


Apache Kafka® simply explained with an e-commerce project example
Apache Kafka® is widely used in the industry, but the learning curve can be steep and understanding the building blocks of this technology can be challenging. That's why the goal for this article is to look at the fundamentals of Apache Kafka in simple terms.
Apache Kafka in a nutshell
Apache Kafka is an event streaming platform that is distributed, scalable, high-throughput, low-latency, and has a very large ecosystem.
Or, simply put, it is a platform to handle transportation of messages across your multiple systems, multiple microservices, or any other working modules. This can be just frontend/backend applications, a set of IoT devices, or some other modules.
Apache Kafka platform is distributed, meaning that it relies on multiple servers, with data replicated over multiple locations, making sure that if some servers fail, we're still fine.
It is scalable and you can have as many servers as you need. You can start small and add more servers as your system grows. These servers can handle trillions of messages per day, ending up in petabytes of data persistently stored over disks.
And what is great about Apache Kafka is its community and a wide ecosystem surrounding the technology. This includes the client libraries available for different programming languages and a set of data connectors to integrate Kafka with your existing external systems. Thus, you don't need to reinvent the wheel to start using Apache Kafka, instead you can rely on the work of amazing developers who solved similar issues already.
Where Apache Kafka is used
To understand where the need for Apache Kafka is coming from, we'll look at an example of a product.
Imagine that we decided to build an e-commerce project. When starting to work on the project, maybe during its MVP (minimal viable product) stage, we chose to keep all subsystems next to each other as a single monolith. That's why, from the beginning, we kept our frontend and backend services, as well as the data store, closely interconnected.
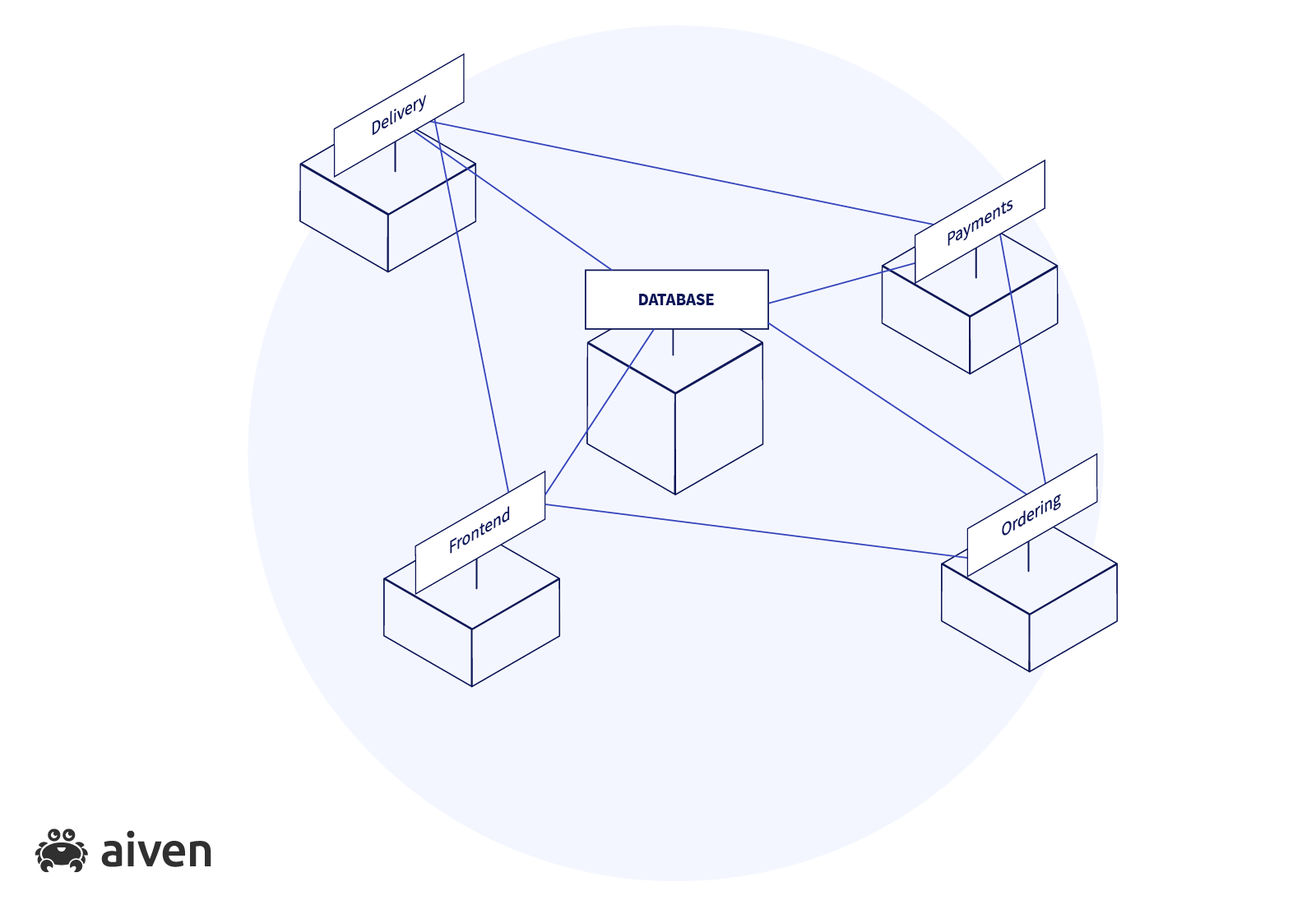
This might be not ideal, but at start this approach can be effective and will work as long as we have a small number of users and a limited amount of functionality.
