Connecting Apache Kafka® and Aiven for ClickHouse®
Learn how to perform analytics with fast response time over huge volumes of data without the need to downsample data.
Learn how to perform analytics with fast response time over huge volumes of data without the need to downsample data.
Apache Kafka® and ClickHouse® are quite different, but also have a lot in common. They are both open source, highly scalable, work best with immutable data and allow us to process big loads of data, but they do all of this in quite different ways. That’s why instead of competing, these technologies actually complement each other quite well.
Apache Kafka is amazing at handling real-time data feeds. However, in certain cases we need to come back to older records to analyse and process data at later times. This is challenging because Apache Kafka, a streaming platform, is not optimised to access large chunks of data and act as an OLAP (online analytical processing) engine.
ClickHouse, on the other hand, is a scalable and reliable storage solution designed to handle petabytes of data and, at the same time, a powerful tool for fast online analytical processing, used by many companies for their data analytics.
By combining both technologies we get a performant data warehouse in ClickHouse, that stays up-to-date by constantly getting fresh data from Apache Kafka.
You can think of Apache Kafka topics as rivers where real-time data flows. ClickHouse, on the other hand, is the sea where all data eventually goes.
With that, time to roll up our sleeves and try integrating these two data solutions in practice. Below step by step we'll create the services, integrate them and run some query experiments.
To simplify the setup we'll be using managed versions of Apache Kafka and ClickHouse, both run by Aiven. If you don't have an Aiven account yet, no worries, registration is just a step away, and you can use a free trial for this experiment.
You can create Aiven for ClickHouse and Aiven for Apache Kafka services directly from Aiven's console. In the examples below I'm using apache-kafka-service and clickhouse-service as names for these services, but you can be more creative ;)
Note, that Aiven for ClickHouse needs at least a startup plan to allow adding integrations.
Once you've created the services, wait until they are completely deployed and are in RUNNING state. Now you're ready for action!
In order to move data from Apache Kafka to ClickHouse we need to have some data in Apache Kafka in the first place. So we start by creating a topic in Apache Kafka. You can do it directly from the Aiven console. Name it measurements. Here we'll send continuous measurements for our imaginary set of devices.
To imitate a continuous flow of new data we'll use a short bash script. In this script we create a JSON object with three properties: the timestamp of the event, the id of the device and a value. Then we send this object into the topic measurements using kcat. To understand how to set up kcat, check this article.
Loading code...
Start the script and leave it running, it'll be continuously creating and sending messages to the topic.
Our work on the Apache Kafka side is done. Now let's move to ClickHouse.
You can actually integrate your Aiven for ClickHouse service with any Apache Kafka service, but for us, having two services within the same Aiven project makes the integration straightforward.
To integrate Aiven for ClickHouse with Apache Kafka we need to do two steps:
We'll do these steps with help from the Aiven CLI.
First, establish the connection by creating an integration of type clickhouse_kafka and specifying the name of your services, Apache Kafka as source and ClickHouse as destination:
Loading code...
Running this command won't return you anything (unless there is a problem). But if you now check the list of available databases in your Aiven for ClickHouse service (with the help of Aiven's console, for example), you'll notice a new one - service_apache-kafka-service. The name of the created database is the combination of service_ and your Apache Kafka service name.
The database is still empty, because we didn't specify yet what kind of data we want to bring from our Apache Kafka service. We can define the datasource in a JSON payload, but first we need to find the id of our integration. You can get it by running this command:
Loading code...
In my case, the integration id was 88546a37-5a8a-4c0c-8bd7-80960e3adab0. Yours will be a different UUID.
Knowing the integration id we can set the proper configuration for our connection where we specify that:
measurementsJSONEachRow)timestamp, device_id and value:Loading code...
ClickHouse will track what messages from the topic are consumed using the consumer group that you specify in the group_name field, no extra effort needed on your side. By default, you'll read each entry once. If you want to get your data twice, you can create a copy of the table with another group name.
The setup we did is already sufficient to start reading data from the Apache Kafka topic from within ClickHouse.
The most convenient way to run ClickHouse SQL commands is by using clickhouse-client. If you're unsure how to run it, check Connect to a ClickHouse® cluster with CLI.
I, for example, used docker and ran the client by using the command below. Just replace USERNAME, PASSWORD, HOST and PORT with your values.
Loading code...
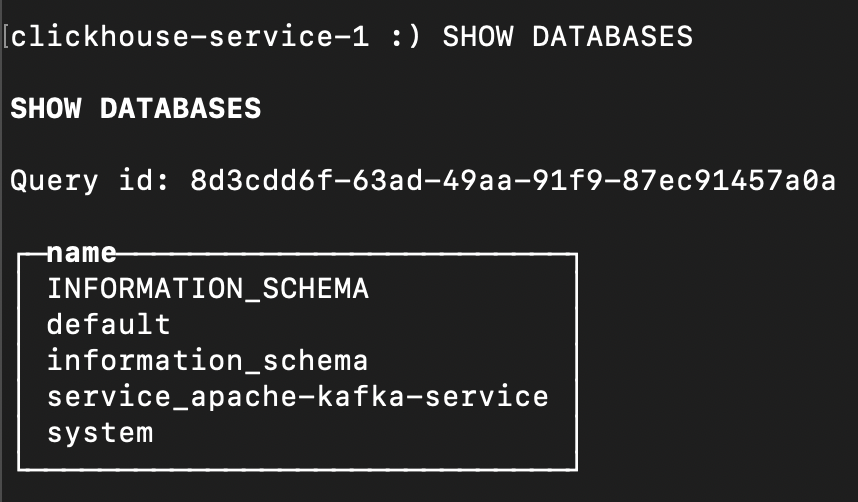
Once in the client, you can check the list of databases
Loading code...
