Dec 21, 2017
PostgreSQL® Performance in AWS, GCP, Azure, DO and UpCloud
Want to know how PostgreSQL performs in different clouds, as well as best practices for benchmarking? Then be sure to check out our latest test results.

Oskari Saarenmaa
|RSS FeedChief Executive Officer at Aiven
I recently gave a talk about PostgreSQL performance in different clouds, under different settings at the pgconf.eu conference in Warsaw.
The talk compared the results of 3 benchmark tests for the just released PostgreSQL 10 running in five cloud infrastructures in two different regions:
- Amazon Web Services (eu-west-1 and eu-central-1)
- Google Cloud Platform (europe-west2 and europe-west3)
- Microsoft Azure (UK South and Germany Central)
- DigitalOcean (LON1 and FRA1)
- UpCloud (uk-lon1 and de-fra1)
We selected the specific regions because we were giving the talk a European conference and all of the vendors operate data centers in England and Germany.
Also, chose to run all benchmarks in two different regions to see if we would find noticeable differences in the different sites operated by these vendors.
The first benchmark was compared the following two different instance sizes on all clouds utilizing the network-backed freely scalable disks that are available in each cloud:
- 4 vCPU / 16GB RAM
- 16 vCPU / 64GB RAM
The second compared network and local SSD performance in AWS and GCP cloud infrastructures with the same instance sizes as the first.
For this post, we will be taking an in-depth look at the two benchmark tests while covering some important considerations when identifying and correcting PostgreSQL setups.
4 vCPU / 16 GB RAM network disks benchmark
Although it is impossible to get VMs with the exact same specifications in every cloud, we provisioned similar setups in all clouds:
-
Amazon Web Services
- m4.xlarge: 4 vCPU; 16 GB RAM
- 350 GB gp2 EBS volume, no provisioned IOPS
-
Google Cloud Platform
- n1-standard-4: 4 vCPU; 15 GB RAM
- 350 GB PD-SSD
-
Microsoft Azure
- Standard DS3 v2: 4 vCPU; 14 GB RAM
- 350 GB P20
-
DigitalOcean
- 16GB: 4 vCPU; 16 GB RAM
- 350 GB block storage
-
UpCloud
- 4CPUx16GB: 4 vCPU; 16 GB RAM
- 350 GB MAXIOPS
PostgreSQL 10.0 was running on top of Linux 4.3.15 kernel on each cloud. To replicate a typical production setup, the disks utilized LUKS full-disk encryption and WAL archiving was enabled to include the overhead of backups in the tests.