However, once we start scaling and adding more and more modules (for example introducing a recommendation engine, notification service, etc.), very quickly the current architecture and the information flow will become a complete chaos which is difficult to support and expand. And with the development team growing, no single person will be able to keep up with the data flow of this product.
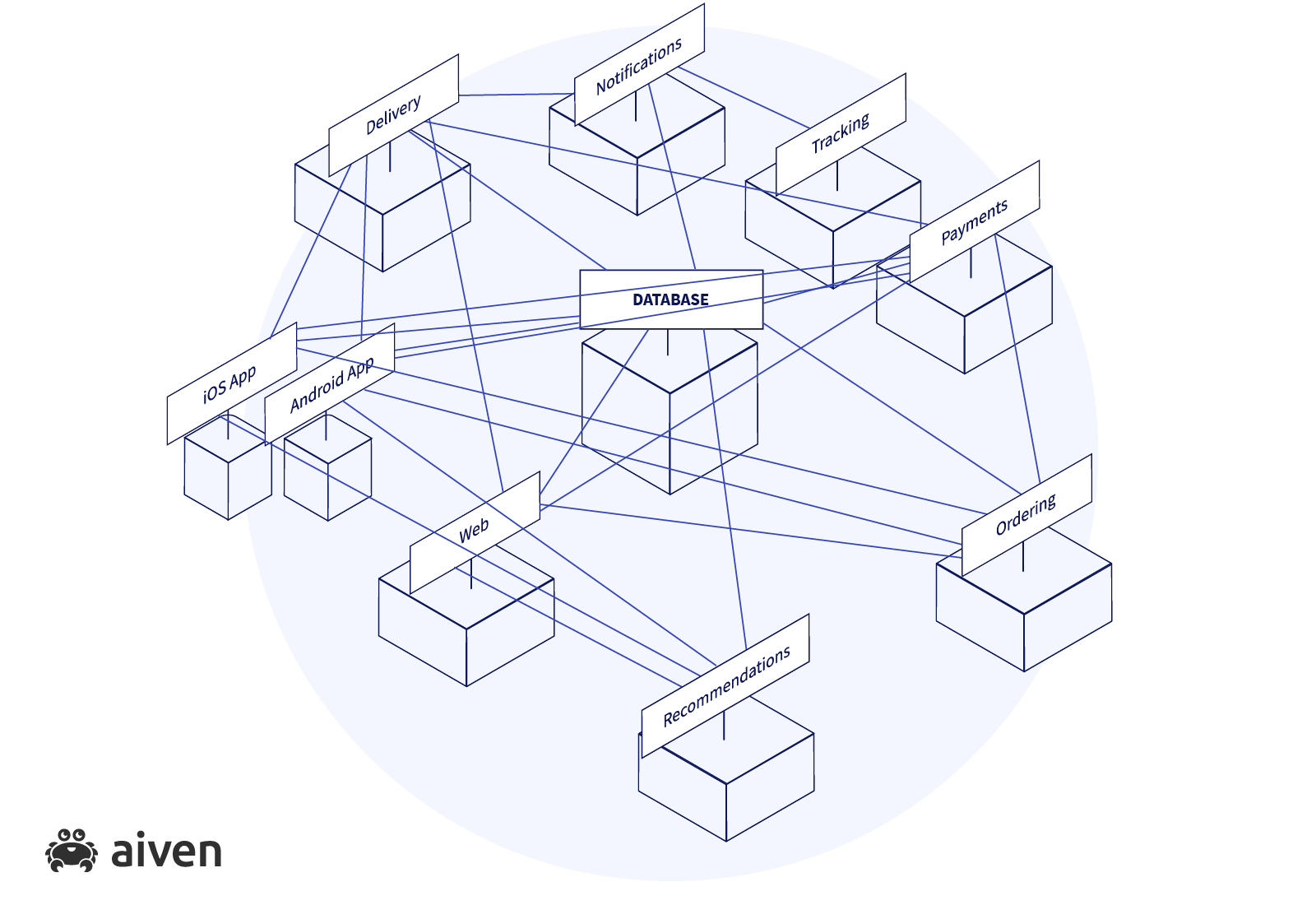
That's why eventually we'll need to have a tough conversation on how to split our monolith into a set of independent microservices with clear, agreed and documented communication interfaces.
