


TL;DR — Diskless is Kafka
KIP‑1150 - Diskless Topics is live. KIP-1150 Diskless Topics ship in Aiven Kafka BYOC on AWS, GCP, and Azure. Data goes straight to object storage—no local replicas, up to 80% lower TCO.
One flip of a switch, three wins:
- 💸Slash cost: Eliminates pricey inter‑AZ traffic and SSD spend
- 🔥 Erase toil: No rebalances, no hot partitions, no IOPS ceilings
- 🔓 Stay free: Its just Apache Kafka—zero vendor lock‑in
Need sub‑100 ms latency? Keep topics on hot replication. Want rock‑bottom cost for logs, telemetry, or backfills? Flip to Diskless. No other diskless solution lets you make that call per topic—one cluster, one protocol, two economic profiles.
No migrations, no API changes. The patch touches about 1.7 % of Kafka’s core, is fully upstream‑aligned, and is already published in a temporary Github repo while the KIP works its way into mainline. We are running diskless in production for some of our logging needs, and we have begun onboarding our first users in BYOC. Self‑managed teams can clone the repo and benchmark their own $‑per‑MB/s improvements.
What makes Apache Kafka so good?
Ask ten engineers why they pick Kafka, and you’ll hear “high throughput”, “exactly‑once semantics”, and “back‑pressure”. Here’s the thing: none of those explain the meteoric adoption.
Picture day 0: an ops team CDCs the payments table into a Kafka topic. On day 1, a fraud‑detection service subscribes and starts flagging anomalies. On day 2, finance spins up an audit‑log consumer that archives the same stream to cold storage. On day 3, an intern asks, “How do I trigger autoscaling before traffic spikes?” The answer is a one‑liner: “The payments topic already exists—just read it.” No extra ETL, no glue jobs, no new ACL dance.
Every additional topic compounds this value. Logs feed dashboards, dashboards feed risk models, risk models feed decision engines—all by pointing a new consumer at data already in the log. The more services you attach, the more attractive Kafka becomes for the next idea, creating a self‑reinforcing loop inside the organisation.
Today, the market is full of “Kafka‑compatible” offerings that break that flywheel. They force you to fork your estate: keep one cluster of Kafka brokers for sub‑100 ms streams, spin up a second, object‑store‑backed one for cheaper logs, then migrate or mirror data between the two. Each copy adds latency, burns network traffic, and—the worst sin—splinters the very network effect that makes Kafka valuable. The moment engineers must ask, “Which cluster has the truth?” you’ve lost the zero‑integration promise and, with it, most of the benefits you chased in the first place. Diskless Kafka keeps everything—low‑latency streams and ultra‑cheap backfills—inside one logical log, so the data gravity and the cost saving pull in the same direction.
So our vision is Kafka’s original vision - to be the friction‑free data mobility layer: a single logical cluster that serves every streaming workload — and soon, with geo‑aware object stores, across regions as well. All use‑cases share a single ordered log, advertised by the same protocol, and routed by the same brokers. That’s why organisations with thousands of topics keep adding thousands more: the cheapest integration is the one you never have to build.
Cloud economics is starving Kafka
In the cloud, each extra megabyte drags along SSDs, inter‑AZ egress, and days of rebalancing. We routinely see >80 % of a cloud Kafka bill tied to cross‑zone traffic alone. Faced with that tax, many teams throttle data or shelve new pipelines. Their most common question to us: “What’s next for our streaming roadmap if we can’t afford more streams?”.
When we floated KIP‑1150, the replies from maintainers, web‑scale operators, and prospects all landed on the same word: “Finally!” In three weeks, we logged dozens of threads, and the shared vision is now crystal clear:
Let's try to make diskless the default Apache Kafka deployment.
Kafka’s vitality showed up in the numbers. The month we posted KIP-1150 also logged a record 22 new KIPs—covering everything from client ergonomics to security hardening. Two stand-outs: Slack opened a proposal to streamline large-queue workloads, and AutoMQ open sourced major portions of its cloud-native engine. For the full breakdown, check the April 2025 Kafka Monthly Digest by Mickael Maison.
