


In our previous post What is Apache Kafka®?, we introduced Apache Kafka, where we examined the rationale behind the pub-sub subscription model. In another, we examined some scenarios where loosely coupled components, like some of those in a microservices architecture (MSA), could be well served with the asynchronous communication that Apache Kafka provides.
Apache Kafka is a distributed, partitioned, replicated commit log service. It provides all of the functionality of a messaging system, with a distinctive design.
In this blog, we’ll look at the Pub/Sub model and examine why it’s an excellent choice for asynchronous communication and loose coupling of components. Then, we’ll set up an Aiven Kafka instance, implement a producer and a consumer, and finally run it all together.
The Pub/Sub model - producers and consumers
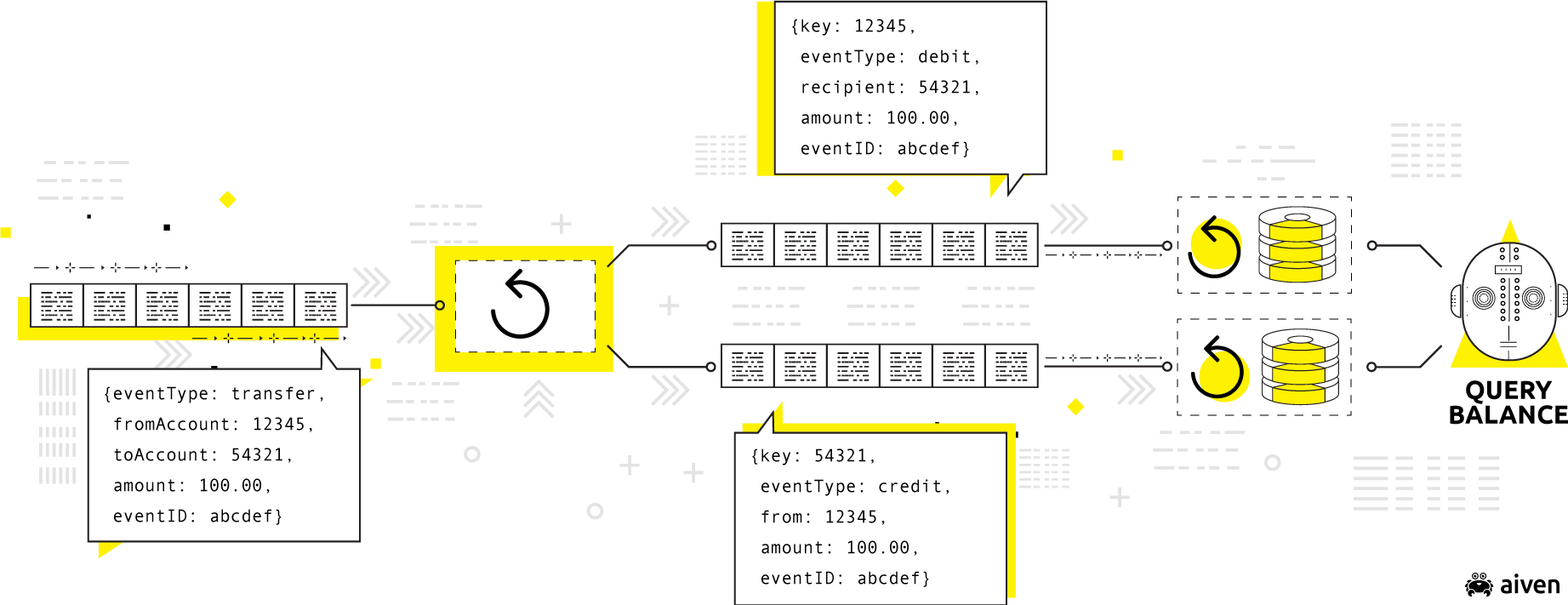
Source: Martin Kleppmann's Kafka Summit 2018 Presentation, Is Kafka a Database?
As noted previously, Apache Kafka passes messages via a publish-subscribe model where software components called producers append events to distributed logs called topics, which are essentially named, append-only data feeds.
Consumers, on the other hand, consume data from these topics by offset (the record number in the topic). When consumers get to decide what they will consume, it is less complicated than it would be with producer-based routing rules.
In other words, the producer simply appends messages to the topic, and the consumer decides, by offset, which messages to consume from the topic!
The producer/consumer or pub-sub model serves communication models, e.g. those within MSAs, particularly well when loose coupling between components and asynchronous communication is required. Why?
Because there is no time- or task- dependency between when the producer creates and sends a message and the consumer receives and/or acts on it. In other words, the producer produces messages in its own time — and at its own pace — and the consumer does the same, without worrying about synchronization locks.
Our demo, which we’ll walk through in the following sections, illustrates this.
