

Request-response is the traditional communication pattern used in computing and in most web applications. In web services, the standard approach is for a client to make a synchronous HTTP request, and then wait for a response from the web server. In a microservices architecture, request-response is also commonly used: a web server sends a connection request or query to a database, then waits for a response. For many use cases, this pattern — a chain of synchronous requests and responses — works well. Until it doesn't.
What happens when one link in the chain goes down? Requests that are waiting for a response don’t receive one at all. They continue to wait, or they time out. The entire application is blocked. What's more, as the number of services increases, the number of synchronous interactions between them increases as well. In such a situation, a single system's downtime affects the availability of other systems as well.
An alternative approach is building a microservices application on an event-driven architecture (EDA). Event-driven architecture is made up of decoupled components — producers and consumers — which process events asynchronously, often working through an intermediary, called a broker. That might feel like a mouthful. Don't worry — we're going to walk through these concepts one step at a time. In this article, we're going to look at the components that make up event-driven architecture, why you would use this paradigm, and how to implement it.
In this post, you'll get a general overview of what event-driven architecture is and how you can make it work for you. Here's what we'll look at:
- Core concepts
- Using events to notify about state change
- Using events to replicate state
- Event collaboration pattern
- Transitioning to EDA with Apache Kafka
Core concepts
1. The event
Everything in an event-driven architecture centers around the event. Put simply, an event is anything interesting that happens in your application. Events at all levels of your application, from the end-user client level down to the network connectivity level, may be noteworthy.
Here are some examples of events:
- A new user creating an account with your web application
- An HTTP request being rejected by your API gateway for exceeding a rate-limiting threshold
- A web server sending a query to the database for deleting a resource
- A failed connection attempt by an API server trying to reach a key-value store
As you can see, what qualifies as an event is incredibly broad.
2. The event record
If the occurrence of an event is to be captured, an event record is the data that captures that event. That data may include the following:
- request IDs or header information
- originating IP addresses
- query statements
- IDs of affected resources
- timestamps
- ... and so on
Because the sender of an event record (the producer, which we'll meet shortly) has no idea how that event will be consumed, it can only give a best guess as to what data to include in that record. Sometimes, all that is needed are the event's breadcrumbs – enough of a trail for the consumer to track down any additional information on its own if needed. Designing an event record payload can require some careful consideration.
3. Producers and consumers
In an event-driven architecture with various services, producers and consumers are the primary actors that deal with events. Producers go to work when an event occurs, piecing together an event record and sending that record to some sort of capturer. On the other side, consumers check or listen for the occurrence of specific events, so that they can respond accordingly to those events.
4. Streams
Just now, we mentioned that a producer sends event records to some sort of capturer. To be more precise, producers write records of an event to a stream. A stream is a persistent and ordered sequence of event records.
When an event occurs, producers send event records to the streams. Consumers watch the stream, waiting for the arrival or presence of certain kinds of events.
5. Decoupled components
While it might seem like there's an analogy between EDA and the request-response pattern (consumers request information about an event, while producers respond to the occurrence of an event by writing an event record) in EDA, producers and consumers are highly decoupled. They function independently of each other.
Producers write events without any knowledge whatsoever about the consumers of those events. In fact, producers don't even know if there are any consumers of an event at all.
Meanwhile, consumers only care that an event occurred, and are completely unaware of who the event producer is.
In EDA, because producers and consumers are highly decoupled, one service's outage or downtime no longer affects another service's availability. A producer, without any knowledge of its event consumers, will simply write event records. Even if all of an event's consumers are unavailable, the producer is unaffected. Similarly, a consumer simply listens for the presence of new event records but is otherwise unaffected if the producer of those events experiences downtime.
6. Asynchronous interaction
Because producers and consumers are decoupled, their interactions are asynchronous. After a producer writes an event record to the stream, its job is done. The producer doesn't care when a consumer does something with that event record, or whether anything is ever done with that event at all.
With asynchronous interactions, a consumer may read that event from the stream immediately, or at a later stage depending on its load. The consumer could even read the event at the end of the week when some sort of task is scheduled for aggregation and analysis. The point is: Becasue an EDA is asynchronous, services do not depend on the immediate performance of functions from other services. They do their job, and they go on with their lives.
