


We're happy to announce that Aiven for PostgreSQL now has support for connection pools. Connection pooling allow you to maintain very large numbers of connections to a database while keeping the server resource usage low.
Aiven for PostgreSQL connection pooling utilizes PGBouncer for managing the database connection and each pool can handle up to 5000 database client connections. Unlike when connecting directly to the PostgreSQL server, each client connection does not require a separate backend process on the server. PGBouncer automatically interleaves the client queries and only uses a limited number of actual backend connections, leading to lower resource usage on the server and better total performance.
Why connection pooling?
Eventually a high number of backend connections becomes a problem with PostgreSQL as the resource cost per connection is quite high due to the way PostgreSQL manages client connections. PostgreSQL creates a separate backend process for each connection and the unnecessary memory usage caused by the processes will start hurting the total throughput of the system at some point. Also, if each connection is very active, the performance can be affected by the high number of parallel executing tasks.
It makes sense to have enough connections so that each CPU core on the server has something to do (each connection can only utilize a single CPU core [1]), but a hundred connections per CPU core may be too much. All this is workload specific, but often a good number of connections to have is in the ballpark of 3-5 times the CPU core count.
[1] PostgreSQL 9.6 introduced limited parallelization support for running queries in parallel on multiple CPU cores.
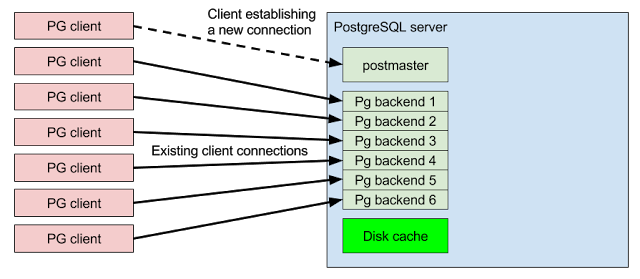
Without a connection pooler the database connections are handled directly by PostgreSQL backend processes, one process per connection:
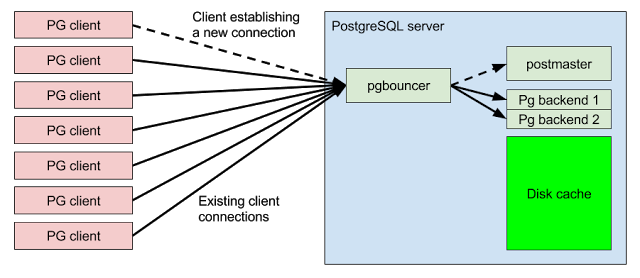
Adding a PGBouncer pooler that utilizes fewer backend connections frees up server resources for more important uses, such as disk caching:
Many frameworks and libraries (ORMs, Django, Rails, etc.) support client-side pooling, which solves much the same problem. However, when there are many distributed applications or devices accessing the same database, a client-side solution is not enough.
Connection pooling modes
Aiven PostgreSQL supports three different operational pool modes: "session", "transaction" and "statement".
-
The "session" pooling mode means that once a client connection is granted access to a PostgreSQL server-side connection, it can hold it until the client disconnects from the pooler. After this the server connection will be returned back into the connection pooler's free connection list to wait for its next client connection. Client connections will be accepted (at TCP level), but their queries will only proceed once another client disconnects and frees up its backend connection back into the pool. This mode can be helpful in some cases for providing a wait queue for incoming connections while keeping the server memory usage low, but has limited usefulness under most common scenarios due to the slow recycling of the backend connections.
-
The "transaction" pooling mode on the other hand allows each client connection to take their turn in using a backend connection for the duration of a single transaction. After the transaction is committed, the backend connection is returned back into the pool and the next waiting client connection gets to reuse the same connection immediately. In practise this provides quick response times for queries as long as the typical transaction execution times are not excessively long. This is the most commonly used PGBouncer mode and also the Aiven PostgreSQL default pooling mode.
-
The third operational pooling mode is "statement" and it is similar to the "transaction" pool mode, except that instead of allowing a full transaction to be run, it cycles the server side connections after each and every database statement (SELECT, INSERT, UPDATE, DELETE statements, etc.) Transactions containing multiple SQL statements are not allowed in this mode. This mode is sometimes used for example when running specialized sharding front-end proxies.
How to get started with Aiven PostgreSQL connection pooling
First you need an Aiven PostgreSQL service, for the purposes of this tutorial we assume you already have created one. A quick
Getting Started guide
is available that walks you through the service creation part.
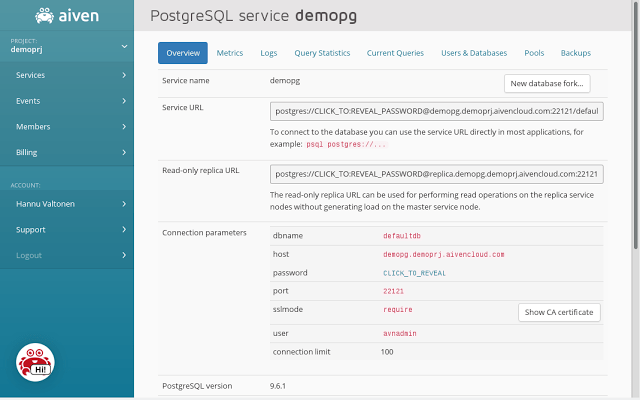
This the overview page for our PostgreSQL service in the Aiven web console. You can connect directly to the PostgreSQL server using the settings described next to "Connection parameters" and "Service URL", but note that these connections will not utilize PGBouncer pooling.
