


With the introduction of Aiven for AlloyDB Omni, many of our customers have wondered what the difference is between AlloyDB Omni and its architectural source project, open source PostgreSQL®. AlloyDB Omni is more than just a re-implementation of PostgreSQL, and understanding how it is similar – and how it differs – from open source PostgreSQL is a valuable exercise.
In this article, we’ll walk through at a high level how the two compare to each other and how they differ, what level of compatibility you can expect between AlloyDB Omni and PostgreSQL, and questions to ask yourself to help you evaluate which is right for you.
This is the first article in a series about PostgreSQL-compatible databases. In future articles, we’ll cover serverless PostgreSQL variants, as well as take a look at what the open source PostgreSQL community is releasing and why it’s exciting, so stay tuned!
What makes PostgreSQL Postgres-y
Before diving into AlloyDB Omni, it’s helpful to review the PostgreSQL project at a high level and understand what its characteristics are.
PostgreSQL is one of the most active and longest-running enterprise grade open source projects out there. The project became open source in 1996, making it almost 30 years old. Due to its extensive extension ecosystem and active contributor community PostgreSQL remains one of the most widely used relational databases on the planet.
PostgreSQL can be defined by a few main characteristics:
- Lightweight core architecture: PostgreSQL core is fundamentally lightweight compared to other database systems. It provides a set of basic functionality for managing databases, connections, users and backups, but doesn’t provide much beyond that. This is due to its second characteristic..
- Extensibility: Extensions are a first-class citizen in the PostgreSQL ecosystem, and some extensions have even gone on to become core functionality due to their popularity and use. The extensions ecosystem allows PostgreSQL to address new data use cases rapidly, without the overhead of committing to PostgreSQL core, and to address industry and use case specific data scenarios that fall outside of the “standard” uses of the software.
- SQL standardization: PostgreSQL adheres very closely to the SQL standard compared to other data storage technologies. This means that the vast majority of SQL statements you can construct for a PostgreSQL database are valid against other data stores that use SQL. This adds an additional layer of portability and ease of use if you ever need to migrate your PostgreSQL database to another technology.
- Data typing, ACID compliance, and relationality: While these may seem like standard components of databases today, when PostgreSQL was invented, enshrining these concepts was a core part of what made PostgreSQL what it is. All data in a PostgreSQL database must have a type, and you can define custom types as needed. Data must relate to other data in the database, and all transactions against the database must be transactional in nature and ACID (Atomicity, consistency, isolation, durability) compliant. Without PostgreSQL setting this standard, databases would not look the way they do today.
What is AlloyDB Omni?
AlloyDB Omni is the containerized, freely distributed image of Google’s AlloyDB database. AlloyDB is defined as “a fully-managed, PostgreSQL-compatible database for demanding transactional workloads. It provides enterprise-grade performance and availability while maintaining 100% compatibility with open-source PostgreSQL”, per Google’s official documentation.
AlloyDB Omni and Postgres compatibility
What this means in practice for AlloyDB Omni’s compatibility with PostgreSQL is that you can expect that any database transaction that you can make against a PostgreSQL database is one that will work against an equivalent AlloyDB Omni
At this time, Google lists no incompatibilities between AlloyDB Omni and open source PostgreSQL. Note that AlloyDB Omni follows PostgreSQL’s versioning scheme, and thus compatibility is also pinned to specific PostgreSQL versions. At the time of writing this article, the current version available of AlloyDB Omni is 15.7.0
SQL standard compatibility
AlloyDB Omni is fully compatible with the PostgreSQL SQL dialect, and adds additional SQL operators to manage specific kinds of data relating to columnar data processing and AI/ML workload processing. As these features do not exist in open source PostgreSQL, naturally these statements are incompatible.
AlloyDB Omni and PostgreSQL, architecturally speaking
Now that we understand the characteristics of PostgreSQL as a database and a bit about AlloyDB Omni, the next useful thing to do is to compare the architecture of both databases to see where they’re similar and where they’re different.