That surge also highlights Kafka’s second network effect—at the ecosystem level. Every time a new company standardises on Kafka, it hires or upskills engineers who, in turn, send patches upstream. More adopters → more contributors → more commits → better stability and features → even more adopters. Diskless slots neatly into that flywheel: by shaving up to 80% off cloud TCO, it lowers the barrier for the next company to choose Kafka, which means a larger contributor pool tomorrow. The screenshot above isn’t a boast about Diskless alone; it’s a heartbeat monitor showing that the project itself is accelerating. As we wrote, Kafka is a rocket still clearing the launchpad—and we couldn’t be more excited to help fuel it.
The community response also torches another classic false narrative —“Open source isn’t enterprise‑grade.” Datadog’s triple‑digit‑gigabit ingest, LinkedIn’s trillion‑event firehose, Netflix’s playback mesh—all run upstream Kafka. Quality lives where the commits do, and Diskless keeps that lineage intact.
That’s the essence of Kafka’s power: the more topics—and the more contributors—you add, the more valuable the whole ecosystem becomes.
The tide is rising; all we have to do is keep shipping.
All You Need is One (Flag)
Most managed services treat upstream code as a dependency. Aiven treats it as home. Every change we write—bug fix, performance tweak, or a brand‑new feature—lands in a public GitHub repo before (or at the same time as) it powers our services. If you run Aiven for Apache Kafka , you’re running OSS Kafka—full stop. This is why we designed adopting Diskless to be just a flag:
kafka-topics.sh --create --topic payments --config diskless.enable=true
That’s it. Same clients, same ACLs, same monitoring—up to 80 % cheaper at scale and able to spin brokers in or out in seconds. Think of it as a routine version bump that quietly deletes an entire class of IOPS bottlenecks, inter-AZ costs, SSDs, leader re‑elections, multi‑hour rebalances, and hot‑partition firefights.
Kafka is evolving into a smart, ordered log proxy in front of S3‑class stores that also supports hot disk paths for low latency. KIP‑1164’s Batch Coordinator is the switch‑yard that keeps both lanes in lock‑step, but that dual mandate—support on premise clusters with no object store and hyperscale clouds that punish every cross‑AZ byte—has slowed truly radical change.
Tiered Storage taught us a lesson: when a foundational feature takes years to reach upstream, forks multiply, costs stay high, and the network effect stalls. We won’t let Diskless replay that history. Shipping the code on day one—and pushing every commit upstream as the KIP advances—keeps the community on a single path and a shared roadmap. Gate‑keeping innovation — is acceptable for dashboards, connectors, or niche optimizations. But holding back replication primitives like Diskless isn’t: it fractures the protocol, weakens the network effect, and taxes every other user for the privilege.
Delivering Diskless, therefore, tackles two chronic issues at once:
- Gatekeeping- All code lives in the public Git repo and is upstream‑bound in real time— there will be no “enterprise” edition.
- Cloud pricing - by replicating via object storage, we remove the cloud-cost penalties that distort the streaming market.
Put simply, we’re betting on progress, not inertia—and we’re betting in the open.
So, can we solve for both costs and innovation lead time in one swing? Can Diskless offer an upstream exit? Today?
Introducing Diskless for Apache Kafka
Back in 2020, a handful of security‑sensitive customers asked Aiven to run Kafka inside their own cloud accounts without losing managed‑service uptime. We built the first Bring Your Own Cloud (BYOC) playbook—custom account wiring, live‑incident hooks, zero‑downtime version upgrades— and have expanded it ever since. Today, BYOC is self‑serve on AWS and GCP (Azure next), carrying 18 GB/s of Kafka traffic—about one‑third of our global fleet—alongside PostgreSQL®, Opensearch®, and more. Others now market BYOC, but the operating model— from IAM scaffolding to 3 a.m. pager rotations—started here to maintain 99.99% reliability. Today, we add the next logical step: Diskless BYOC.
Why start with BYOC?
