Managing data drift with Apache Kafka® Connect and a schema registry
Use Karapace, an open source Apache Kafka® schema registry, to prevent data errors by managing the data model across databases
Use Karapace, an open source Apache Kafka® schema registry, to prevent data errors by managing the data model across databases
Data flows across many technologies, teams, and people in today's businesses. Businesses are always growing and changing, so the way we collect and share data changes all the time too. We need to know not only who owns certain data but also what to do if that data changes. This problem is often referred to as "data drift."
Consider the scenario where a piece of data is modified at its source — what implications does this have for other systems reliant on it? How do we communicate necessary changes to stakeholders? Conversely, how do we prevent changes that could disrupt the system?
Having a robust plan for managing data drift is imperative. Businesses require data systems that function seamlessly and remain consistent, even amidst changes at the data source. Additionally, mechanisms are needed to assess and decide on changes, ensuring smooth operations for everyone involved with the data.
This tutorial will show you how tools like Apache Kafka®, Apache Kafka Connect, and the built in schema registry functionality provided by Karapace, can help businesses keep an eye on data drift. It will also explain how to either deny or allow changes based on what a business needs.
Apache Kafka is widely adopted as a backend data hub, empowering companies to move their data supported by a reliable, fast and scalable technology. Apache Kafka provides the benefit of decoupling data producers and consumers, by allowing the producers to reliably send the data without having to worry about consumers being ready to read, or being fast enough to keep up with throughput.
By default, Apache Kafka doesn't impose or verify the structure of data. Messages are pushed and retrieved in any format agreed upon by the producer and the consumer. However, in complex systems, where the same information needs to be reused across multiple consumers from different parts of the company, a simple external agreement is often insufficient. Apache Kafka must not only ensure that consumers can retrieve the data but also make sense of it, even if the structure of the messages changes slightly over time.
This is where the schema registry functionality enabled by Karapace comes into play: a way to decouple the structure of the message from its content and a method to verify that updates in the data structure won't break downstream consumers of the information. With Karapace, we can define the structure of each topic, along with the compatibility level that determines which data structure changes are allowed or rejected.
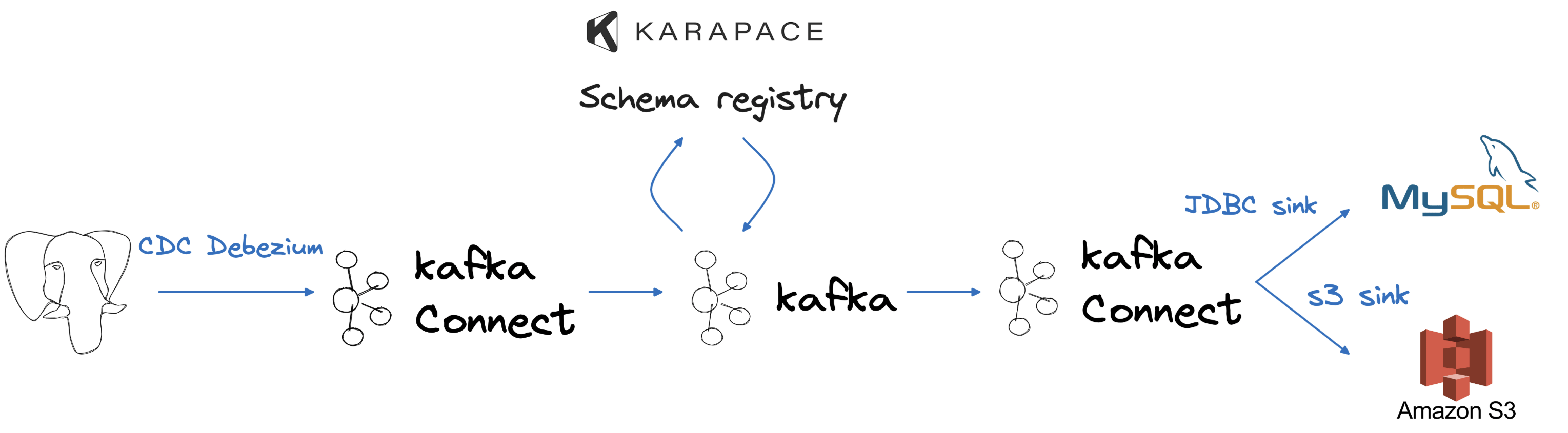
In the following sections, we will explore how the schema registry can be used in conjunction with Apache Kafka® Connect, both as a source and a sink, to check data structure changes and propagate them if they meet compatibility requirements..
