


TL;DR
Diskless Kafka splits storage from compute, delegating replication to cheap object storage and turning Apache Kafka® Brokers into a stateless compute layer. It’s 100% Kafka, and 80% cheaper.
But in the cloud, a cheaper underlying technology does not always mean you pay less. The cost varies significantly depending on the deployment model - SaaS or BYOC. In this article, we will learn why:
1. Fully-managed solutions do not always reduce costs as much as you think
2. Bring Your Own Cloud (BYOC) fits Diskless perfectly
Over the past year, as we built Diskless Kafka, the question we have received most consistently from Kafka operators has been “What exactly is BYOC—and is it worth the added complexity?”
Short answer: yes, if you're operating at scale.
Diskless BYOC nails the three E’s:
- Economics: Diskless eliminates inter-AZ replication and local disk storage. BYOC removes cross-account networking. Together: up to 80% lower TCO.
- Enforcement: Open Source Kafka data plane runs entirely inside your cloud boundary. You control VPC peering, IAM, and KMS keys.
- Enterprise Discounts: All infra spend stays under your org’s cloud bill—qualifies for committed-use discounts and centralized cost tracking.
If you're pushing gigabyte scale workloads, have a Kafka bill north of $100k/year, or need to prove compliance boundaries without DIY, Diskless BYOC is the only Kafka architecture that hits all three. Diskless runs inside your cloud account, you own the IAM, VPCs, and audit trail. Data stays within the perimeter; cross-account networking disappears. The best thing? All cost savings are directly passed down to you.
We’ll walk through the common pitfalls, the cost model, and when to switch. Let’s dive in.
3 Ways to Buy Kafka in the Cloud (and Why Only One Is Truly Yours)
If you write code for a living you’ve probably heard of BYOC—but it’s often lumped together with “serverless,” “dedicated,” or plain-old “managed” and left to fend for itself. No wonder there’s confusion. To clear the fog, let’s do a lightning tour of the three ways you can consume Kafka today without doing it yourself.
Multi Tenant SaaS, “Serverless” (Topic-as-a-Service)
TL;DR: You book a room in a hotel
You rent a handful of Kafka topics on an oversubscribed mega-cluster.
- Control: Topic-level only, plus a single, vendor-defined auth—no custom IAM roles, no bring-your-own certificates.
- Trade-off: Perfect for prototypes; gets dicey for 24/7 production once the neighbour’s traffic spikes or your CISO’s security checklist hits.
- Good Fit: Spiky, low-to-medium throughput workloads where “spin-up fast” beats “fine-grained control and airtight network isolation.”
Single Tenant SaaS, Dedicated Cluster
TL;DR: You rent the whole house.
You rent an entire set of VMs or containers in a vendor's account. Full tenancy, full SLA.
- Control: Service, Broker, and Topic. You can tweak ISR counts, log segment sizes—everything.
- Trade-off: The house is on the vendor’s land, so every message crosses an account boundary: you still juggle partition counts, AZ placement, and a perpetual $0.01–0.02/GB network toll. PrivateLink can wall the traffic off, but you pay for the tunnel and the bytes. Bottom line: you turn the knobs, the vendor owns the data path.
- Good Fit: Always-on, business-critical pipelines that need hard isolation but can stomach higher network costs and the legal reality that the data lives outside your perimeter.
Bring Your Own Cloud (BYOC)
TL;DR: You own the house.
You only rent the code, but it runs inside your AWS/GCP/Azure account—next to your producers and consumers.
- Zero Ingress/Egress Surprise: Data never leaves your perimeter.
- Operations: The vendor still patches, scales, and carries the pager. You just monitor CloudWatch or Stackdriver.
- Cost Curve: You pay your usual cloud bill—no vendor mark-up on compute/storage—just a management fee on top.
For more than a decade, the industry playbook has been: treat Kafka like an API, not a Cluster. You punch in a credit card, pick a region, dial the SLA slider, and—poof—topics or if you have larger workloads, clusters appear.
But the moment before you click “Create” you must ask the provocative question that every architect eventually faces: Do you want your Kafka easy…or do you want control and safety?