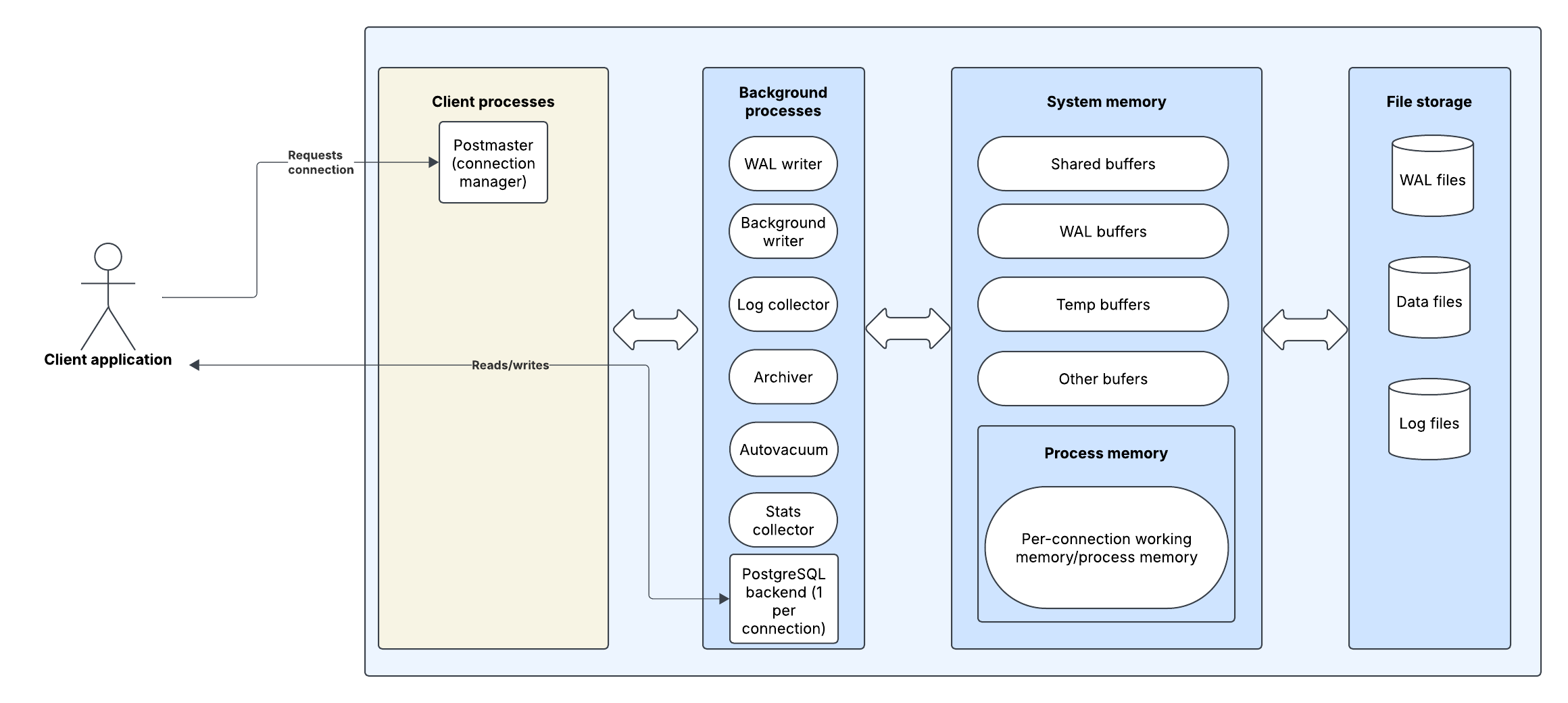
At a high level, we can divide PostgreSQL into 4 layers:
- Client processes, which manage connections to the database and spin up backend processes on a per-connection basis. This is where SQL statements are decoded and passed to the next layer for processing
- Background processes, which handle reads and writes to the database, as well as memory management for the PostgreSQL server. The most important of these are the WAL (write ahead log) writer, which records transactions to the database to apply them in order, the PostgreSQL backend processes, which manage requests per connection, and the autovacuum, which performs cleanup for the database.
- System memory, which consists of a collection of buffers. Each buffer is responsible for writing to a different part of the PostgreSQL’s file storage.
File storage, which is where the data for a table is actually stored on disk, in addition to storage for logs and other backups.