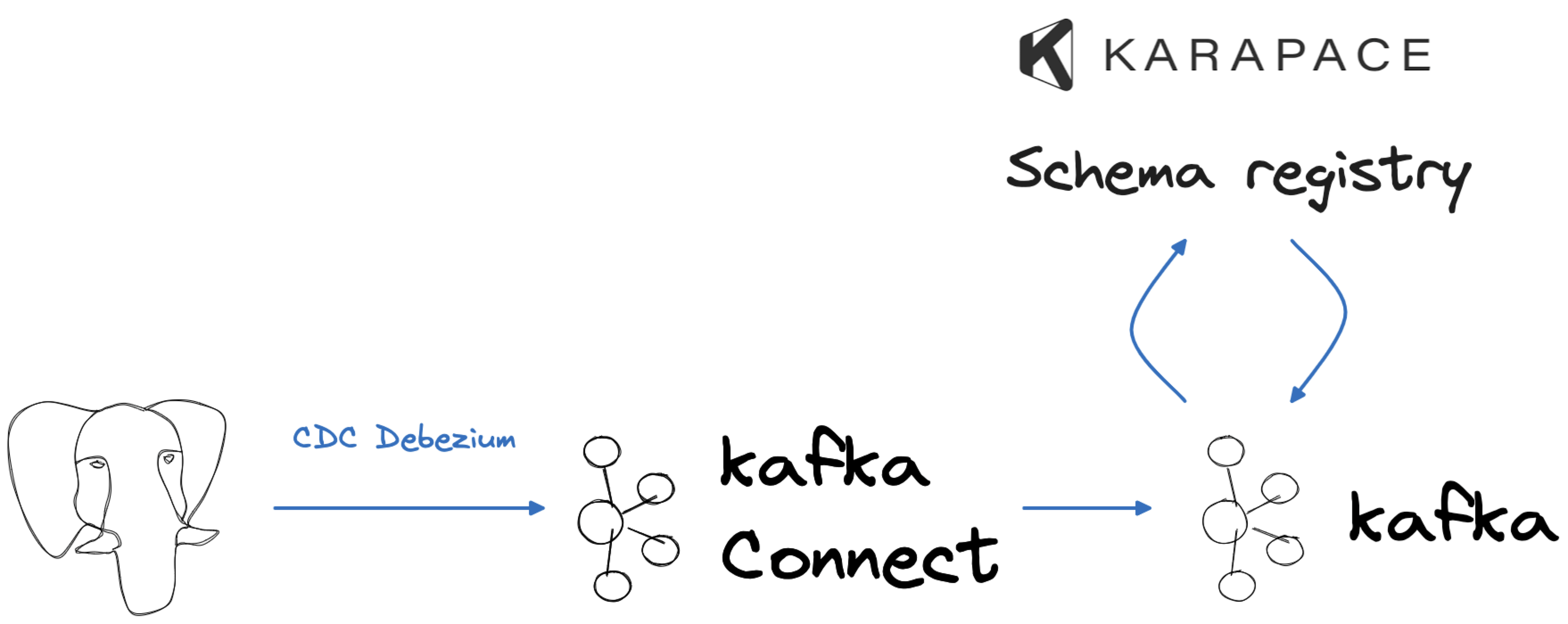
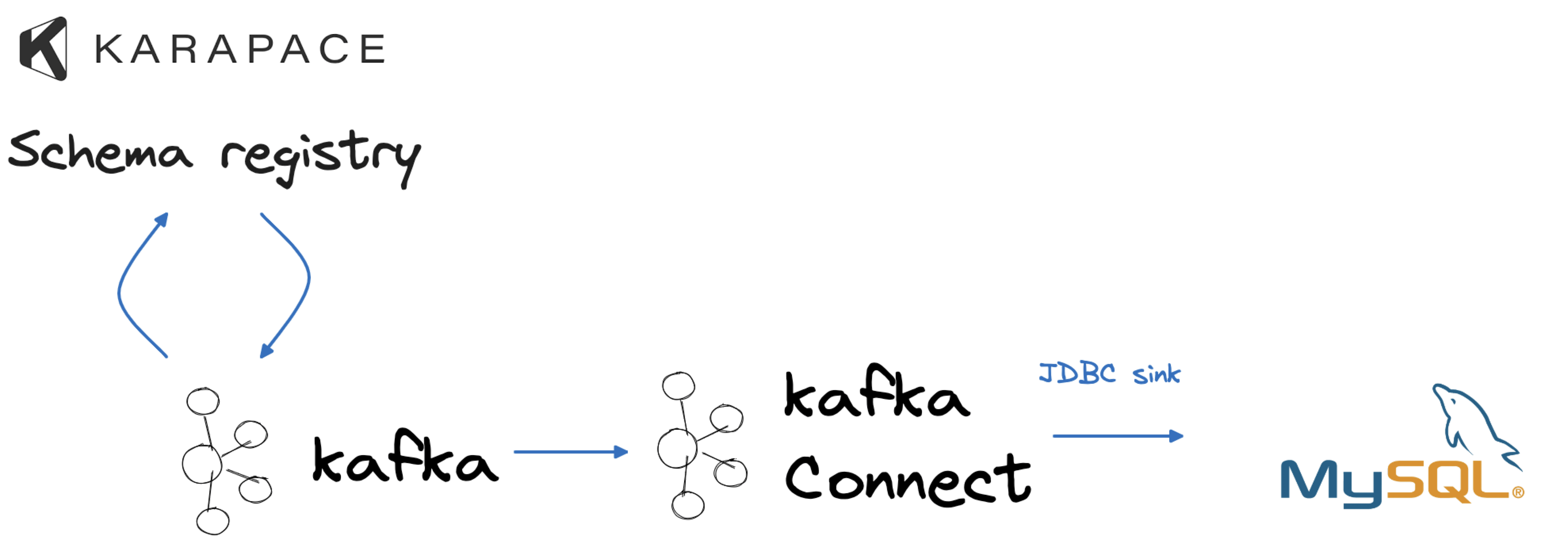
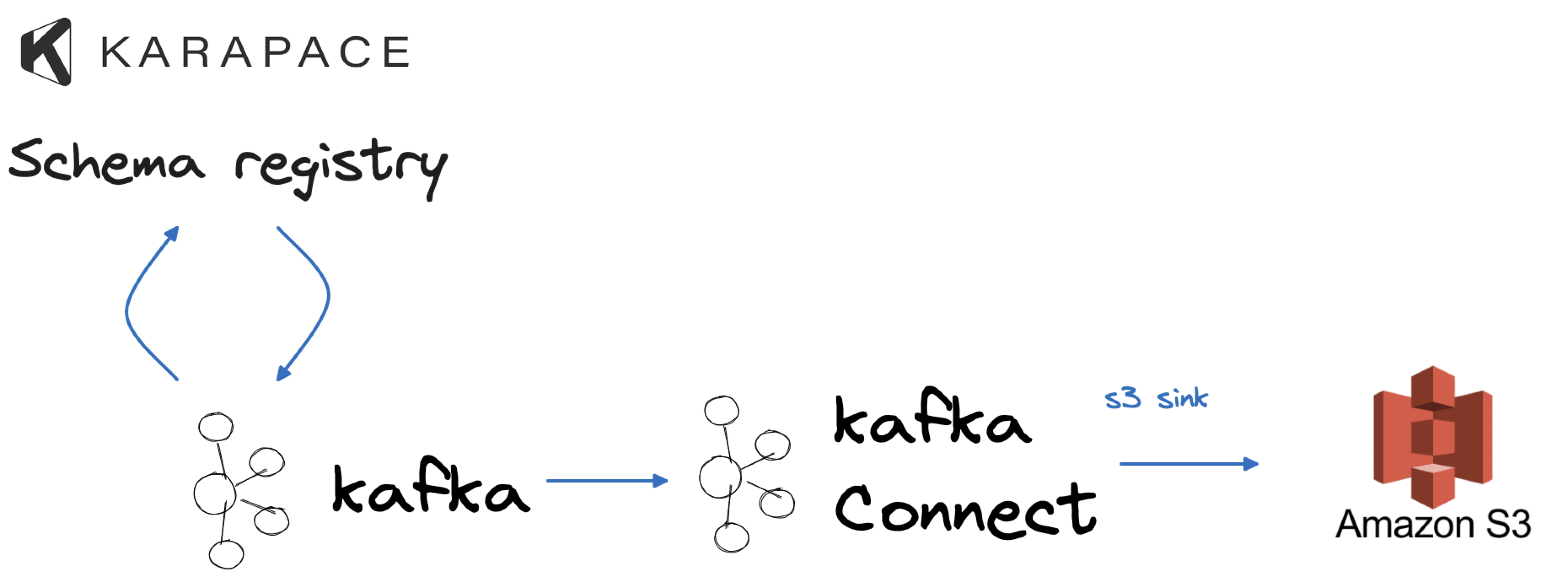
To simulate a typical company data flow, we will employ PostgreSQL® as our source, serving as our transactional database. Extracting data from it will involve using Apache Kafka, Apache Kafka Connect, and the Debezium source connector, enabling a real-time change data capture process. Once the data resides in Apache Kafka, we will leverage the integrated integration with Karapace to store the data schema and assess changes for compatibility. Finally, the results of our data changes will manifest in a MySQL database and an Amazon S3 bucket, mirroring two use cases: departmental analytics and long-term data storage.
We'll use Aiven for Apache Kafka®, Aiven for PostgreSQL®, Aiven for MySQL and a Debezium Kafka Connector to demonstrate this. Sign up for an Aiven account to follow along.
We can create the whole flow using Aiven's command line interface. You'll also need to install psql. Run the following commands:
Loading code...
Loading code...
Loading code...
