Webhook data from Apache Kafka®️ to the world
Let your data flow with the Apache Kafka®️ HTTP sink connector
Let your data flow with the Apache Kafka®️ HTTP sink connector
There are many reasons why Apache Kafka®️ is such a powerful tool, and an important one is the extensive selection of ready to run connectors that can bring data in or out of Apache Kafka and connect it to any of the other components in your system.
One of the best connectors available is the HTTP sink connector because it's so adaptable. Today we'll use an HTTP Connector to send the data from a Kafka topic to any HTTP endpoint, giving you an easy way to integrate your data with your own code or any platform that supports webhooks. This lets you send your data to places there might not be a prebuilt connector for!
All data platforms are more fun when they have actual data in them, and some way to see what's happening. In this post we'll use:
The fake data producer generates and sends data to an Apache Kafka topic, Kafka Connect consumes the data and sends it over HTTP to a webhook endpoint. Hookdeck is a tool we'll use in this demo to mock a webhook.
You will need:
Starting at the end seems counterintuitive, but by setting up the webhook endpoint now, we have the URL available when we configure the other parts of the setup.
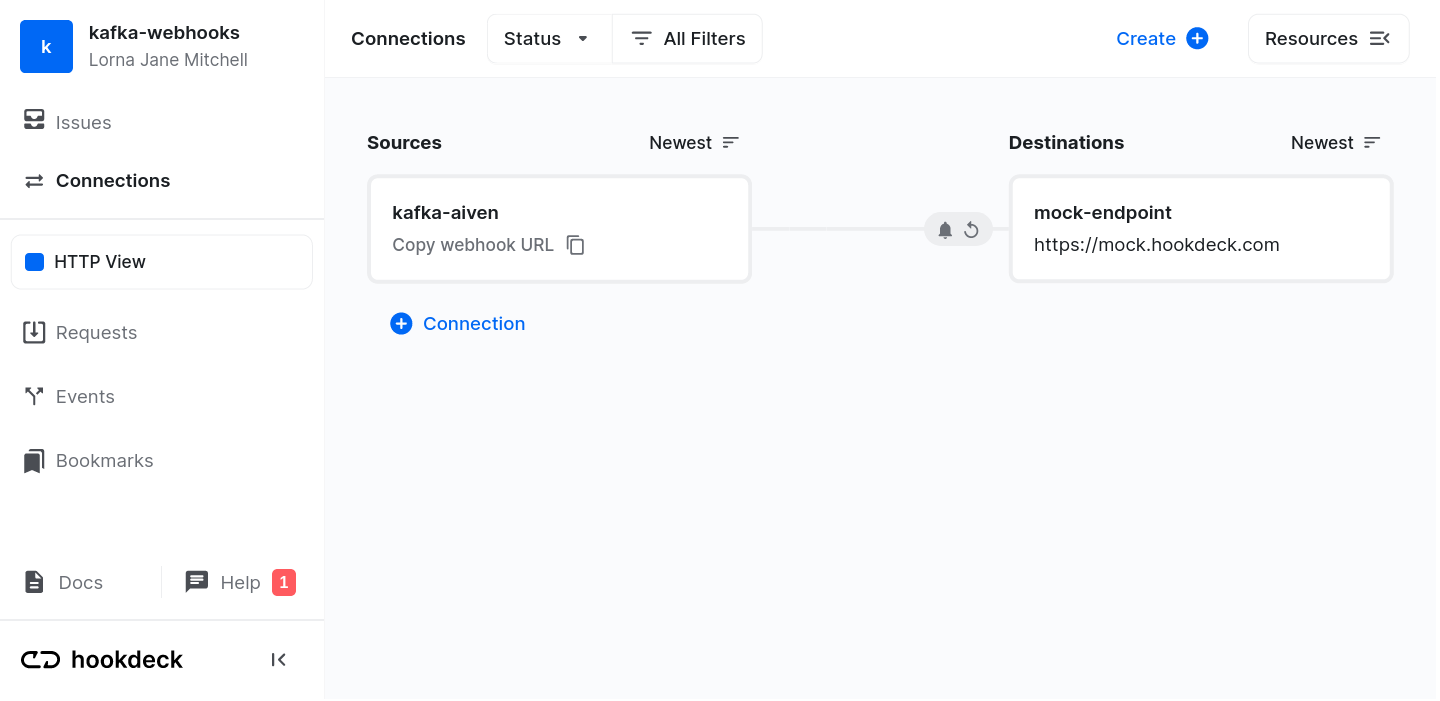
Go to your Hookdeck dashboard, and create a new connection.
kafka-aiven.mock-endpoint.
Your connection should now be set up, showing that requests to the kafka-aiven URL will be sent to the mock-endpoint.
Copy the webhook URL from the source box, and put it somewhere safe. We need this later.
If you're already curious about the webhook feature, you can paste the URL into your browser and see the request arrive in the dashboard on Hookdeck.
Visit the Aiven Console, and choose or create a project.
Click Create service and add the first service, Apache Kafka. Choose a cloud and region: a business-4 plan size in your region is a good option, as the startup plan sizes are a little underpowered for connectors. We'll stop the services at the end of this post, so don't worry about running up a bill. Give your service a name, for example kafka-demo.
While the service is building, we can configure it:
user_activity if you'll be sending user data to the topic. We'll need this topic name later to configure the connector.With the streaming data platform in place, the next step is to add the connector to bring the data to another platform.
