


Apache Cassandra® is a popular wide column data store that can quickly ingest and process massive amounts of data.
Let’s say you are considering a data storage solution for an IoT or application event load. You’ll have a few questions: How to store all of your data with its variable event length? And how to query your massive, fast-growing dataset for immediate insights and iterative, perpetual improvements?
These things require a distributed data store that can accomodate evolving and variable-length records, at massive scale and ingest velocity, employing built in fault-tolerance and availability, with high write speeds and decent read speeds. And this data must be manageable with a query language everyone already understands.
Enter Apache Cassandra.
In today’s information age, billions of connected devices and digital environments continually stream and store data. From smartphones and laptops, web browsers and applications, to smart appliances, infrastructure controls and sensors — all of these devices generate data.
Every bit of generated data is created to be collected, stored, refined, queried, analyzed and operationalized for the purpose of continuous improvement: perpetually and iteratively providing better, safer and more efficient products, processes and services.
Data generation is endless, and that data, when stored, grows exponentially. As long as users continue to use digital products, and as long as digital products remain connected to networks, they’ll continue to.
But as long as IoT networks grow asymmetrically, by adding different kinds and versions of devices, that data won’t always look the same.
Wide column stores like Apache Cassandra were developed to help organizations regain a semblance of control over these massive, exponentially-growing amounts of constantly transforming data.
In this article, we’ll look at what Apache Cassandra is, what’s special about it, and how it distributes and stores data. We’ll consider why consistency and availability (read: performance) are core tradeoffs, consider what scenarios are best (or not), and review some use-cases. Finally, we’ll look at how easy it is to set up this NoSQL database with Aiven.
What is Apache Cassandra?
Apache Cassandra is an open-source, NoSQL, wide column data store that can quickly ingest and process massive amounts of data. It’s also decentralized, distributed, scalable, highly available, fault-tolerant and tuneably consistent, with identical nodes clustered together to eliminate single points of failure and bottlenecks(we’ll go over each of those terms later). You can deploy Cassandra on-premise, in the cloud or in a hybrid data environment.

Originally designed for Facebook inbox searching, Cassandra is used today by CERN, GitHub, Apple, Netflix, and countless other organizations. It’s extremely well suited for managing large amounts of semi-variable but structured data (from sensors, connected appliances and applications) for analytics, event logging, monitoring, and eCommerce purposes, particularly when high write speeds are needed.
So what's so special about it?
In order to understand the unique value add that Apache Cassandra provides, it’s useful to look at those terms we’ve used to describe it.
-
Decentralized means there’s no master-slave paradigm, and each separate node is capable of presenting itself to any end-user or client as a complete or partial replica of the database.
-
Distributed means that Cassandra adds the most value when it is distributed across many nodes and even data centers.
-
Scalable means that Cassandra can be easily scaled horizontally, by adding more nodes (machines) to the cluster, without disrupting your read and write workflow.
This is one of the best features of Cassandra: each node communicates with a constant amount of other nodes, allowing you to scale linearly over a huge number of nodes.
-
Highly Available means that your data store is fault-tolerant and your data remains available, even if one or several nodes and data centers go down.
-
Tunably Consistent means that it is possible to adjust the tradeoff between availability and consistency of data on Cassandra nodes, typically by configuring
replication factorandconsistency levelsettings.
In practice, this really means a tradeoff between consistency and performance. For example, if you were to set
consistency levelto3on a 3-node cluster, it would require at least all three nodes to be in agreement. For this cluster, this would be the slowest throughput in favor of maximum consistency.
How Apache Cassandra distributes data
Casandra uses a peer-to-peer distribution model, which enables it to fully distribute data in the form of variable-length rows, stored by partition keys. This happens across different cloud availability zones and multiple data centers. Cassandra is built for scalability, continuous availability, and has no single point of failure.
Many databases, such as Postgres, use a master-slave replication model, in which the writes go to a master node and reads are executed on slaves. Unfortunately, the master-slave hierarchy often creates bottlenecks. To provide high availability, fault tolerance and scalability, Cassandra’s peer-to-peer cluster architecture provides nodes with open channels of communication.
Cassandra uses tokens to determine which node holds what data. A token is a 64-bit integer, and Cassandra assigns ranges of these tokens to nodes so that each possible token is owned by a node. Adding more nodes to the cluster, or removing old ones leads to redistributing these token ranges among nodes.