Vendors do their best to guide you (we do too!) —“start small and graduate later,” “just pay for what you stream”—but when the firehose hits a few MB/s and the data runs critical business processes, the math (and pricing incentive) tilts toward a stable dedicated cluster almost every time. After all, you rarely wake-up on a random Tuesday morning asking for “some Kafka in your life”, Data Streaming is an elite discipline which mandates careful planning.
Which raises a puzzle: if the answer is always “get a dedicated Kafka cluster”, why are we even talking about BYOC? After all, it’s still the same managed service—just deployed in your cloud account instead of the vendor’s.
You guessed it: the cloud is hiding something. Stick around; we’re about to pull the curtain on that mystery.
The Hard Truths of Kafka Consumption
Usage-based billing sounds perfect for Kafka—pay only for what you write, store, and read. But, as we discussed, the moment Kafka traffic goes from hobby to heavy, you quickly realise you’re feeding two meters at once:
- The cloud provider’s meter—every byte that moves, every zone it crosses
- The Kafka vendor’s meter—an extra markup stacked on the very same bytes
Ask yourself: When you sign-up for “fully-managed” streaming, how many times does that byte get resold before it lands in your consumer?
Here’s the real kicker: the priciest part of “Kafka” isn’t Kafka. It's the data moving within and around Kafka - the swarm of producers, consumers, connectors, and ETL jobs slinging data in and out. As we discussed in previous blogs, every hop lights up a data-transfer tollbooth.
If you want to understand Kafka’s SaaS pricing, there’s an important separation to make between cloud costs and vendor markups. Most vendors target ≈ 80% gross margin. Translating that to Kafka means that If a new feature burns $1 of cloud COGS—compute, storage, network—the list price must be $5. $1 is only 20% of $5; the other 80 % funds salaries, support, R&D, and profit.
Now layer it on Kafka’s physics:
- Cloud margin — every byte pays AWS or GCP first.
- SaaS margin — that same byte gets repackaged at 5× to hit the 80 % goal.
- Read amplification — Kafka fans each byte out to multiple consumers, so the whole stack re-charges it 2-3-4 times over.
A per-gigabyte transfer price that looks tidy on paper is really cloud tax × vendor multiplier × fan-out factor.
But nothing gives a better picture than a real-world example: let’s watch the “pay-as-you-go” model crack along the Produce → Consume path for a real-world 500 MB/s Kafka.
Produce
A typical usage-based SaaS model says “writes cost $0.05 per GB,” so you budget for five cents. What the price sheet glosses over is the extra $0.01 per GB AWS charges the moment your producers push bytes out of your VPC and into the vendor’s public endpoint. Remember - one byte, two cash registers.
Why is that penny so stubborn? Because most default deployments connect over a public IP; wiring private IPs across VPCs means PrivateLink, CIDRs, Terraform—hardly a “quick-start.” And remember: AWS still applies the cross-AZ tax even when the traffic never leaves the AZ as long as it rides that public hop.
- How much do you budget for?
500 MB/s × 31 days ≈ 1.3 PB a month → $785k a year to the vendor. - How much extra data is that?
500 MB/s × 60 s × 60 min × 24 h × 31 days ≈ 1,309,000 GB a month - What does it cost additionally?
1,309,000 GB × $0.01 ≈ $13,100 every month—or roughly $157k a year.
That unaccounted costs changes nothing about durability, retention, or replication of your Kafka; it’s just the toll for letting bytes cross the street into your vendor’s account. And because most “quick-start” setups ride a public IP—even inside the same AZ—the meter never stops.
Consume
Kafka’s super-power is read amplification: most use-cases expect at least three consumer groups for every producer. That 3× multiplier means our 500 MB/s write stream becomes 1.5 GB/s on the way out.
- Data OUT fee. Let’s use the same $0.05/GB for reads. Multiply:
1.5 GB/s × 31 days ≈ 4,017,600 GB/month → $2.4m a year just in “usage.” - Cloud toll behind the curtain. same 4 PB × $0.01 / GB = another $490k a year in AWS ingress inter-az fees.
Before we deep dive in the wild-west of Networks, Kafka storage hurts too! Say you have 0.05 / GB-month for a single copy of the log. Kafka keeps three. So the true bite is $0.24 / GB-month—about 10× the price of parking the same data in S3.