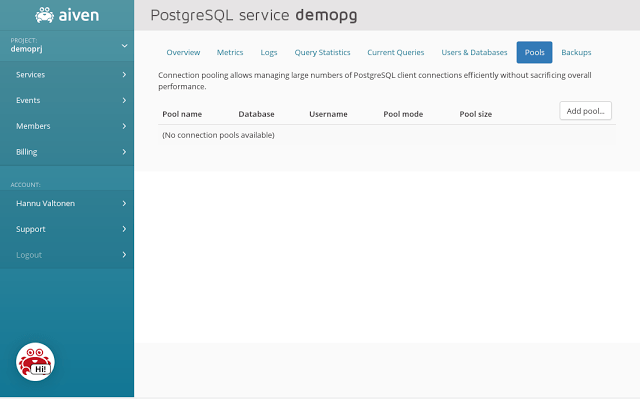
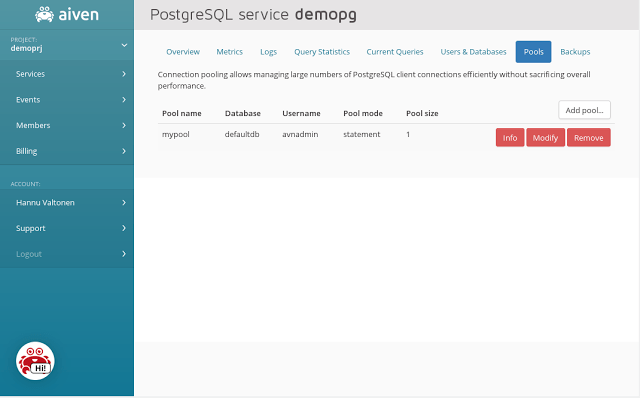
Clicking the "Pools" tab opens a list of PGBouncer connection pools defined for the service. Since this service was launched, there are no pools defined yet:
To add a new pool click on the "Add pool" button:
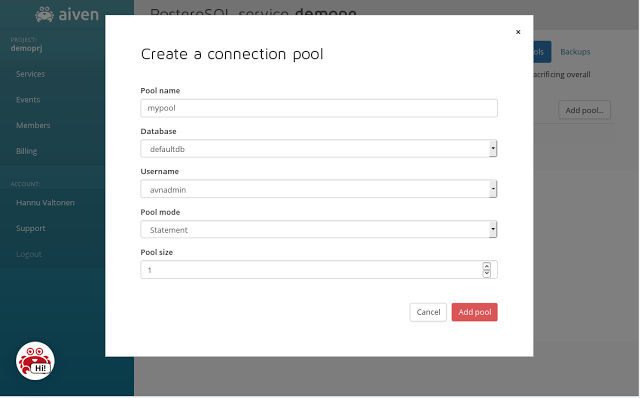
The pool settings are:
- Pool name: Allows you to name your connection pool. This will also become the "database" or "dbname" connection parameter for your pooled client connections.
- Database: Allows you to choose which database to connect to. Each pool can only connect to a single database.
- Username: Selects which database username to use when connecting to the backend database.
- Pool mode: Refers to the pooling mode descried in more detail earlier in this article.
- Pool size: How many PostgreSQL server connections can this pool use at a time.
For the purposes of this tutorial we'll name the pool as "mypool" and set the pool size as 1 and the pool mode as "statement". Confirming the settings by clicking "Add pool" will immediately create the pool and the pool list is updated:
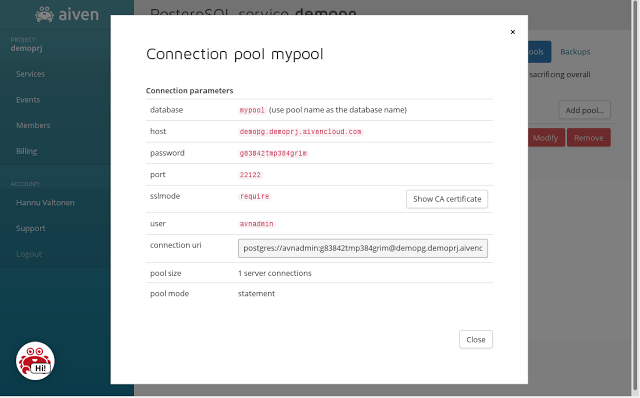
Clicking the "Info" button next to the pool information shows you the database connection settings for this pool. Note that PGBouncer pools are available under a different port number from the regular unpooled PostgreSQL server port. Both pooled and unpooled connections can be used at the same time.
Verifying the connection pool
We can use the psql command-line client to verify that the pooling works as supposed:
From terminal #1:
Loading code...
From terminal #2:
Loading code...
Now we have two open client connections to the PGBouncer pooler. Let's verify that each connection is able access the database:
Terminal #1:
Loading code...
Terminal #2:
Loading code...
Both connections respond as they should. Now let's check how many connections there are to the PostgreSQL backend database:
Terminal #1:
Loading code...
And as we can see from the pg_stat_activity output the two psql sessions use the same PostgreSQL server database connection.
Summary
The more client connections you have to your database, the more useful connection pooling becomes. Aiven PostgreSQL makes using connection pooling an easy task and migrating from non-pooled connections to pooled connections is just a matter of gradually changing your client-side connection database name and port number!
Try PostgreSQL 9.6 for free in Aiven
Remember that trying Aiven is free: you will receive US$10 worth of free credits at sign-up which you can use to try any of our service plans. The offer works for all of our services: PostgreSQL, Redis, Grafana, OpenSearch and Kafka!
Go to aiven.io to get started!