The above three commands will start:
demo-drift-postgresql in the aws-eu-west-1 cloud region using Aiven's free tierdemo-drift-mysql in the aws-eu-west-1 cloud region using Aiven's free tierdemo-drift-kafka in the aws-eu-west-1 cloud region using Aiven's business-4 plan and enabling:
We can wait for the above services to be created with:
Loading code...
The first step of the data journey will be in the PostgreSQL database, acting as a company transactional backend. In this section we'll connect to the database and include some data. To connect, we can use the prebuilt Aiven CLI command (that requires psql to be installed locally):
Loading code...
After connecting, we can create a basic USERS table and include some data:
Loading code...
After mimicking the OLTP (Online Transaction Processing) system, we can now create the change data capture pipeline allowing us to track the USERS table in Apache Kafka. We'll set up the CDC flow using a Debezium connector and the following configuration file, which we'll name cdc-deb.json. Be sure to replace values like <DATABASE_HOST> in the below example.
Loading code...
In the above connector we are defining:
The Debezium PostgreSQL connector in the connector.class parameter
The PostgreSQL connection settings in the set of database.* parameters, We can get the list of needed parameters with the following call:
Loading code...
The PostgreSQL replication plugin name, slot name, publication name and mode. We can either create the slot and publication in PostgreSQL beforehand or have the connector create them for us.
The list of tables to include in the replication (public.users)
The usage of Avro and Apache Kafka schema registry functionality for both message keys and values. We can fetch the needed connection parameters (<KAFKA_HOST>, <SCHEMA_REGISTRY_PORT>, <SCHEMA_REGISTRY_PASSWORD>)
Loading code...
The above command will report the Kafka schema registry URI in the form:
Loading code...
Once we've replaced the placeholder values in the file, we can create the connector with the following call where cdc-deb.json is the file containing the connector settings:
Loading code...
Once the connector is working, we can use kcat to check the data in Apache Kafka.
To get the kcat command for connecting to our Kafka service and also download the necessary SSL certificates, run:
Loading code...
Next, we can get the avnadmin password with:
Loading code...
Finally, we can take that kcat command and use it to check the data.
We need to add some parameters to explain what we want to read:
-C to tell it to act as a Consumer,-t sourcepg.public.users to tell it which topic to read from,-s avro to tell it to use Avro, and-r https://avnadmin:<SCHEMA_REGISTRY_PWD>@<KAFKA_HOST>:<SCHEMA_REGISTRY_PORT> to tell it where the schema registry isPutting all of that together, the command you run should look like this:
Loading code...
We should see the same four rows we inserted previously appearing in the standard Debezium format:
Loading code...
Having created the connector using Avro and the Karapace schema registry, we can examine the schema definition for the topic. By default, when utilizing Kafka Connect with a schema registry, two schemas are generated with names <TOPIC_NAME>-value and <TOPIC_NAME>-key to store the schema definition for the value and key, respectively.
We can get the list of schemas defined in Karapace with:
Loading code...
Which returns output similar to:
Loading code...
The above is the names of the two schemas for the Debezium topic. Each name is the concatenation of the database.server.name parameter (sourcepg), the schema and table name (public.users) and either the key or value suffix.
We can check which versions we have for the sourcepg.public.users-key topic with:
Loading code...
The output should show version 1 being available.
To check the definition of the schema sourcepg.public.users-key version 1 we can use the following command:
Loading code...
The output shows all the fields included in the key, including the id and name we defined in the original PostgreSQL table.
Loading code...
Now that we have the data in Apache Kafka, let's set up a consumer for the data to demonstrate how the solution manages drift. The initial consumer will be a MySQL database. We can establish the flow using a dedicated JDBC sink connector and the following code stored in mysql_jdbc_sink.json.
Loading code...
In the above connector we are defining:
The JDBC sink connector in the connector.class parameter
The MySQL connection settings in the connection.url parameter, We can get the parameters to compose the URL and the credentials with the following call
Loading code...
The target table name will be users_mysql with upsert mode (see insert.mode), inserting or updating existing rows based on the id field (see pk.mode and pk.fields parameters)
The table will be created automatically if it does not exist ("auto.create": "true") and evolve following the changes in the Apache Kafka topic ("auto.evolve": "true"). This will be key to propagating the drift to downstream technologies (MySQL in this case).
A transformation called extract to retrieve and propagate the status of the row after the change from the Debezium format
The usage of Avro and Apache Kafka schema registry functionality for both message keys and values. We can fetch the needed connection parameters (<KAFKA_HOST>, <SCHEMA_REGISTRY_PORT>, <SCHEMA_REGISTRY_PASSWORD>)
Loading code...
The above command will provide the Kafka schema registry uri in the form:
Loading code...
Having replaced the placeholder values, we can create the connector with the following call, where cdc-deb.json is the file containing the connector settings:
Loading code...
We can verify the status of the connector with:
Loading code...
The above command should show the connector in RUNNING state
Once the above connector is running, we can head to MySQL to check the data. To get the connection parameters, we can retype the following command:
Loading code...