Add it up and a workload that looks like “$0.05/GB, no surprises” snowballs into $647k per year in cross-account network charges alone. So the real question is: what if we could erase those toll booths—keeping every byte inside your own VPC—and finally unleash the pent-up demand for truly massive, fully managed streaming? That’s precisely the gap BYOC is built to close.
🚨 Confusion Alert 🚨
In AWS you’ll even pay the $0.02/GB cross-AZ tax inside the same AZ if the traffic is over a public IP - which is the default account to account set-up! You discover the cross-AZ toll hiding in your bill and think, “Easy—let’s switch to private networking.” But, is it though?
First stop is VPC peering. It’s free on paper—until you realise every VPC must have a non-overlapping CIDR block. One duplicate subnet and the peering fails, which means renumbering workloads that have been humming for years. Add two more VPCs and the peerings explode into a full mesh; suddenly you’re mapping routes like an air-traffic controller - do you want to do this with a third party vendor?
You pivot to a Transit Gateway—clean hub-and-spoke topology, far less subnet juggling. Then the first invoice lands: AWS charges the same $0.02 per GB at the gateway itself plus a fixed hourly rate, effectively doubling the fee you were trying to erase. Now you’re paying the toll and running the toll plaza.
Next option: PrivateLink. Secure, one-way, and blissfully oblivious to overlapping CIDRs. But it isn’t quite free either—about $0.01 per GB—and Kafka’s brokers now advertise odd DNS names that every producer and consumer must learn. Each new AZ needs its own endpoint, each endpoint its own quota of IAM, TLS, and Terraform plumbing. The “managed” service now comes with a 30-page network run-book. Fallback? Keep the public endpoint and rely on NAT. Cost drops, security teams panic, and of course you’re right back to paying cross-AZ rates for traffic that never left the building.
In short, every escape hatch either reinstates the toll in a different guise or replaces it with weeks of network archaeology. So much for drop-in convenience. Shall we look at BYOC now?
The 3 E’s of BYOC: Enforcement, Economics, Enterprise-discounts
(A three-question stress test for whether BYOC is really your move.)
Before we declare BYOC the winner, let’s take a step back. A handful of security‑sensitive customers asked Aiven to run Kafka inside their own cloud accounts without losing managed‑service uptime in 2018 (We built the first BYOC — custom account wiring, live‑incident hooks, zero‑downtime version upgrades— and have expanded it ever since.)
A BYOC cluster looks almost identical to one running in our VPC, yet it exists for a specific set of pain points. Decide if those pain points are yours by running through three brutally honest questions:
Enforcement | Can my data legally leave the house?
E-commerce keeps carts on-shore, hospitals quarantine PHI, telcos hide keys in hardware vaults—yet all that rigor crumbles if a single zero-day breaches the SaaS provider’s VPC where your data plane lives. This is a big deal because a single breach, can endanger your entire Kafka setup.
BYOC shrink-wraps Kafka inside your security boundary: your keys, IAM, flow logs, kill switch. The vendor still handles patches and scaling, but any blast radius stops at your VPC wall. New law? New exploit? Non-issue—because the data never left the building. BYOC is the only way to lock down Kafka’s data plane without going back to DIY toil.
Economics | How much do I write, and who’s reading?
Remember the math from our 500 MB/s example? That stream pushes 1.3 PB IN and 4 PB OUT every month. Because the bytes hop from your VPC to the vendor’s over a public IP, AWS tallies them as cross-AZ traffic—$0.01/GB on your side, another $0.01/GB on theirs. That’s $53k every month—$647k a year—in tolls no pricing page warns you about.
Stanislav Kozlovski did a great cost anatomy post which powerfully visualizes the problem. There is also a lesser known piece by Redpanda on the same topic.
AWS will happily sell you PrivateLink to knock the toll down to ~$0.01/GB + a monthly fee, but that’s still a six-figure line item with zero business value. BYOC vaporizes the toll entirely—producers, brokers, and consumers live inside the same account, chatting over a free network. That’s the superpower of BYOC: it turns the physics of cloud bandwidth into a rounding error on your cloud bill.