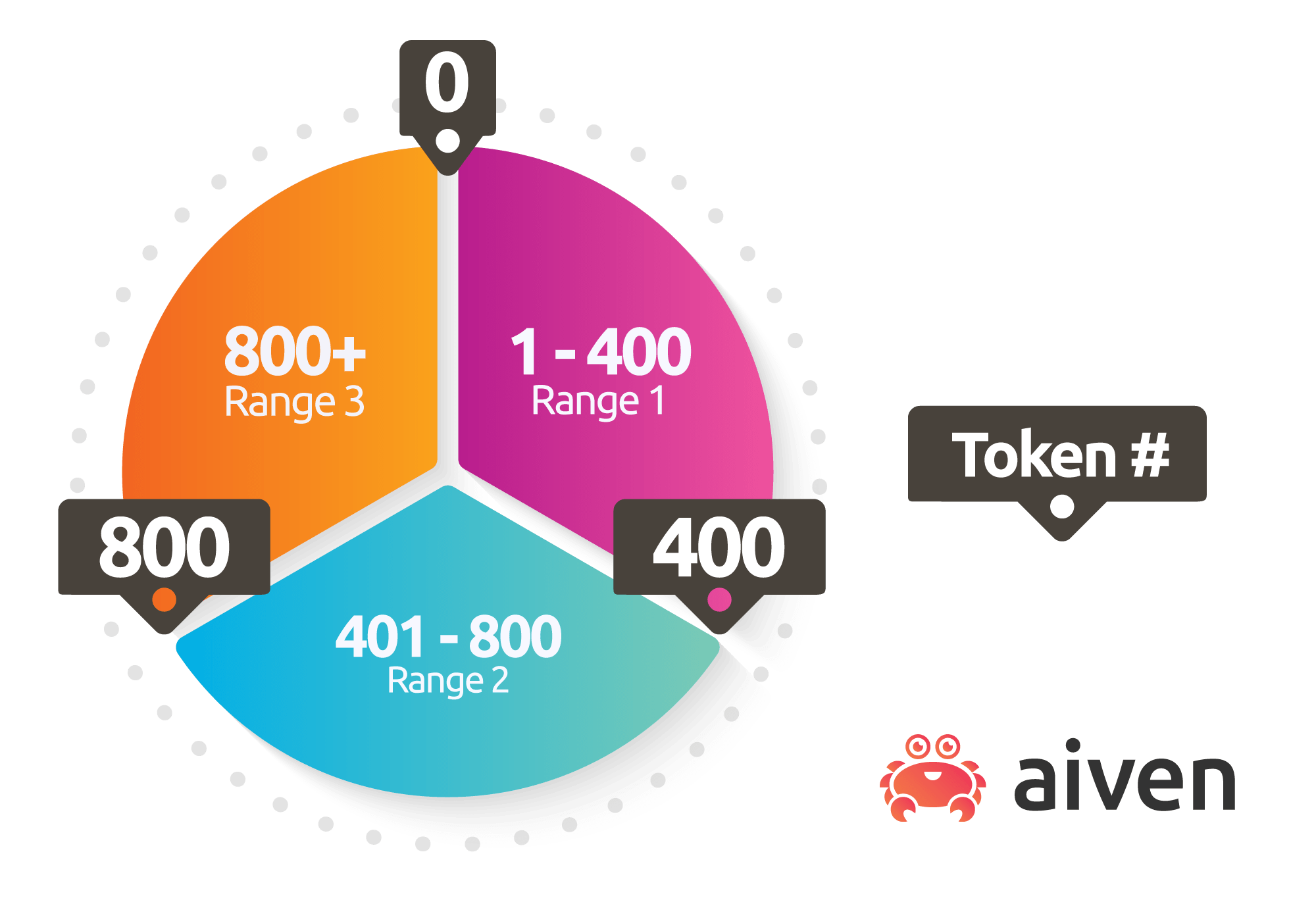
In practice, however, tokens are not assigned from the values 1-1200, but are rather assigned from the range between the minimum and maximum signed 64-bit integers.
A row's partition key is used to calculate a token using a given partitioner (a hash function for computing the token of a partition key) to determine which node owns that row. That's how Cassandra finds where the replicas are which hold that data.
The wide-column store, and how data is modelled
Cassandra exposes a dialect similar to SQL called CQL for its Data definition language (DDL) and data manipulation language (DML). While similar to SQL, there is a notable omission: Apache Cassandra does not support join operations or subqueries.
Apache Cassandra lets you ingest variable-length events into rows. It all starts with how the data is modeled in CQL:
Loading code...