You'll see the one we created by establishing the integration service_apache-kafka-service (maybe you named it differently!).
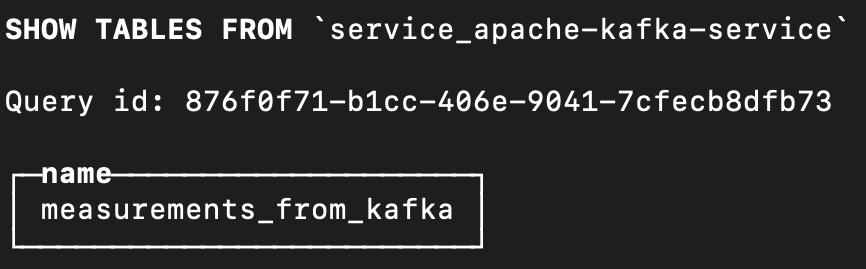
If you get the list of tables from this database, you'll see the name of the table that you specified in the integration settings.
Loading code...
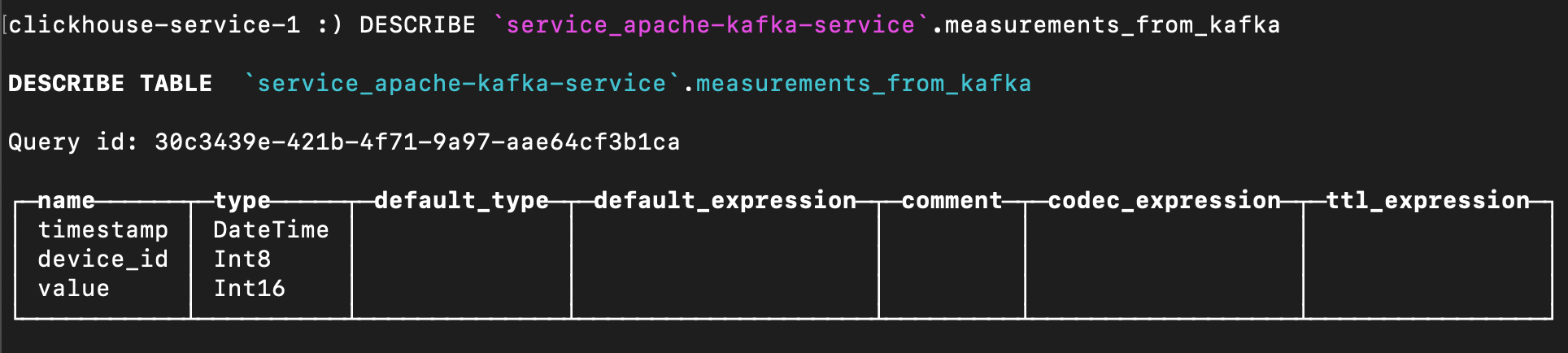
You can also double-check its structure with
Loading code...
Now, you might want to read from this table directly, and it will work. However, remember that we can consume messages only once! So once you read the items, they will be gone. Still, nothing stops you from running the following commands:
Loading code...
Loading code...
However, this is not the most convenient way of consuming the data from Apache Kafka, and apart from debugging won't be used much. Most probably you want to copy and keep the data items in ClickHouse for later. And this is exactly what we'll do in the next section.
To store the data coming from Apache Kafka to ClickHouse we need two pieces:
measurements_from_kafka) and our destination table.You can create them with these two queries:
Loading code...
Loading code...
When we create a materialised view, a trigger is actually added behind the scenes. This trigger will react to any new data items added to our table measurements_from_kafka. Once triggered, the data will go through the materialised view (where you also can transform it if you want) into the table device_measurements
You can check that the data is flowing by running:
Loading code...
