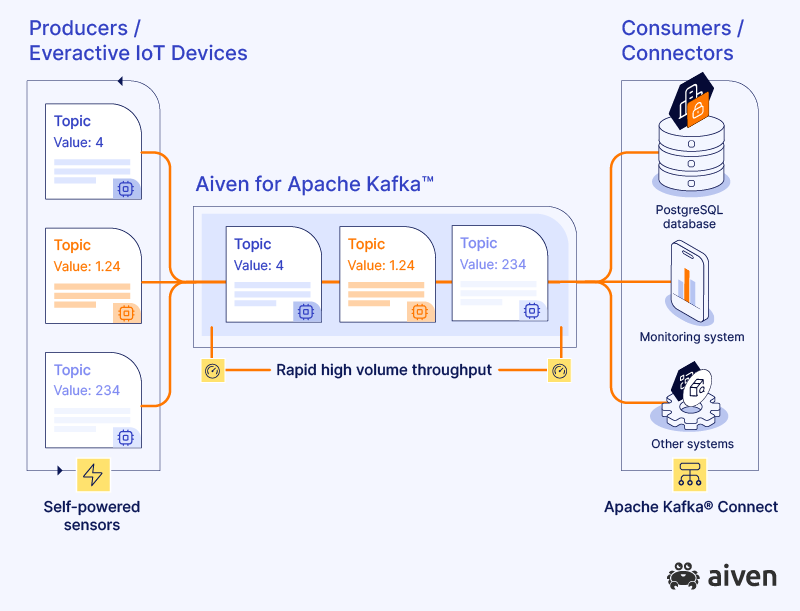
The outcome
Everactive has now had their managed Apache Kafka service running for more than a year, and they are very happy with how things have turned out.
“With Aiven, things just work better than they did before,” says Rob.
According to Carlos, the clearest benefit is change management in the configuration of the system. “With Kafka, thanks to its APIs, and to the Terraform provider that Aiven put out there, we’ve managed to automate almost everything: configuration, deployment, and maintenance. The automation has given us a lot of speed ín the development work. It’s also provided security, not just in terms of protecting against malicious things, but also in terms of not making a mistake. So we can change our configuration and scale up. We got rid of those performance problems!”
Another clear benefit is improved observability. “Before, it was really hard to understand the health of the system-we didn't really know if the system was about to be overloaded or not.
It was only when a problem happened that we knew that it was in bad shape.”
Thanks to the metrics that Apache Kafka offers, that’s now history. “We can react early on when something is happening and our DevOps person sleeps better at night. Besides, in the system I can track only the metrics I’m interested in, and not get flooded with data I wasn’t asking for.
And those sensor installations? The signal checking time has gone from 5 minutes to 1 second. It’s not only Apache Kafka but also new microservices that are easy to build on top of it.
Rob says innovation is easy with Apache Kafka. “We've been able to offer some additional services that we wouldn't have been able to offer before. For example, our customers can now receive their readings via webhook, and soon also via a MQTT streaming service. With Apache Kafka, we can automatically spin up services without any manual steps."
Both Rob and Carlos are happy enough with their current setup to want more of the same. “We're always changing our systems, of course. Next we’re planning to put Aiven for Apache Kafka at the very center of everything, providing data to and from every endpoint in the system.”