Setting up your Aiven Kafka instance
We’ll start by spinning up an Aiven Kafka service in the cloud. In Aiven’s Services pane, simply create a new Kafka service instance as shown below:
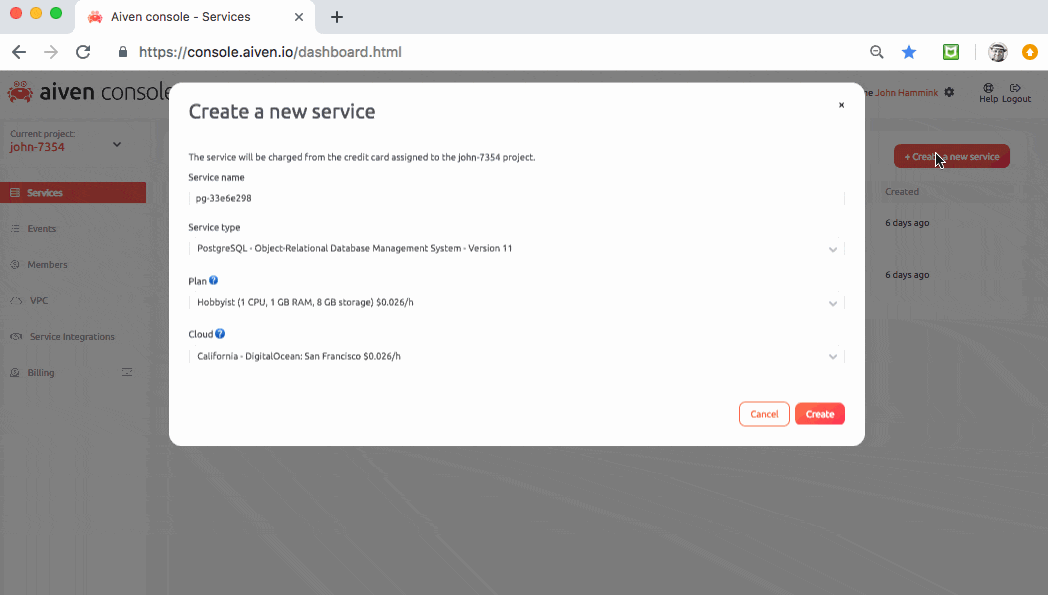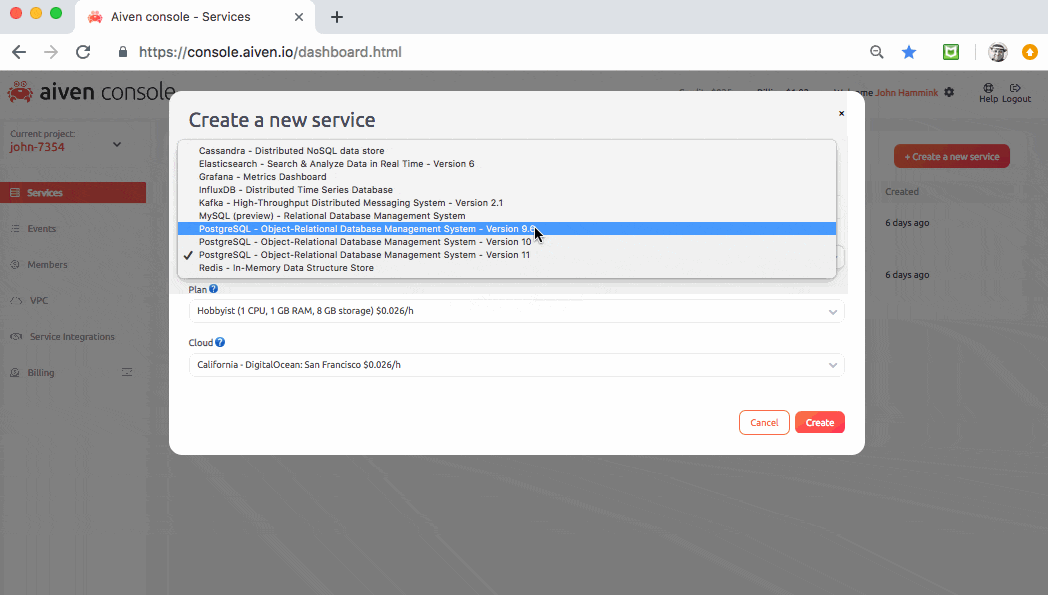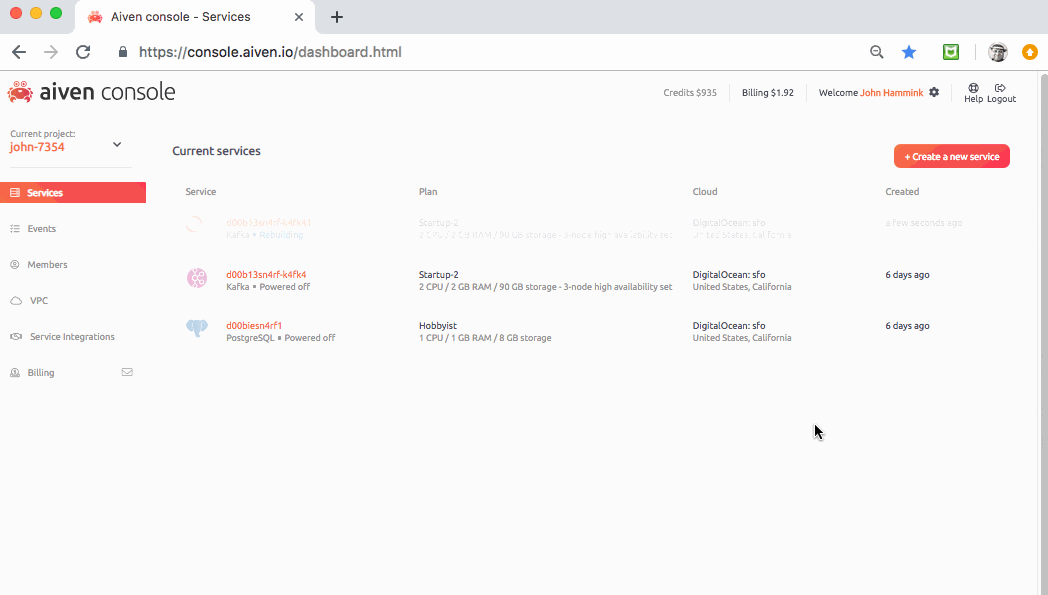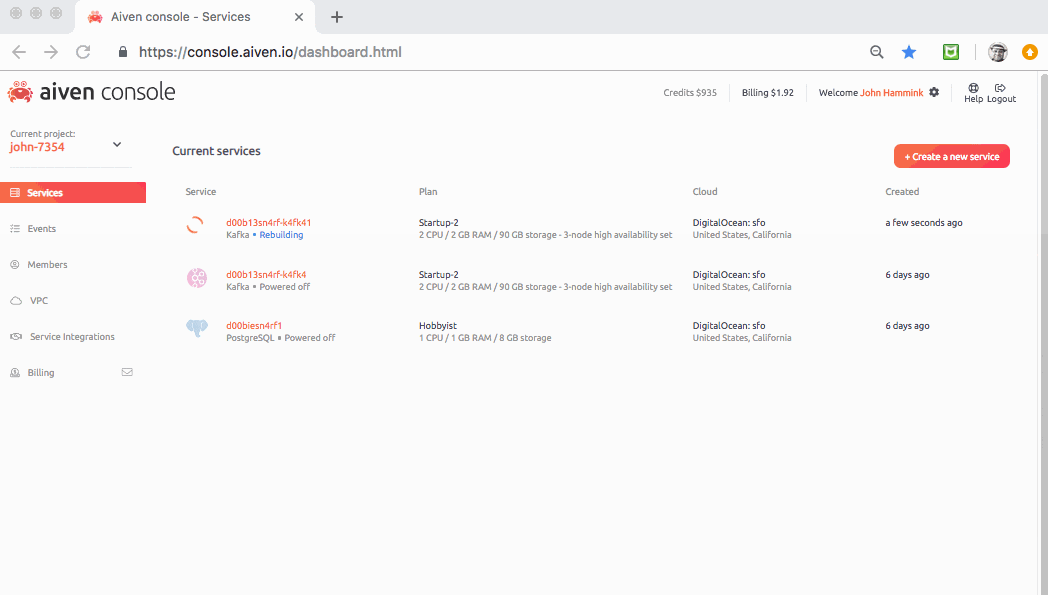
From the Connection parameters section within the Kafka service’s overview pane, copy the URL (you’ll reference it in your producer and consumer code later on).
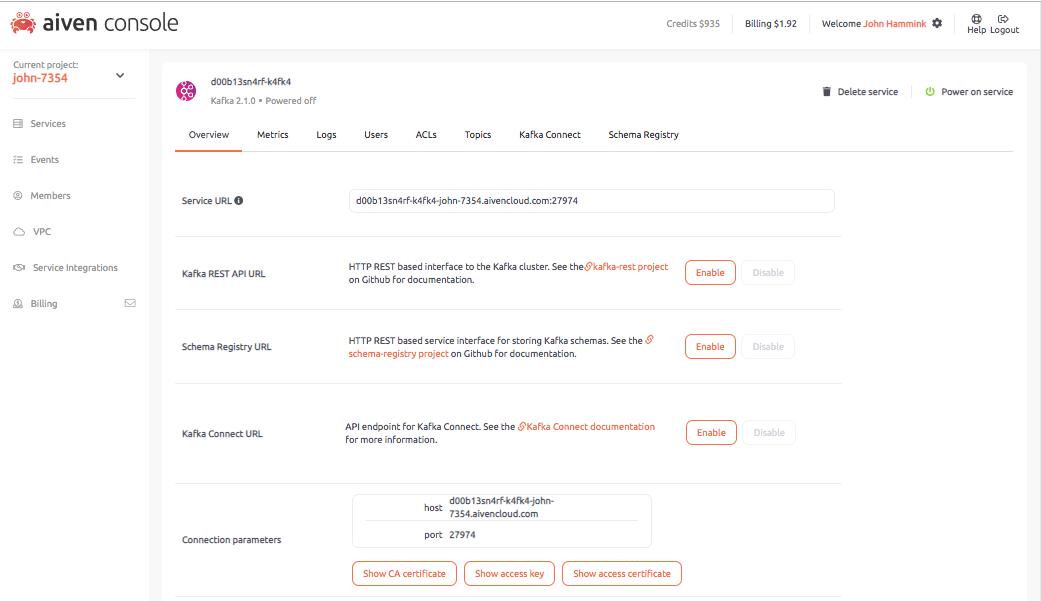
Also, generate the following files and copy them to the local directory where your producer and consumer files will be created:
ca.pemservice.certservice.key
Finally, from the Kafka service’s Topics tab, generate a topic called demo-topic. This is the topic you’ll be writing to:
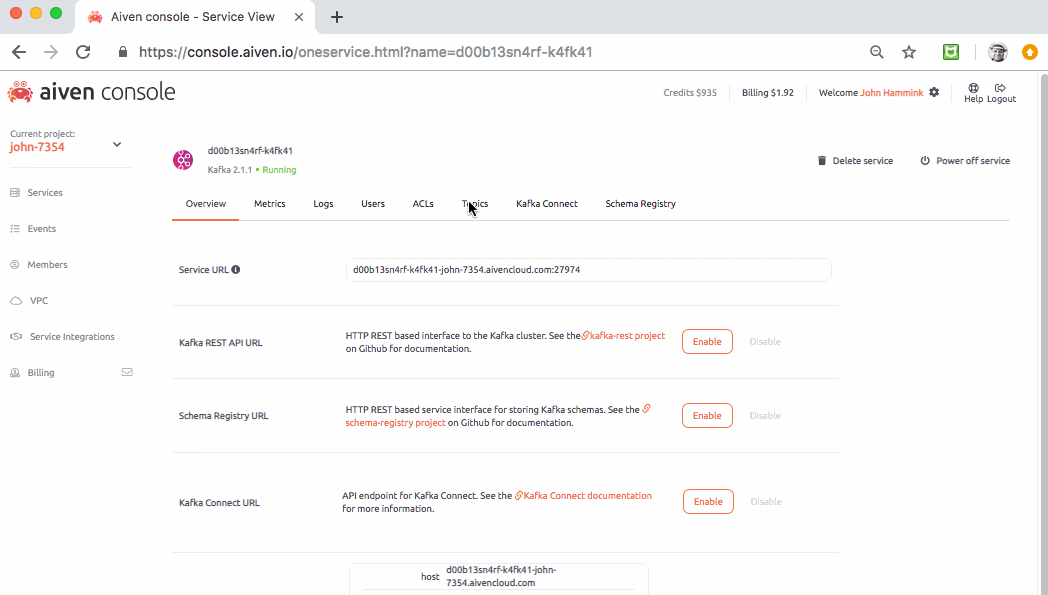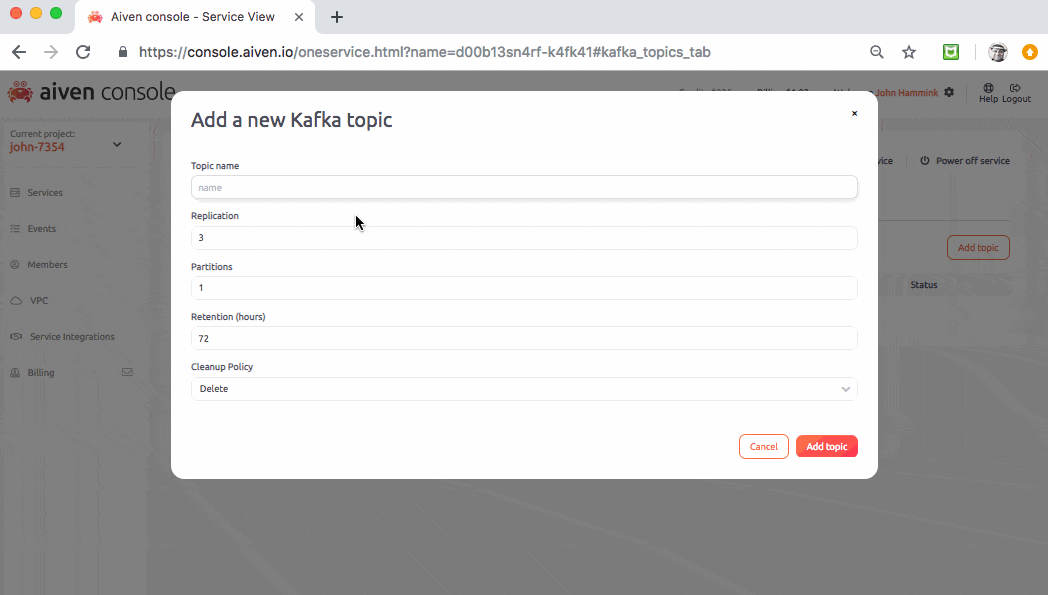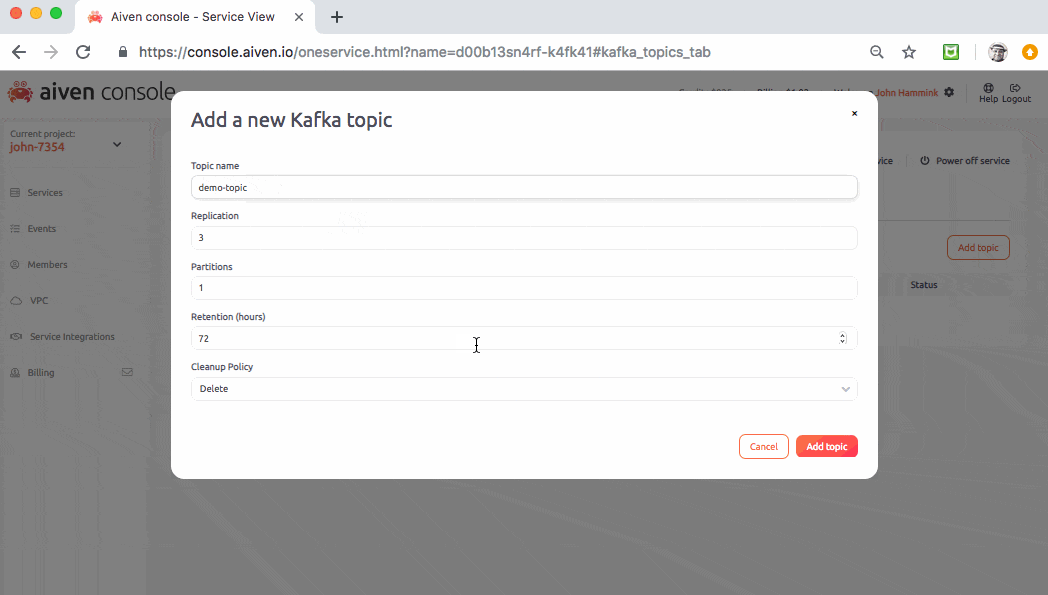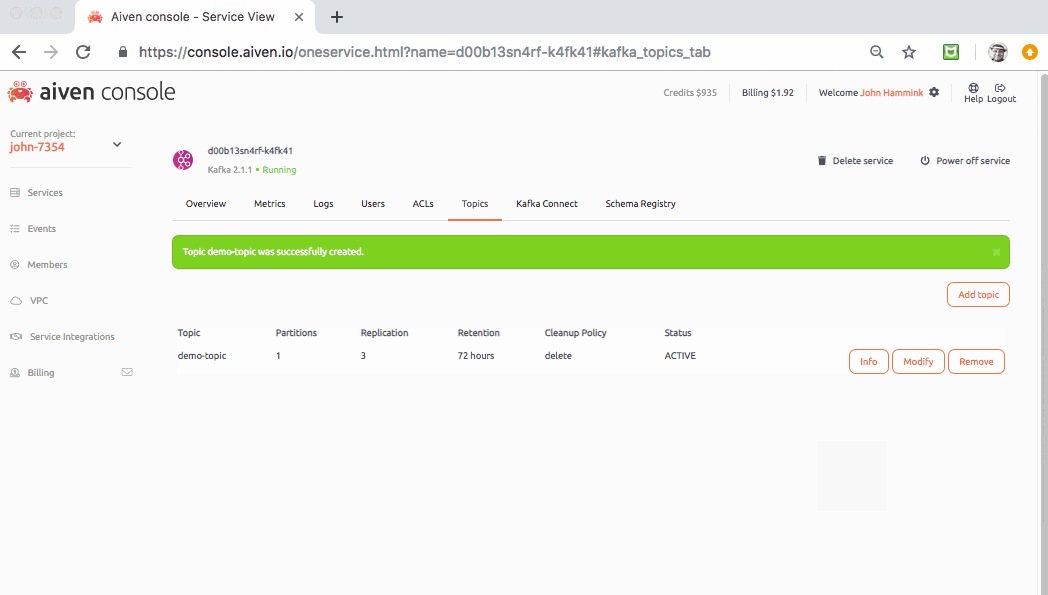
Introducing the ibeacon
