



Aiven for Apache Flink: New features added in Q2 2023.
Back in February 2023, we launched Aiven for Apache Flink as a fully-managed Flink service that evolves around three key themes:
- The ability to run Apache Flink applications in the cloud of your choice, including AWS, Google Cloud and Microsoft Azure.
- The simplicity of using the Flink SQL and Table API to run unified queries on top of real-time data
- A Flink automation layer that allows users to eliminate the operational overhead of deploying, running, monitoring and managing open source Apache Flink for production workloads.
After the first three months of launching the service, we are excited to bring some new enhancements to Aiven for Apache Flink that will enable our customers to easily connect their Flink jobs to the rest of their infrastructure and allow them to scale their stream processing applications to bigger volumes as their usage and adoption of Aiven for Apache Flink grows. Today we are introducing:
- Aiven for Apache Flink can now read data from/write data to instances of Apache Kafka that may or may not be managed by Aiven.
- Aiven for Apache Flink now comes with a built-in CDC Connector for PostgreSQL.
In the following sections, we discuss the latest enhancements to the Flink service and share additional background on how to leverage them for stateful stream processing with Aiven.
Integration with all types of Apache Kafka clusters
The first release of Aiven for Apache Flink came with built-in integrations for other Aiven services with a few simple steps including Aiven for Apache Kafka®, Aiven for PostgreSQL® and Aiven for OpenSearch®. However, modern stream processing computations oftentimes require the processing of events from multiple places. At Aiven, we want customers to experience such streaming applications, no matter where their data is residing, especially for bigger scale and more sophisticated scenarios. This is why we now make it available to connect Aiven for Apache Flink services to all types of Apache Kafka clusters — whether they are fully managed by Aiven or not. This significantly improves the efficiency of a data pipeline and encourages data sharing and collaboration across various teams within an organization.
For example, Aiven users can now easily connect Aiven for Apache Flink to clusters that are self-managed and process events in real-time for streaming analytics use cases. This can be the case for specific types of events that might need to be retained to a Kafka topic that is managed on a client’s premises and not in the public cloud*. Users of the service can easily offload events to Apache Flink, perform any stateful computations and pass the events to downstream Kafka topics that reside in a fully managed environment like Aiven for Apache Kafka or in a self-managed environment of their choice.
A typical use case for this scenario would be stream processing and streaming analytics applications for data that is not managed by Aiven due to regulatory or other reasons. Users of our Flink service in highly regulated industries like financial services, government or healthcare can now retain full control of their data residency requirements by:
- Deploying Aiven for Apache Flink in their own cloud account, with Aiven’s newly introduced Bring-Your-Own-Cloud (BYOC) deployment mode
- Processing data in real-time with Aiven for Apache Flink from a Kafka topic that may or may not be managed by Aiven
- Passing the processed events to downstream Kafka topics (or other Aiven services) for further processing or analysis.
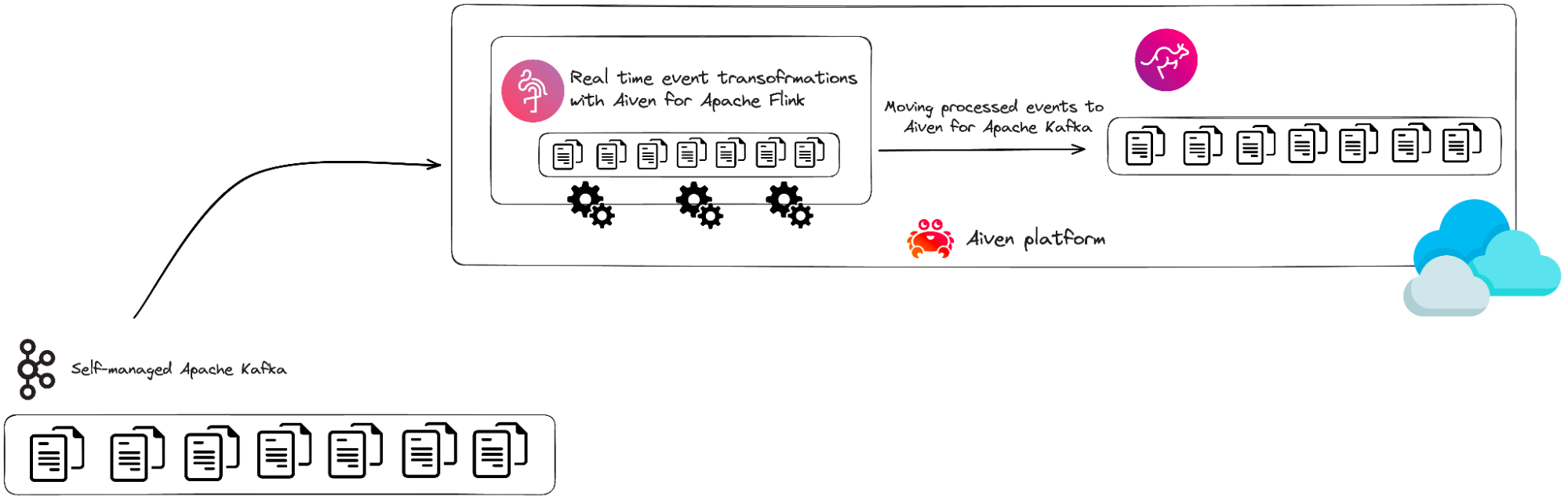
In addition, and in line with Aiven’s vision of being the trusted open source data platform for everyone, customers can now leverage the openness of the Aiven platform and process their data in real-time from Kafka topics that might be fully managed by other vendors in the market.