What's even more crucial, our new architecture must allow the product to rely on real-time events, where users don't have to wait till tomorrow to get meaningful recommendations based on their latest purchases.
And this is a lot to ask. Introducing such processing of events is an immensely high volume operation and needs to be resistant to failures.
Lucky for us, these are exactly the challenges with which Apache Kafka can help. Apache Kafka is great at untangling data flows, simplifying the way we handle real time data and decouple subsystems.
Apache Kafka's way of thinking
To understand how Apache Kafka works, and how we can work with it effectively, we need to talk about Apache Kafka's way of thinking about data.
The approach which Apache Kafka takes is simple, but clever. Instead of working with data in the form of static objects, or final facts that are aggregated and stored in a database, Apache Kafka describes entities by continuously arriving events.
For example, in our e-commerce product we have a list of goods that we sell. Their availability and other characteristics can be presented in a database as numbers, as shown below.
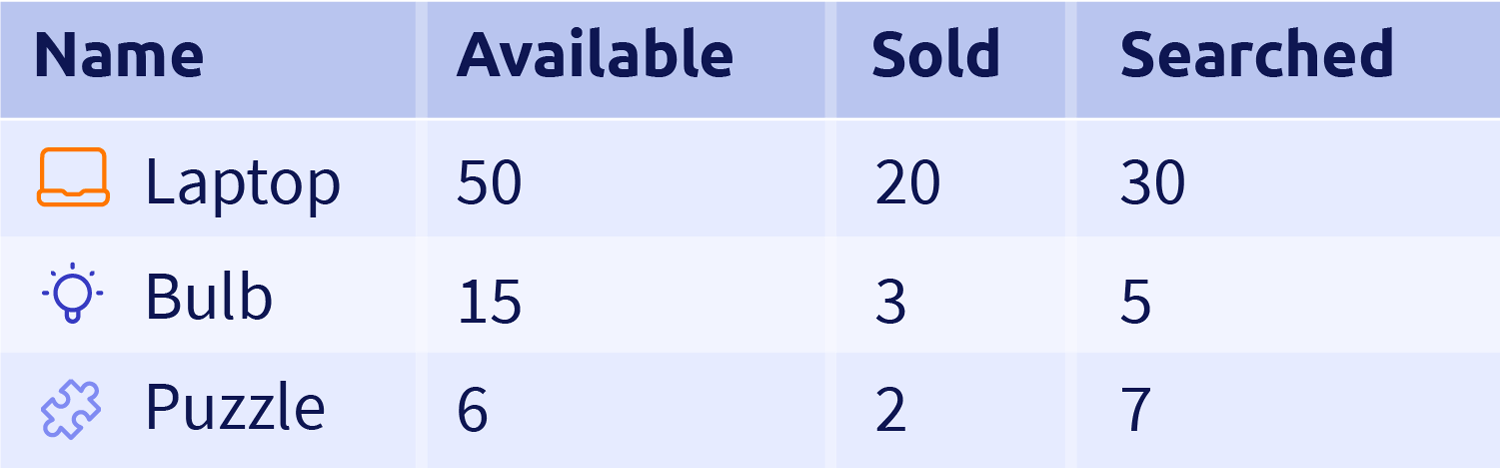
This gives us some valuable information, some final aggregated results. However, we need to plan very carefully what information we store, so that it is sufficient to cover calculations of future insights. Since we don't know what the future holds, it is very tough to predict what data should be kept long term and what is safe to throw away.