And then connect with the following command, replacing the placeholders. Note the absence of spaces between the -p parameter and the password.
Loading code...
We can then check the data with:
Loading code...
The table is users_mysql following the table.name.format in the connector. The data should be in line with what we have in PostgreSQL.
Loading code...
If we check the table structure with describe users_mysql, we can see that the hero column has been mapped to a TINYINT in MySQL.
Loading code...
So far we've built a fairly traditional data pipeline. Now, let's include some changes to the original data structure in PostgreSQL to mimic drift.
In the terminal connected to the PostgreSQL database, execute the following command to add a POINTS integer column:
Loading code...
Nothing happens immediately in the target MySQL table after the DDL execution in PostgreSQL. The structure and the data of USERS_MYSQL is still the same.
Now change the data in PostgreSQL, using the following update statement:
Loading code...
In MySQL, execute:
Loading code...
We can see the effect on the MySQL table points in near real time:
Loading code...
As mentioned in the sink connector definition, "auto.create": "true" allows the automatic creation of the table if it doesn't exist, and "auto.evolve": "true" allows the evolution of the table in cases when new data columns are included.
What about removing columns? Let's test it! Let's drop the same points column we just added from the PostgreSQL terminal with:
Loading code...
If we execute our previous query in MySQL again:
Loading code...
We see that column is not dropped in MySQL, the structure of the users_mysql is the same and the points column is still filled.
Loading code...
This makes sense because downstream applications might be using the points column. An unexpected and unhandled drop of a column could have disastrous effects on the downstream data pipelines. However the risk actually is dealing with updated information, as the points column has been dropped from PostgreSQL and therefore cannot be updated.
What about changing the column type? A change in the column type could be needed in cases, like this example, where we want to migrate from a BOOLEAN to a VARCHAR for the HERO column. Let's execute the following in PostgreSQL:
Loading code...
As before nothing happens on the DDL statement, but, when we try to add some data using the new VARCHAR column type:
Loading code...
The insert goes well PostgreSQL as expected, but the Debezium source connector crashes with the following error:
Loading code...
This is because the schema is stored in Karapace with the BACKWARDS compatibility setting. The BACKWARDS compatibility ensures that consumers using an older schema definition are able to consume events produced with the current schema. The change, from BOOLEAN to VARCHAR could stop old consumers from being able to parse the information correctly, so it's not allowed and the connector fails.
For the sake of this example, let's remove the BACKWARDS compatibility setting and allowing all changes in the source system to propagate. We'll set compatibility to NONE allowing all the changes to propagate to the Apache Kafka topic.
First, we check the default compatibility level for the Apache Kafka service with:
Loading code...
This shows BACKWARD being the default. The same default setting is applied to the sourcepg.public.users-value topic, that we can check with:
Loading code...
To change the compatibility level to NONE for both key and value, run the following commands:
Loading code...
Now, if we restart the Debezium Source connector task 0 with:
Loading code...
We see that the source connector restarts correctly. Using avn service connector status demo-drift-kafka pg-source-users shows the connector in the RUNNING state:
Loading code...
avn service connector status demo-drift-kafka cdc-sink-mysql returns an error:Loading code...
The error indicates that the connector attempted to insert the new value (middle) into an integer column. This implies that the auto-evolution process did not alter the structure of the pre-existing column.
To confirm this, we can execute describe users_mysql on the MySQL database and validate that the hero column remains a tinyint.
In the JDBC sink connector documentation, the auto.evolution section says:
- The connector does not delete columns.
- The connector does not alter column types.
- The connector does not add primary keys constraints.
We already talked about automatic column deletion being a dangerous action. The same is true for the automatic change of column types, since downstream applications could rely on functions that work specifically on particular column types. Therefore, modifying a column type should be handled as a breaking change, correctly making the sink connector fail.
The scenario described above is one of the more strict scenarios possible, in terms of data evolution. Both the source and the target are relational databases with strict column type definition. In this second example we'll sink the data to an S3 bucket where the data structure is not defined upfront.
We can create a sink connector to S3 with the following JSON configuration file stored in a file named s3_sink.json
Loading code...
Where:
aws.* parameters refers to the S3-related secrets, as detailed in the connector prerequisites documentation.topics parameter defines the source of information (specifically, the sourcepg.public.users topic).format.output.type parameter specifies how the data will be stored (in this case, as json).key.converter and value.converter parameters enable the connector to retrieve schema information from Karapace.transforms section allows the extraction of the value after the change from the Debezium format.We can start the above connector with:
Loading code...
If we check the data in S3, we should see a document in the bucket containing all the changes implemented in PostgreSQL.
Loading code...
The output from the CDC -> Kafka -> S3 flow encompasses all events. Due to the Debezium compatibility mode being set to NONE, every change successfully stored in Kafka. Moreover, as S3 does not enforce a specific structure on the data, all changes, whether they involve new or deleted columns, have been written to the target bucket in JSON format.