Diskless lands first in BYOC because that is where costs are most visible: every gigabyte passes through the customer’s cloud bill, not ours. Flipping the diskless topics ON will show savings in the next invoice—no hand‑waving, no contract re-negotiation/renewal, just a smaller invoice for our users if they opt in.
“Sounds cool, but what changes under the hood?”
Here’s the unexpected part: almost nothing you have to touch.
- Write path: producer batches stream straight to object storage; we postpone offset assignment until a lightweight SQL sequencer commits them.
- Read path: broker asks the sequencer for coordinates, hits an edge cache first, then object storage if cold. Offsets are stitched back in before the records leave the broker.
- Housekeeping: a background compactor fuses tiny objects into larger ones to keep read amplification low.
- Kafka 4.0, KRaft‑only: no ZooKeeper sidecars, fewer moving parts.
Because Diskless is Kafka, the BYOC rollout was almost boring: during our scheduled upgrade to Kafka 4.0/KRaft, a single engineer spent four weeks and touched fewer than 2.5K new lines, including new tests in our pipelines to recognise the new topic.type=inkless flag. All the disk‑health probes, rebalance logic, and IOPS alarms stayed in place for classic topics; the patch simply skips them when a partition never touches an SSD. In short, Diskless is grafted onto the control plane the way any minor feature would be.
Aiven is Diskless user #1
Before opening the service to early customers, we pointed our internal producers and consumers to diskless for some of our services. As we hinted in our first blog post, Aiven stands to gain a lot from diskless topics. As a matter of fact, we are user #1 of Diskless in production. At Aiven, we have 170+ thousand free-tier services for Postgres and MySQL. All free tiers come with lower SLA than production databases (99%) and best-effort reliability, but there is a need to support hundreds of thousands of developers in the most cost-efficient way. A solution like diskless is a natural addition to how we handle our logging for our free tier, driving our bills down.
Some of our free-tier logging traffic — circa 100 MB/s (at 4x compression) across three regions—now flows through small-scale production Diskless clusters. The first goal is reliability, not latency: tackling data loss, memory leaks, and four-nines availability. Current p99 latency sits around 3-3.5 s. We already see a clear path to sub-2 s with basic tuning, and we’ll do a deep dive, but the beauty of mixed deployment is we don’t have to chase milliseconds where they don’t matter; workloads that need low-latency can run on hot-replicated topics, while cost-heavy streams live on Diskless.
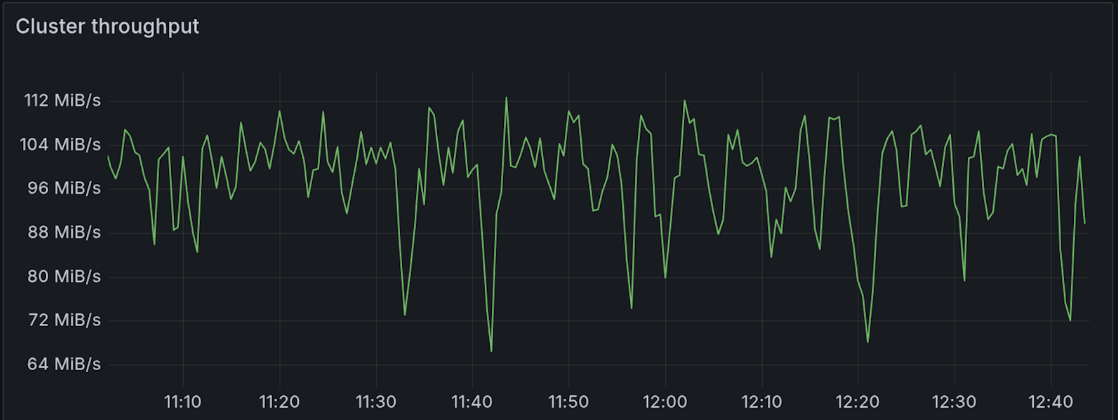
The disk usage graph shows that despite 100 MiB/s cluster throughput, the actual disk usage remains near zero (only for KRaft metadata and internal Kafka topics took approximately 30 mb).