Apache Kafka suggests that instead of storing aggregated object characteristics, we view this data as a flow of events:
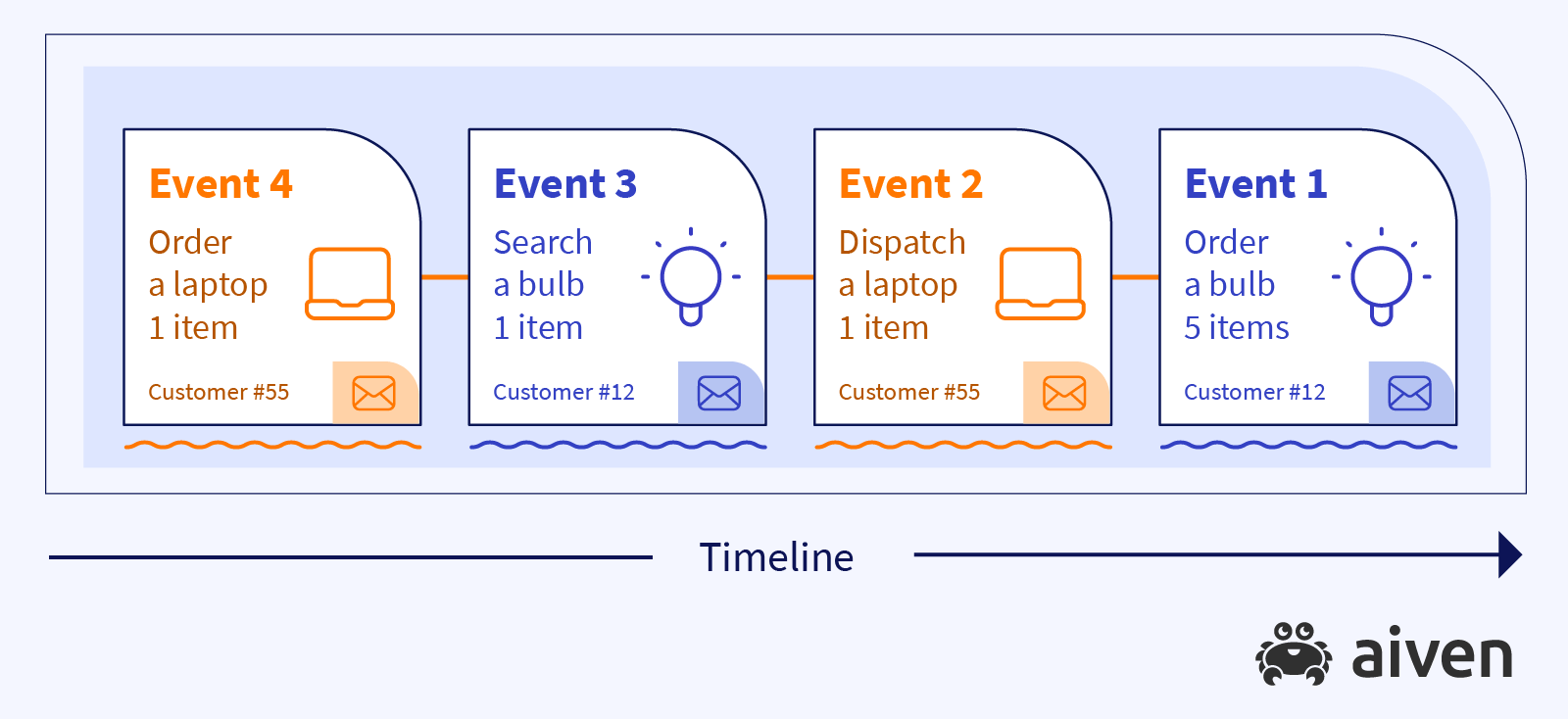
This flow shows the complete life cycle of a product purchase. And instead of seeing the aggregated final data, we observe the change of state.
We also can replay the events, if needed. We can start from the beginning, we can move to a certain point of time.
Note that we can't change any of the events that already happened, but we can replay the events again and again, calculating metrics we need, answering different types of questions about the products and sails.
This type of architecture is actually called event driven architecture and, in the next section, we'll look at how Apache Kafka fits such architecture.
How Apache Kafka coordinates events
An Apache Kafka cluster coordinates data movement and takes care of the incoming messages. It uses a push-pull model to work with them. This means that on one side we have processes that create and push the messages into the cluster, they are called producers. On the other side, we have consumers, who pull, read and process the messages.