7. Message brokers
While producers and consumers are the primary actors in an EDA, we also need an intermediary to help facilitate the storage and availability of the event stream. A message broker is responsible for acquiring, storing, and delivering events to their consumers. A message broker should be highly reliable, scalable, and most importantly, ensure that it does not lose events on system failures.
There are two categories of message brokers defined by how they store data:
- Store-backed: These brokers store events in a data store to serve the consumers. They purge events from their store after delivering them to consumers. RabbitMQ® and Apache ActiveMQ® are examples of store-backed brokers.
- Log-based: These brokers store events in logs. The brokers persist the events even after their consumption. Since the events are not removed, the brokers allow consumers to replay events from a previous point in time. NATS and Apache Kafka® are examples of these types of brokers.
Apache Kafka is one of the most popular durable open-source message brokers that enables applications to process, persist, and re-process events or streams of data. We will discuss the architecture of Kafka and its approach to routing in detail in the next article in this series.
Previously, we emphasized the highly decoupled nature between producers and consumers in an EDA. It is worth noting here that there is some necessary coupling between the producer and the message broker, and between the consumer and the message broker. An effective EDA system requires its message broker to be highly available for writing by producers. Similarly, both the store-backed and log-based brokers provide guarantees of event delivery.
8. Event schema
An event schema is the prescribed shape for an event record in an EDA. This event schema functions like an agreed-upon contract between producers and consumers in the system. Producers are designed to publish event records that comply with the event schema specification, and consumers know what to expect when reading events from the stream. We at Aiven developed Karapace to keep track of schemas and related changes.
Using events to notify about state change
Now that we've covered the core concepts of EDA, let's consider common use cases and patterns.
Brokers such as Apache Kafka support the publish-subscribe pattern, in which consumers define the routing of messages to them. Since the routing is consumer-driven, any consumer can plug into the brokers to receive the events they are interested in without affecting other services.
In an EDA, any given service does not know whether other services exist. A service is only interested in specific state changes in the system, and then that service reacts to the change. For example, let’s say we have two services in an eCommerce application:
- Orders Service: To accept orders from the customers.
- Shipping Service: To ship the orders received.
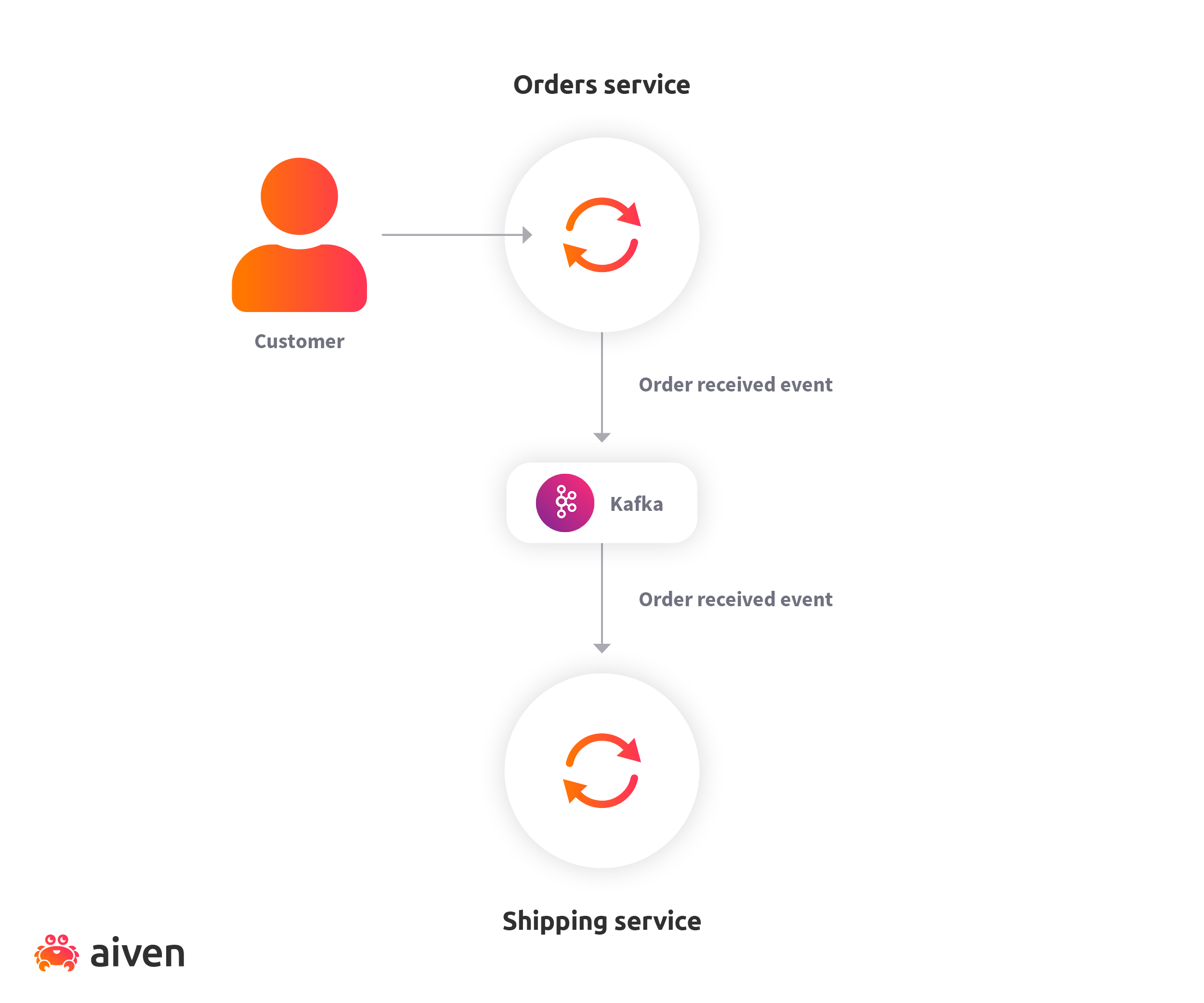
When a customer places an order, the Orders Service updates its state and publishes the "order received" event to the message broker. The shipping service fetches the event and updates its state. Due to loose coupling between the services, we can extend the feature set of our application without modifying the existing services.
