


Diskless topics are proposed in KIP-1150, which is currently under community review. The examples in this article use "Inkless", Aiven's implementation of KIP-1150 that lets you run it in production.
I joined Aiven as a Developer Advocate in May, shortly after the Kafka Improvement Proposal KIP-1150: Diskless Topics was announced, which reduces the total cost of ownership of Kafka by up to 80%! It was very exciting to join Aiven just as the streaming team were making this major contribution to open source but I wanted to take my time to understand the KIP before sharing my thoughts.
In this article I’ll share my first impressions of Diskless Kafka, walk you through a simple example you can use to experiment with Diskless, and highlight some of the great resources that are out there for learning about the topic. First though, what actually is Diskless Kafka?
What is Classic Kafka?
To understand Diskless Kafka, you first need to understand how Apache Kafka® works today. Kafka data is stored and replicated across multiple broker servers using local disks. A designated leader broker handles all writes to a given partition, while follower brokers maintain copies of the data. To ensure high availability Kafka clusters are often deployed with cross-zone replication, where data is duplicated across different cloud availability zones, but this creates a significant cost problem. Up to 80% of Kafka's total cost of ownership comes from expensive cross-zone network traffic, with cloud providers like AWS charging per GB for data transfer between zones.
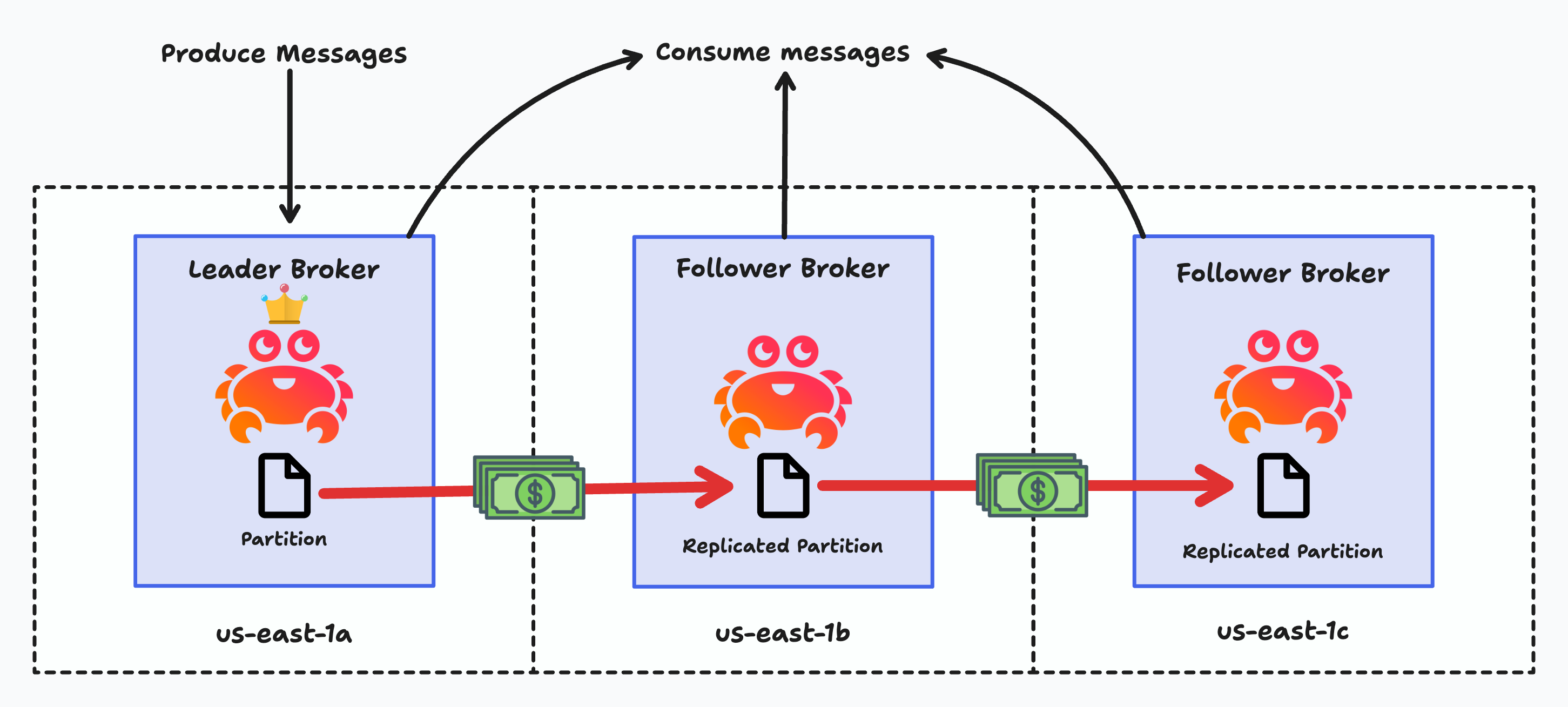
What is Diskless Kafka?