The ibeacon is a hardware transmitter and a protocol developed by Apple and introduced at the WWDC in 2013. Additional vendors have followed up with beacon systems of their own, following the same protocol. The technology allows other devices such as smartphones, tablets and other devices do certain things when in specified proximity to a given beacon.
These include actions like determining a device's (and customer’s) physical location, tracking customers, sending targeted ads to customer devices based on where in the retail space the customers are located, and so on. The ibeacon protocol and methods are similar, in function, to those derived from GPS, but more accurate to smaller locations and less battery-intensive.
For our purposes, we’ll be simulating an ibeacon that sends events with the following fields:
-
uuid: universally unique identifier for a specific beacon. Ours are 27 chars in length. -
Major: value assigned to a specific ibeacon to incrementally fine-tune identification beyonduuid.Majorcorresponds to a specific group of beacons, for example, those located in a specific department or floor.
Major values are unsigned integers between 0 and 65535
-
Measured power: this is a factory-calibrated, read-only constant which indicates what the expected RSSI is at a distance of one meter to the beacon. -
rssi: stands for Received Signal Strength Indicator, and indicates the beacon’s signal strength from the point of view of the receiver, for example, customer’s tablet. Combined with measured power, these two settings let you estimate the distance between the device and the beacon. -
accuracy: some ibeacon devices also calculate a string for signal accuracy. -
proximity: ‘Near’, ‘Immediate’, ‘Far’, and ‘Distant’.
For demo purposes, we’ve made some shortcuts. As we’ve configured it, our producer will produce the events at a pace that’s faster than the consumer consumes them. This is actually OK, as we want to illustrate how Kafka provides some temporary persistence for stored messages that have not yet been delivered.
Setting up your producer
The code below should get you started: go here to view the whole code block.
Loading code...
This code simulates an ibeacon - it sets up and calculates the kind of fields that your ibeacon is likely to send, packs the fields into a message, and sends the message along as a Kafka producer message. For the sake of simplicity, we’ve avoided JSON handling for now. Rinse, lather, repeat.
We’ve added a short sleep between message iterations so that you can actually see the messages go by on the console as they are produced.
Setting up your consumer
The code below should get you started: go here to view the whole code block.
Loading code...
Running it all together
Open two command prompts, set to your current directory.
- In one, enter: $$ python ibeacon_producer.py 500000`
In fact, you can set the tail value to anything you want, but setting it to a higher value simply ensures that the producer will run continuously, and the consumer, to be run on the next step, doesn’t immediately time out.