Comparing this to the AlloyDB Omni:
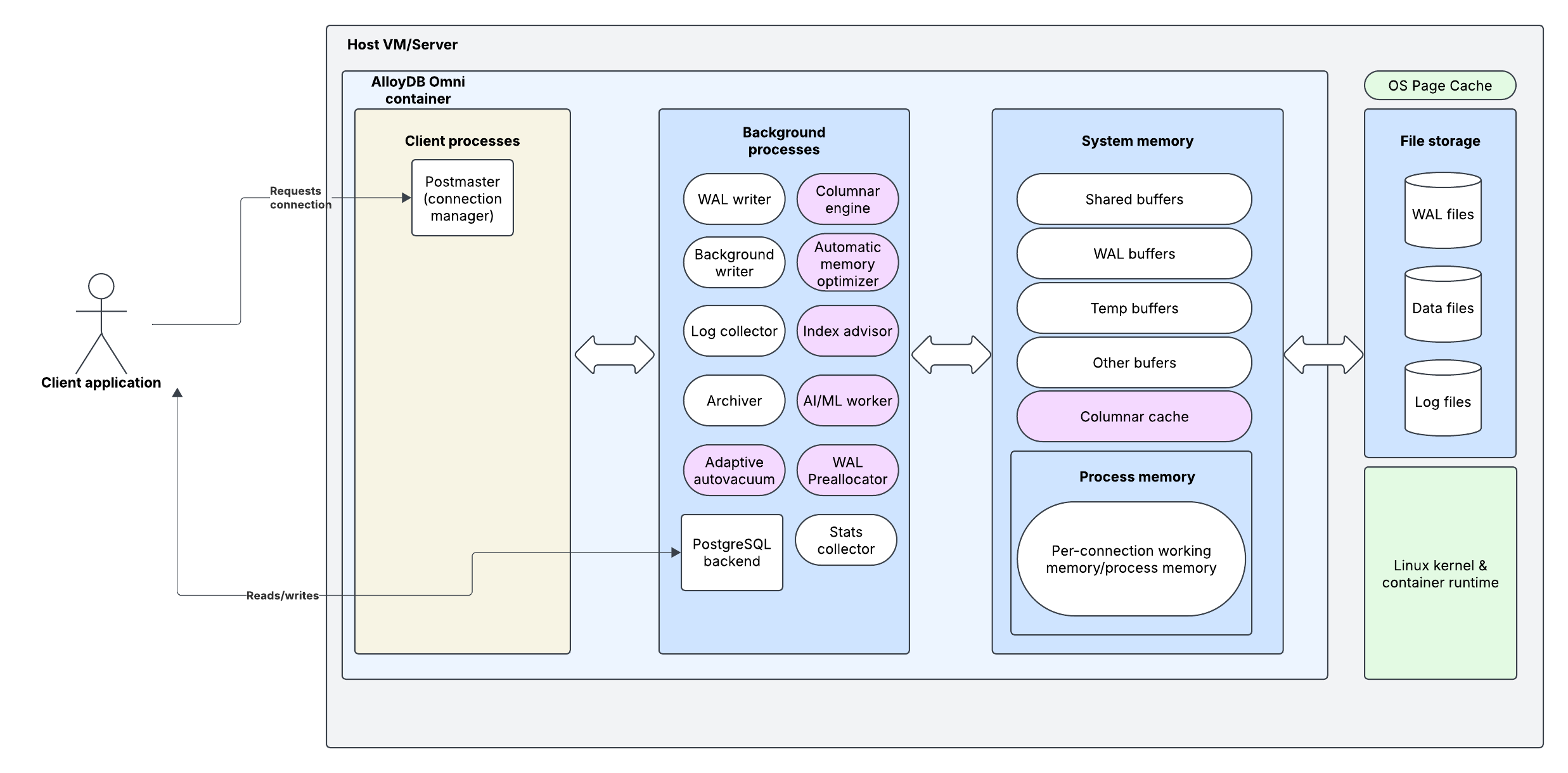
We see three main areas of difference in the layers previously described:
- In the background processes, we have a number of additional processes with various tasks:
- The columnar engine provides the logic for generating columnar indexes on a database and running queries against a column
- The AI/ML worker manages much of AlloyDB Omni’s optimizations for AI/ML workloads
- The WAL preallocator and automatic memory optimizer, in addition to optimizations Google has made to other background processes allow you to autoscale the memory required by these background processes and by AlloyDB Omni in general. AlloyDB was built specifically for Google Cloud and for management in the cloud, and the improvements made to memory management are a large part of that.