Diskless Kafka fundamentally reimagines this architecture by delegating replication directly to object storage services like Amazon S3, eliminating the need for cross-zone disk replication entirely. Instead of storing user data on local broker disks, diskless topics write data straight to object storage, adopting a leaderless design where any broker can handle any partition. This is as opposed to tiered storage, which still relies on local disk replication for recent data before moving older segments to object storage.
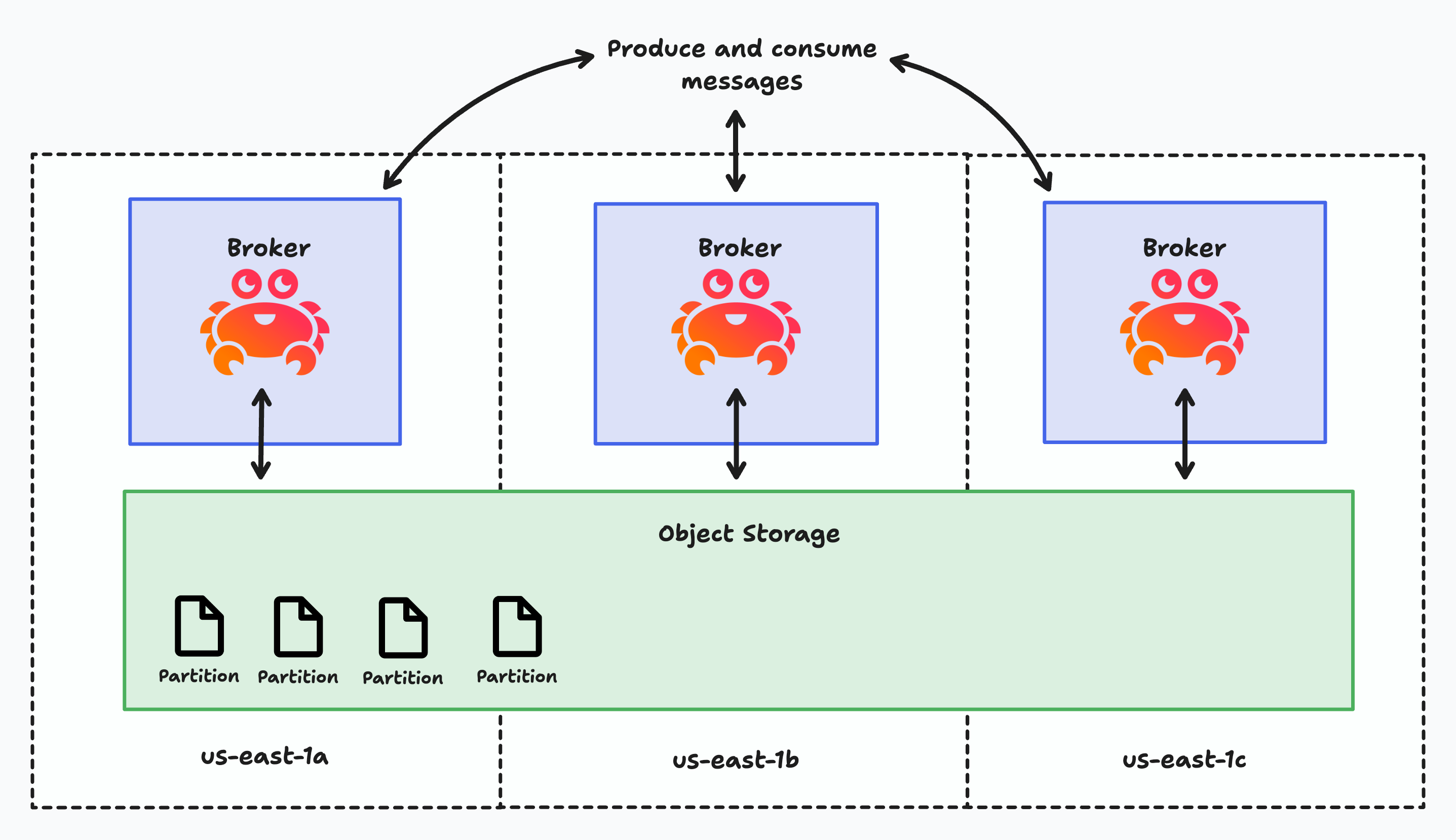
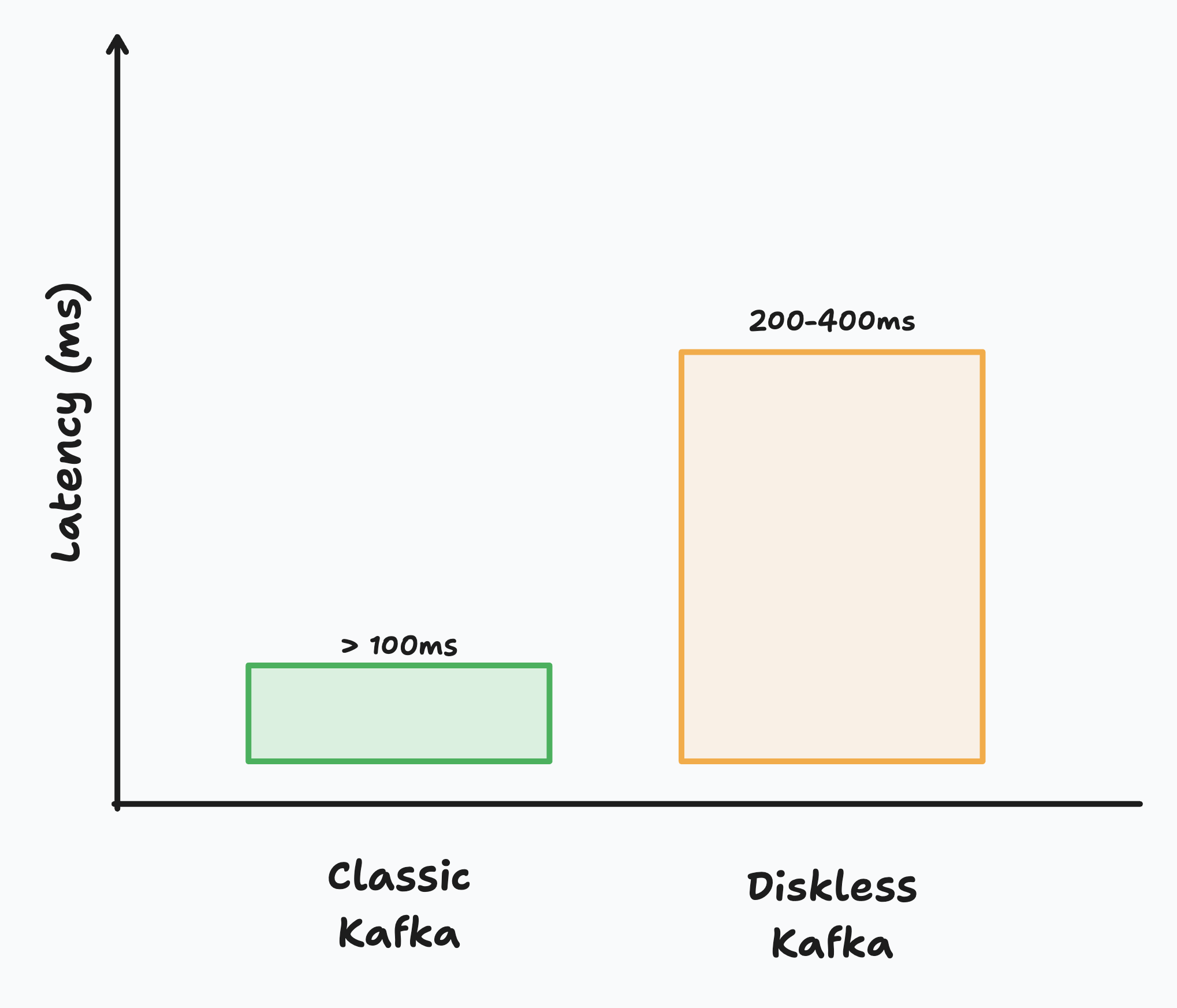
The trade-off of Diskless is that reads and writes from object storage are slower than those from local disk, to mitigate this KIP-1150 has been engineered such that you can run both traditional low-latency topics (sub-100ms) and cost-optimized diskless topics (200-400ms) in the same cluster, allowing you to choose the right performance profile for each workload. KIP-1150 maintains all existing Kafka APIs and client compatibility. Many use cases tolerate higher latency that Diskless topics enable such as logging and are thus a natural fit, but some use cases like high frequency trading or gaming are latency critical.