Up front, the schema is actually predefined and static. The schema for Cassandra tables needs to be designed with query patterns in mind ahead of time, so structural changes to data in real-time are not necessarily trivial with Cassandra (we’ll look at ways to do this later).
Previously tables in Cassandra were referred to as column families.
Here's what that populated table could look like:
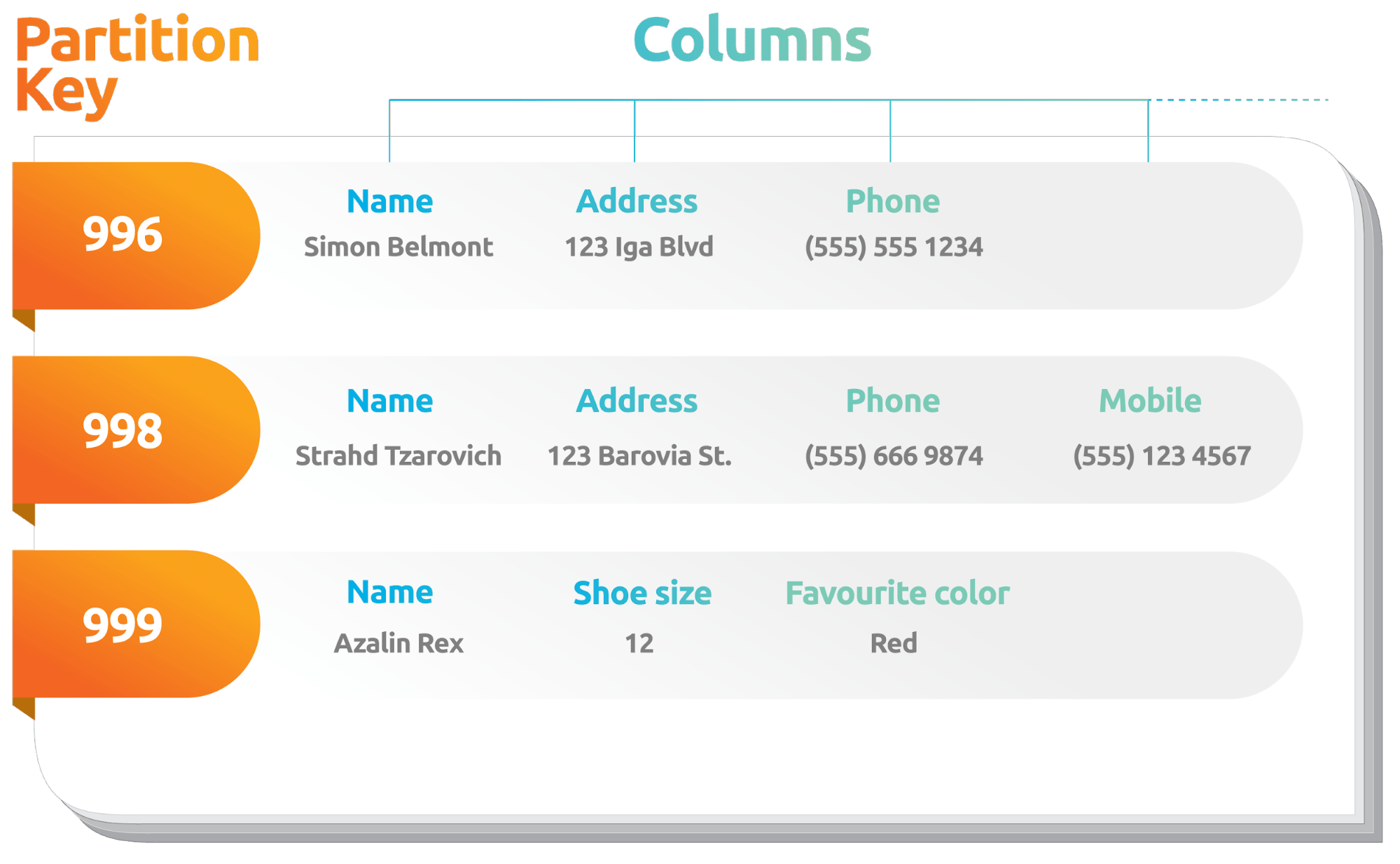
NOTE: in a wide-column store, each row in a table appears to contain all columns. But only some need to be populated. The rest can be filled with NULL values during an insert operation, as we’ll see later.
