


Holistically managing your Apache Kafka® infrastructure
With the recent acquisition of Kafkawise and its renaming to Klaw as well as the launch of Aiven for Apache Flink earlier in 2022, we are proud to introduce our complete ecosystem of technologies and tools around Apache Kafka®.
Our vision is to offer a truly end-to-end open source based ecosystem of services and tooling deeply integrated with Apache Kafka that can fit the data streaming needs and workloads of any organization.
An organization’s growth and development with Apache Kafka
We constantly see companies taking the first baby steps on their streaming data journey. This journey is a continuous process of development, experimentation and implementation. Companies go through different stages, each with its associated characteristics and needs.
First steps
When companies adopt Apache Kafka, they initially focus on basic necessities — much like babies needing good quality nutrition and sleep to develop their bodies. For companies developing their Apache Kafka infrastructure, these necessities are about getting familiar with the technology and understanding its application for their specific needs and use cases. Companies also research the basic concepts and spin up Apache Kafka clusters just to get things going.
Companies starting with Apache Kafka will also want to understand how (and where) to spin up clusters, examine their streaming topology, and explore their latency requirements for specific use cases based on existing data volumes, and so on.
Growing needs
When Apache Kafka grows in the organization, its capacity also needs to grow larger so it can handle greater amounts of traffic and use cases. An organization might start using Apache Kafka to transport data between environments and databases but as Kafka’s adoption grows, it might need to interact with edge devices, message queues, blob or cloud storage or enable real time processing to ensure data correctness and availability. The more an organization uses Apache Kafka, the more requirements it will have.
The more an organization uses Apache Kafka, the more requirements it will have.
Leaving the nest
Once a child reaches a certain age, they start moving outside their family home and become part of a wider team, like a nursery or a school. They start learning how to interact and behave in society.
For companies, this is the third stage of Apache Kafka adoption that brings additional needs for tooling and software. Apache Kafka becomes the backbone of data transportation around the organization. As more and more use cases emerge, more schemas will be created and existing schemas evolve over time. New topics and partitions will be created to highlight the different types of events multiple teams will want to have access to. At the same time, new use cases will be enabled such as real time data pipelines or event driven applications.
Companies need to properly manage and track how the topics and schema change and evolve in their Apache Kafka environment to ensure that Apache Kafka applications are not impacted by schema and topology changes and updates.
Last, as the company’s usage of Kafka grows further, it needs to establish a governance structure and a mechanism to ensure that Apache Kafka meets the specific standards and rules that apply. This lets the technology to start supporting mission-critical applications in a secure, compliant way.
By offering a full open source streaming ecosystem for Apache Kafka, we want to support organizations in each and every stage of their Apache Kafka journey. We want to walk the whole journey with them and become their trusted partner. From seamlessly setting up clusters to testing or running Apache Kafka services, all the way to building an end-to-end platform service team around Apache Kafka, Aiven’s ecosystem will be there.
A streaming ecosystem to support your growth
Let us take a look at the tools and services in our open source ecosystem in more detail.
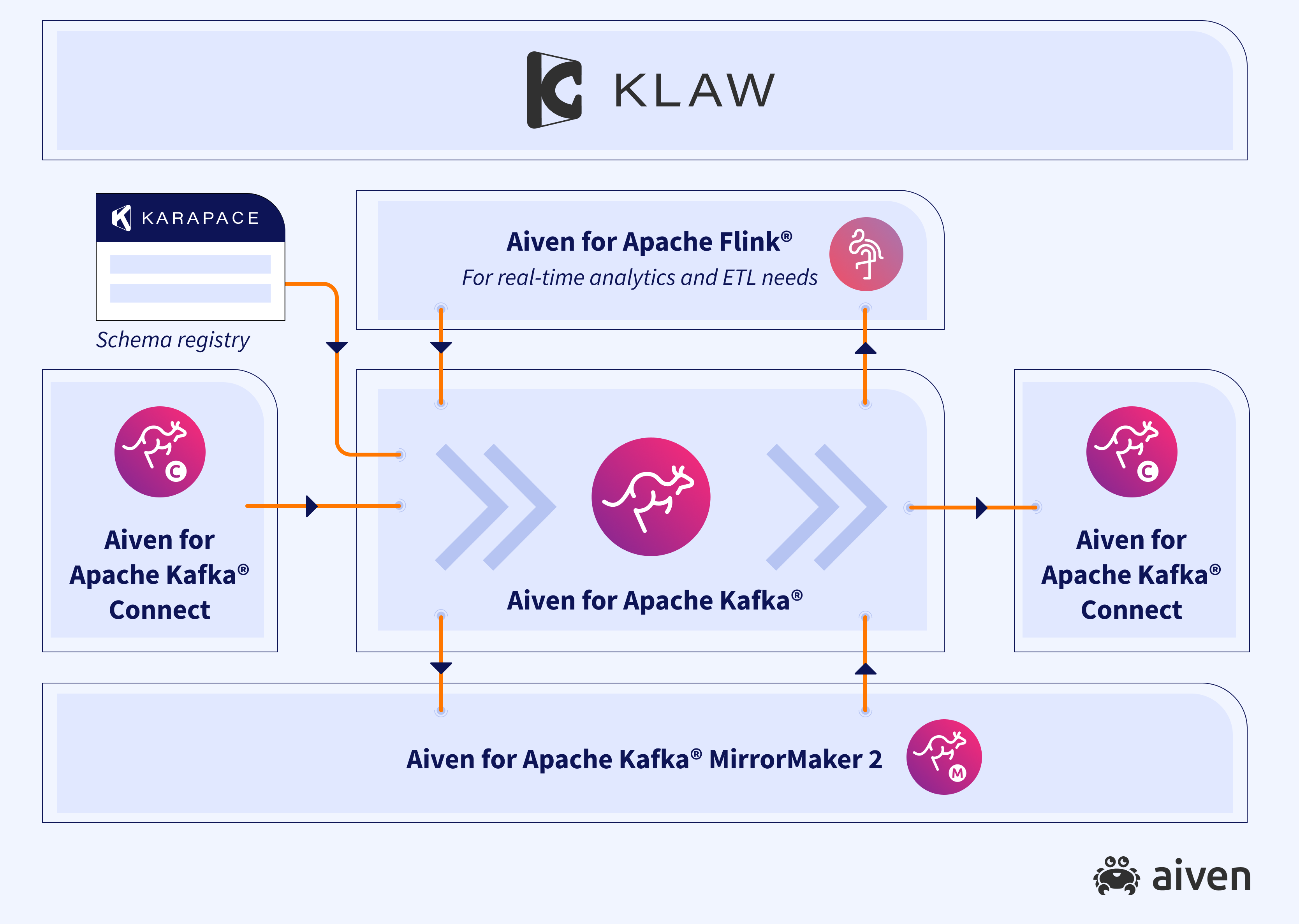
Aiven for Apache Kafka
Aiven for Apache Kafka is the core event streaming framework that allows the transportation of data streams in an organization.