If you followed this tutorial and want to remove the services used for testing, you can run the commands below:
Loading code...
Data and Schema drift must be managed in scenarios where multiple consumers want to access the changes happening in a source system. Apache Kafka, and the Karapace schema registry, provide a method to propagate compatible changes and forbid breaking ones by stopping the pipeline. Pay special attention to column drops, since they are not propagated automatically to target systems (specifically if the target is another relational database) and could cause problems with updated data on the deleted columns.
To summarize how changes are propagated:
| Action | Status | Description |
|---|---|---|
| Add column | ✅ | Propagates downstream if auto.evolve is set to true. |
| Remove column | ⚠️ | Does not propagate downstream in case of sink to relational database. Possible use of stale data for the dropped column. |
| Change datatype | ⚠️ | Depends on the change, compatibility settings and target technology. Not propagated in case of JDBC sink. |
A summary of Schema registry compatibility:
BACKWARDS allows you to stop the pipeline before ingesting data in Kafka, since breaking changes will not be included in the topicNONE allows you to continue ingesting, but might break downstream data pipelines if the downstream tech is relational or has precise column definition and evolution is not straightforwardTable of contents
avn service create demo-drift-postgresql \
-t pg --cloud aws-eu-west-1 -p free-1-5gbavn service create demo-drift-mysqldb \
-t mysql --cloud aws-eu-west-1 -p free-1-5gbavn service create demo-drift-kafka \
-t kafka \
--cloud aws-eu-west-1 \
-p business-4 \
-c kafka.auto_create_topics_enable=true \
-c kafka_connect=true \
-c kafka_rest=true \
-c schema_registry=trueavn service wait demo-drift-postgresql
avn service wait demo-drift-kafka
avn service wait demo-drift-mysqldbavn service cli demo-drift-postgresqlCREATE TABLE USERS (ID SERIAL PRIMARY KEY, USERNAME VARCHAR, HERO BOOLEAN);
INSERT INTO USERS (USERNAME, HERO)
VALUES ('Spiderman', TRUE), ('Flash', TRUE), ('Joker', FALSE), ('Batman', TRUE);{
"name": "pg-source-users",
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.server.name": "sourcepg",
"database.hostname": "<DATABASE_HOST>",
"database.port": "<DATABASE_PORT>",
"database.user": "avnadmin",
"database.password": "<POSTGRESQL_PASSWORD>",
"database.dbname": "defaultdb",
"plugin.name": "pgoutput",
"slot.name": "myslot1",
"publication.name": "mypub1",
"publication.autocreate.mode": "filtered",
"database.sslmode": "require",
"table.include.list": "public.users",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "https://<KAFKA_HOST>:<SCHEMA_REGISTRY_PORT>",
"key.converter.basic.auth.credentials.source": "USER_INFO",
"key.converter.schema.registry.basic.auth.user.info": "avnadmin:<SCHEMA_REGSITRY_PASSWORD>",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "https://<KAFKA_HOST>:<SCHEMA_REGISTRY_PORT>",
"value.converter.basic.auth.credentials.source": "USER_INFO",
"value.converter.schema.registry.basic.auth.user.info": "avnadmin:<SCHEMA_REGISTRY_PASSWORD>"
}avn service get demo-drift-postgresql --format '{service_uri_params}'avn service get demo-drift-kafka --json | jq -r '.connection_info.schema_registry_uri'https://avnadmin:<SCHEMA_REGISTRY_PASSWORD>@<KAFKA_HOST>:<SCHEMA_REGISTRY_PORT>avn service connector create demo-drift-kafka @cdc-deb.jsonavn service connection-info kcat demo-drift-kafka -Wavn service user-list --format '{password}' --project devrel-francesco demo-drift-kafkakcat -b <KAFKA_HOST>:<KAFKA_PORT> \
-X security.protocol=SSL \
-X ssl.ca.location=ca.pem \
-X ssl.key.location=service.key \
-X ssl.certificate.location=service.cert \
-s avro \
-r https://avnadmin:<SCHEMA_REGISTRY_PWD>@<KAFKA_HOST>:<SCHEMA_REGISTRY_PORT> \
