
In today's data-driven world, data is created everywhere, and in order to be useful to an organization, it needs to move from its source to a destination. That’s what a data pipeline does — it moves data from a source to a destination where it can be stored, analyzed, and made available to other applications. Data pipelines are the backbone of modern data architecture.
But what is the meaning of a data pipeline, and how can it transform the workflows of businesses and developers? Let’s find out.
Data Pipeline Definition
At its core, a data pipeline moves data from point A to point B. This involves a series of processing steps, where data is collected from various sources, processed, and then moved to a destination where it can be used for analysis, reporting, or further processing.
The advantage of data pipelines lies in their ability to automate the flow of data from one point to another, ensuring that data is clean, consistent, and ready for use by any downstream datastore, analytics program, or application.
Big Data Pipeline: Tackling Volume and Velocity
When talking about a big data pipeline, we're referring to pipelines designed to handle vast quantities of data — think terabytes or petabytes — often streaming in real time. They are engineered to process and analyze data at lightning speed, enabling organizations to react swiftly to changing trends or operational needs.
What Are the Benefits of a Data Pipeline?
The benefits of a data pipeline extend far beyond simple data movement.
- Enhanced Data Quality and Consistency: By automating the data flow, pipelines ensure that data across the organization is consistent, reliable, and free from errors or duplications. The data can then be used by anyone or any system across the organization as the single source of truth.
- Improved Decision-Making: With timely access to processed and relevant data, businesses can make informed decisions quickly, gaining a competitive edge.
- Increased Efficiency: Automating the data pipeline process reduces manual tasks, saving organizations time and resources while increasing productivity.
- Scalability: Data pipelines can be designed in accordance with your data needs, accommodating growth without compromising performance.
- Flexibility: A data pipeline can be integrated with various data sources and formats, making it easier to adapt to new technologies and data types.
Types of Data Pipelines
There are several types of data pipelines, each designed to meet different needs:
1. Batch Data Pipelines Batch data pipelines are designed to process large volumes of data at once, typically on a predetermined schedule. These pipelines are ideal for scenarios where data does not need to be processed in real time. Batch processing can handle extensive datasets efficiently, making it suitable for data warehousing, reporting, and large-scale data movement.
1a. Full Data Set Batch
Full data set batch processing involves the complete dataset being processed at each scheduled interval. This approach is straightforward and ensures that the entire dataset is consistently processed, providing a comprehensive view of the data. However, it can be resource-intensive, particularly with very large datasets, and may result in processing delays as the system handles the entire dataset in one go. Full data set batch jobs are often performed once per day, usually during off hours like kicking off at midnight.
1b. Micro-Batch (Incremental Batch)
Micro-batch processing, also known as incremental batch processing, deals with smaller, more frequent batches of data. Instead of processing the entire dataset, only the incremental changes are processed. This approach reduces the load on the system and allows for more frequent updates, providing a balance between real-time processing and traditional batch processing. Micro-batching is beneficial for applications that require near-real-time updates, but can tolerate slight delays.
2. Streaming Data Pipelines
Streaming data pipelines are designed to process data as soon as it becomes available, providing continuous, real-time processing. These pipelines are crucial for applications that require immediate data processing and response, such as fraud detection, real-time analytics, and monitoring systems.
Streaming pipelines can handle high-velocity data and provide instant insights, making them ideal for scenarios where latency needs to be minimized. They often employ technologies like Apache Kafka and Apache Flink to manage the data streams effectively.
3. Change Data Capture (CDC)
Change Data Capture (CDC) is a specialized type of data pipeline similar to streaming, but focused on tracking and transmitting only the changes made to a relational database as they happen. CDC pipelines capture insertions, updates, and deletions in real time, ensuring that the downstream systems receive the most recent data changes without the need to reprocess the entire dataset.
CDC is particularly useful for keeping data warehouses, data lakes, and other data repositories synchronized with operational databases. It supports real-time analytics, data replication, and other use cases where timely and accurate data changes are critical. When data changes are captured from relational database log files, there is minimal, if any, performance impact on the database itself. There are specialized connectors available, like Debezium, for extracting CDC data and loading it directly into Apache Kafka for further disemmination and processing.
