


We are happy to announce that we have enabled read-only replica access to all of our PostgreSQL plans that have one or more standby nodes. Utilizing the standby server nodes for read-only queries allows you to scale your database reads by moving some of the load away from the master server node to the otherwise mostly idle replica nodes.
What are master and standby nodes?
PostgreSQL master node is the primary server node that processes SQL queries, makes the necessary changes to the database files on the disk and returns back the results to the client application.
PostgreSQL standby nodes replicate (which is why they are also called "replicas") the changes from the master node and try to maintain an up-to-date copy of the same database files that exists on the master.
Standby nodes are useful for multiple reasons:
- Having another physical copy of the data in case of hardware/software/network failures
- Having a standby node typically reduces the data loss window in disaster scenarios
- Restoring the database back to operation is quick by a controlled failover in case of failures, as the standby is already installed, running and in-sync with the data
- Standby nodes can be used for read-only queries to reduce the load on the master server
What is the difference between having 0, 1 or even 2 standby nodes?
Aiven offers PostgreSQL plans with different number of standby server nodes in each:
- Hobbyist and Startup plans have just a single master node and no standby nodes
- Business plans have one master node and one standby node
- Premium plans have one master node and two standby nodes
The difference between the plans is primary the behavior during failure scenarios. The are many bad things that can happen to cloud servers (or any server in general): hardware failures, disk system crashes, network failures, power failures, software errors, running our of memory, operator mistakes, fires, floods and so on.
Single node plans are most prone to data loss during failures. For example, if the server power suddenly goes out, some of the latest database changes may not have made it out from the server into backups. The size of the data loss window is dependent on the backup method used.
Single node plans are also the slowest to recover back to operation from failures. When the server virtual machine fails, it takes time to launch a new virtual machine and to restore it from the backups. The restore time can be anything from a couple of minutes to several hours, the primary factor in it being the size of the database that needs to be restored.
Adding a "hot" standby node helps with both of the above issues: the data loss window can be much smaller as the master is streaming out the data changes in real-time to the standby as they happen. The "lag" between the master and standby is typically very low, from tens of bytes to hundreds of bytes of data.