What Aiven customers now get out-of-the-box is the ability to leverage the simplicity and scalability of Flink SQL with Aiven for Apache Flink for real-time data processing without the need to migrate their entire Kafka infrastructure to Aiven.
Change Data Capture(CDC) connector for PostgreSQL
Aiven for Apache Flink now comes with a CDC connector for PostgreSQL, using the Debezium framework for change data capture. Let’s take a closer look at CDC as a paradigm for capturing changes to your database and why it becomes an ever more prominent use case for Apache Flink.
What is Change Data Capture (CDC) and why you should care
Change data capture (CDC) is the process of identifying and capturing changes made to data in a database to track what and when is updated in an organization’s data and then alert and inform other systems and services that must react to such changes in real-time. Especially in today’s business environment, where data is frequently referred to as the lifeblood of the modern enterprise, keeping track of such data updates is becoming increasingly challenging — although being increasingly important. Just think about the frequency with which data is being updated for an e-commerce retailer. Any time a new transaction or order is recorded or new inventory is added or deleted. Having the ability to track and respond to such data changes in real-time becomes ‘a must’ for modern, cloud application development where multiple (micro) services are codependent on each other and must be adjusted according to all new recorded changes in a database.
Instead of upgrading any application or service at the same time as the changes occur in the source database — such as PostgreSQL or MySQL, Change Data Capture (CDC) can easily track row-level changes in source tables as insertions, deletions and updates to the data and make such changes available as events that can be consumed by other systems or services that depend on the changed data. Some interesting use cases for Change Data Capture include among others Data Replication workloads where data is replicated across systems and environments to ensure each data warehouse, data lake or relational database reflects the latest changes and status quo of the data. Another use case is Microservice(s) synchronization where multiple services need to be synchronized and updated (more often than not with low latency) with the latest updates to the respective data.
CDC connection from Aiven for PostgreSQL
Customers could previously integrate Aiven for Apache Flink with Aiven for PostgreSQL, however, this integration would be a query based approach which had some limitations, especially as this relates to memory utilization for low latency scenarios. In the standard setup, Aiven for Apache Flink users would need to process the entire dataset of the database (in a given period of time) and update any changes that occurred in that timeframe. With the CDC connector for PostgreSQL, Aiven users can now stream any changes in their PostgreSQL instance as events in real-time and send them to Flink for additional processing and/or transformations before moving the processed events to any downstream systems and operators. The updated connection makes it easy to process changes in a Postgres database and pass it on to Aiven for Apache Kafka to make such changes available to downstream services and applications or Aiven for OpenSearch for analytical workloads or logging purposes.