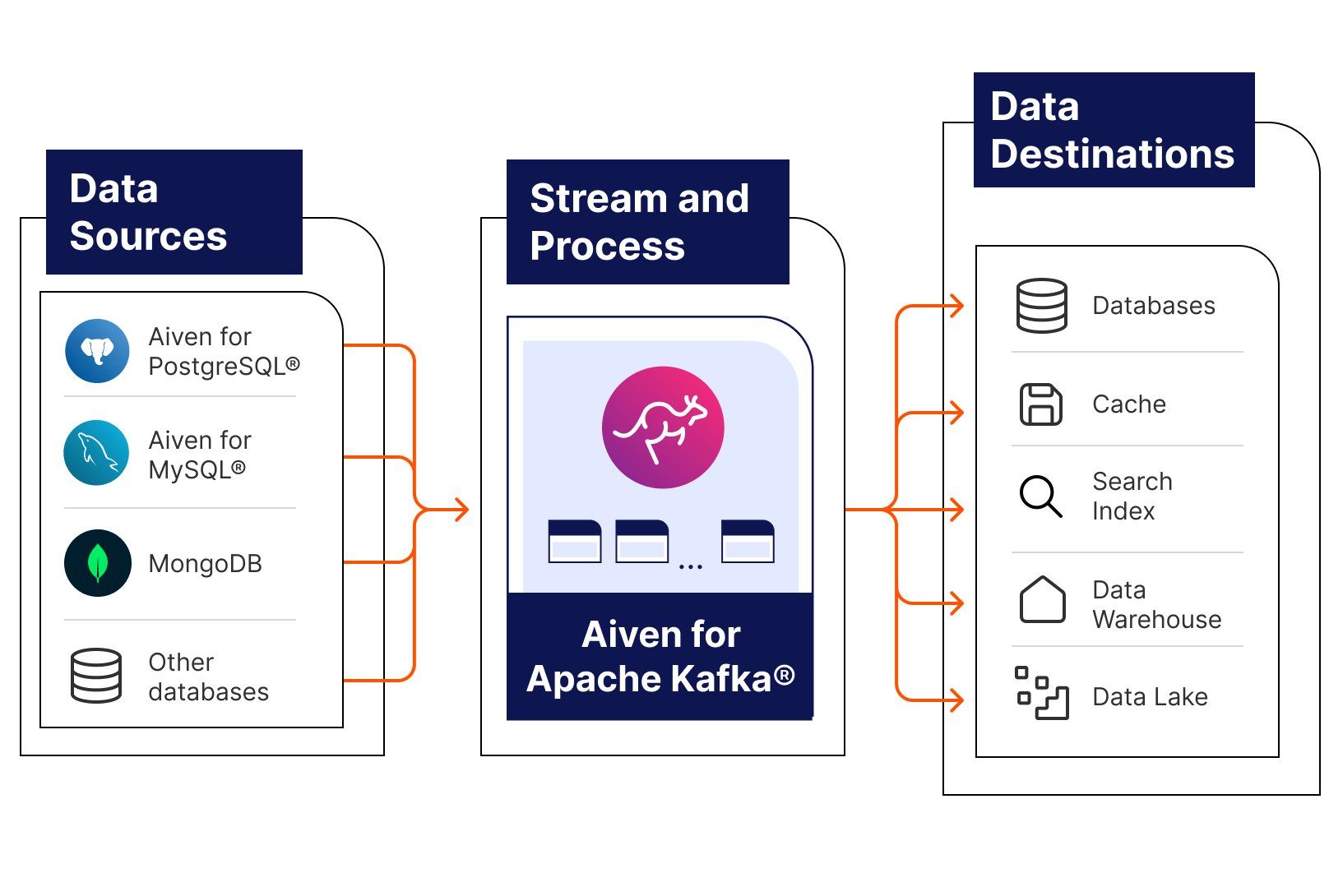
Data Pipelines vs. ETL Pipelines: Understanding the Difference
While often used interchangeably, data pipelines and ETL (Extract, Transform, Load) pipelines have distinct differences:
- Purpose and Scope: Data pipelines are broader in scope, designed to automate the flow of data through various processes, including but not limited to ETL. ETL pipelines are a subset of data pipelines specifically focused on extracting data from sources, transforming it, and loading it into a destination system for analysis.