The test was performed using the venerable pgbench tool that comes bundled with PostgreSQL.
pgbench was run on another VM in the same cloud, running 16 clients for one hour with a data set roughly three times the amount of available memory, meaning that the data would not fit in cache and the impact of I/O is visible.
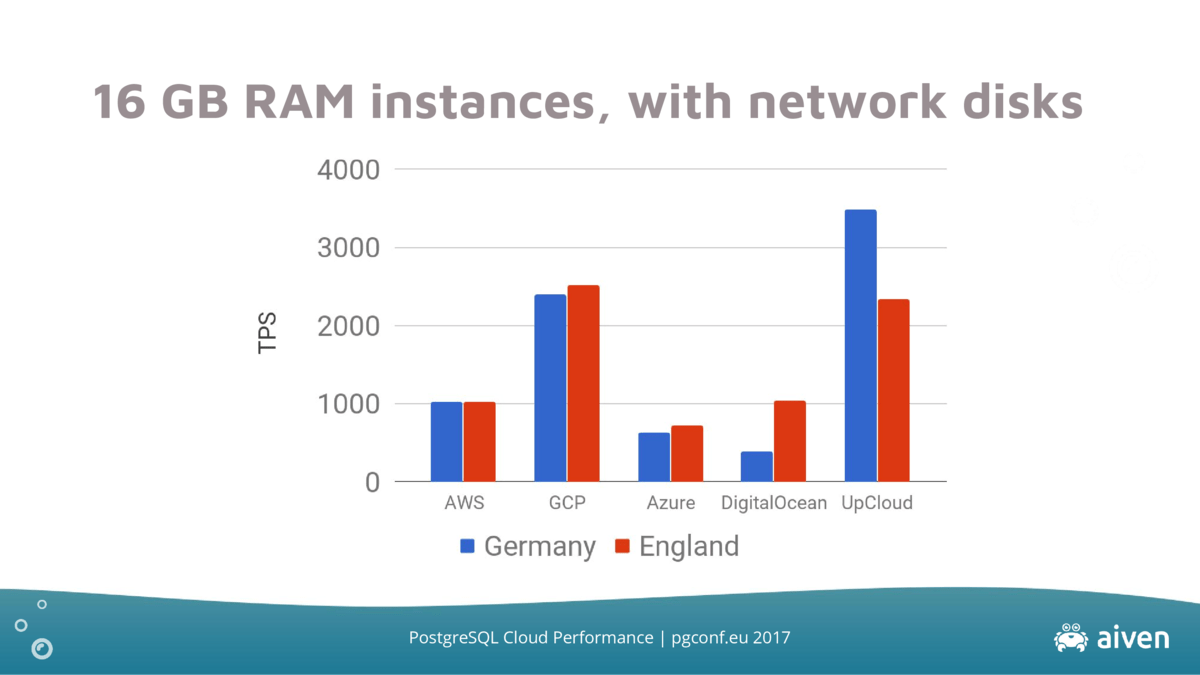
Google Cloud and UpCloud lead this benchmark showing that there's quite a bit of variation between the different cloud providers.
The performance of the big three providers are most stable across different regions while DigitalOcean and UpCloud show larger differences between different regions: the hardware or density of those regions may vary.
16 vCPU / 64 GB RAM / network disks benchmark
The test run was repeated on the 16x64 setup:
-
Amazon Web Services
- m4.4xlarge: 16 vCPU; 64 GB RAM
- 1 TB gp2 EBS volume, no provisioned IOPS
-
Google Cloud Platform
- n1-standard-16: 16 vCPU; 60 GB RAM
- 1 TB PD-SSD
-
Microsoft Azure
- Standard DS5 v2: 16 vCPU; 56 GB RAM
- 1 TB P30
-
DigitalOcean
- 64GB: 16 vCPU; 64 GB RAM
- 1 GB block storage
-
UpCloud
- Custom: 16 vCPU; 60 GB RAM
- 1 TB MAXIOPS
Again we used PostgreSQL 10.0, Linux 4.3.15 and pgbench for the benchmark, this time with 64 parallel clients on the pgbench host with a dataset three times the host ram.
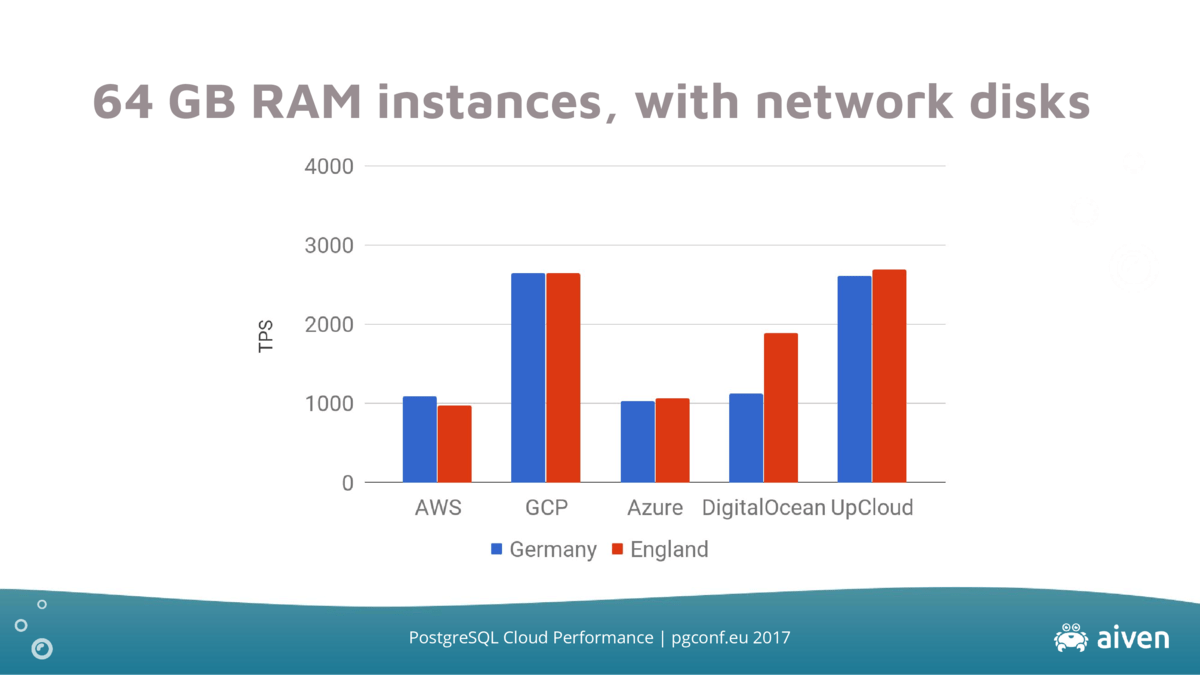
As with the prior setup, Google Cloud and UpCloud lead the pack with DigitalOcean's inter-region performance demonstrating widely different characteristics.
However, Amazon and Azure have a smaller performance gap and UpClouds inter-region performance gap is almost nonexistent.
Additionally, the actual transactions per second count hasn't increased much from the test run with the smaller instance types. This is mostly due to the size of the data set and the number of clients having increased.
General and cloud provider performance considerations
Data access latency has always been one of the most important factors in database performance and often is the most important single factor.
In broad terms, this means the larger the amount of your hot data that you can fit in your fastest data storage system the better.
Data is typically fetched from the following systems, listed below from fastest to slowest with each system typically being an order of magnitude slower than the preceding system:
CPU caches < RAM < Local disks < Network disks
All vendors use Intel Xeon CPUs of various types in their clouds and you can usually identify the type of CPU from the vendor's home page or simply by spawning a virtual machine and looking at /proc/cpuinfo.
Different hypervisors are used by different providers which may account for some differences, but most of the differences between these vendors are most likely in their IO subsystems.
AWS
AWS has a number of different volume types available in its Elastic Block Storage (EBS) ranging from large & cheap spinning rust to highly performant SSDs with provisioned IOPS.
The most common disk type for database workloads are probably the "general purpose" gp2, which was used in our tests, and the "provisioned iops" io1 type.
The general purpose disk works just fine for most use cases and provides guaranteed performance for a reasonable price based on the disk size ranging from 100 IOPS to 10k IOPS.
While you can get up to 32k IOPS with the provisioned IOPS volume type, it comes with a hefty price.
AWS also provides a number of instance types with fixed local storage ("instance storage") which we'll cover later.
Google Cloud (GCP)
GCP has two options for its scalable network storage: SSDs ("pd-ssd") and spinning ("standard").
The performance of Google Cloud's disks scale up automatically as volume size increases, i.e. the bigger the volume, the more bandwidth and IOPS you get.
GCP doesn't have provisioned IOPS disks at the moment, but the number of IOPS available by default usually exceeds what's available on Elastic Block Storage.
GCP allows attaching up to 8 local SSDs to most instance types, which we'll also cover later.
Microsoft Azure
Azure has a number of different options for network attached storage with default storage based on spinning disks that are affordable, but rather slow.
To utilize SSDs in Azure, you must switch from the standard "D" type instances to "DS" and select the layout of disks to use: disks come in fixed sizes ranging from 128 GB to 4 TB in size with each tier offering different IOPS and bandwidth.
We used the "P20" (512GB) and "P30" (1TB) disks in our benchmarks which currently appear to have the best performance per dollar spent of all Azure disks.
Azure also has a number of instance types with instance local storage, but we have not yet included them in our benchmarks.