Bonus: those bytes now count toward your own compute/storage discounts instead of padding your vendor’s bill. Which leads to..
Enterprise Discounts | Whose cloud-commit discount is bigger?
High-throughput streaming is an elite sport. Sustaining GB/s isn’t “turn on a feature”—it’s an entire engineering culture, and it usually drags seven-figure cloud commitments behind it. Your FinOps team already lands platinum-tier discounts:
- Every Kafka broker you rent from a vendor’s VPC is a broker you could have run at 30-40% less inside your own.
- BYOC lets you double-dip—vendors manage the ops, you harvest the CSP rebate.
That kind of structure comes with multi-million dollar commitments— 20% off EC2, 30% off S3, 80% off Networking, maybe more. Every VM you rent in a vendor’s VPC burns those discounts to ash. Move the cluster into your own account and the same bytes now count toward your rebate. You keep the managed-service brain, but the bulk-buyer coupon stays in your wallet.
Simply put: BYOC doesn’t lower the list price; it leverages the discount you already have.
The Take-Home
If your Kafka is small i.e. 5-10 MB/s, your cloud bill modest, and your compliance team mellow, classic SaaS is perfect easy wins, zero plumbing.
But the moment the meter tips, discounts kick in, or regulators circle, you hit the fork in the road: Do you want Kafka that stays easy—or Kafka you can control?
BYOC exists so you can finally answer, “How about both?”
Cracking the BYOC Pricing Code
(spoiler: the “mystery” is mostly smoke)
We’ve shown how consumption pricing collapses under scale—but BYOC stickers can still look like stage-magic. Surely there must be some gotchas?
A-ha #1: Only Two Vendors Publish Numbers
Go price-shopping for BYOC Kafka and you’ll find a desert: Aiven and WarpStream are the lone booths with a sticker on the window. Everyone else treats BYOC like the secret menu at a restaurant—“Ask the waiter, he’ll whisper a number.” The irony? The heavy lift already shows up on your cloud bill, not ours. All a vendor really needs to charge for is the stewardship: upgrades, monitoring and the four nines.
Why the Curtain?
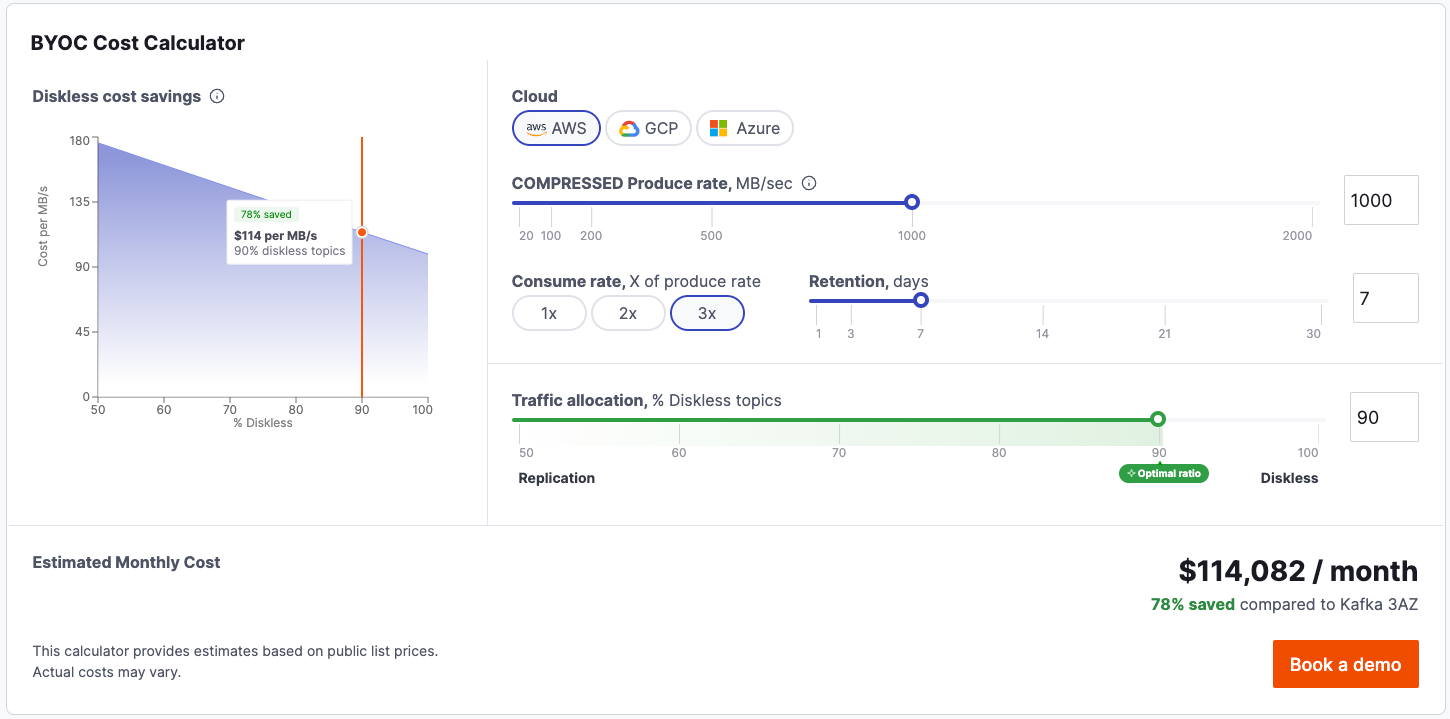
Because a “management fee” looks like pure margin on a spreadsheet—and margin invites haggling. Easier to keep the line item invisible. We went the other way: Aiven’s BYOC Cost Calculator breaks the price down—VM class, storage tier, support overhead—so you can audit it quickly and decide for yourself.
A-ha #2: The Exotic Work-arounds