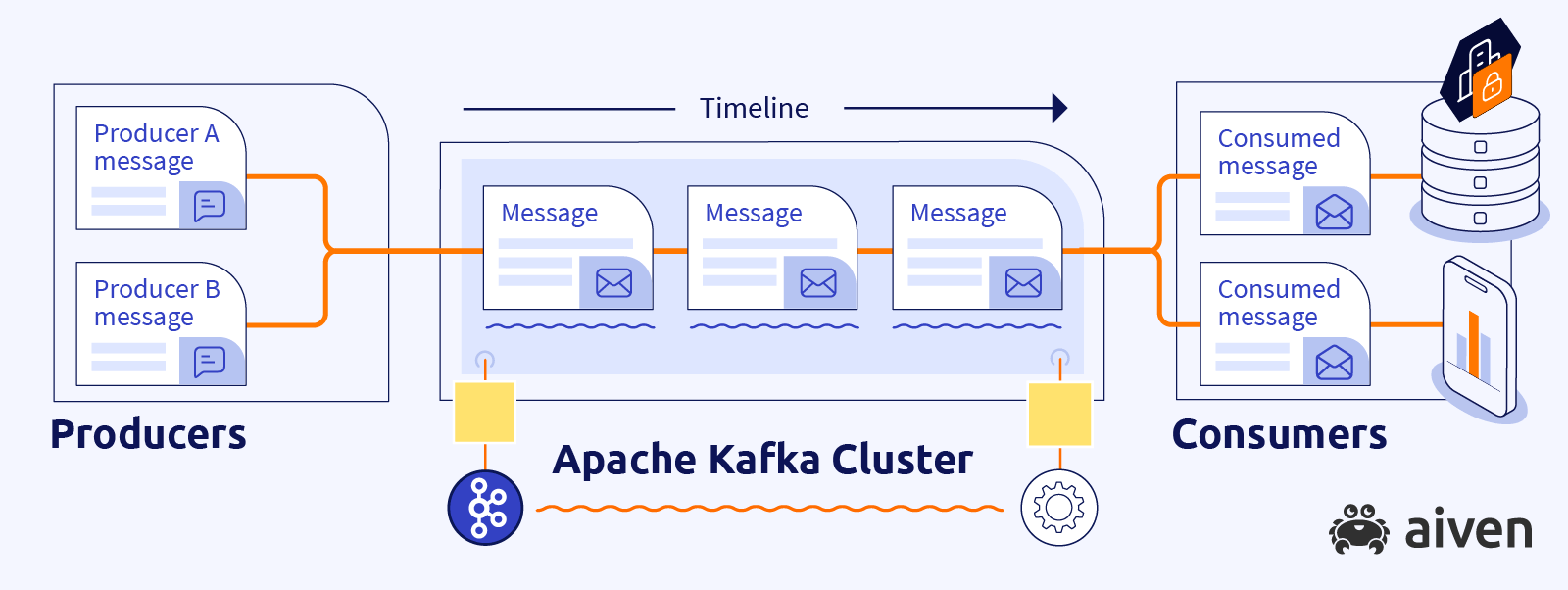
Producers and consumers are applications which you write and control. You can have as many producers and consumers as you need.
Looking at our e-commerce example, the producers can be part of the frontend applications, web and mobile apps. They will observe user actions, package information and send events to the cluster. The consumers can be connected to subsystems responsible for backend modules (in our example - notifications, deliveries, recommendation services).
What is important, producers and consumers can be written in different languages, different platforms, completely not knowing of each other's existence.
We can shut down some producers and add others, meanwhile the consumers will not care that the messages were produced by some other entity, they wouldn't even realize that.
If a consumer gets broken, producers will continue working without issues, producing and sending new messages into Apache Kafka, where those messages will be stored in a persistent storage. Once the consumer is restored, it doesn't need to restart from the beginning since its last read message information its persisted in the platform, it picks up where it left off, reading messages from this persistent storage.
Therefore, there is no synchronization expected between the work of producers and consumers, they work at their own pace. And this is how this helps decoupling our systems.
So, now we know where messages come from and who later reads them, but how are they organized inside the Kafka cluster?
Topics and messages
We call the sequence of messages in Apache Kafka a topic. Topic is an abstract term, we'll come back to this later, but in short, it's not how stuff is physically stored on the disk, but rather, how we think of it to simplify things.
You can have as many topics as needed describing different types of event, similar to tables in databases. Coming back to our example, we can have a topic with information describing a product purchase lifecycle, another topic with user registration events or a topic with system health state events.