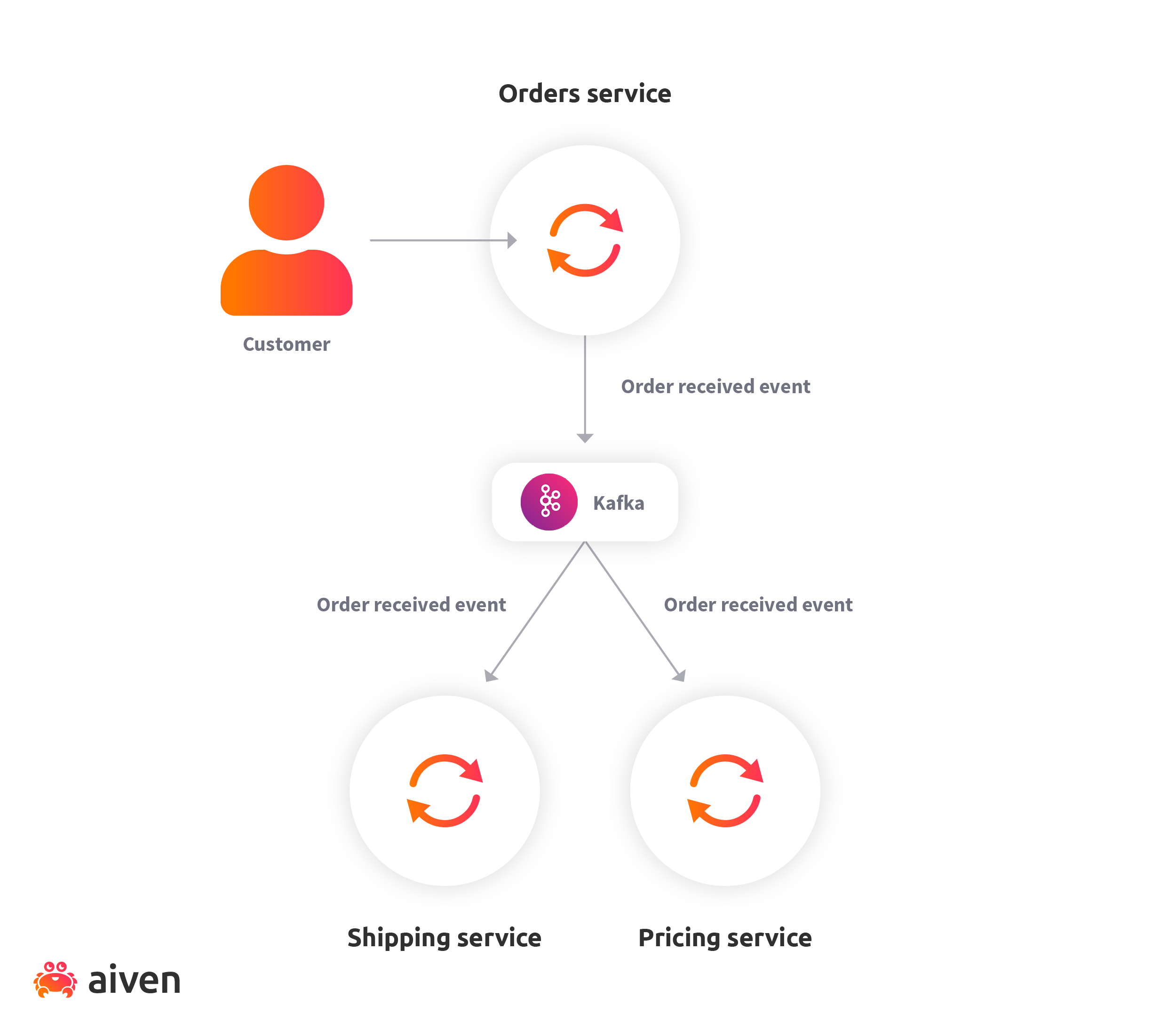
Let’s assume that we want to add a pricing service to the application. This service updates a product’s price based on its demand. Then, we can plug in the new service as a consumer of the "order received" event without affecting the other services.
Using events to replicate state
In the previous example, we used events to notify services of state changes. However, if the shipping service requires customer details, it would need to query some sort of customer service synchronously. The astute reader will likely realize that this type of synchronous interaction breaks the loose coupling between services. We can fix this problem with events.
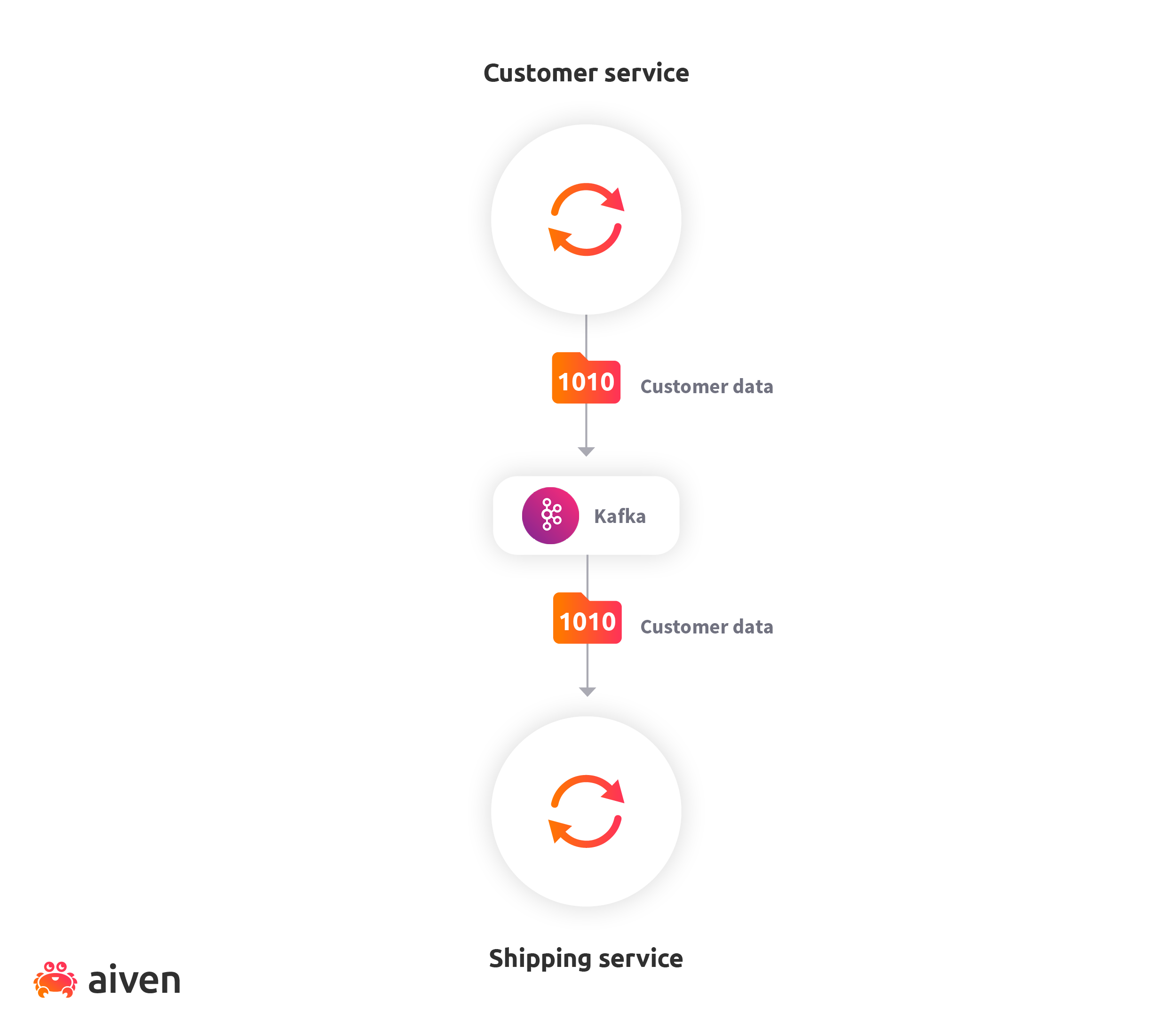
We can use events to replicate the state from the customer service so that the shipping service can use its local state to read customer details. Whenever a customer updates shipping information, a "customer data" event is published to the message broker. The shipping service is subscribed to "customer data" events, reacting to those events by keeping its own local state of customer shipping information up-to-date at all times. This pattern is formally termed event-carried state transfer.
Event collaboration pattern
Martin Fowler introduced a pattern called Event Collaboration which enables a set of services to collaborate on a single business workflow. In this architecture, each service does its bit in the workflow by listening to events and creating new ones. The events are processed in an orchestrated manner by the services to complete an operation.
