Jul 8, 2019
The data continuum, examined
To know which data store is best for your data, it's helpful to understand where your data lies on the continuum of structured to unstructured data.

John Hammink
|RSS FeedDeveloper Advocate at Aiven
Imagine all of the possible formats into which you could collect data. And then, imagine what you could do with it. Think of a continuum – on one end is completely structured data, on the other, completely unstructured data.
Coupled with this comes the flexibility of searching that data, but this is where things get interesting. You’d think that the more structured your data is, the more flexible the means of searching it – but then you’d be wrong.
To understand all of this better, let’s examine the data continuum: from fully-structured to unstructured. From there, we’ll look at the data stores that handle each kind of data. And we’ll consider questions to ask when choosing a data store: even when you may need more than one in your pipeline. But first, let’s start on the structured end of the spectrum.
Relational database management systems
On one end of the continuum, you have rigorously-structured data: think of RDBMSes like PostgreSQL or MySQL. On this end, you’ll find transactional data, where data format is held to the strictest requirements, and records cannot afford to be lost under any circumstances.
If an incoming event doesn’t strictly meet the criteria, the event will not be stored but rejected, and the database or client will throw an error (a type incompatibility is when data in a specific field doesn’t match the predefined format for that field). So, for example, if a field in a PostgreSQL schema specifies an integer and an incoming event has a float in that space, the incoming event will be rejected.
RDBMSes require ACID transactions, meaning that all transactions within the database are atomic, consistent, isolated, and durable. This explains the rigidity of the SQL query language: transactions cannot break or introduce inconsistencies into other database records, even if it is distributed.
Also, once specific columns are defined for a table, when inserting data using insert into, in all rows, these fixed columns will be automatically populated to contain at least a NULL value.
NOTE: These days, Postgres and MySQL support JSON quite well, making them competitive in some ways with other data stores for semi-structured data.

Wide-column stores
Moving to the right on the continuum, the rules of engagement relax slightly. A wide-column store like Apache Cassandra or ScyllaDB allows rows (as minimal units of replication, analogous to rows as records in Postgres) to store a great, but most importantly variable number of columns.
These are great for the sort of data later to be used in aggregations and statistical analysis where events come in large, occasionally inconsistent batches: a fairly fixed schema but of variable width.
The variable width of rows concept is what some might argue, allows flexibility in terms of the events it can store: one event (row) can have fields name(string), address(string), and phone(string), with the next event having name(string), shoe_size(int), and favorite_color(string). Both events can be stored as rows in the same column family (analogous to a table in PostgreSQL or MySQL).
How is this possible? Because a wide-column store like Cassandra can accommodate new columns. In other words, different rows in the same column family can contain different columns.