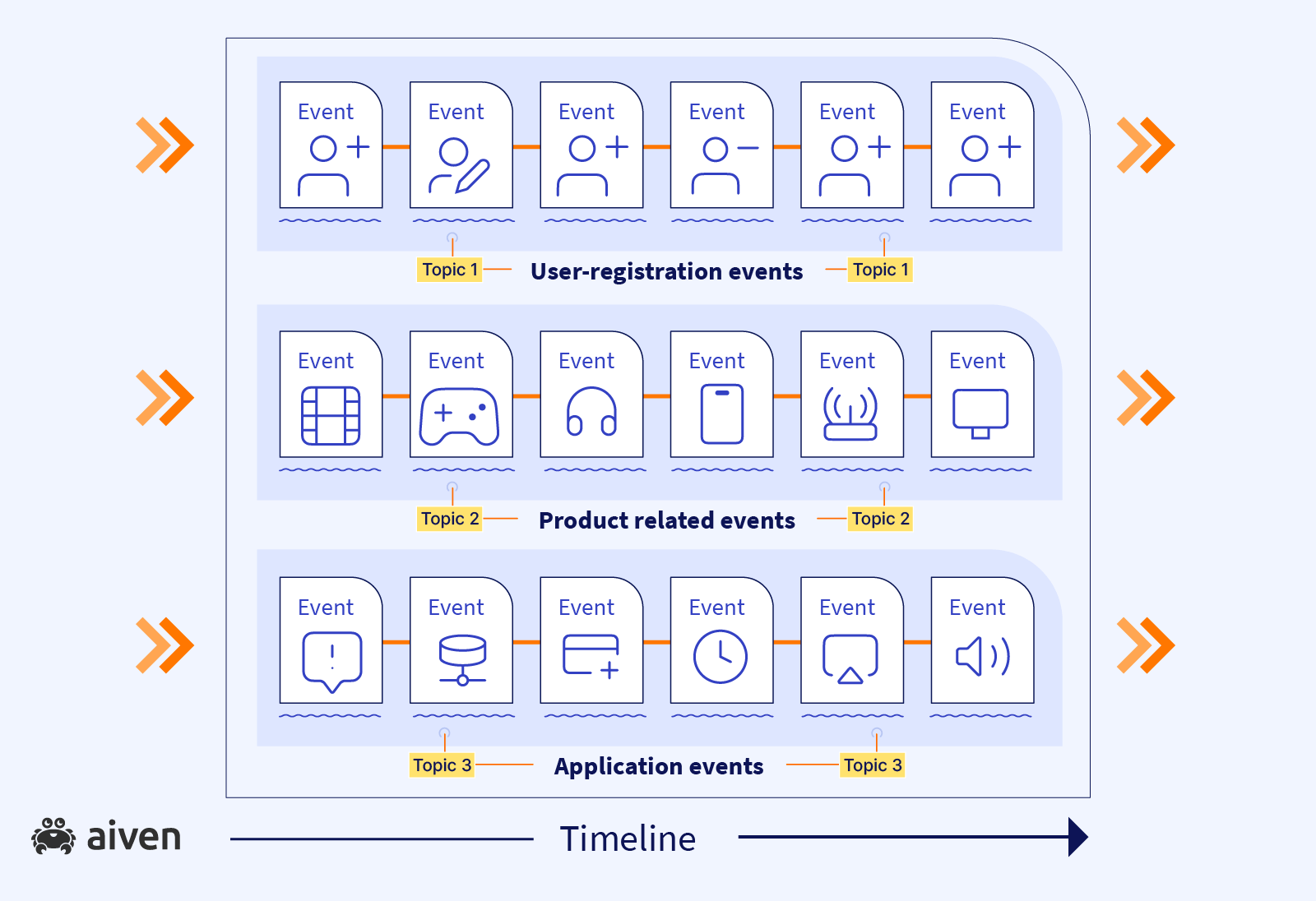
The data is continuously flowing into the topics, there are no pauses, no breaks. As long as our application is working, we have new users registering, new products being purchased.
The messages are ordered. The position of each record is identified by its sequence number, which is known as its offset.
The messages are also immutable, you can't change records later. This is completely logical. For example, let's say someone buys a product at our shop, and we record an event for this action. Later we can't go back in time and change that fact. If the customer decides to return the product - this is a new event. In this way we modify state of objects by sending new events into the topic.
You can see a topic as a queue, but here is a twist - in Apache Kafka, unlike in many other queue systems, the consumed messages are not removed from the queue and not destroyed. Instead, they can be read by multiple consumers multiple times if needed. In fact, this is a very common scenario, information from a topic will be used by multiple consuming applications for different needs, approaching data from different perspectives.
Brokers and partitions
I already mentioned that Kafka cluster consists of multiple servers. These servers are called brokers. And topics are stored on them. Topics can have millions and possibly trillions of events. So we need to think how we're going to store these long sequences of records on the server.
Remember I mentioned before that a topic is an abstract term. The topic itself is not a physical tangible thing stored as a whole on a single server.
It's probably neither reasonable nor feasible to keep a topic as a single piece of data on a single machine. Very probably one day the size of the topic will outgrow the server's memory. That's why it is very important that we scale horizontally, not vertically.
To achieve this we split a topic into multiple chunks stored across multiple machines. These chunks are called partitions.
Each of the partitions is technically a log of messages.