In the following diagram for an eCommerce application, we see the workflow that comes out of the interplay of different services and events. Some services create events while others consume them. Sometimes, a service consumes an event and then reacts by creating a separate event. Events can be associated with each other through the use of topics.
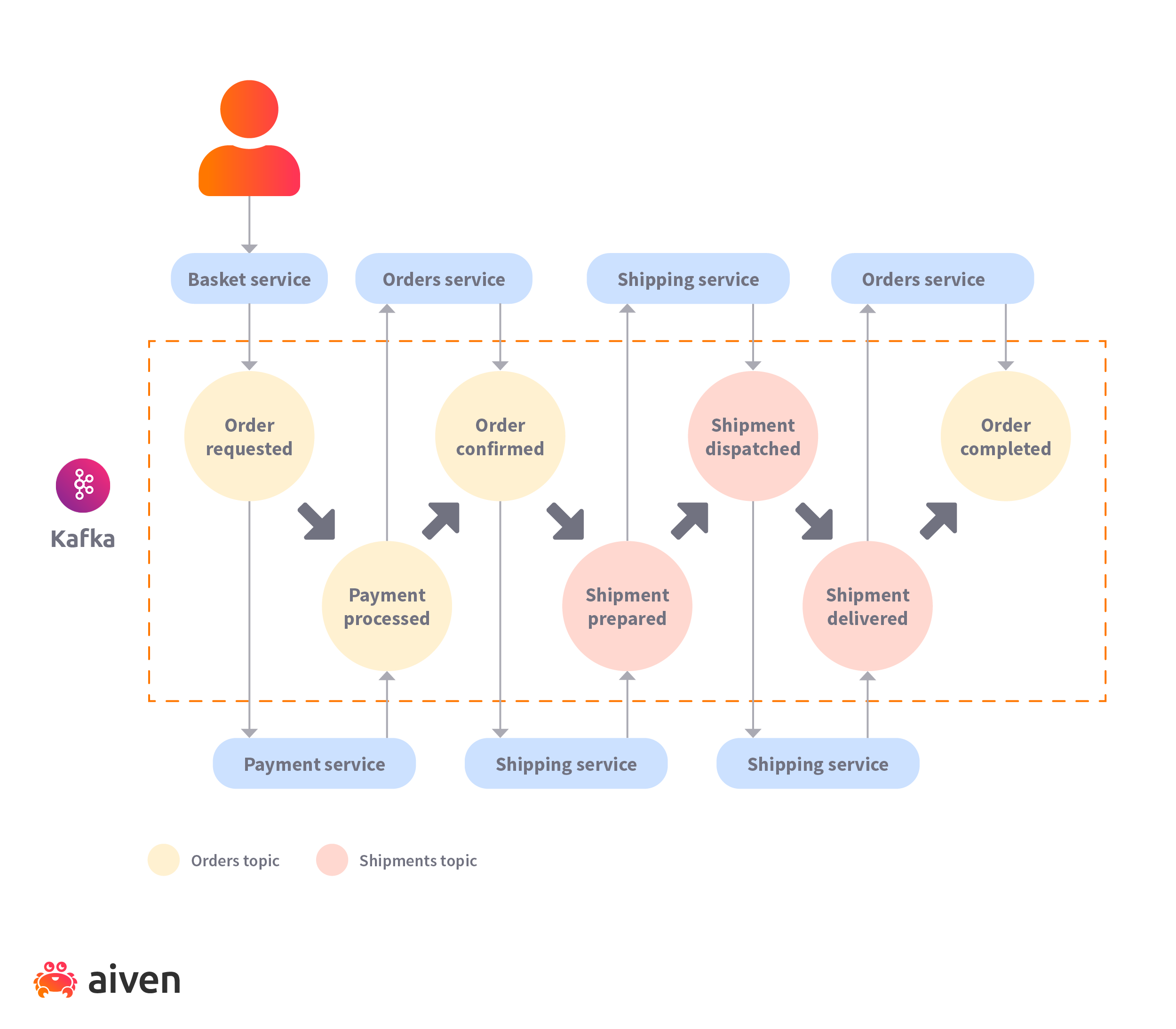
As you can see, no single service owns the process, and each service owns a subset of event transitions. The services only understand the event they require and the event they produce. Thanks to loose coupling, you can replace existing services or update services to raise more events without affecting the workflow, as long as you maintain compatibility with the produced event schema.
Transitioning to EDA with Apache Kafka
An Apache Kafka cluster is essentially a collection of log files filled with messages, spanning many nodes in a cluster. Kafka’s internals tie these log files together, reliably route messages between producer and consumer, replicate for fault tolerance, and gracefully handle failure. Kafka is a messaging system designed to address various use cases such as high-throughput streaming, durable and ordered message delivery, and long-term storage of large datasets. Kafka is a distributed, scalable messaging service which makes it an ideal backbone through which services can exchange events.
When transitioning to an event-based architecture, it may seem daunting to think about architectural changes and infrastructure management at the same time. To focus on implementing an EDA with Apache Kafka, you can offload the infrastructure concerns with a fully managed Apache Kafka solution, such as Aiven for Apache Kafka, deployed and hosted with major cloud providers like AWS, Azure, and GCP.
