


TL;DR
In the cloud, Kafka’s promise of “never lose a byte” quietly morphs into “always pay for two.” Every time the leader syncs followers across zones, you get hit with premium egress charges that can dwarf compute costs. Diskless Kafka turns that upside-down: brokers replicate data straight into S3, so the pricey cross-zone hops vanish. Yes, object storage is slower than a local SSD, but the swap buys you on-demand elasticity and a bill that finally makes sense.
What we’ll learn:
- Diskless’ cost equation—why the switch slashes both inter-AZ egress and per-request API fees..
- The Diskless Tuning playbook— showing exactly how to set buffer size and commit interval so you hit your latency SLO without leaving money on the table.
Deconstructing the Replication Tax
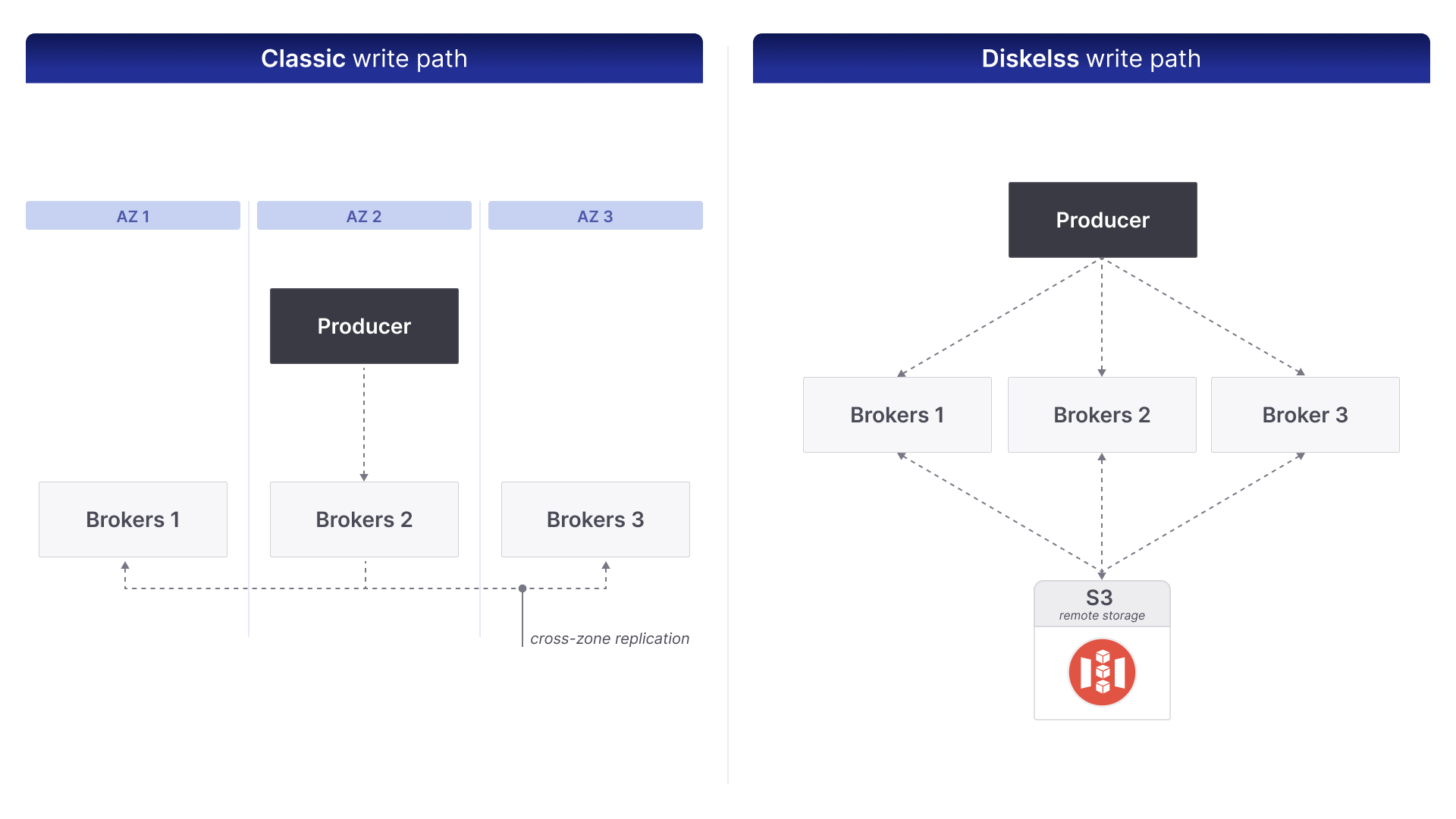
The first thing you need to know is that network costs associated with a standard Kafka deployment are a direct byproduct of its replication protocol, which is essential for achieving its data durability promise. In a three-zone cluster, the leader lands a message in AZ-A, then instantly fires two carbon-copies across zone borders. Those hops travel on the most expensive road in the data-center—inter-AZ egress—and they’re non-negotiable: the leader can’t raise the high-water mark until both copies salute. Here’s the bite-size loop:
- Ingress: The message is sent to the leader broker in AZ 1. This incurs a base network ingress cost.
