segment, we reduce the number of discrete files—or in this case, object uploads—the system must handle. That means lower overhead, fewer individual I/O operations, and simpler management. Inside each shared log segment, batches still maintain some local ordering (based on physical placement), but there’s no inherent order across segments until offsets and timestamps are officially assigned.
Immutable Objects
Once a shared log segment is uploaded, it becomes immutable—just like “inactive” segments in classic or tiered topics. This behavior matches typical object storage, where you can’t do random writes. Each segment gets a globally unique UUID for easy reference.
This approach optimizes the Produce path of the process. However, it leaves plenty of room for improvement for the Consume one:
- Many Small Objects: Having numerous small objects hinders sequential reads, increases the demand for parallel operations, raises costs for object storage GET requests, and introduces latency.
- Batch Metadata Overhead: Storing many small batches results in significant metadata overhead, which can be optimized by merging batches.
Object Compaction to the Rescue
To handle these drawbacks, KIP-1150 introduces compaction agents within brokers. These agents:
- Reorder Batches by offset.
- Group Batches by topic-partition.
- Stream the process to minimize memory and object storage hits.
Once the data is reorganized, the compaction agent notifies the Batch Coordinator of the updated structure. By consolidating batches into fewer, more orderly segments, the system ensures better data locality—ultimately reducing the number of object fetches (and associated costs) when consuming data. For the ones with constant back pain, this might sound like a familiar routine action we did back in old Windows systems, Disk defragmentation.
In short, Object Compaction keeps Diskless Kafka efficient on both ends of the pipeline. You get the low-cost, high-scale promise of shared log segments, plus a clean way to handle compaction and heavy read patterns without drowning in tiny object overhead.
A Better Road, Same Map - Now It’s Your Turn
We’ve shown that Kafka can shed its disks, slash the cloud tax, and still look exactly like the Kafka you deploy today. The idea is simple, expected, and concrete—a single topic flag moves data straight to object storage—yet credible because it builds on cloud primitives that already run half the internet. The only step left is community consensus, and that’s where you come in.
How to jump in:
-
Read and reply on the KIP threads.
Start with the motivation KIP-1150 and skim the follow‑ups (1163 Core, 1164 Batch Coordinator, 1165 Compaction). All discussion happens ondev@kafka.apache.org; every “+1,” objection, question or edge‑case helps shape the final design. -
Stress‑test the assumptions.
Does object‑storage latency break your SLA? Do you see a corner‑case the Batch Coordinator can’t cover? Share numbers or even napkin math—real‑world pressure is what turns a proposal into production code.
Open source moves at the speed of informed debate. Add your voice, close the remaining gaps, and let’s finish paving this new lane for Kafka—together.
Don’t panic; just hit “Reply All”.

Table of contents
- TL;DR;
- What’s Under the Hood of KIP-1150?
- Kafka’s Cross-Zone Data Transfer: the Tollbooth We All Ignore
- Diskless nukes the leadership model, to eliminate cross-zone taxes
- Eliminating Cross-Zone Clients
- Eliminating Cross-Zone Replication
- Elasticity as a side-effect
- The (hot) path not taken
- How Diskless Packs Its WAL
- Object Compaction to the Rescue
- A Better Road, Same Map - Now It’s Your Turn