Similar to consumption pricing in SaaS, lately we’ve seen two anti-patterns in BYOC pricing:
- Self-Reported Fees – You comb CloudWatch, tally usage, and wire the vendor each month.
- Half-in / Half-out Architectures – Parts of the Kafka protocol (batch coordinators, metadata services) stay in the vendor’s VPC so they can charge “traffic” like SaaS.
Both feel innovative until you look closer:
- More moving parts to certify for compliance.
- More cross-account traffic, the very thing BYOC was invented to eliminate.
- More meetings when someone fat-fingers the usage report.
High-scale BYOC customers don’t want a carnival of meters; they want a partnership: a clear monthly fee, a volume-based annual commit, and zero data leaving the house. Anything else is a step backward disguised as progress.
BYOC pricing doesn’t need to be mystical, at Aiven we believe it should be boring. Publish the fee, show the math, and let customers validate the TCO against their own cloud discounts. The moment you do, the “mystery” evaporates—and the real conversation can start.
BYOC and Chill
We joke internally that “Diskless BYOC is a $100K-and-up club.” Not because we’re price-gouging, but because the very need for BYOC is a litmus test:
- Your Kafka is mission-critical. Hundreds of megabytes per second makes economics impossible to ignore.
- Your cloud discounts are real. You’re already on a first-name basis with your CSP’s enterprise rep.
- Your CISO is nervous. Data residency or regulations mean nothing can cross the street.
When all three lights are flashing, that six-figure line item quickly looks like the cheapest decision in the room—and the only way to keep streaming simple and under your control.
Ready to see if you’re in the $100k-and-up club? Try the Cost Calculator now and get an instant, line-item comparison.
Happy streaming 🚀

Table of contents
- TL;DR
- 3 Ways to Buy Kafka in the Cloud (and Why Only One Is Truly Yours)
- Multi Tenant SaaS, “Serverless” (Topic-as-a-Service)
- Single Tenant SaaS, Dedicated Cluster
- Bring Your Own Cloud (BYOC)
- The Hard Truths of Kafka Consumption
- 🚨 Confusion Alert 🚨
- The 3 E’s of BYOC: Enforcement, Economics, Enterprise-discounts
- Enforcement | Can my data legally leave the house?
- Economics | How much do I write, and who’s reading?
- Enterprise Discounts | Whose cloud-commit discount is bigger?
- The Take-Home
- Cracking the BYOC Pricing Code
- A-ha #1: Only Two Vendors Publish Numbers
- Why the Curtain?
- A-ha #2: The Exotic Work-arounds
- BYOC and Chill