The variable width of rows concept is what some argue enables flexibility in terms of the events it can store: one event (row) can have columns name (string), address (string), and phone (string), with the next event having name (string), shoe_size (int), and favorite_color (string). Both events can be stored as rows in the same table.
How is this possible? Because in a wide-column store like Cassandra, different rows in the same table may appear to contain different populated columns.
Actually, Cassandra doesn’t really have a full row in storage that would match the schema. Instead, Cassandra stores mutations; the rows an end user sees are a result of merging all the different mutations associated with a specific partition key. Merging is the process of combining mutations to produce an end result row.
Rows are accessed by partition key and stored within a table; as shown above, rows are searched and accessed by the partition key. The partition key is a hash that tells you on which replica and shard the row is to be located.
Now that we know how data is modelled, populated and distributed in Apache Cassandra, let’s look at another problem: how data is added, read and deleted from Cassandra.
How data is added to Cassandra
During an update operation, values are specified and overwritten for specific columns; the values of the remaining columns in the row should be what was there, if anything, before the update.
As events are ingested, they can not freely add unstructured data or random data types as new columns to new rows on the fly. Rather, they require one of two things:
-
Columns already exist in the schema -- unused columns in new rows are populated with
NULLvalues during aninsertoperation; -
Applications can dynamically run
alter tablecommands to add new columns to the schema.
How data is read from Cassandra
When a client selects a row with a select statement, all the mutations of the row are gathered and applied in order of their timestamps. If an insert happens first, and is followed by an update, then the resulting row is the insert mutation columns with the update overwriting the values for columns it contains. On the other hand, if an update is followed by an insert, then the insert overwrites all the columns from the updated row.
How data is deleted from Cassandra
A delete in Cassandra creates a mutation called a tombstone, which marks the partition key as deleted, and suppresses associated data in SSTables (discussed below). The process of compaction, which happens periodically, is what permanently removes this suppressed data and effectively defragments the remaining lot, improving read performance.
How data is organized for scale and asymmetry
As mentioned earlier, Cassandra uses a table to organize data. Cassandra uses them to define what types of data can be partitioned together and organizes that data into rows. When machines are added or removed from a cluster, Cassandra will automatically repartition according to the configuration (partition keys) of the table.
How data is replicated for fault tolerance
Cassandra automatically replicates data to multiple nodes and across multiple data centers to create high fault tolerance and ensure zero data loss. To enable fast performance, Cassandra stores writes into a memory-volatile table structure called a memtable.