DigitalOcean
DigitalOcean has simple options for VMs with a number of different VM sizes you can select which all come with a certain amount of vCPUs, RAM and local (SSD) disk. You can additionally attach a network disk ("block storage") of any size to the VM.
All DigitalOcean VMs have local disks, but they are too small to be usable in these benchmarks.
UpCloud
UpCloud has a proprietary storage system called MAXIOPS which is used for all disk resources. MAXIOPS allows attaching a number of disks up to 1TB each to a VM.
We believe MAXIOPS is based on SSD arrays connected using InfiniBand, but UpCloud has not given a detailed view to its storage technology so far.
UpCloud doesn't offer any VMs with local storage.
Considerations for running PostgreSQL on ephemeral disks
As mentioned, a number of the cloud infrastructure vendors offer instance storage with what we believe to be much faster (potentially an order of magnitude faster) than the default, network-attached storage, and we wanted to include them in our benchmarks.
It is important to note that we can't rely on instance storage for data durability because local disks are ephemeral and data on them will be lost in case the VM is shut down or crashes.
Therefore, other means must be used to ensure data durability across node failures. Luckily PostgreSQL comes with multiple approaches for this:
- Replication to a hot standby node
- Incremental backup of data as it's written (WAL streaming)
We utilized WAL streaming for backups in this benchmark: all data is streamed to a durable cloud storage system for recovery purposes as it's written.
16 GB RAM / local vs. network disks benchmark
Just as we couldn't with the network disk test, we were unable to provision VMs with identical specifications from the selected cloud infrastructure providers.
Specifically, AWS has a limited set of instance types with local disks unlike Google, which allows for attaching local disks to most types. The following VM configuration was used in this test run:
-
Amazon Web Services
- i3.large: 2 vCPU; 15 GB RAM
- 350 GB NVMe disk (max 475 GB)
-
Google Cloud Platform
- n1-standard-4: 4 vCPU; 15 GB RAM
- 350 GB NVMe disk (max 3 TB)
Again, we used PostgreSQL 10.0, Linux 4.3.15 and pgbench for the benchmark, this time with 16 parallel clients on the pgbench host with a dataset three times the host ram.
The following graph compares the performance of PostgreSQL 10 running in AWS and GCP with local and network disks:
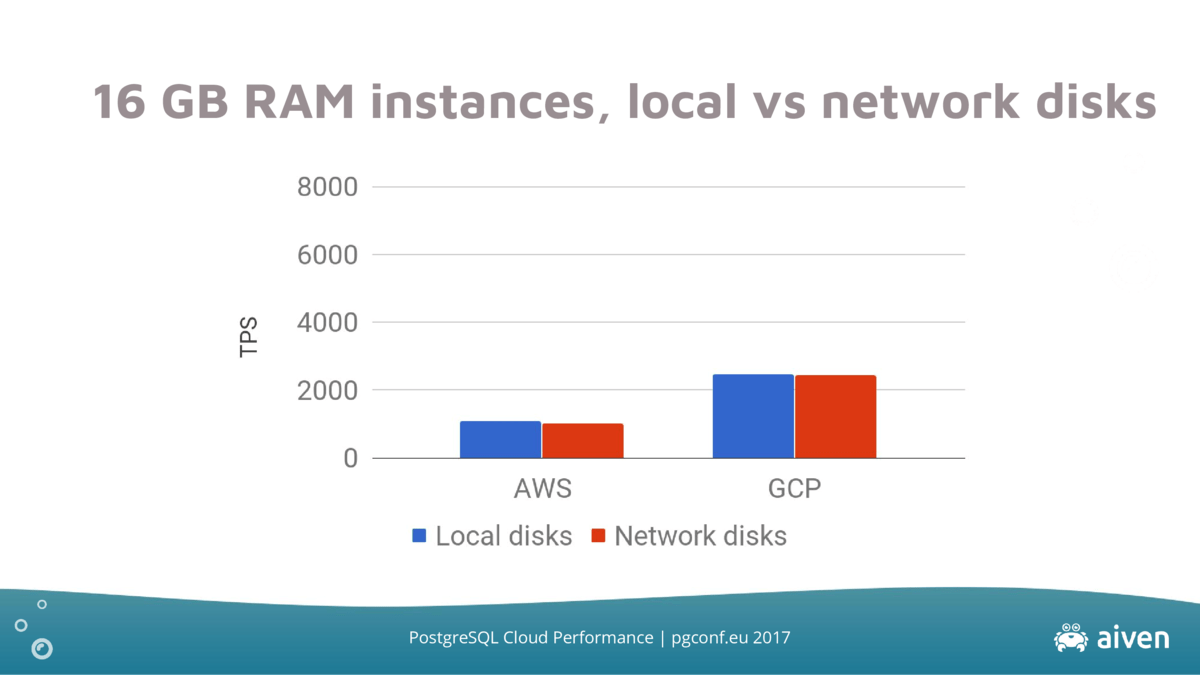
We were a bit surprised by the lack of differences between local and network disks. Apparently, the bottleneck is not in disk IO in this case.