- The adaptive autovacuum is a rewrite of PostgreSQL’s vacuum function for cleaning up dead tuples. It is yet another background process optimized for management as a cloud resource.
- The next difference is the addition of a columnar cache to handle caching for columnar queries. By default this is set to 1gb and must be configured by hand.
- The final difference is at the container/VM layer, in which we see that file storage occurs on disk, outside of the container which runs AlloyDB Omni’s functional processes. This architectural change decouples storage from compute, making disaster recovery easier in case of the AlloyDB server container falling over. Note: this doesn't make AlloyDB Omni a serverless architecture precisely. We'll get into that in further blog posts!
For all intents and purposes, on the back end AlloyDB and PostgreSQL are architecturally similar or the same. This is a large part of why AlloyDB can claim such high compatibility with PostgreSQL and most PostgreSQL extensions. Compared to other PostgreSQL-compatible databases, AlloyDB Omni offers the greatest architectural similarity to open source PostgreSQL, and therefore provides the least vendor lock-in.
It’s important to note that AlloyDB Omni is closed source and distributed as a Docker image. This means that ultimately, as end consumers, none of us have full transparency into the architecture of AlloyDB Omni, and thus no one can make any concrete guarantees about compatibility beyond what Google’s documentation states.
AlloyDB Omni features
Aside from AlloyDB Omni’s significant memory management enhancements, it has two important features: enhanced ability to work with AI/ML workloads, and the ability to navigate columnar data and queries.
AI/ML workload features - vector, Vertex AI Models, and more
AlloyDB Omni’s main feature is its deep integrations for AI and ML workloads. This comes in two parts:
- The ability to directly call Vertex AI Models via SQL to manipulate your data without writing external scripts or code. Note that for users of Aiven for AlloyDB Omni users, you’ll need a Google Cloud account and a project key, even if you deploy your service on AWS or Azure.
- The
vectorextension is an AlloyDB specific extension which adds additional vector indices to AlloyDB. Notably, the SCaNN index provides a more efficient nearest neighbors index.
Columnar engine
The second main feature that AlloyDB Omni provides is the ability to create columnar indexes and run queries against your data in a columnar fashion. This is useful for analytics use cases and other queries that run against large data sets.
We talk quite a bit about columnar data and its benefits in regards to Aiven for ClickHouse, but committing to a fully columnar database is a big decision and not the right move for many businesses. The columnar engine in AlloyDB Omni is a great transition for anyone with existing Postgres databases who wants to explore whether columnar queries are more efficient for their use case.
Aiven for AlloyDB Omni or Aiven for PostgreSQL: which should you choose?
While it may seem that AlloyDB Omni offers everything PostgreSQL does and more, there’s a use case for both technologies in a modern data stack.
Aiven for AlloyDB Omni is best for those who…
- Have a well-scoped need for AI/ML integration with their database
- Are looking for a managed solution for AlloyDB Omni
- Are curious about working with columnar data and query processing, but not ready to commit to a fully columnar datastore like ClickHouse
Whereas Aiven for PostgreSQL is best for those who…
- Want the freedom, flexibility and data portability of a fully open source solution
- Want full access to the PostgreSQL extensions ecosystem and a full compatibility guarantee
- Are storing more traditional relational data such as customer records which are unsuitable for use with black box AI models.
In the end, it’s all about what you intend to do with your data, and how portable you need your data to be in future. If you need more information, we encourage you to book a demo for AlloyDB Omni and Postgres, and discuss with our sales team which technology benefits you the most.
About Aiven for AlloyDB Omni
Aiven for AlloyDB Omni is now available and is a fully managed AlloyDB Omni database deployable on Google Cloud, Amazon AWS and Microsoft Azure cloud platforms. It provides the benefits of an AlloyDB database, the stability of a managed service, and the flexibility to deploy to any major cloud provider. Sign up today to create your AlloyDB Omni instance.

Table of contents
- What makes PostgreSQL Postgres-y
- What is AlloyDB Omni?
- AlloyDB Omni and Postgres compatibility
- SQL standard compatibility
- AlloyDB Omni and PostgreSQL, architecturally speaking
- AlloyDB Omni features
- AI/ML workload features - vector, Vertex AI Models, and more
- Columnar engine
- Aiven for AlloyDB Omni or Aiven for PostgreSQL: which should you choose?
- About Aiven for AlloyDB Omni