Wrapping up
In this article, we covered the core concepts that make up event-driven architecture. We looked at events, the main actors (producers and consumers), the role of the message broker for facilitating event streams, and the advantages of EDA with its asynchronous and highly decoupled structure.
The message broker is critical to the design and effectiveness of an EDA with Apache Kafka making an excellent choice for its scalable, reliable, and fault-tolerant qualities. A fully managed solution, such as Aiven for Apache Kafka, let’s you focus on the EDA implementation while keeping your Kafka service up and running, at the size you need, and in the cloud region of your choice.
Not using Aiven services yet? Sign up now for your free trial at https://console.aiven.io/signup!
Want to know more about Apache Kafka®?
We've got what you need!
Check out our free ebook for everything you always wanted to know about Apache Kafka, but were afraid to ask.In the meantime, make sure you follow our changelog, our blog or our LinkedIn account to stay up-to-date with product and feature-related news.

Table of contents
- Core concepts
- 1. The event
- 2. The event record
- 3. Producers and consumers
- 4. Streams
- 5. Decoupled components
- 6. Asynchronous interaction
- 7. Message brokers
- 8. Event schema
- Using events to notify about state change
- Using events to replicate state
- Event collaboration pattern
- Transitioning to EDA with Apache Kafka
- Wrapping up