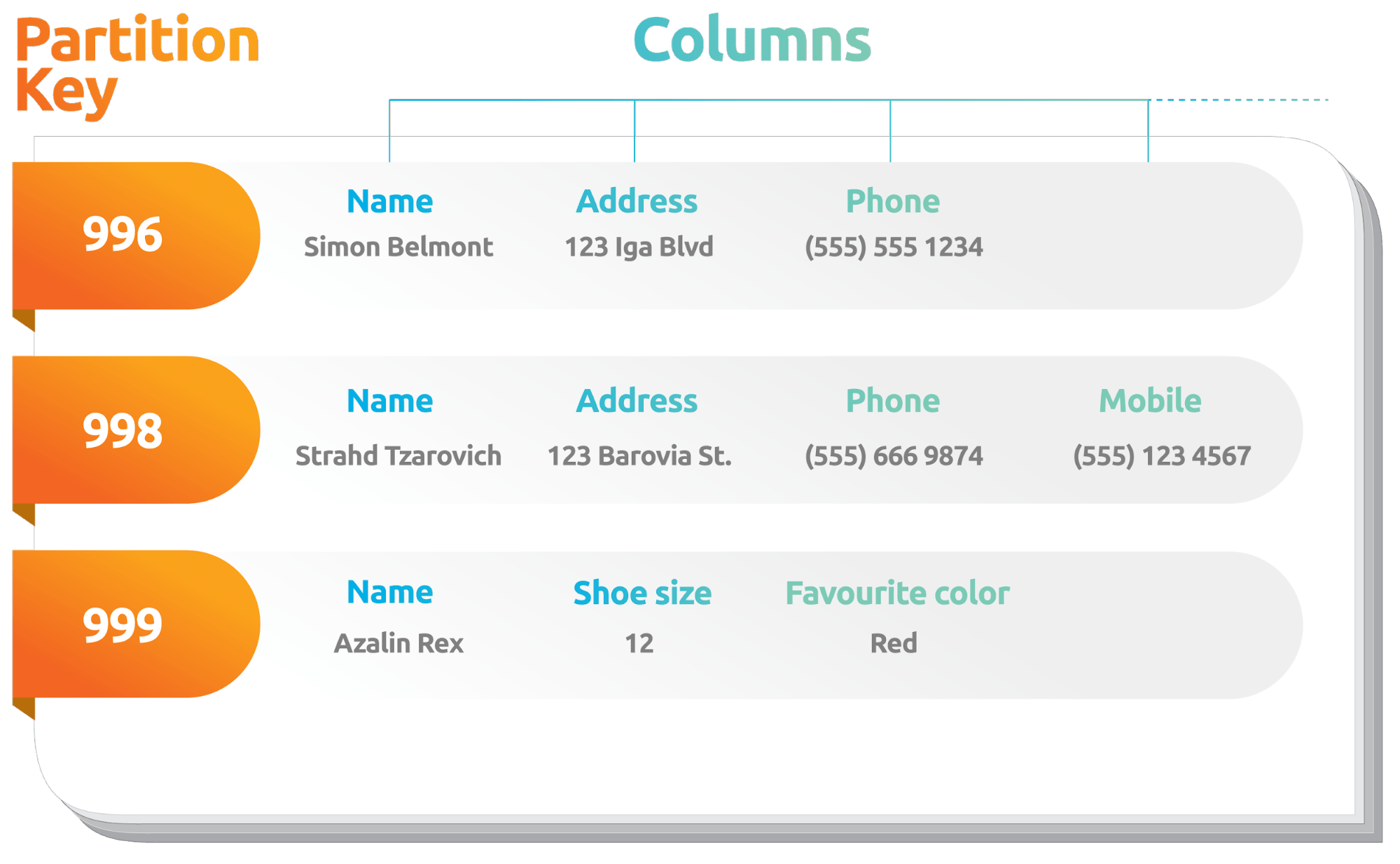
There is still one inflexible notion here: the column family schema, including all columns, should ideally be defined prior to ingestion. During data ingestion, Cassandra cannot create new fields on the fly during a streaming ingest.
However, you could create a column family using a compound key or use, as a separate step, an alter table command during an ingest on an existing column family to add new columns. When this is done dynamically from a running application, this gives the appearance of flexibility in a Cassandra column family, when actually, the application is doing the work!
Cassandra exposes a SQL dialect called CQL for its DDL (data definition language) and DML (data manipulation language). While similar to SQL, there is one notable omission: Apache Cassandra does not support join operations.
Finally, as Cassandra is a distributed database, you can configure things like replication factor and consistency level to determine where the data gets replicated and how often. Almost every distributed database honors the CAP theorem nowadays: the oft-repeated notion that a distributed data store must honor the tradeoff between data consistency, availability, and partition tolerance. As time moves on, the understanding of this tradeoff continues to evolve. Regardless, these settings are typically hidden from end users in managed solutions and default settings serve most use cases.
Key-value stores
Next up, we have key-value stores like Redis, which runs in-memory. These store a key that works like a fast-searchable index and associated values which can contain, for example strings, lists, hashes, sets, sorted sets or even bitmaps.
These are useful where you’re essentially storing flat hierarchies that require the fastest, lowest-possible latency lookup of very specific bits of data. They’re flexible in that many things can go into the value part (although not the key), but inflexible in that the key to value ratio is 1:1.
Document stores/full-text search engines
Document stores like MongoDB and Elasticsearch offer the greatest level of flexibility – and complexity. A document store roughly resembles a key-value store where the key becomes the document ID and the value is the document containing the actual stored data.
The document can be almost anything, including an array of values; thus, Elasticsearch might be a good choice when the stored data is hierarchical within a single document and should not be flattened. Elasticsearch indexes data into indices, which hold types, which contain documents which hold fields.
In addition to accommodating the most unstructured data of the bunch, Elasticsearch also offers the most flexibility in querying the data. Not limited to SQL's ACID constraints, the supported Query DSL is profoundly extensive, flexible and works down to the keyword/token level.
Elasticsearch query types include (but are not limited to) full-text queries; term-level queries; relevance-ranking queries; term-completion queries (where word-completion suggestions appear after a user starts typing); joining queries (less expensive than SQL-style joins); regular expression and partial-regular expression queries; geo queries (essentially geolocation data queries); specialized queries (a rather motley crew of “none of the above” query types); and even span queries, which control for word order and position and are well suited to legal, contractual, and patent documents (but can be used on any text, anywhere).