Diskless flips the cost equation so completely that we can now store every partition-placement event our control-plane emits—we perform over 5 thousand every few seconds—and keep a full, queryable audit trail for pennies. We intend to power a cold-standby DR cluster that mirrors every topic across regions at near-zero cost until the day we route traffic to it. And with object storage as the sink, months of verbose logs, long-tail metrics, and on-demand backfills that once drowned SSDs now can sit cheaply beside our sub-100 ms streams, turning “too expensive for Kafka” into “why not?”.
We’re already sustaining gigabyte‑per‑second Diskless topics in our soak tests—expected, given that direct‑to‑object‑storage paths scale extremely well. The real exam starts next: we are scheduling to hand the full Kafka codebase—Diskless patches included—to Antithesis. Because Diskless rides the same core as Kafka, those chaos runs effectively will become the first end‑to‑end correctness campaign for Kafka itself. To our knowledge, no one has mapped randomized faults across the entire Kafka stack before; doing so we will generate a searchable backlog of Kafka issues and bugs for upstream maintainers. We’ll publish every trace—not just as marketing proof, but to harden Kafka for everyone.
Tiered Storage won’t fix Kafka, writing to S3 won’t either
Many teams assumed tiered storage would tame Kafka’s cloud costs. It didn’t: tiering parks cold data on object storage but leaves the replication hot‑path exactly where the invoices hurt —disks and cross‑AZ replication. Many companies delivered on truly groundbreaking direct-to-S3 designs. This batch-in-stream method is great for archiving, logs and metrics, useless if you need low-latency pipelines or near-real time decisions.
Talking with hundreds of large‑scale operators, we kept hearing the same frustration: “Give us one cluster, one API, but let us dial storage economics per topic.” Diskless BYOC does precisely that. Need sub‑100 ms latency for payments? Keep a classic topic. Want up to 80 % cheaper telemetry or backfill streams? Flip topic.type=inkless—in the same cluster, same clients, no vendor lock‑in.
This per‑topic knob ends the tired batch‑versus‑streaming debate. A single service can now have:
- Batch mode: blast multi‑GB/s logs, metrics, telemetry, and archival data
AND
- Real‑time mode: to power real-time use cases that make Kafka shine
But having an economics knob built-in Kafka is only half the story - we believe that by offering Diskless we regenerate Kafka’s network effect - the near zero incremental cost of adding use-cases after you have the streaming platform set-up. This compounding magic is no longer held back by cloud economics and will allow the protocol and the community to flourish for years to come.
To showcase our thinking, we have built a BYOC configurator which offers insight into your workload and demonstrates the cost savings based on what % of your cluster is diskless vs. being just Kafka. You can check it out here.
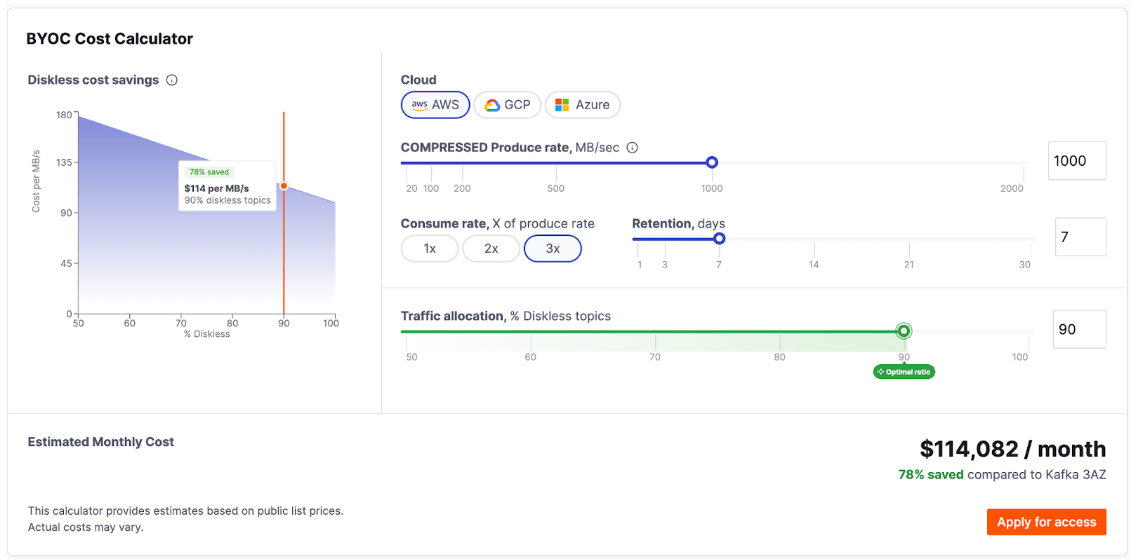
The configurator redraws instantly and shows where the dollar curve bends.