- Synchronous Replication: The leader broker writes the message to its local log and then forwards it to the two follower brokers in AZ 2 and AZ 3. This is a synchronous operation; the leader must await acknowledgment from all brokers in the ISR set.
- Network Egress: The data transfer from AZ 1 to AZ 2 and AZ 1 to AZ 3 incurs inter-AZ data ingress and egress charges. For every byte written by the producer, two bytes are transferred across the expensive AZ boundary.
- Acknowledgement: Once the followers have successfully written to their local logs and acknowledged the write, the leader can acknowledge the write back to the producer. The High Watermark is then advanced, making the message visible to consumers.
Mathematically, each write costs
where N is the replication factor.
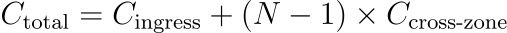 where N is the replication factor.
where N is the replication factor.With the default replication factor = 3, that’s two egress legs per byte. Feed the cluster 1 TiB a day and you leak 2 TiB across zones—about $40 every single day at $0.02/GB. Multiply by all your topics and the “replication tax” often outruns the brokers’ compute bill. Keep this figure in mind; in the next section we’ll show how diskless Kafka turns those costly hops into a rounding error.
One Cluster, Multiple Modes
The premise of a diskless architecture is that not all data workloads require the same Service Level Objectives (SLOs). A Kafka cluster often serves a multitude of use cases with vastly different performance characteristics. For example:
- Transactional Systems: A financial ledger or e-commerce order system requires extremely low latency, strict message ordering, and ironclad, per-message durability guarantees. While diskless topics can be a reasonable choice for most use cases, if extremely low latency is a must have, then a classic, disk-based topic is the best choice.
- Log and Telemetry Aggregation: Centralizing application logs, IoT sensor data, or user interaction metrics is often tolerant of higher end-to-end latency. For this data, some micro-batching is acceptable, and the primary requirements are reliable, cost-effective transport of large data volumes. This makes it an ideal workload for a diskless topic.
- Asynchronous Job Queues: Data streams feeding batch processing or analytics systems are often characterized by high throughput and less stringent latency demands. Here, cost-efficiency and operational simplicity are the key drivers, thus making it a good workload for a diskless topic, unless there is a need for really low latency.
Treating all three the same is like giving every athlete identical shoes and pacing instructions—you guarantee someone underperforms and someone else overpays. A hybrid cluster lets you hand-pick the right gear per topic: classic for the sprinters, diskless for the distance runners, and a custom mix for everything in between. The result is a lineup where every workload hits its Service-Level Objective without dragging the rest of the team—or the cloud bill—down.
Technical Deep Dive: The Diskless Data Path
A diskless topic fundamentally re-routes the data flow, replacing the broker's local log segment files with objects in a shared object store. This introduces several significant architectural changes.

1. Leaderless Writes: every broker is an open door
Pull the crown off the partition leader and something magical happens—any broker can accept a write. The moment a message arrives, the broker drops it into RAM and keeps pouring until one of two gauges trips: a time-based timer or a buffer-size ceiling. Hit either limit and the whole batch is frozen into an immutable segment and pushed to object storage; After the PUT 200 OK, only metadata is passed between nodes.
Why this matters:
- Perfect load balance – With no single leader, traffic skates to whichever broker has room. Hot partitions cool off on their own.
- Instant scale-up – A fresh broker doesn’t chase replicas; it just registers with the cluster and starts catching writes. Recovery is a handshake, not a data marathon.
- No leadership fights – Failover is trivial because there’s nothing to elect.
- Avoidance of cross-az traffic – Producers can be configured so they only produce data to a broker in their availability zone, making it more efficient in both time and cost.
The payoff is a write path that flexes elastically under load, heals in seconds after a node drop, and erases the old hotspots that once kept you up at night.
2. Reads That Feel Local—even When the Bytes Live Far Away
From the consumer’s point of view nothing changes: a Fetch call flies to any broker and data comes back. The magic happens behind the curtain, where each broker moonlights as a mini-CDN:
-
Hot slice, instant bite. If you’re tailing the log, chances are the records still sit in the broker’s memory. The broker hands them over in microseconds—you never touch the object store.
-
Cold slice, quick road-trip. Ask for older offsets and the broker looks up the segment’s object key, pulls it from S3/GCS, streams it to you, and—if its cache has room—keeps a copy for the next reader. One extra round-trip adds tens of milliseconds, not seconds.
Offset bookkeeping stays in the broker’s ledger, mapping every range of messages to a specific object and byte span, so consumers see a single, unbroken timeline.