- Flexibility and Complexity: Data pipelines can handle a wide range of data operations beyond ETL, including real-time data processing and streaming. ETL pipelines, by contrast, are specifically designed for batch processing and transformation of data for analytics purposes.
- Use Cases: ETL pipelines are typically used in data lake or data warehousing scenarios where data needs to be stored and prepared for analysis. Data pipelines have a broader range of applications, including real-time analytics, machine learning model feeding, and more.
In essence, while ETL pipelines are an essential component for data preparation in analytics, data pipelines encompass a wider array of data processing and movement tasks, offering greater flexibility to meet the diverse needs of modern data-driven organizations.
The Data Pipeline Process
Navigating through the stages of the data pipeline process is crucial for businesses aiming to leverage their data for strategic advantage. Let’s delve deeper into each step to understand its importance and complexity.
1. Data Collection
The journey of data through the pipeline begins with data collection, a critical stage where diversity in data sources becomes apparent.
From structured data residing in databases to unstructured data pulled from social media, cloud services, APIs, and IoT devices, the variety is vast.
This phase is foundational because the quality and breadth of collected data directly impact the insights that can be generated. Ensuring completeness, accuracy, and timely collection of data sets the stage for the subsequent processes in the pipeline.
2. Data Processing
After the data is collected, it is far from ready for analysis. It often arrives raw, unstructured, and riddled with discrepancies. Data processing is where this raw material is refined into a valuable resource. This stage involves several steps:
- Cleansing: Removing errors, duplicates, and irrelevant entries to ensure data quality.
- Normalization: Standardizing formats and values to ensure consistency across the dataset.
- Transformation: Converting data into a format or structure suitable for analysis, which may include complex operations like tokenization, encryption, or data masking for security purposes.
- Aggregation: Summarizing detailed data for more general analysis, which is vital for handling vast volumes of data efficiently.
Each of these steps requires careful consideration and application of rules and algorithms that align with the data’s end use.
3. Data Storage
Now, the processed data needs a home where it can be easily accessed, queried, and analyzed. This is where data storage comes into play, with options ranging from traditional databases to modern data warehouses and data lakes, each serving different needs.
Data warehouses are structured and ideal for storing processed data ready for analysis, while data lakes can store vast amounts of raw data in its native format, as well as transformed data ready for various purposes.
Choosing the right storage solution is pivotal, as it affects the efficiency of data retrieval and analysis stages.
4. Data Analysis
The culmination of the data pipeline process is data analysis, where the stored data is turned into insights.
Through techniques ranging from statistical analysis to machine learning models, businesses can extract actionable insights about
- customer behavior,
- operational efficiency,
- market trends, and more.
This stage is where the true value of a data pipeline is realized, as it informs business strategies, identifies areas for improvement, and can significantly enhance customer experiences.
How Do You Create a Data Pipeline?
Each of the following steps is crucial for creating a data pipeline that efficiently and reliably meets your needs.
1. Define Your Objectives
Understanding your objectives involves identifying the specific goals you aim to achieve through your data pipeline. Questions to consider include:
- What kind of data will you be dealing with (customer data, transaction data, sensor data, web clickstreams, system log files, etc.)?
- What are your end goals (real-time analytics, machine learning, reporting)?
- Who are the end-users of the data pipeline (data scientists, business analysts, other applications)?
Defining clear, measurable objectives will guide your decisions throughout the data pipeline development process, ensuring that the final product aligns with your business needs and goals.
2. Select Your Tools and Technologies
Choosing the right set of tools and technologies is critical for the success of your data pipeline. This step involves researching and selecting the software and infrastructure that will support your pipeline’s requirements. When deciding on the right solution, ask yourself:
- Can the tools handle your data volume as it grows?
- Are the tools stable and dependable for critical operations?
- How user-friendly are the tools? Will your team need extensive training?
This selection process might involve comparing databases, data processing frameworks, cloud infrastructure services, and any other technologies relevant to your pipeline’s needs.
3. Design Your Pipeline Architecture
Designing your pipeline architecture involves planning how data will move through your system from collection to storage and analysis.