It also answers a counterintuitive question we get a lot: “Does Diskless always win?”.
Not quite—and the configurator makes that plain. Take Azure - cross‑AZ traffic is already $0, so Diskless can’t slash a fee that isn’t there, hence 0% benefit. So, if you’re comfortable (and you should be!) tiering to object storage after, say, < 1 hour of local retention, classic topics plus Tiered Storage can be as cheap as Diskless for that slice of data. The tool shows exactly where those inflection points live.
Towards the Lowest cost per MB/second
When we priced Kafka BYOC for Diskless Topics, we started with the only cost model that matters to an infra team: How many senior operators and infrastructure does it take to keep a fully‑tuned cluster—producer compression, tiered storage, follower‑fetch tricks? Drawing on our experience from managing thousands of Kafka clusters with 99.99% SLA (lately 99.995%) we took our own playbook and applied it.
Our fleet telemetry set the baseline assumptions:
- 1 senior Kafka engineer (~ $130 k/yr) carries ≈ 150 MB/s across hundreds of topics.
- Every additional 100 MB/s on a given cluster demands ≈ 0.25 Engineers for client onboarding, capacity tuning, and the inevitable 3 a.m. RCAs —even with modern tools like Strimzi, Cruise Control, and K8s in play.
We priced Diskless BYOC below that curve at every throughput band, funneling all object‑storage savings straight back to our customers. The result is a co‑pilot that keeps clusters healthy at four‑nines with near‑zero intervention while rarely costing more than half what the leanest in‑house team plus optimised infrastructure would (though in Azure we still recommend Tiered Storage!)
We’re onboarding early adopters now. If you want to benchmark your own numbers, hit the access form— we’ll get in touch to see how low your $ / MB/S can go.
Inkless: Born To Upstream
Today, we are also releasing Inkless—our deliberately short‑lived fork of Apache Kafka that makes Diskless Topics available right now. Because waiting years for a feature you need today is not an option. So we have open‑sourced Diskless Topics in a temporary fork we call Inkless.
Why “Inkless”?
Kafka’s name nods to Franz Kafka—the novelist who turned ideas into ink on paper, just as classic Kafka turns events into bytes on disk. Diskless breaks that loop: data still persists, but the “paper” is cloud‑native object storage. We could have named the repo diskless and surfed KIP‑1150’s buzz. We chose Inkless instead to signal two things:
- Different medium, same story. The write‑ahead log is intact; only the substrate changes.
- This project is provisional. Inkless exists solely to bridge the gap until upstream Kafka absorbs Diskless.
A fork we intend to retire
Maintaining a fork is a tax we’d normally refuse to pay—but waiting years for upstream merges would cost everyone more. Inkless is a staging branch, not a breakaway project. Every commit lands in a public GitHub repo and is queued as an upstream PR the moment the KIPs finish their vote. So far, the diff applies to Kafka 4.0 with almost zero merge conflicts—a strong signal that the code is fit for mainline.
We do not want two Kafka communities. If you care about Diskless, the right place to weigh in is the dev@kafka mailing list and the KIP threads; Inkless is merely the test harness.
When Diskless ships in upstream Kafka, Inkless will sunset. Upgrading will feel like any other minor version upgrade: bump the package, restart the brokers, keep streaming. Topics, offsets, ACLs—all stay put. No migrations, no data shuffles, no vendor lock‑in now or later.