To add to the pile and drive home the flexibility of Elasticsearch, compound-queries are possible. These wrap other query types (including mashups of more than one of the above queries) to calculate items such as scores, matches, relevance ranking of results, and boolean truth values.
_NOTE: Time-Series data can be stored and tracked in any RDBMS, wide-column store or even full-text search data store, like Elasticsearch.
Breaking SQL and NoSQL databases down further
PostgreSQL and MySQL are both examples of SQL/RDBMS databases. Elasticsearch, MongoDB, Redis, Cassandra/ScyllaDB, are all examples of NoSQL data stores. The comparison between NoSQL to relational databases looks as follows:
| SQL/RDBMS | NoSQL |
|---|---|
| Relational | Non-relational |
| Fixed schema, table based | Many types are not table-based; if they are, schemas are not usually fixed. |
| Vertically-scalable (expandible primarily by adding more memory and processing power to the same server). | Horizontally-scalable (expandible primarily by adding more nodes/computers to the network). |
| Generally not distributed. Transactions adhere strictly to ACID (Atomic, Consistent, Isolated, Durable) properties. | If distributed, follows the CAP theorem. |
It’s probably worth clarifying though, that as each of these solutions evolve, they are starting to assume more of the features of each other. For example, both Cassandra and Elasticsearch can be vertically scaled within the same server and PostgreSQL can be distributed (but not sharded) — although each were originally not built that way.
NoSQL database types: feature comparison
To even better understand the distinction, we can also consider the differences within the NoSQL database category:
| Type | Examples | Features |
|---|---|---|
| Key-value pair | Redis | Fast, in-memory database platform offering native support for a wide range of data structures. Often used also as part of a cache or message broker system. |
| Text search / Document Store | OpenSearch | Full text search and analytics engine; works in near real time, including indexing. |
| Time-series | InfluxDB, Timescale | Simple DBMS for storing time series, events, and metrics. |
| Distributed wide-column store | Cassandra | Distributed, wide-column store best suited to multi-cloud or multi-data center environment. |
Which is best to use, and when?
If you could answer the question, "Why NoSQL?" in only only a few words, they would probably boil down to scale (including flexibility of scale), flexibility (including of schema and type constraints), or latency and performance (including throughput).
Secondary considerations may include the size of the community (as well as the support and documentation you're likely to find) or the level of industry adoption as a measure of popularity, and thus reliability and fitness for purpose of a given solution.
Of course, there's more to it. While NoSQL offerings are built around these concepts, RDBMS databases remain the preferred choice in industries and applications involving transactional data, where ACID properties are essential: user authentication and access-rights management, healthcare, banking, resource allocation and inventory management, and shopping carts to name but a few.
RDBMS databases come with the long-established promises of isolation, security, and referential integrity; and, there's no seeing those requirements go away any time soon.
However, in applications involving high-volume, fast-moving analytics data from sensors, applications, or complementary systems, a NoSQL solution with different features or attributes might be a better fit.
What kind of needs do you have? A fast-lookup with caching features, like a key-value store? A more flexible document-store for searching through larger records, or even text search for unstructured data? Maybe a distributed wide-column store with tunable consistency, or a store specialized for time-series data?
NoSQL is an evolution from RDBMS databases to better serve specific needs. The "best" in any case is what suits your needs; remember to assess your existing infrastructure and team to find areas where gaps can become strengths.
But it's not as simple as that
Note that most data pipelines and data architectures will use a combination of data stores for different purposes. In a lambda architecture, for example, a datastore like Cassandra might be used to capture and store large volumes of historical data where slower read access is allowed, while Elasticsearch may be deployed in parallel to capture recent, less structured data that requires a fast, low-latency, but very flexible search.