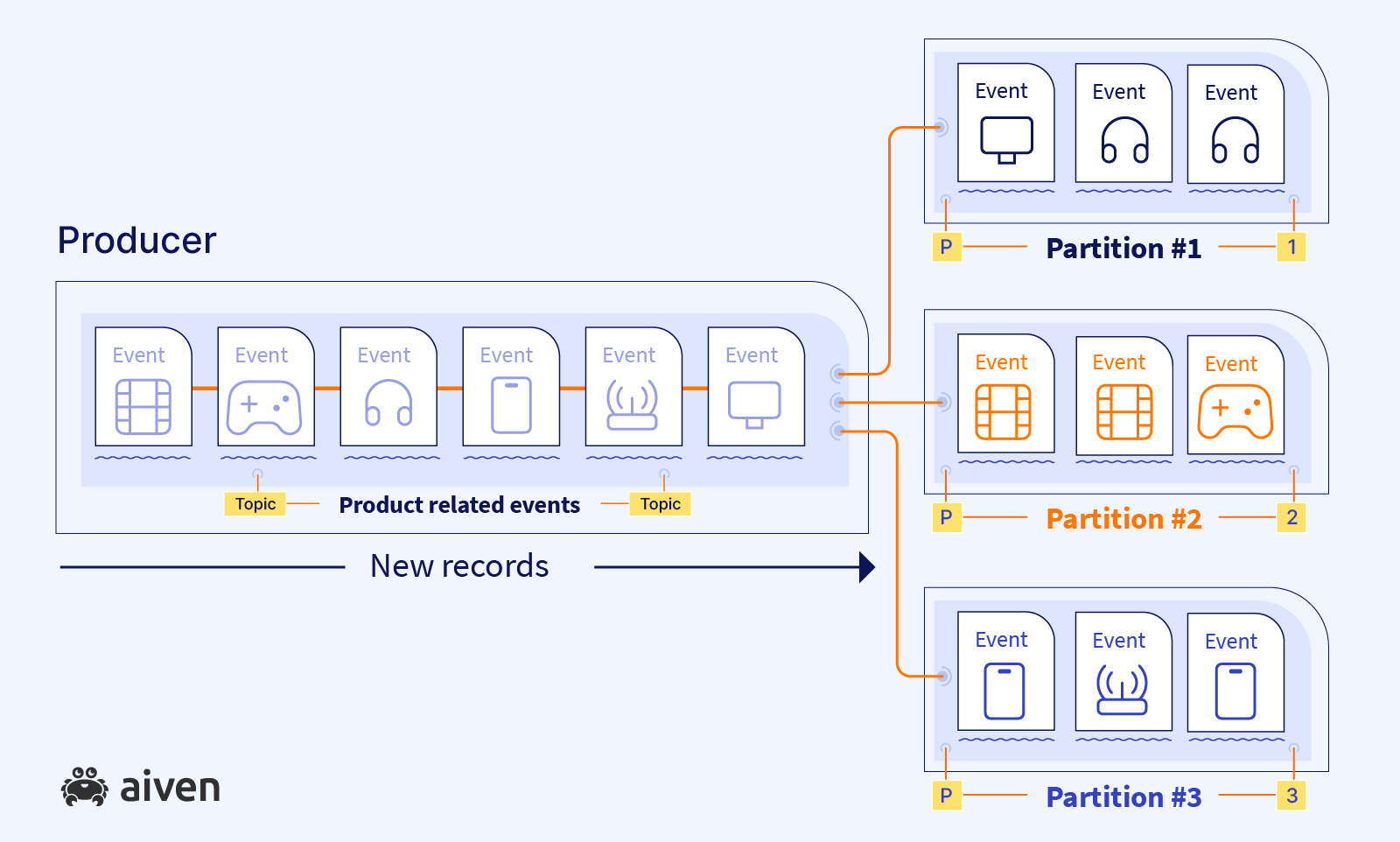
Partitions are self-sufficient entities. Each partition will independently maintain offset numbers for their own values. For us this means that the offsets make sense only within a single partition, across partitions there is no connection between those offsets.
When I was saying before, that a producer writes to a topic, what I meant is that the producer writes to a set of partitions. And a consumer reads from the set of partitions.
Behind the scenes our consumers and producers know how to work with multiple partitions.