Another snag with "Diskless" Kafka is that the name is somewhat of a misnomer. While “Diskless” implies complete elimination of disk usage, brokers still require local disks for Kafka metadata, batch coordination, temporary operations like compaction, and optional caching. The term "Diskless" specifically refers to topic data storage for Diskless topics - user messages and logs that traditionally consume the vast majority of disk space and I/O resources. Therefore it’s more accurate to describe the changes in KIP-1150 as adding Diskless Topics within classic Kafka than creating a new “Diskless Kafka”.
TL;DR: Naming things is hard. Speaking of naming things -
What is Inkless Kafka?
Inkless is the name the team behind KIP-1150 gave to the temporary GitHub repository that contains the implementation KIP-1150, so you can use Diskless Kafka before it is merged into the Apache Kafka main branch. You can find the Inkless repo here.
Run Diskless Kafka Locally with Inkless and MinIO
When I first got hands on with Diskless I wanted to experiment with running it locally to see what made it tick. In order to run Inkless locally we also require object storage, I decided to use MinIO, a performant object store that you can deploy locally with a docker container. You can try running Diskless Kafka yourself by following the steps below:
- First, ensure you have Docker installed locally (see the Docker documentation for detailed instructions on how to do this).
- Clone my GitHub repo with the example Docker Compose and navigate into the local directory.
Loading code...
- Start the Kafka and MinIO services by running the docker compose and check the status of the newly created containers with the following:
Loading code...
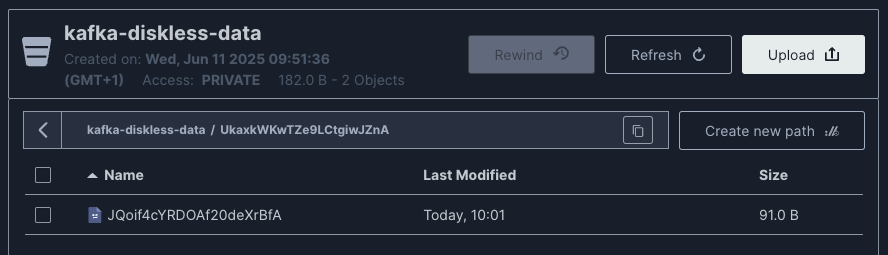
- You should see a MinIO service created and a temporary service which creates a bucket in MinIo called
kafka-diskless-datawhich our Diskless broker will use to store our Kafka data. Our Kafka configuration remains pretty much the same as a bog standard Kafka deployment apart from the inclusion of the following environment variables which specify that the broker should use S3 for the storage backend as well as the details required to access our bucket. Interestingly the S3 specification requires a region so even though the bucket is on our local machine we still need to set the region tous-east-1as we’re using the S3 spec to write to our local bucket in this example.