64 GB RAM / local vs. network disks benchmark
We repeated the local disk benchmark with 64 GB instances configured as follows:
-
Amazon Web Services
- i3.2large: 8 vCPU; 61 GB RAM
- 1 TB NVMe disk (max 1.9 TB)
-
Google Cloud Platform
- n1-standard-16: 16 vCPU; 60 GB RAM
- 1 TB NVMe disk (max 3 TB)
Again we used PostgreSQL 10.0, Linux 4.3.15 and pgbench for the benchmark, this time with 64 parallel clients on the pgbench host with a dataset three times the host ram.
The following graph compares the performance of PostgreSQL 10 running in AWS and GCP with local and network disks:

The results speak for themselves: the local NVMe-backed instances blow away the network-backed instances.
Summary
A great many factors affect PostgreSQL performance and each production workload is different from the other, and most importantly, different than the workloads used in these benchmarks.
Our advice is to try to identify the bottlenecks in performance and tune the database configuration, workload or (virtual) hardware configuration to match the requirements.
In a cloud PostgreSQL-as-a-Service system such as ours, the PostgreSQL system parameters are typically automatically configured to match typical workloads and it's easy to try out different virtual hardware configurations.
If you decide to roll your own PostgreSQL setup, be sure to pay special attention to backups and data durability when using local disks.
Next steps
My conference slides are available in our GitHub repository and they include a set of benchmarks on different AWS PostgreSQL-as-a-Service platforms (Aiven, RDS and AWS Aurora) comparing performance of Aiven PostgreSQL backed by NVMe SSDs to RDS PosgreSQL on EBS volumes and AWS Aurora with a proprietary backend.
We will be publishing more benchmarks at regular intervals in the future comparing different workloads and infrastructure setups. We'll also include more database-as-a-service providers in our regular benchmarks, so stay tuned!
Launch the top-performing PostgreSQL service in minutes
As detailed in a previous blog post, PostgreSQL 10 with local disks is now available for all Aiven users. Please sign up for our free trial and have your top-performing PostgreSQL instance available for use in minutes.

Table of contents
- 4 vCPU / 16 GB RAM network disks benchmark
- 16 vCPU / 64 GB RAM / network disks benchmark
- General and cloud provider performance considerations
- 16 GB RAM / local vs. network disks benchmark
- 64 GB RAM / local vs. network disks benchmark
- Summary
- Next steps
- Launch the top-performing PostgreSQL service in minutes
Stay updated with Aiven
Subscribe for the latest news and insights on open source, Aiven offerings, and more.
![That's no game. [image: hand flying a paper airplane across a field of circles suggestive of planets]](https://cdn.sanity.io/images/sczeoy4w/production/d87a689961ac59cebd1d8245b24c2fb04e6c9ec8-2500x1308.png?q=80&fit=max&auto=format&dpr=1.5)
![Aiven for PostgreSQL® 13 performance on GCP, AWS and Azure [Benchmark] illustration](https://cdn.sanity.io/images/sczeoy4w/production/3eb1b1efb1b5f0343cbbd0a0668ed0af38005b02-1567x844.png?q=80&fit=max&auto=format&dpr=1.5)