Also recovery from failure is much faster as the standby node is already up and running and just waiting to get the signal to get promoted as the master, so that it can replace the old failed master.
What about having two standby nodes? What is the point in that?
The added value of having a second standby node is that even during recovery from (single-node) failures, there are always two copies of the data on two different nodes. If another failure strikes after a failover when there is just a single master node running, we again risk losing some of the latest changes written to the database. It takes time to rebuild a new standby node and getting it in sync node after a failover when there is a lot of data in the database, and it often makes sense to protect the data over this time period by having another replica. This is especially important when the database size is large and recreating a replacement node for the faulted one can take hours.
Using standby nodes for read-only queries
Standby nodes are also useful for distributing the load away from the master server. In Aiven the replica nodes can be accessed by using the separate "Read-only replica URL" visible in the Aiven web console:
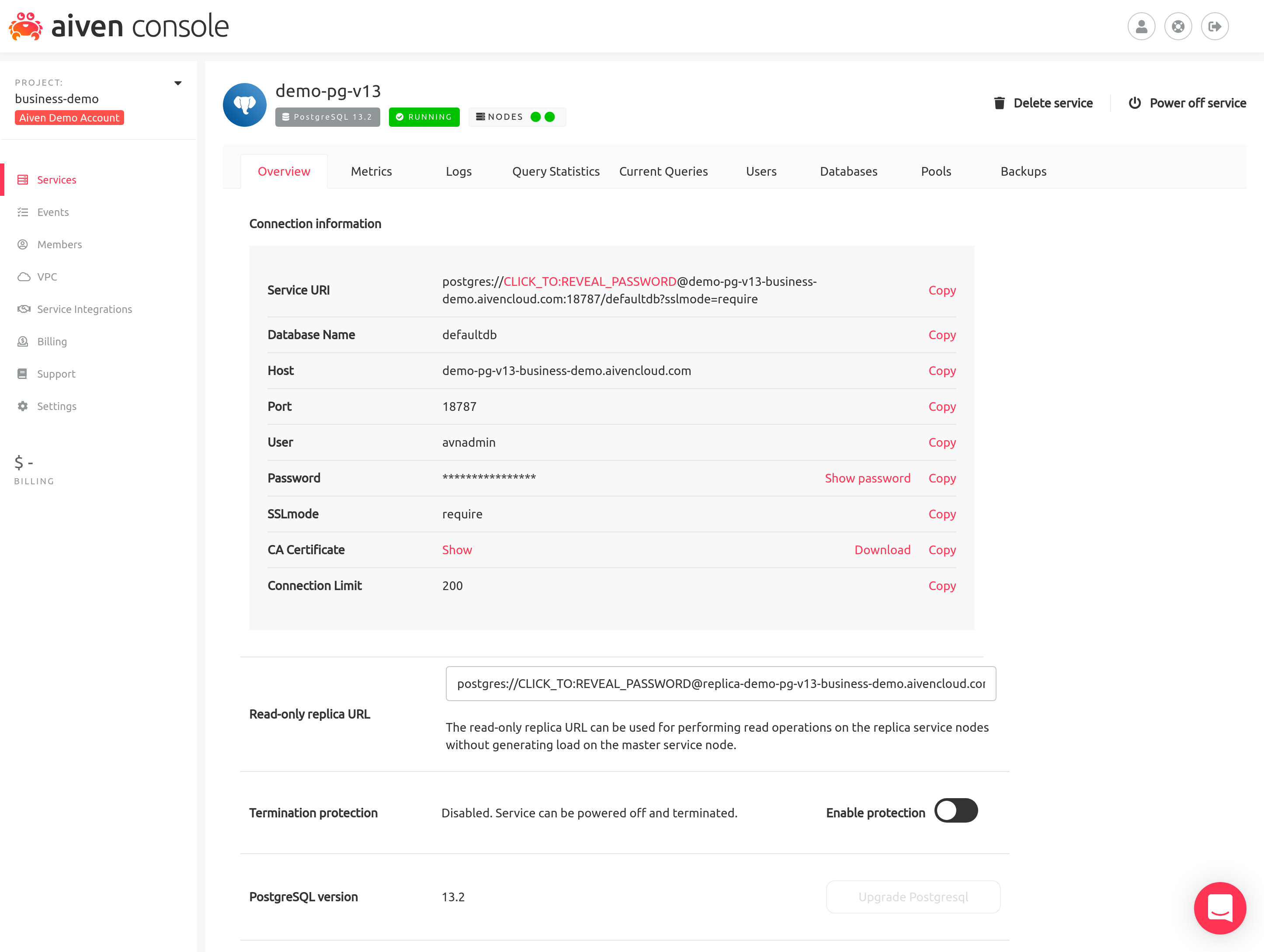
Using the replica URL in a database client application will connect to one of the available replica server nodes. Previously replica node access was only available in our Premium plans (master + two standbys) and now we have enabled it in our Business plans (master + one standby) as well.
So if you have had high CPU usage on the master node of your Startup plan, it may be worthwhile looking into the possibility of increasing your read throughput by using the replica servers for reads. Of course in addition by using a Business plan you'll also make the service have better high availability characteristics by having a standby to fail over to.
A good thing to note is that since the PostgreSQL replication used in Aiven PostgreSQL is asynchronous there is a small replication lag involved. What this means in practice is that if you do an INSERT on the master it takes a while (usually much less than a second) for the change to be propagated to the standby and to visible there.
Replica Usage
To start using your read-replica find its database URL and after that you can connect to it by copying the Read-only replica URL:
Loading code...
After which you can run any read-only query without slowing down the master.
Also while connected, PostgreSQL can tell you whether you're connected to either a master or standby node. To check that out you can run:
Loading code...
If it returns TRUE you're connected to the replica, if it returns FALSE you're connected to the master server.
Wrapping up
Not using Aiven for PostgreSQL yet? Sign up now for your free trial at https://console.aiven.io/signup!
In the meantime, make sure you follow our changelog and blog RSS feeds or our LinkedIn and Twitter accounts to stay up-to-date with product and feature-related news.