Loading code...
- Create a new diskless topic with the following:
Loading code...
- You can now produce and consume from your Diskless topic using the standard Kafka CLI tools. As I mentioned previously this is because whilst KIP-1150 adds new functionality under the hood the Kafka API remains unchanged so we don’t have to change any of our ways of producing and consuming from Kafka.
Loading code...
-
It's worth noting that other companies (like the first implemetnation from WarpStream) have created their own 'Diskless' streaming solutions but these are completely separate platforms that replace Kafka entirely. What makes KIP-1150 exciting is that it extends the existing Apache Kafka codebase by adding Diskless topics as a new option, rather than forcing you to migrate to a different streaming platform. This means you can gradually adopt Diskless topics for specific workloads while keeping your existing Kafka infrastructure and expertise.
-
You should now be able to see the data that are written to your MinIO bucket by visiting http://localhost:9001 (username and password are both
minioadminin this example). -
You may notice that in this example one message becomes one object in the bucket which is an inefficient way of writing to storage, at higher volumes Diskless Kafka employs batching to more efficiently write messages as objects.
You can find more Docker based demos on the Inkless repo here that demonstrate how to use the Diskless clusters and allow you to make comparisons between regular and Diskless topics.
Troubleshooting
Check the Kafka container status and logs with:
Loading code...
If you see reference to the control plane being provisioned in memory it’s likely your environment variables configuring your object storage are not being picked up - double check your variable names are correct and that your docker compose is formatted correctly.
What does Diskless mean for Kafka?
It’s exciting to see the new use cases the KIP enables and it’s clear that Diskless will benefit a variety of Kafka users. I’m already using Diskless Kafka in updated versions of my flight data demo. (which you can check out here), to backup data from my receivers to S3, saving my data from SD card failure on my Raspberry Pis.
I'm still exploring the space, and in future and I look forward to exploring both potential cost savings and the new use cases Diskless enables now. For example: could it be possible to leave data in Kafka to enable operational use cases without having to ingest data into a database first?For analytical use cases in future there are also exciting possibilities - would it someday be possible to write data directly from Kafka into an object store like S3 in a format like Apache Iceberg?
Diskless Kafka represents a fundamental shift in how we think about streaming data storage. By moving replication to object storage, it promises to slash total cost of ownership while enabling new use cases that were previously too expensive to consider. The slight latency trade-off (200-400ms vs sub-100ms) is a small price to pay for most workloads outside of high-frequency trading or gaming. If you're running Kafka in the cloud and dealing with high cross-zone replication costs, Diskless topics could reduce your streaming infrastructure costs significantly.
Ready to help shape the future of Kafka? Join the conversation on the dev@kafka.apache.org mailing list and add your voice to the KIP-1150 discussion. Every "+1" vote and thoughtful feedback helps determine whether this innovation becomes part of Apache Kafka's core. The streaming future is being written now, make sure you're part of the conversation!
Learn more about Diskless Kafka with these awesome resources:
- Diskless - The Cloud-Native Evolution of Kafka by Kaivalya Apte
- The Hitchhiker’s guide to Diskless Kafka by Filip Yonov & Josep Prat
- Diskless Kafka: 80% Leaner, 100% Open by Filip Yonov
- Read KIP-1150 itself!
Want to explore Diskless Kafka in production?
Join us for "Get Kafka-Nated Episode One" where we'll dive into Apache Kafka's evolution from LinkedIn's internal tool to modern streaming infrastructure. We'll cover major architectural shifts including KIP-500, KIP-1150 (Diskless Topics), enterprise adoption patterns, and what's driving the next phase of streaming with industry experts who've been there since the beginning.
Plus every attendee gets a free coffee voucher! Click here to register.
Brought to you by Aiven, KIP-1150 contributors.