Typically customers starting with data streaming will want to focus on Apache Kafka itself: getting it up and running and ensuring they have enough knowledge and training to get it off the ground.
With Aiven for Apache Kafka, you can seamlessly manage, operate and transport real time data in one place. You can also integrate with other Aiven services, and migrate clusters from other cloud regions and external systems.
Aiven for Apache Kafka®
Apache Kafka as a fully managed service, with zero vendor lock-in and a full set of capabilities to build your streaming pipeline.
Try our open source service!Aiven for Apache Kafka Connect
Aiven for Apache Kafka Connect enters the picture with additional systems. The more you use Apache Kafka, the more likely it will be that managing your own configurations for connecting to external systems will become a chore of its own. This is where Kafka Connect and a fully managed, distributed service like the one from Aiven really come into their own.
Apache Kafka Connect enables customers to integrate existing data sources and sinks seamlessly in a scalable way, without having to manage separate connectors.
An example here would be using the Debezium source connector to extract committed changes to transaction logs in a relational database, such as PostgreSQL, and push them to a Kafka topic in a standard format so it can be easily read by multiple consumers.
Aiven for Apache Kafka MirrorMaker2
Aiven for Apache Kafka MirrorMaker2 is great for data replication needs. With it, you can run hybrid workloads, meaning you can maintain clusters in your own data centers, while moving other services and clusters to the cloud for better scalability. Or you can implement a true multi-cloud strategy, where different or identical clusters reside in multiple cloud regions and/or cloud environments.
In Aiven for Apache Kafka MirrorMaker2, you get a fully managed, fully open source distributed data replication service for Apache Kafka. It enables cluster to cluster data replication, disaster recovery and geographic proximity across regions or clouds.
Karapace
Karapace provides a fully open source Kafka Schema Registry. Applications can access it to serialize and deserialize messages with popular formats such as AVRO, Protobuf and JSON.
This enables you to centrally manage the schema and metadata of your applications across the various components and services of any event driven architecture.
Aiven for Apache Flink
Aiven for Apache Flink adds the ability to process data in real time. Using a streaming SQL engine based on Apache Flink, you can extract, transform and analyze data coming into Apache Kafka before pushing it to external services or systems.
Apache Flink allows you to move away from batch processing and start parallelizing tasks to be concurrently executed in a cluster. It can for example deliver data from Apache Kafka to monitoring systems or transform it before it goes into long term storage.
Aiven for Apache Flink®
A fully managed service for Apache Flink for all your real time ETL and streaming analytics use cases.
Start your free trialKlaw
Klaw can help when your Apache Kafka infrastructure grows too complex to manage comfortably without an interim layer. With Klaw, you can manage your topics and ensure that the right teams can access the right data in Apache Kafka.
In the early stages, you might use spreadsheets or an e-mail based request/approval system. This is fine when the teams interacting with Apache Kafka are relatively small. As the organization grows, however, these one-off processes will probably become a bottleneck for successfully managing and operating Apache Kafka at larger scale.
Enter Klaw: an open source data governance tool that helps enterprises exercise Apache Kafka® topic and schema governance, complete with automated processes and approval flows across DevOps teams and Data engineering teams.
When open source really makes a difference
Aiven is a firm believer that open source delivers the best technology to the industry. We are very committed to sustaining open source and want to keep playing a key part in driving open source technologies forward.
In line with our open source roots and values, we want Apache Kafka engineers and developers to feel empowered by the solutions they use. They need to know that there is an active community to support them throughout their Apache Kafka journey - whether that’s with Aiven or not.
That’s why all the components of Aiven’s ecosystem around Apache Kafka are open source based. We want to ensure that the codebase of these technologies is maintained and supported by inclusive communities with an in-depth understanding of what developers need from the tools and services they use.
An invitation to explore Aiven’s ecosystem for Apache Kafka
Interested in finding out more about how the different technologies and tools of Aiven’s ecosystem for Apache Kafka can work together? Here’s a list of resources to get you started:
- Event streaming with Apache Kafka
- An event driven architecture with Aiven
- Managed Apache Kafka from Aiven
Take the first step today
Book an Aiven expert for a chat and find out if event streaming with Apache Kafka® is what you need.
Book a demo nowAre you still looking for a managed data platform? Sign up for a free trial!