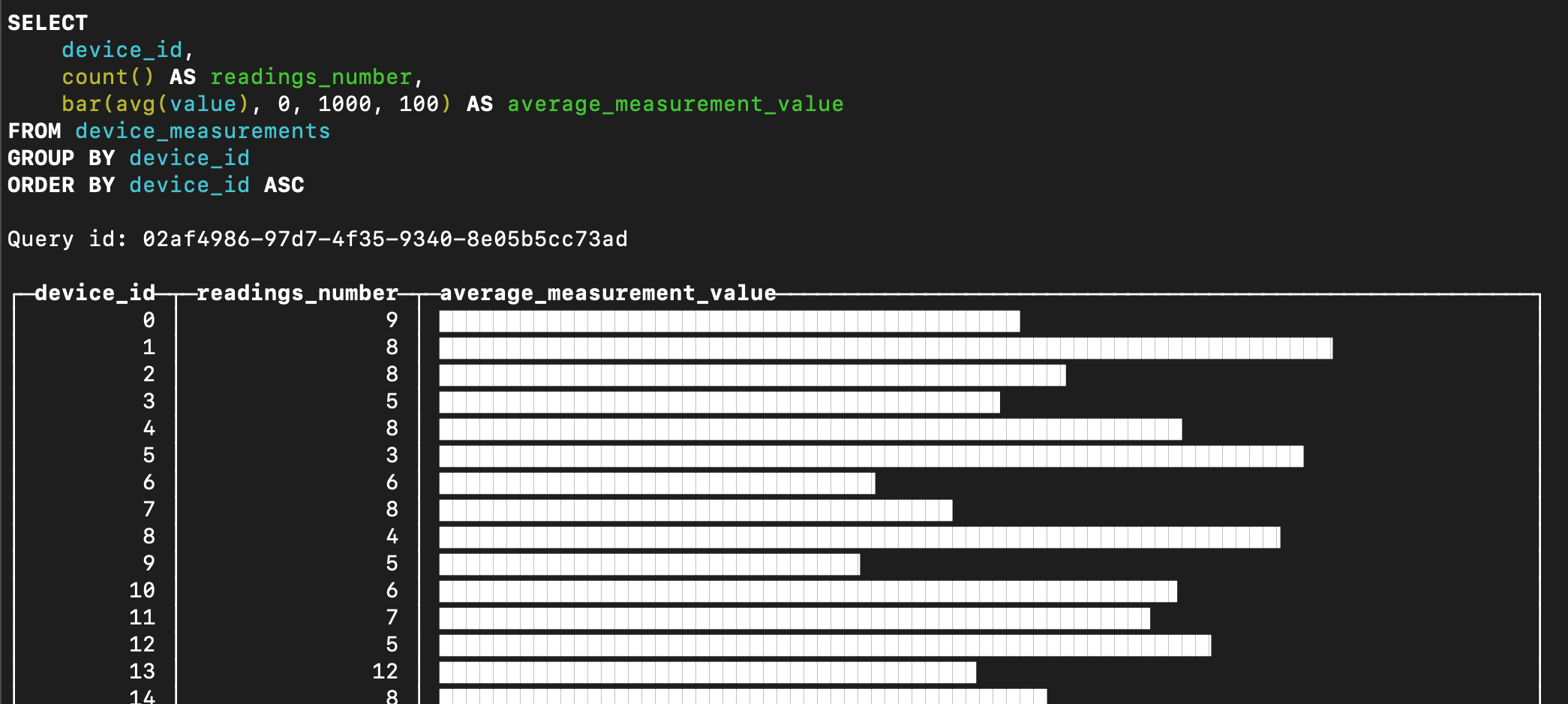
We can run a query to count all readings from the devices and see which devices have higher values on average. Here we use a nice and simple visualisation mechanism with the bar function.
Loading code...
Now you are equipped with the skill to bring data into Aiven for ClickHouse and use materialised views to store the data. Here are some more materials you might be interested to read:
#!/bin/bash
while :
do
stamp=$(date +%s)
id=$((RANDOM%100))
val=$((RANDOM%1000))
echo "{\"timestamp\":$stamp,\"device_id\":$id,\"value\":$val}" \
| kcat -F kcat.config -P -t measurements
doneavn service integration-create \
--integration-type clickhouse_kafka \
--source-service apache-kafka-service \
--dest-service clickhouse-serviceavn service integration-list clickhouse-service | grep apache-kafka-service avn service integration-update 88546a37-5a8a-4c0c-8bd7-80960e3adab0 \
--user-config-json '{
"tables": [
{
"name": "measurements_from_kafka",
"columns": [
{"name": "timestamp", "type": "DateTime"},
{"name": "device_id", "type": "Int8"},
{"name": "value", "type": "Int16"}
],
"topics": [{"name": "measurements"}],
"data_format": "JSONEachRow",
"group_name": "measurements_from_kafka_consumer"
}
]
}'docker run -it \
--rm clickhouse/clickhouse-client \
--user USERNAME \
--password PASSWORD \
--host HOST \
--port PORT \
--secureSHOW DATABASESSHOW TABLES FROM `service_apache-kafka-service`DESCRIBE `service_apache-kafka-service`.measurements_from_kafkaSELECT * FROM `service_apache-kafka-service`.measurements_from_kafka LIMIT 100SELECT count(*) FROM `service_apache-kafka-service`.measurements_from_kafkaCREATE TABLE device_measurements (timestamp DateTime, device_id Int8, value Int16)
ENGINE = ReplicatedMergeTree()
ORDER BY timestamp;CREATE MATERIALIZED VIEW materialised_view TO device_measurements AS
SELECT * FROM `service_apache-kafka-service`.measurements_from_kafka;SELECT COUNT(*) from device_measurementsSELECT
device_id,
count() as readings_number,
bar(avg(value), 0, 1000, 100) as average_measurement_value
FROM device_measurements
GROUP BY device_id
ORDER BY device_id ASC