How data is cached for speed and stored for persistence
Once a memtable is full, Cassandra flushes the writes into a static storage called an SSTable. SSTables are immutable and cannot be written to again after the associated memtable is flushed. To keep flushing to a minimum — and writes at high speed — Cassandra also appends memtable writes to a Commit Log.
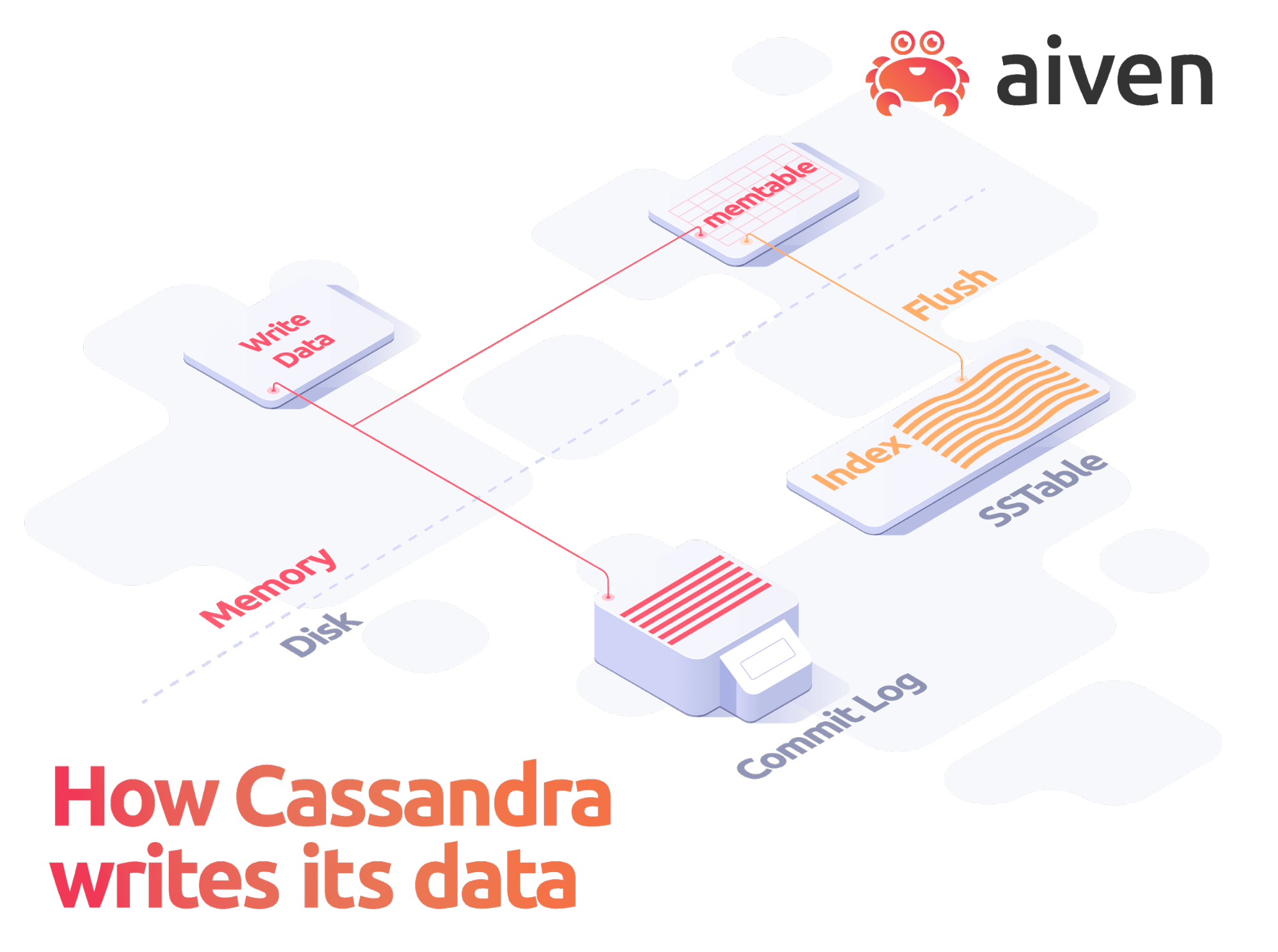
How it all ties together
It's these mechanisms combined that allow Cassandra to have excellent write performance. Even when the consistency level is low, two nodes can hold different versions of the same row separately, and resolve the conflict during a read operation by simply picking the version on the node with the newer timestamp.
Cassandra is scalable and elastic, allowing the addition of new machines to increase throughput without downtime. When a master node shuts down in databases that operate on the master-slave architecture, the database can’t process new writes until a new master is appointed. In such cases, Cassandra, which doesn’t rely on a master-slave architecture, can simply redirect writes to any available node, without shutting down the system.
Can Apache Cassandra provide consistency?
According to Dr. E. A. Brewer, distributed data stores can fulfill only two of the three CAP Theorem functions simultaneously. When pressed to choose between consistency, availability and partition tolerance, data professionals were left with no choice but to prioritize partition over consistency — you simply can’t have distributed databases without partitioning.
While many data stores enforce their own setup of the CAP Theorem, Cassandra lets you choose your own preferred functions. However, as time moves on, the understanding of this tradeoff continues to evolve.
Cassandra’s Tunable Consistency allows you to decide what is more important to you, on a per-query level, by instructing Cassandra on how to handle any write and read request.
The consistency level you configure will define when clients are acknowledged, while the default configuration of the replication factor will ensure that writes are always sent to all replicas.
For example, you can configure how Cassandra handles read requests according to your preferred level of consistency:
- High stale data potential (low consistency level) — you can risk the return of stale data by configuring Cassandra to wait for any available node. This could potentially return an out-of-date replica, but conflicts are resolved by picking the replica with the latest timestamp. This allows for the fastest query completion. <br/>
- Medium stale data potential (medium consistency level) — to reduce the probability of getting stale data while compromising on query speed, you can instruct Cassandra to reach a quorum of nodes. <br/>
- Strong data consistency (high consistency level) — if you ask Cassandra to wait for every node, you will get strong consistency, in which Cassandra always returns the latest data.
But you will experience other performance impacts as a result: full consistency takes longer and you will compromise performance: it will take longer to query results containing new data until every node’s data is updated.
Some considerations of Apache Cassandra
As in any piece of software, Cassandra has its shortcomings. One notable disadvantage is its slow process for reads.