The result: real-time workloads stay snappy, deep-history scans stay possible, and the cluster decides on the fly which data deserves front-row seats in RAM and which can relax in cheaper storage until called up.
3. True Separation of Compute and Storage
This model creates a genuine separation of the compute (brokers) and storage (object store) layers. In classic Kafka, a broker is a tightly coupled unit of compute and storage. Scaling for more processing power requires adding a new broker and waiting for a network-intensive data rebalancing process to complete.
With a diskless architecture, the broker tier becomes a stateless compute layer. Scaling for throughput is as simple as adding more broker instances, which can immediately begin serving traffic. This provides immense operational elasticity and allows for independent scaling of processing power and long-term storage capacity.
4. Analysis of Failure Modes and Durability Guarantees
This architecture changes Kafka's durability model and introduces new and interesting trade-offs:
- Broker Crash and Data Loss: In traditional Kafka,
acks=1guarantee ensures that data has been persisted in at least 1 broker’s disk (or at least in their page cache). If this broker were to crash before it could replicate a specific message to other brokers, the risk of data loss is quite high. Currently, Diskless doesn’t support this guarantee model, but stay tuned, we are exploring this problem space at the moment. - Object Store Latency: A sudden increase in object store
PUTlatency will cause broker memory buffers to fill up. This will exert backpressure on producing clients, increasing their local latency or causing write failures, depending on their configuration. - New Durability Model: The
acks=allguarantee of classic Kafka is replaced. For a diskless topic, a produceracksignifies that data has been persisted in object storage, guaranteeing its durability.
Day-2: Running, Observing, and Maintaining a Diskless Cluster
Adopting a diskless architecture requires understanding its impact on "Day 2" operations and monitoring. The lifecycle of a diskless topic is managed differently from that of a Kafka topic.
Partitions: Plan Once, Sleep Better. Altering the partition count of an existing diskless topic is as complex as altering it on a classic topic. For this reason, operators should plan their partitioning scheme carefully at topic creation time.
Quick rule of thumb: target partitions = future peak MB/s ÷ Consumer rate in MB/s.
Retention: Same, but Different. Diskless topics are ruled by the same retention policies as classic topics (time or size based), and semantically they mean the same, what is the data that should be retained, and what should be deleted. What changes is the way of enforcing this. Initially, data violating the retention policy is logically deleted, meaning it's marked for deletion but not yet removed from object storage. A separate process then permanently deletes objects from storage once all messages within them are marked for deletion.
Tuning for Optimal Economics and Performance
The performance of a diskless topic is highly configurable. The key is to find the largest buffer size and commit interval that still meets the application's SLOs, thereby maximizing cost savings.
diskless.append.commit.interval.ms: This dictates the maximum time messages reside in the buffer before a flush is triggered. A lower value reduces potential data loss on crash and lowers append latency, but increases API costs due to more frequentPUToperations.diskless.append.buffer.max.bytes: Triggers a flush when the buffer reaches this size. This works in tandem with the time-based interval.- Compaction: Background compaction is critical for economic efficiency. It merges smaller segment objects into larger ones, reducing the total object count (lowering management and API costs) and improving read performance by minimizing the number of
GETrequests required for a large scan.
Here are two example tuning profiles:
| Parameter | Profile A: Low-Latency Telemetry | Profile B: Maximum Cost-Saving Logs |
|---|---|---|
commit.interval.ms | 200 | 10000 |
buffer.max.bytes | 1MB | 64MB |
| Resulting Latency | Lower (300ms+) | Higher (seconds) |
| API Cost | Higher | Lower |
Furthermore, a complete TCO analysis must account for the cost of object store operations. Egress traffic is not the only factor. Every buffer flush results in a PUT request, and every read from cold storage results in a GET request, each with an associated cost. A cluster with very small buffers and a short commit interval can generate millions of API requests, adding a significant line item to the cloud bill. Tuning buffers to be as large as your latency SLOs allow is therefore essential for managing both egress and API costs. As an advanced optimization, operators should use object store lifecycle rules to transition older data to cheaper storage tiers (e.g., S3 Standard-IA), further reducing long-term storage costs.
A More Versatile Kafka
The diskless architecture is not a replacement for classic Kafka but rather a powerful extension. It transforms Kafka from a single-paradigm platform into a more versatile, multi-modal system. By moving from a tightly coupled scale-unit to a disaggregated, cloud-native design, it provides a technical solution to the economic friction of running large-scale streaming workloads in the cloud. This allows a single Kafka cluster to house a wider range of applications, each with its own finely tuned balance of performance, durability, and cost, making the platform more economically viable and architecturally flexible for the future.
Ready to Slash Your Kafka Cloud Bill? Calculate your potential savings with our TCO calculator, then join other engineering leaders already exploring diskless architectures with our Diskless Implementation in the Inkless repo. Calculate Savings | Inkless Repo