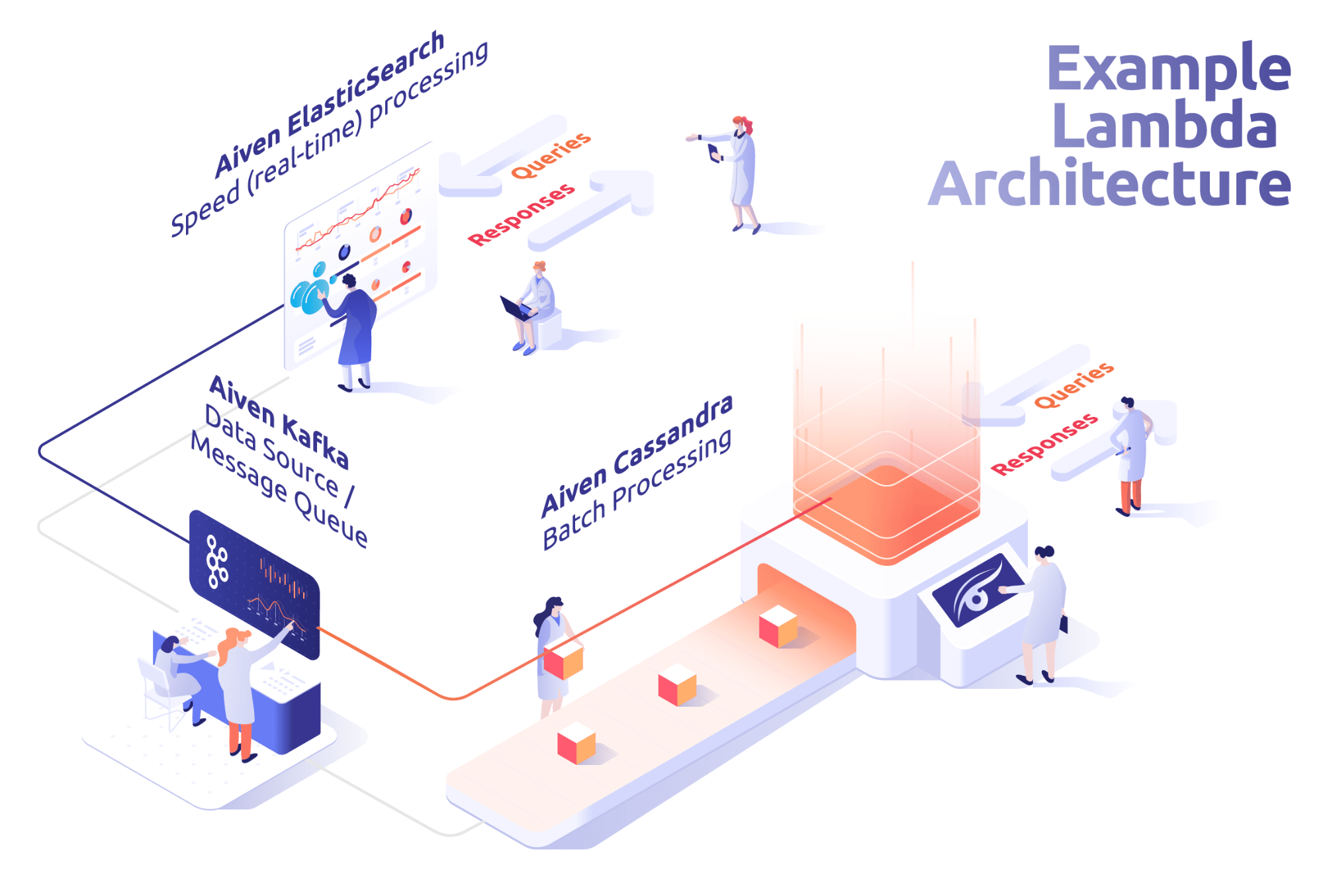
Based on: Wikipedia, Lambda Architecture
Yet another architecture might include a time-series database to the above to track timestamps for events. And, other systems may contain a transactional component where a NoSQL store is used for analytics of fast data retrieval and an RDBMS is used for transactional data.
Wrapping up
Today, there are more data sources than ever: website tracking, cloud-stored flat files, CRM, other databases, eCommerce, marketing automation, ERP, IoT, other large datasets via REST APIs, and mobile apps, etc. The ability to mash up and transform data ultimately means getting competitive insights from all of your data.
We’ve looked at the data continuum: data stores as they handle the spectrum of data from fully-structured to unstructured: from RDBMSes to wide-column stores to key-value stores to full-text search.
We’ve then simplified the comparison, looked at database choice criteria, and considered the lambda architecture: when data pipelines have multiple stores for multiple purposes.
So where on the spectrum does your data lie? And how will you put your data pipeline together? Aiven provides fully-hosted and managed cloud databases and messaging services on all major cloud providers across the globe. Get started today.
References
John Hammink, for Alooma: NoSQL vs. SQL: Differences Explained
Further reading
Table of contents
Stay updated with Aiven
Subscribe for the latest news and insights on open source, Aiven offerings, and more.