Scylla, which is based on Cassandra but coded natively (Cassandra runs in a JVM) has attempted to resolve these issues.
In Cassandra, schema and data types must be defined at design time, complicating the planning process and limiting your ability to modify schema or add additional data types later on. This, as explained earlier, can have an impact on your ability to manage fast-streaming, dynamic data.
Cassandra has no built-in aggregation functionality, and data grouping must be pre-computed manually. If you’re running a very small dataset, consider another solution. The same goes if you were to only require a single-node solution; the only real benefits of Cassandra are when data is distributed across multiple nodes.
Cassandra uses a low-level data model, which requires extensive knowledge of the dataset, making it a less optimal choice if you need application transparency. Cassandra adds further complexities by using CQL, a proprietary language, which provides no join or subquery support. Ordering is done per partition at table creation time to enforce efficient application design, and you can only run queries for keys and indexes.
In Cassandra, the amount of data that can be stored per partition is limited to the size of the smallest machine in the cluster. Column values are limited in size to 2GB but lack of streaming or random access of blob values limits this more practically to under 10 MBs.
Collection values are limited to 64KB and the maximum number of cells in a single partition is 2 billion. Appending new rows to a table is just what Cassandra is intended for. Nonetheless, If you were to need to overwrite existing rows with new rows on a regular basis, Cassandra is not the right solution for you.
Use cases for Apache Cassandra
Imagine the following scenario: You’re an assembly line foreman with an evolving IoT environment. As your operations grow, you need to expand the monitoring and control of your production line. To start iterative improvements, you add temperature sensors to the assembly line to log temperature events as time series data.
Next, you add time stamped pressure sensor readings. Eventually, outputs from proximity sensors to monitor component placement are added and calibrated. Finally, level sensors — to monitor device fluid capacity — are added to the mix.
All events must be time-synced and correlated. But as your process is tuned, and each sensor calibrated, they are gradually replaced with different variants of sensors. This process introduces quite a bit of variability in your collected data schema, types and the data itself.
Once your assembly line is optimized, you’re running in the millions. All that time, your sensor stats and output data were continually tweaked and refined with values added and removed. All while you collected, analyzed and operationalized your massively growing, fast-moving dataset.
As it turns out, Cassandra is a popular solution for those looking for high performance on large datasets, including use cases such as storing multivariate time-series data such as logs and IoT sensor data.
The fast write capabilities of Cassandra would, for example, also make it ideal for tracking huge amounts of data from health trackers, purchases, watched movies and test scores. And there are still many using it for tracking web activity, cookies and web application data.
If you’re interested in big data analysis for messaging applications, you can use Cassandra while ensuring continuity — there will be zero downtime. Cassandra’s scalability and partitioning techniques can even turn it into a secure, stable, and cost-effective environment for fraud detection.
Setting it up
Aiven Cassandra is a fully managed and hosted Apache Cassandra service which provides high-availability, scalability, and state-of-the-art fault tolerance. It's easy to set up, either straight from the Aiven Console:
Directly from the command line or using our REST API.
Wrapping up
Cassandra is an excellent choice if you need a massively scalable NoSQL database to handle big data workloads streaming variable-length events, provided all columns were specified when the table was created (or use of the alter-table command).
It provides robust capabilities that can help you set up a fast, efficient and automatic system for processing logging, tracking, and usage data. You can configure Cassandra according to the needs of your organization, and according to the specs of any given project.
In this article, we’ve looked at Apache Cassandra: what it is, what’s special about it, and how it distributes and stores data. We’ve also considered consistency and availability as core tradeoffs, looked at shortcomings and use-cases, and how to set it up as an Aiven service.
If you'd like to see Aiven Cassandra in action, check it out with our no commitment, 30-day trial, or find out more on its product page!
References
Cassandra, The Definitive Guide
Thanks also to Gilad Maayan and Ilai Bavati for their contributions to this article, and Mathias Fröjdman for his explanations.
Further reading

Table of contents
- What is Apache Cassandra?
- So what's so special about it?
- How Apache Cassandra distributes data
- The wide-column store, and how data is modelled
- How data is added to Cassandra
- How data is read from Cassandra
- How data is deleted from Cassandra
- How data is organized for scale and asymmetry
- How data is replicated for fault tolerance
- How data is cached for speed and stored for persistence
- How it all ties together
- Can Apache Cassandra provide consistency?
- Some considerations of Apache Cassandra
- Use cases for Apache Cassandra
- Setting it up
- Wrapping up
- References
- Further reading