- In the second command prompt, enter: $$ python ibeacon_consumer.py`
Now you should have the producer and consumer running side by side, as follows:
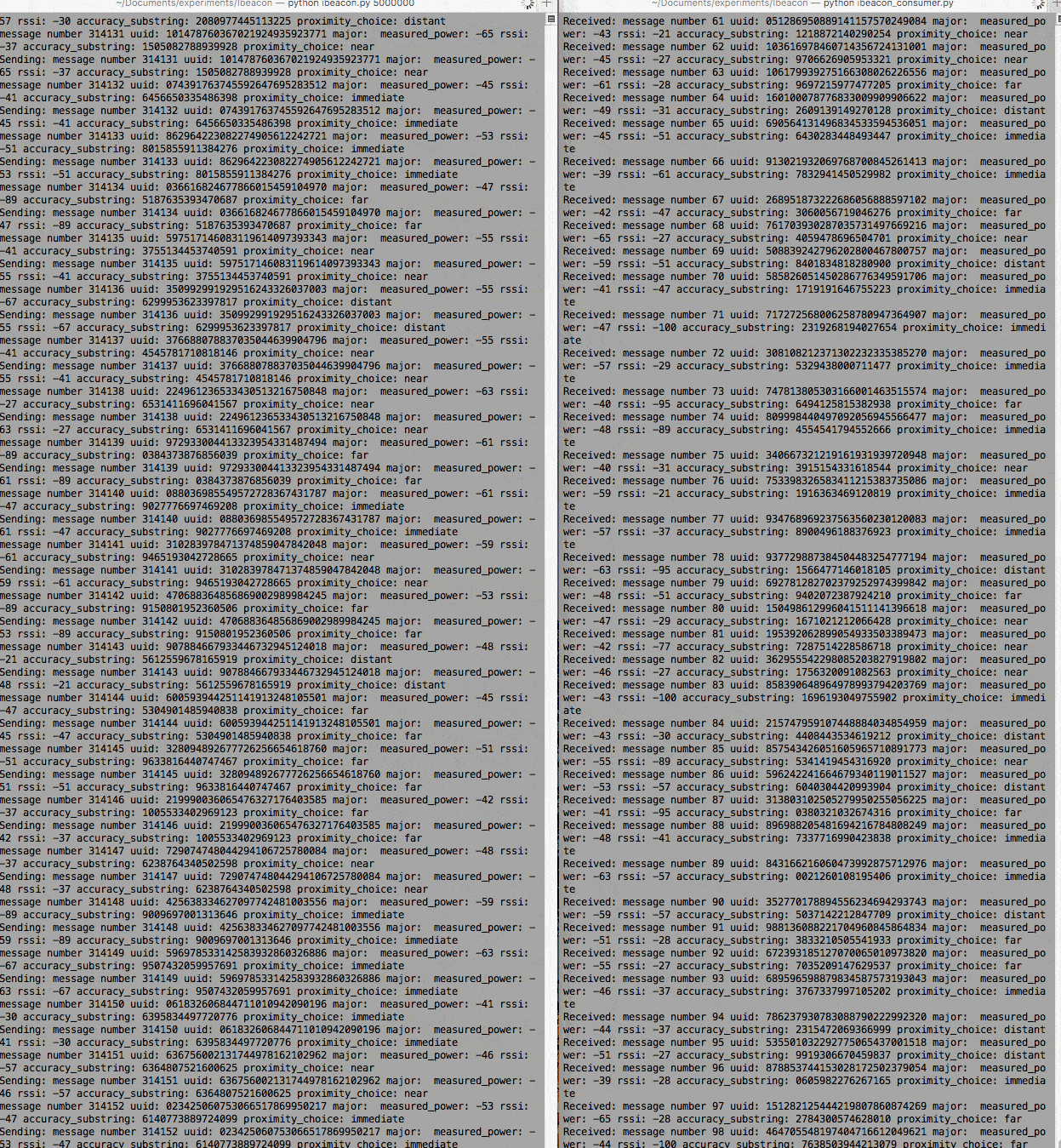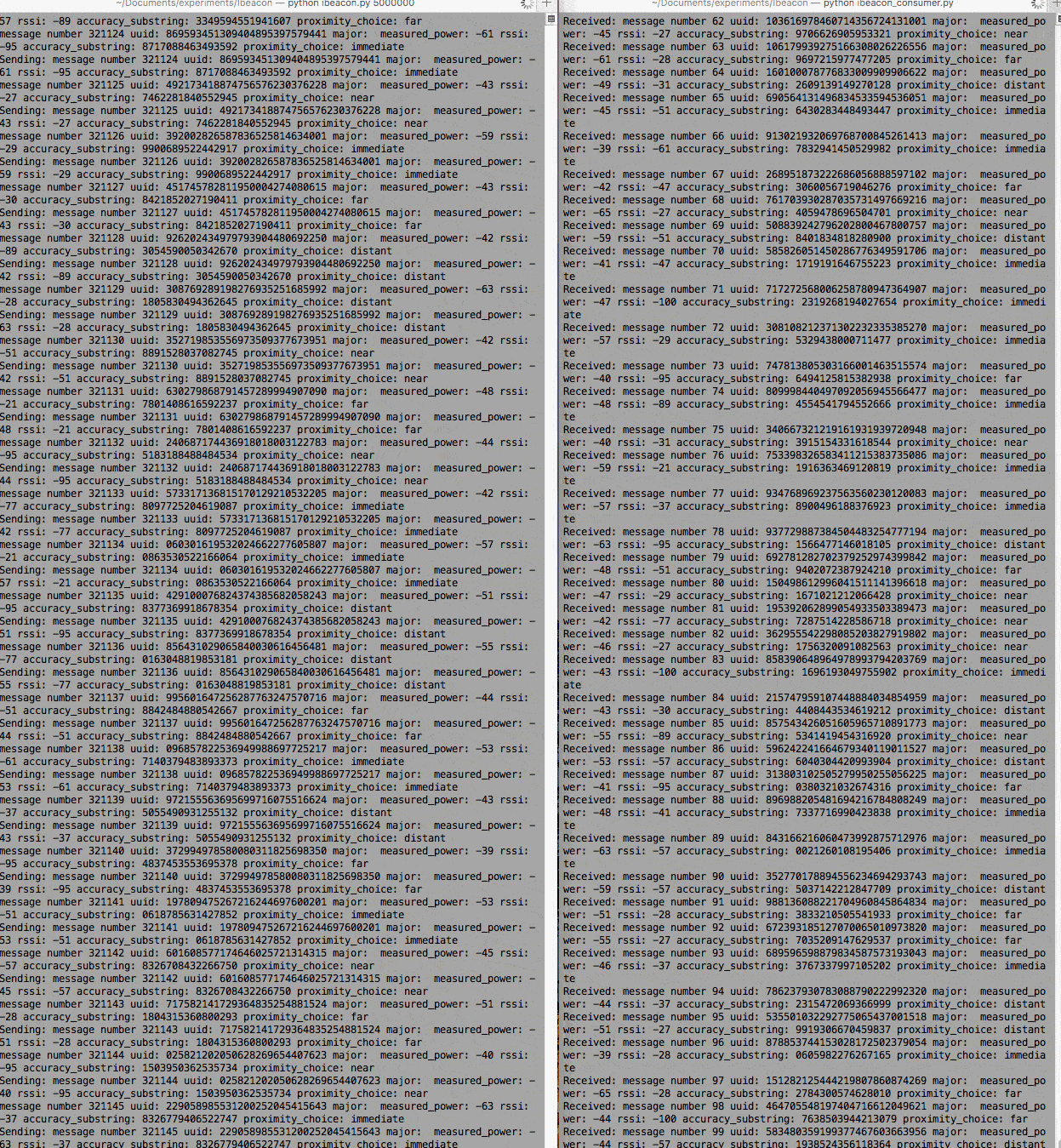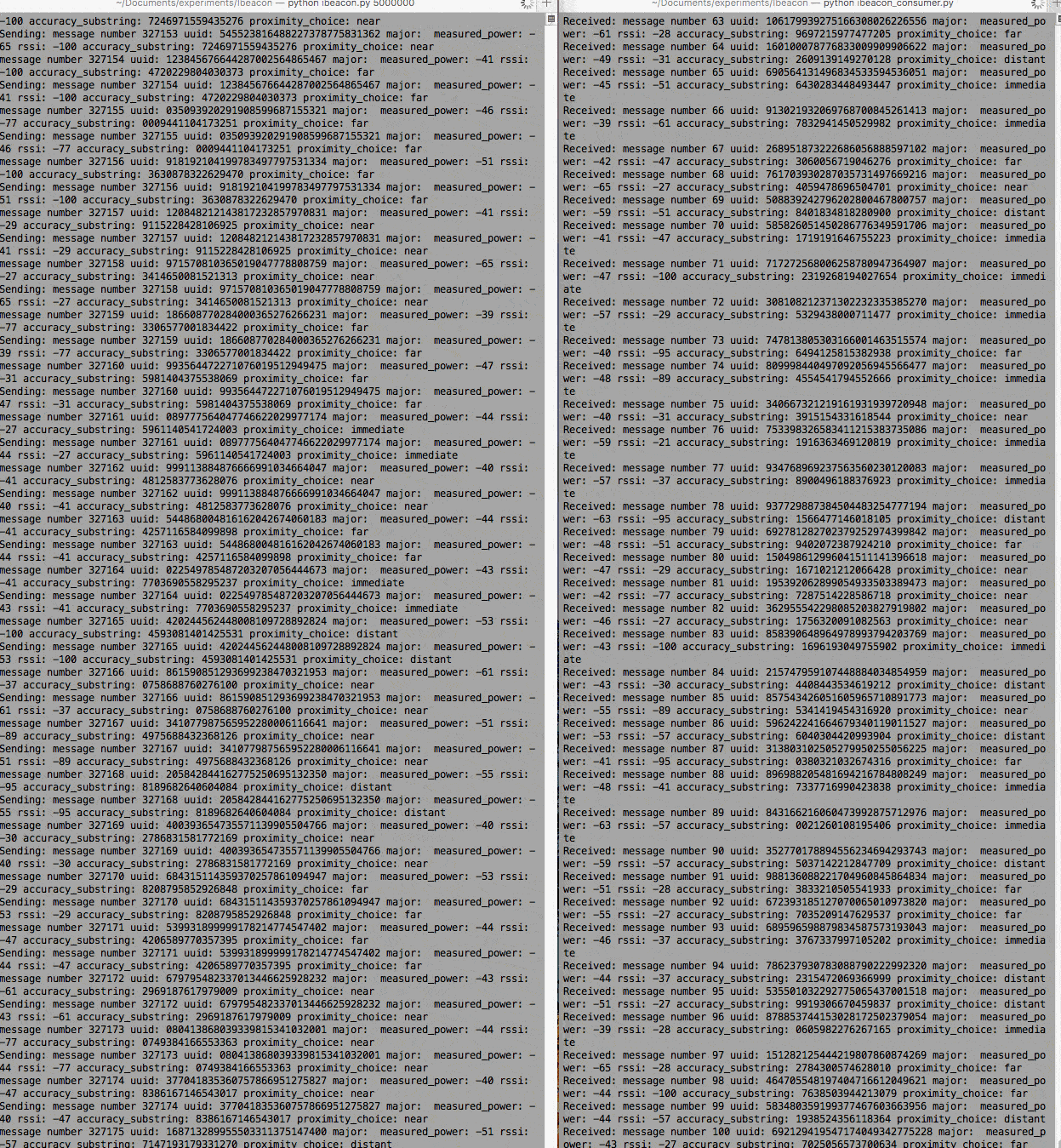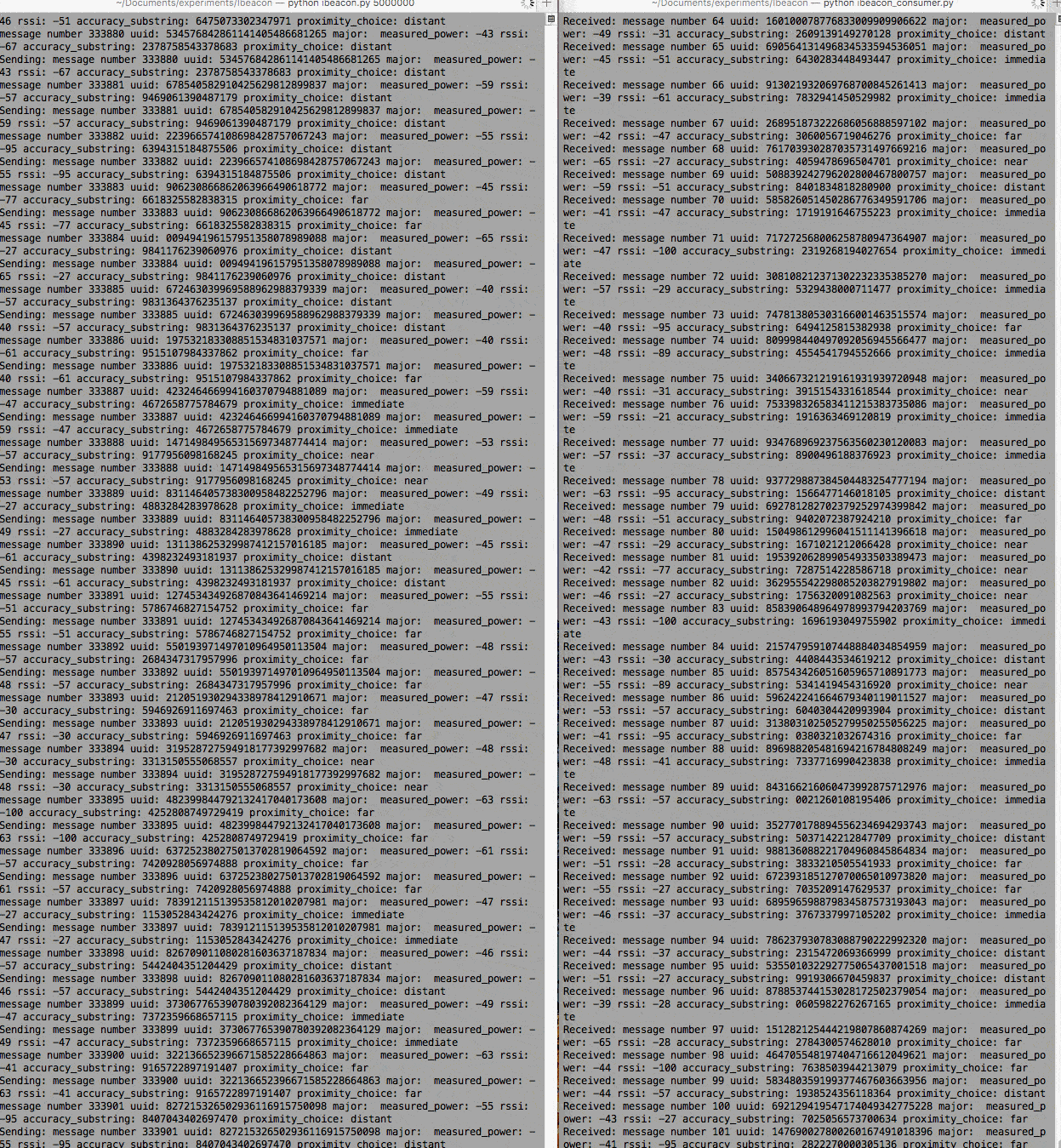
In this example, we have the producer writing to the log faster than the consumer is reading it (it’s built into the scripts, also). This was done so intentionally, using sleep commands in each, to illustrate that the consumer need not be tightly coupled to the producer and can consume events — the ones it chooses — at its own pace.
Wrapping up
We’ve reviewed the producer-consumer (or pub/sub) communication model and looked at why it may be quite useful for systems that require asynchronous communication between components.
Then, we’ve set up an Aiven Kafka Instance, implemented a producer and a consumer, and then run the lot together. Our consumer ingests messages slower than our producer writes them, thus demonstrating how Kafka can serve as a temporary persistence store for messages that have yet to be read.
We’ve also demonstrated how easy Aiven Kafka is to set up and use. Aiven Kafka is a fully-managed, high-throughput messaging system with built-in monitoring, enabling you to decouple your services, simplify your development and focus on development.
By choosing Aiven to manage and host your cloud Kafka clusters, you get the benefits of Kafka without the risk and opportunity costs associated with it. There’s no risk with our 30-day trial. Try us out or contact us today!