Things to consider:
- Where is your data coming from, and where does it need to go?
- Will data move in real time, or will it be in pre-scheduled batches?
- What transformations or enrichments are required?
A well-thought-out architecture not only focuses on the current needs but also anticipates future scaling and integration requirements.
4. Implement Data Processing Logic
With a clear design in place, the next step is to implement the logic that will process your data. This involves writing code or configuring your chosen tools to cleanse, transform, and aggregate data according to your predefined rules and requirements.
This step is where technical skills and understanding of the data come into play, as the processing logic needs to be both efficient and accurate to ensure the quality of the output.
5. Test Your Pipeline
Testing is a critical phase that determines the robustness of your data pipeline. It involves running real data through your pipeline to identify any issues or bottlenecks. Testing should cover:
- Functionality – Does the pipeline meet the defined objectives?
- Performance – Can it handle the expected data volume and velocity?
- Accuracy – Are the data transformations correct?
Comprehensive testing ensures that your pipeline is ready for deployment and can handle real-world data and scenarios.
6. Monitor and Maintain
Deployment is not the end of the pipeline journey. Continuous monitoring is essential to ensure that the pipeline performs as expected over time.
Monitoring involves:
- Performance - Keeping an eye on processing times, throughput, and resource utilization,
- Resiliency - Quickly identifying and addressing any issues that arise,
- Management - Regularly updating the pipeline to accommodate new data sources, changes in data formats, and evolving business requirements
Data Pipeline Examples
Let's take a look at some examples of how data pipelines are used in various areas:
- E-commerce Personalization: An e-commerce company uses data pipelines to collect customer behavior data in real time, analyze purchasing patterns, and deliver personalized product recommendations.
- Financial Fraud Detection: A bank employs a streaming data pipeline to monitor transactions across its network, applying machine learning models to detect and prevent potential fraudulent activity instantaneously.
- Social Media Analytics: A social media platform utilizes a real-time data pipeline to aggregate user data, analyze engagement metrics, and optimize content delivery for enhanced user experience.
Seamless Data Pipelines: How Aiven Is Changing the Game
Navigating the data landscape requires powerful tools tailored for efficiency, scalability, and reliability.
Aiven’s managed Apache Kafka® significantly enhances data pipelines for any systems or applications requiring high volumes of data with very low latencies. Streaming data pipelines with Apache Kafka offer:
- High throughput and scalability to manage vast volumes of data from numerous devices,
- Real-time data processing to ensure immediate insights and responses to fresh data,
- Enhanced durability and reliability for safeguarding critical data against loss, even in the event of system failures,
- Decoupling of data producers and consumers to streamline system scalability, facilitate seamless integration with a variety of data processing and storage technologies, and limit the impact radius if or when failures occur.
For more information about streaming pipelines, visit our Aiven for Streaming solutions web page.
Discover the beauty of seamless data pipelines & transform your real-time insights into action. Get started for FREE!
Further Reading
- Why you should think about moving analytics from batch to real-time (Blog article)
- Move from batch to streaming with Apache Kafka® and Apache Flink®
- Build a real-time analytics pipeline in less time than your morning bus ride (Blog article)
- Secure, Segregated Multi-tenant Analytics in PostgreSQL® using Aiven for Apache Kafka®, Debezium®, and Aiven for ClickHouse® (Blog article)
- Using Kafka Connect JDBC Source: a PostgreSQL® example (Tutorial)
Table of contents
- Data Pipeline Definition
- Big Data Pipeline: Tackling Volume and Velocity
- What Are the Benefits of a Data Pipeline?
- Types of Data Pipelines
- Data Pipelines vs. ETL Pipelines: Understanding the Difference
- The Data Pipeline Process
- 1. Data Collection
- 2. Data Processing
- 3. Data Storage
- 4. Data Analysis
- How Do You Create a Data Pipeline?
- 1. Define Your Objectives
- 2. Select Your Tools and Technologies
- 3. Design Your Pipeline Architecture
- 4. Implement Data Processing Logic
- 5. Test Your Pipeline
- 6. Monitor and Maintain
- Data Pipeline Examples
- Seamless Data Pipelines: How Aiven Is Changing the Game
- Further Reading