-C -t sourcepg.public.users{"id": 1}{"before": null, "after": {"Value": {"id": 1, "username": {"string": "Spiderman"}, "hero": {"boolean": true}}}, "source": {"version": "1.9.7.aiven", "connector": "postgresql", "name": "sourcepg", "ts_ms": 1692017248192, "snapshot": {"string": "true"}, "db": "defaultdb", "sequence": {"string": "[null,\"235090528\"]"}, "schema": "public", "table": "users", "txId": {"long": 1036}, "lsn": {"long": 235090528}, "xmin": null}, "op": "r", "ts_ms": {"long": 1692017248487}, "transaction": null}
{"id": 2}{"before": null, "after": {"Value": {"id": 2, "username": {"string": "Flash"}, "hero": {"boolean": true}}}, "source": {"version": "1.9.7.aiven", "connector": "postgresql", "name": "sourcepg", "ts_ms": 1692017248192, "snapshot": {"string": "true"}, "db": "defaultdb", "sequence": {"string": "[null,\"235090528\"]"}, "schema": "public", "table": "users", "txId": {"long": 1036}, "lsn": {"long": 235090528}, "xmin": null}, "op": "r", "ts_ms": {"long": 1692017248493}, "transaction": null}
{"id": 3}{"before": null, "after": {"Value": {"id": 3, "username": {"string": "Joker"}, "hero": {"boolean": false}}}, "source": {"version": "1.9.7.aiven", "connector": "postgresql", "name": "sourcepg", "ts_ms": 1692017248192, "snapshot": {"string": "true"}, "db": "defaultdb", "sequence": {"string": "[null,\"235090528\"]"}, "schema": "public", "table": "users", "txId": {"long": 1036}, "lsn": {"long": 235090528}, "xmin": null}, "op": "r", "ts_ms": {"long": 1692017248494}, "transaction": null}
{"id": 4}{"before": null, "after": {"Value": {"id": 4, "username": {"string": "Batman"}, "hero": {"boolean": true}}}, "source": {"version": "1.9.7.aiven", "connector": "postgresql", "name": "sourcepg", "ts_ms": 1692017248192, "snapshot": {"string": "last"}, "db": "defaultdb", "sequence": {"string": "[null,\"235090528\"]"}, "schema": "public", "table": "users", "txId": {"long": 1036}, "lsn": {"long": 235090528}, "xmin": null}, "op": "r", "ts_ms": {"long": 1692017248494}, "transaction": null}curl https://avnadmin:<SCHEMA_REGISTRY_PASSWORD>@<KAFKA_HOST>:<KAFKA_PORT>/subjects["sourcepg.public.users-key","sourcepg.public.users-value"]curl -X GET https://avnadmin:<SCHEMA_REGISTRY_PASSWORD>@<KAFKA_HOST>:<KAFKA_PORT>/subjects/sourcepg.public.users-key/versionscurl -X GET https://avnadmin:<SCHEMA_REGISTRY_PASSWORD>@<KAFKA_HOST>:<KAFKA_PORT>/subjects/sourcepg.public.users-key/versions/1{
"id": 1,
"schema": "{\"connect.name\":\"sourcepg.public.users.Key\",\"fields\":[{\"default\":0,\"name\":\"id\",\"type\":{\"connect.default\":0,\"type\":\"int\"}}],\"name\":\"Key\",\"namespace\":\"sourcepg.public.users\",\"type\":\"record\"}",
"subject": "sourcepg.public.users-key",
"version": 1
}{
"name": "cdc-sink-mysql",
"connector.class": "io.aiven.connect.jdbc.JdbcSinkConnector",
"topics": "sourcepg.public.users",
"transforms": "extract",
"connection.url": "jdbc:mysql://<MYSQL_HOST>:<MYSQL_PORT>/<MYSQL_DB_NAME>?ssl-mode=REQUIRED",
"connection.user": "avnadmin",
"connection.password": "<MYSQL_PASSWORD>",
"table.name.format": "users_mysql",
"insert.mode": "upsert",
"pk.mode": "record_key",
"pk.fields": "id",
"auto.create": "true",
"auto.evolve": "true",
"transforms": "extract",
"transforms.extract.type": "io.debezium.transforms.ExtractNewRecordState",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "https://<KAFKA_HOST>:<SCHEMA_REGISTRY_PORT>",
"key.converter.basic.auth.credentials.source": "USER_INFO",
"key.converter.schema.registry.basic.auth.user.info": "avnadmin:<SCHEMA_REGISTRY_PASSWORD>",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "https://<KAFKA_HOST>:<SCHEMA_REGISTRY_PORT>",
"value.converter.basic.auth.credentials.source": "USER_INFO",
"value.converter.schema.registry.basic.auth.user.info": "avnadmin:<SCHEMA_REGISTRY_PASSWORD>"
}avn service get demo-drift-mysqldb --format '{service_uri_params}'avn service get demo-drift-kafka --json | jq -r '.connection_info.schema_registry_uri'https://avnadmin:<SCHEMA_REGISTRY_PASSWORD>@<KAFKA_HOST>:<SCHEMA_REGISTRY_PORT>avn service connector create demo-drift-kafka @mysql_jdbc_sink.jsonavn service connector status demo-drift-kafka cdc-sink-mysqlavn service get demo-drift-mysqldb --format '{service_uri_params}'mysql -u avnadmin \
-P <MYSQL_PORT> \
-h <MYSQL_HOST> \
-D defaultdb \
-p<MYSQL_PASSWORD>select * from users_mysql;+----+-----------+------+