Replications
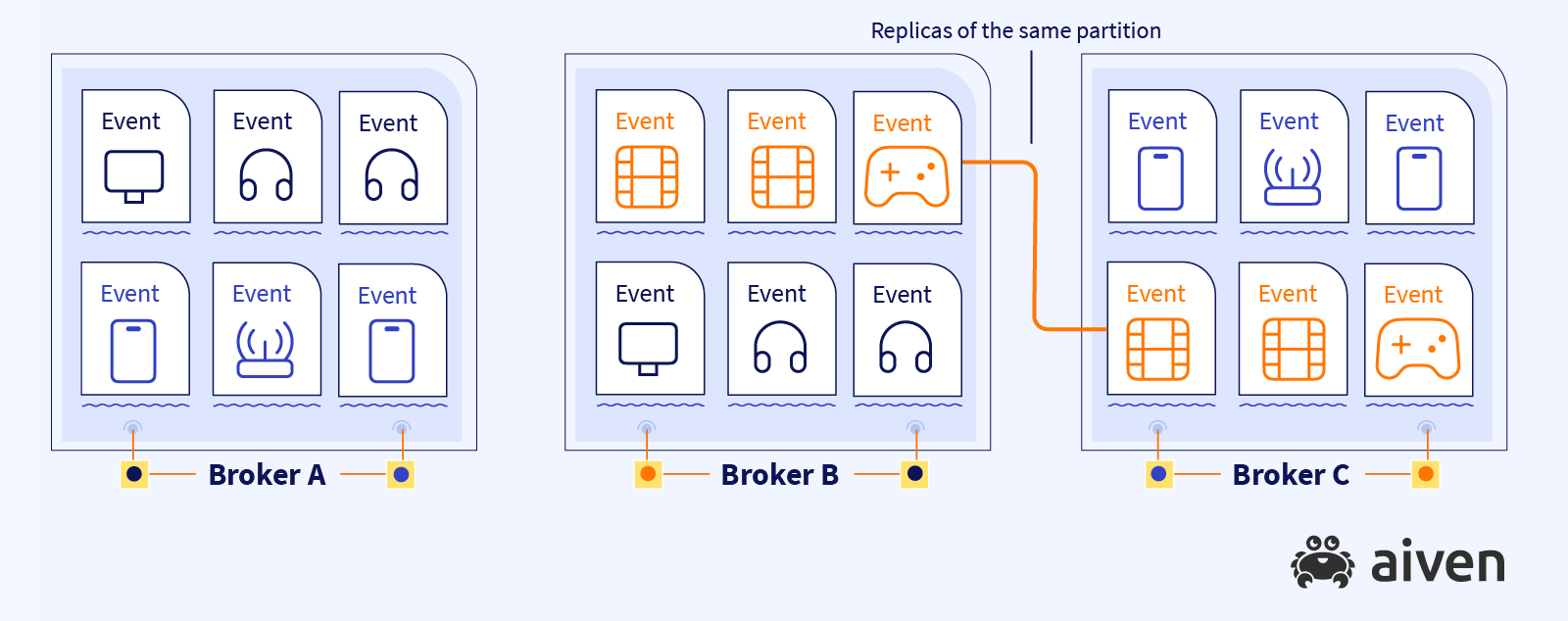
So far we talked about topics, how they are divided into partitions and spread across brokers. Let's now dive one step deeper and talk about replications.
To remain highly available and prevent data loss, Apache Kafka replicates data across brokers. Replication happens at the partition level. In particular, each of the brokers will hold several partitions. Now if any of the brokers experience issues, we can take the data for the partition from a different location.
Apache Kafka connectors
So far we covered plenty of Apache Kafka concepts and building blocks. I wanted to share with you one more concept, a bit more advanced, but that can simplify connecting your applications to Apache Kafka.
Apache Kafka as we saw is a transmission mechanism. A very common scenario is when data is either already available in a source technology or needs to be pushed to a target destination. And this is where Apache Kafka Connect becomes very helpful. It is a tool to write connectors, that are used to integrate external data sources (such as PostgreSQL®, OpenSearch®, other databases and tools). These pre-built connectors can be used across multiple projects, and in fact, many of them are open sourced and supported by the community. Or if you encounter a connector that doesn't exist yet - you can create your own.
Next steps
This was quite a long journey and I hope you now understand better how Apache Kafka works. To dive deeper, check out these articles exploring detailed topics in the Kafka journey:
- how you can create a data generator to source data into Apache Kafka cluster,
- how to use kcat - a very handy utility to work with Apache Kafka from command line,
- how to apply Karapace schema registry to align the structure of data coming to Kafka cluster,
- how to use Apache Kafka® to migrate across database technologies.
- or does Apache Kafka® really preserve message ordering?
- also have a look on Apache Kafka® and the great database debate
- and Broker communication in Apache Kafka® 2.7 and beyond
Also see the earlier post, What is Apache Kafka®, for more in-depth information about Aiven for Apache Kafka® and resources.
Finally, see a curated list of articles related to Kafka and the streaming ecosystem.