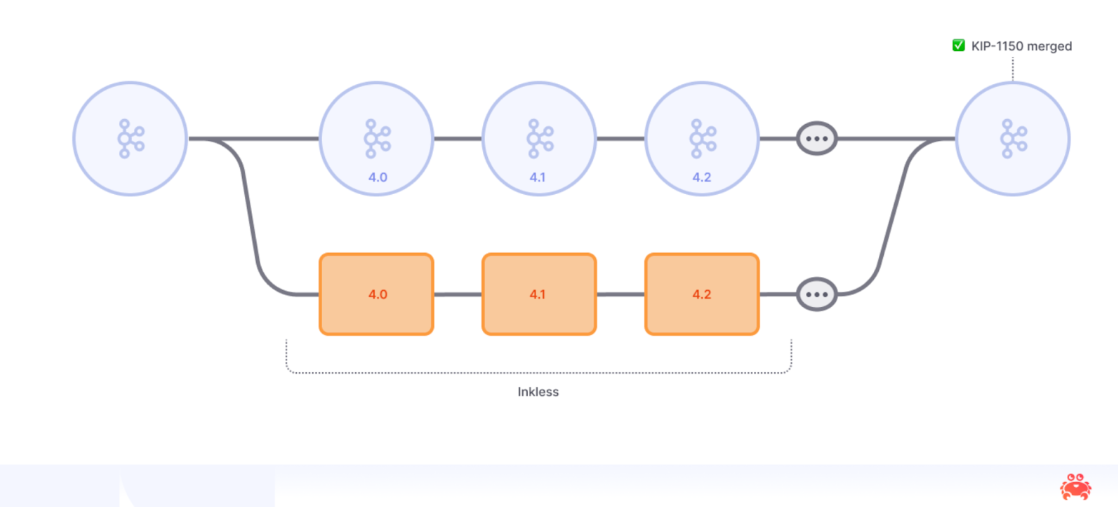
Inkless currently ships the familiar DB-backed coordinator you see in most object‑storage designs; it was the fastest way to get real workloads flowing. But our next milestone is a topic‑based coordinator as described in KIP-1164 that embeds ordering metadata into a Kafka topic, trimming coordination hops, and simplifying fault isolation. Design docs, prototypes, and pull requests will appear in the repo as they happen—one of the quiet super‑powers of open source.
Two adoption paths, one destination
-
☁️ Managed – Toggle “Diskless” in Aiven Kafka BYOC; our control‑plane handles upgrades, auto‑healing, and the 3 a.m. pager.
-
🛠 Self‑managed – Clone Inkless and see it in action on your laptop or CI box:
- - git clone https://github.com/aiven/inkless.git - - cd inkless & make demo
Behind the scenes, we are working on incremental fleet upgrades to Diskless as we revise pricing and explore the design space—material for another deep dive. For now, the intent is clear: Inkless is born upstream. Its sole purpose is to shorten the runway between an idea the community likes and a feature the community owns. When upstream Kafka ships Diskless Topics, we’ll archive the fork and celebrate one less divergence in the ecosystem.
Inkless is live, BYOC support is going to production soon, and the repo is wide‑open for inspection. Clone it, flip the flag, and tell us where it breaks. We’ll cover the next wave of Kafka features in upcoming posts, but your test runs and mailing‑list feedback will shape what ships first.
Having said all that, we just put KIP‑1150 up for a vote.
Kafka is rising — ride the wave with us.
Get started with Diskless for Apache Kafka
Learn more
Table of contents
- TL;DR — Diskless is Kafka
- What makes Apache Kafka so good?
- Cloud economics is starving Kafka
- All You Need is One (Flag)
- Introducing Diskless for Apache Kafka
- Why start with BYOC?
- Aiven is Diskless user #1
- Tiered Storage won’t fix Kafka, writing to S3 won’t either
- Towards the Lowest cost per MB/second
- Inkless: Born To Upstream
- Why “Inkless”?
- A fork we intend to retire
- Two adoption paths, one destination