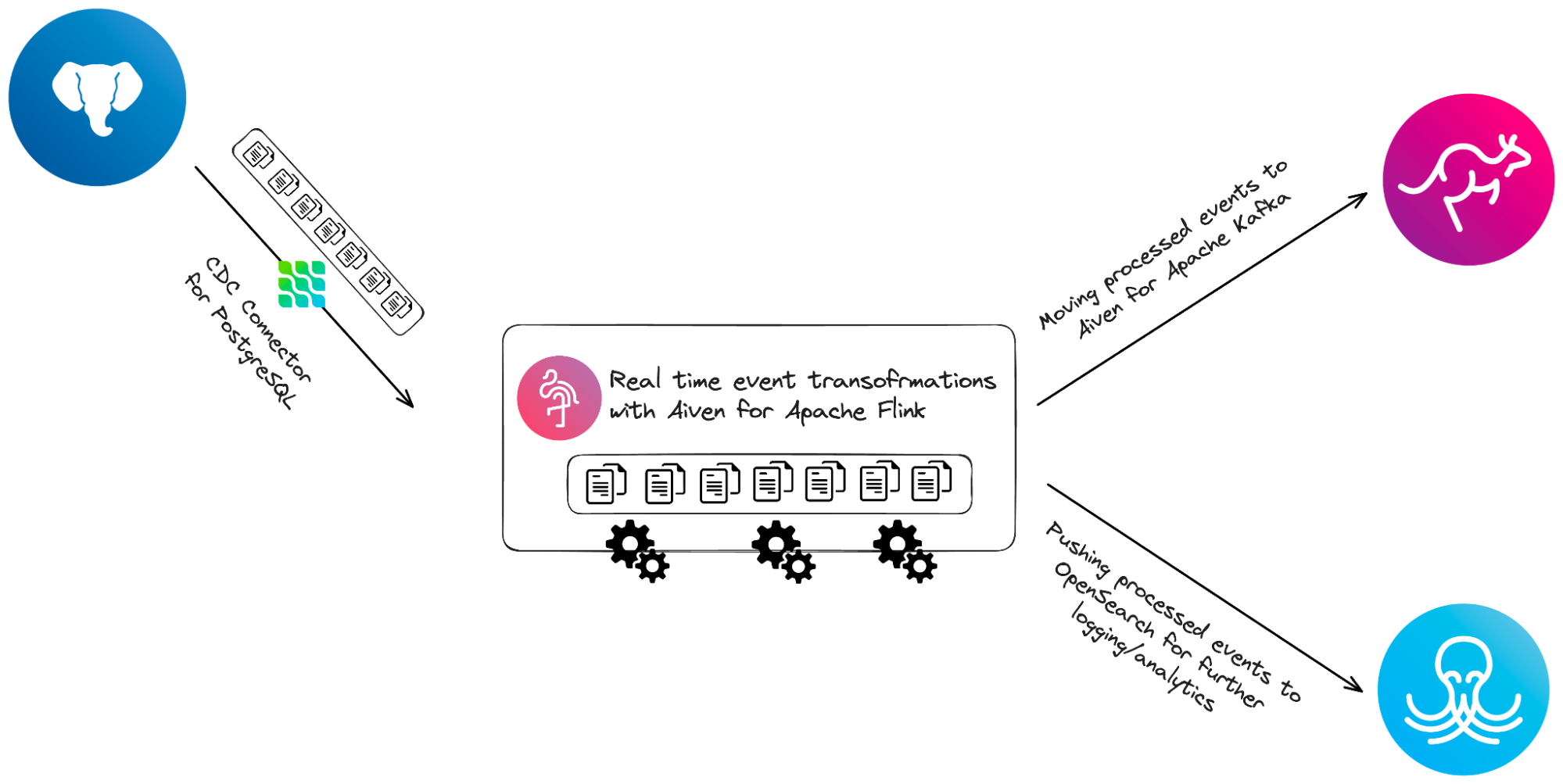
Existing and new customers of Aiven for Apache Flink can leverage the CDC connector for Aiven for PostgreSQL to quickly:
- Maintain a single source-of-truth with recorded changes to their PostgreSQL database(s) by synchronizing all other database instances, data warehouses and data lakes with the latest recorded changes to the data in real-time.
- For event driven architectures where multiple services are interconnected and react to events in real-time, customers can now ensure that synchronizing these services will happen more seamlessly and with sub-second latency resulting in smoother operations for their team.
How to get started with the new features
We are very excited to bring these new additions to our Flink service and cannot wait to show what’s in store for Aiven for Apache Flink in the future! To take advantage of the new features in the product, be sure to perform a maintenance upgrade to your Flink service. If you haven’t used Aiven for Apache Flink and are brand new to Aiven, you can sign up for a 30-day trial here and start your stream processing and real-time analytics journey with Aiven!
If you have additional feedback or requests for our product, we would be happy to hear your suggestions here.
Pricing and Availability
Aiven for Apache Flink is available on all major hyperscalers - AWS, Google Cloud and Microsoft Azure - in over 100 regions globally.
All Aiven for Apache Flink plans come with a minimum of 3-node setup, providing resilience and high availability while ensuring minimal downtime even in the case of a node failure.
Aiven for Apache Flink is priced per hour, with prices starting from $0.57/h ($400/month).

Table of contents
- Aiven for Apache Flink: New features added in Q2 2023.
- Integration with all types of Apache Kafka clusters
- Change Data Capture(CDC) connector for PostgreSQL
- What is Change Data Capture (CDC) and why you should care
- CDC connection from Aiven for PostgreSQL
- How to get started with the new features
- Pricing and Availability