| id | username | hero |
+----+-----------+------+
| 1 | Spiderman | 1 |
| 2 | Flash | 1 |
| 3 | Joker | 0 |
| 4 | Batman | 1 |
+----+-----------+------++----------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+--------------+------+-----+---------+-------+
| id | int | NO | PRI | 0 | |
| username | varchar(256) | YES | | NULL | |
| hero | tinyint | YES | | NULL | |
| points | int | YES | | NULL | |
+----------+--------------+------+-----+---------+-------+ALTER TABLE USERS ADD COLUMN POINTS INT;UPDATE USERS SET POINTS = CASE WHEN USERNAME = 'Batman' then 5 else 10 end;SELECT * FROM users_mysql;+----+-----------+------+--------+
| id | username | hero | points |
+----+-----------+------+--------+
| 1 | Spiderman | 1 | 10 |
| 2 | Flash | 1 | 10 |
| 3 | Joker | 0 | 10 |
| 4 | Batman | 1 | 5 |
+----+-----------+------+--------+ALTER TABLE USERS DROP COLUMN POINTS;SELECT * FROM users_mysql;+----+-----------+------+--------+
| id | username | hero | points |
+----+-----------+------+--------+
| 1 | Spiderman | 1 | 10 |
| 2 | Flash | 1 | 10 |
| 3 | Joker | 0 | 10 |
| 4 | Batman | 1 | 5 |
+----+-----------+------+--------+ALTER TABLE USERS ALTER COLUMN HERO TYPE VARCHAR;INSERT INTO USERS (USERNAME, HERO) VALUES ('Panda', 'middle');ERROR "Caused by: org.apache.kafka.common.config.ConfigException: Failed to access Avro data from topic sourcepg.public.users : Incompatible schema, compatibility_mode=BACKWARD reader union lacking writer type: RECORD; error code: 409"
Backwards compatibility, old schema type is boolean (with null), new schema type is string... incompatibleavn service schema configuration demo-drift-kafkaavn service schema subject-configuration demo-drift-kafka \
--subject sourcepg.public.users-valueavn service schema subject-configuration-update demo-drift-kafka \
--subject sourcepg.public.users-value \
--compatibility NONE
avn service schema subject-configuration-update demo-drift-kafka \
--subject sourcepg.public.users-key \
--compatibility NONEavn service connector restart-task demo-drift-kafka pg-source-users 0 {
"status": {
"state": "RUNNING",
"tasks": [
{
"id": 0,
"state": "RUNNING",
"trace": ""
}
]
}
}Caused by: org.apache.kafka.connect.errors.ConnectException: java.sql.SQLException: java.sql.BatchUpdateException: Incorrect integer value: 'middle' for column 'hero' at row 1
java.sql.SQLException: Incorrect integer value: 'middle' for column 'hero' at row 1{
"name": "s3sink",
"connector.class": "io.aiven.kafka.connect.s3.AivenKafkaConnectS3SinkConnector",
"aws.access.key.id": "<AWS_SECRET_ID>",
"aws.secret.access.key": "<AWS_SECRET_ACCESS>",
"aws.s3.bucket.name": ">AWS_BUCKET_NAME>",
"aws.s3.region": "<AWS_REGION>",
"topics": "sourcepg.public.users",
"format.output.type": "json",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "https://<KAFKA_HOST>:<SCHEMA_REGISTRY_PORT>",
"key.converter.basic.auth.credentials.source": "USER_INFO",
"key.converter.schema.registry.basic.auth.user.info": "avnadmin:<SCHEMA_REGISTRY_PASSWORD>",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "https://<KAFKA_HOST>:<SCHEMA_REGISTRY_PORT>",
"value.converter.basic.auth.credentials.source": "USER_INFO",
"value.converter.schema.registry.basic.auth.user.info": "avnadmin:<SCHEMA_REGISTRY_PASSWORD>",
"transforms": "extract",
"transforms.extract.type": "io.debezium.transforms.ExtractNewRecordState"
}avn service connector create demo-drift-kafka @s3_sink.json[
{"value":{"id":1,"username":"Spiderman","hero":true}},
{"value":{"id":2,"username":"Flash","hero":true}},
{"value":{"id":3,"username":"Joker","hero":false}},
{"value":{"id":4,"username":"Batman","hero":true}},
{"value":{"id":1,"username":"Spiderman","hero":true,"points":10}},
{"value":{"id":2,"username":"Flash","hero":true,"points":10}},
{"value":{"id":3,"username":"Joker","hero":false,"points":10}},
{"value":{"id":4,"username":"Batman","hero":true,"points":5}},
{"value":{"id":5,"username":"Panda","hero":"middle"}}
]avn service terminate demo-drift-postgresql --force
avn service terminate demo-drift-kafka --force
avn service terminate demo-drift-mysqldb --force