Click Set up integration and choose Apache Kafka Connect. Select the option to create a new service and again give your connect service a name such as kafka-demo-connect. Choose the same cloud and region to ensure the service is speedy. Pick a plan size such as business-4. When you're happy with your choices, select Create and enable, and your service will start building.
From the service overview page of your Apache Kafka service, go to the Integrations tab, and click on the Kafka Connect service. In the Connectors tab, click Create connector. Pick the HTTP sink connector from the list.
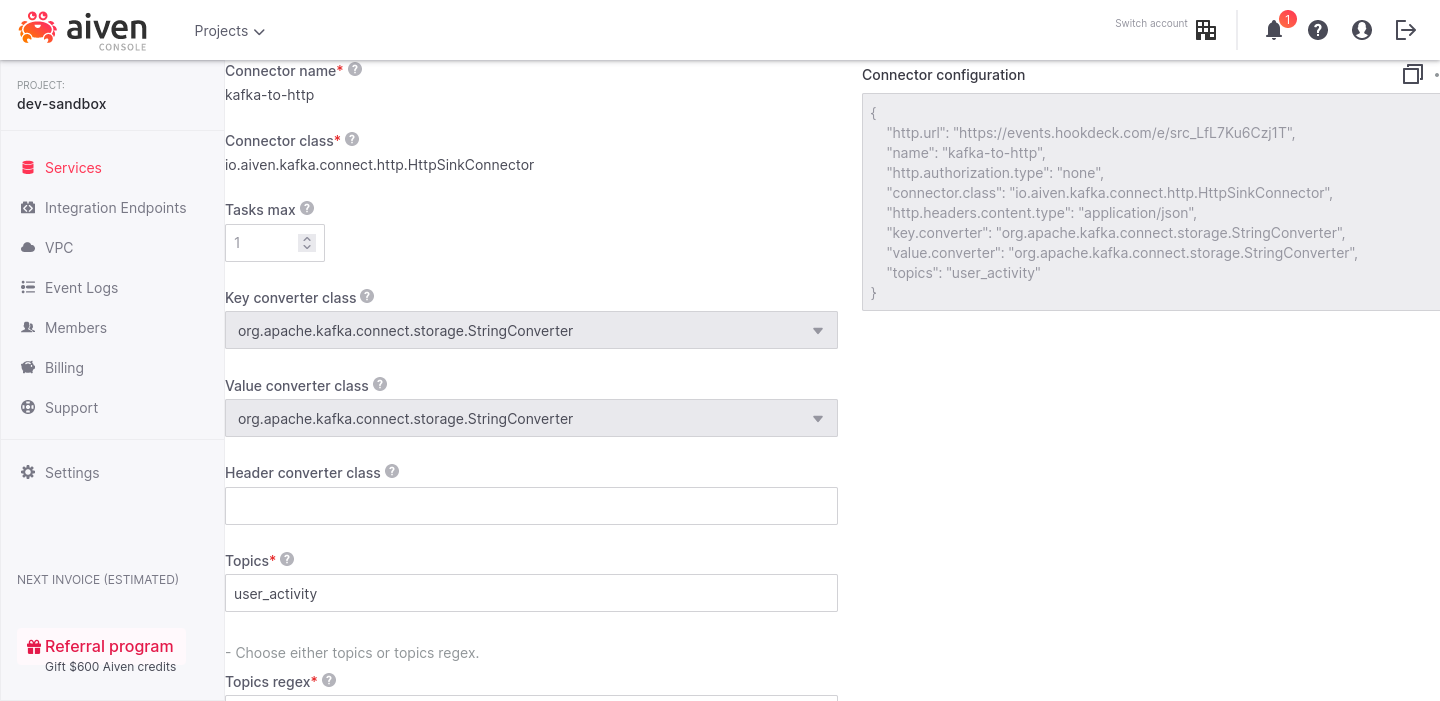
This was the fun part, next is the tricky bit: configuring the connector. Here are the settings you need, by section:
In the Common tab:
kafka-to-http would work, or a name that fits your project.user_activity, the topic we created earlier in this post.StringConverter for both fields.In the Connection tab, input information about the HTTP endpoint we're sending data to:
http.url: the URL of the Hookdeck endpoint we created.http.authorization.type: none (warning: the value is case-sensitive).http.headers.content.type: application/json. We'll be using JSON data in our sample data payloads later.
Once everything is in place, click Create connector to bring your ideas to life.
If you see errors when setting up the configuration, go to the Logs tab of your Kafka Connect and Apache Kafka services for more detail.
Everything is set up, all we need now is data!
To test that our Apache Kafka connection to Hookdeck is configured correctly, let's send a single message. We enabled the Karapace REST features earlier, so we can do this through the Aiven web interface. If you have a favourite Kafka client, feel free to use that instead (we have docs for some cool Kafka tools here).
In the Topics tab, click the three dots icon on the right hand side for the topic you created earlier such as user_activity, then click Produce message.
This defaults to JSON, so the only thing to do is add some Value data (the key isn't needed). You can send any valid JSON, but here's some test data to use if you'd like:
Loading code...
Click Produce. You can inspect the messages on the topic by with the Fetch messages button. If you set the Format dropdown to JSON and then fetch, the messages come through as JSON.
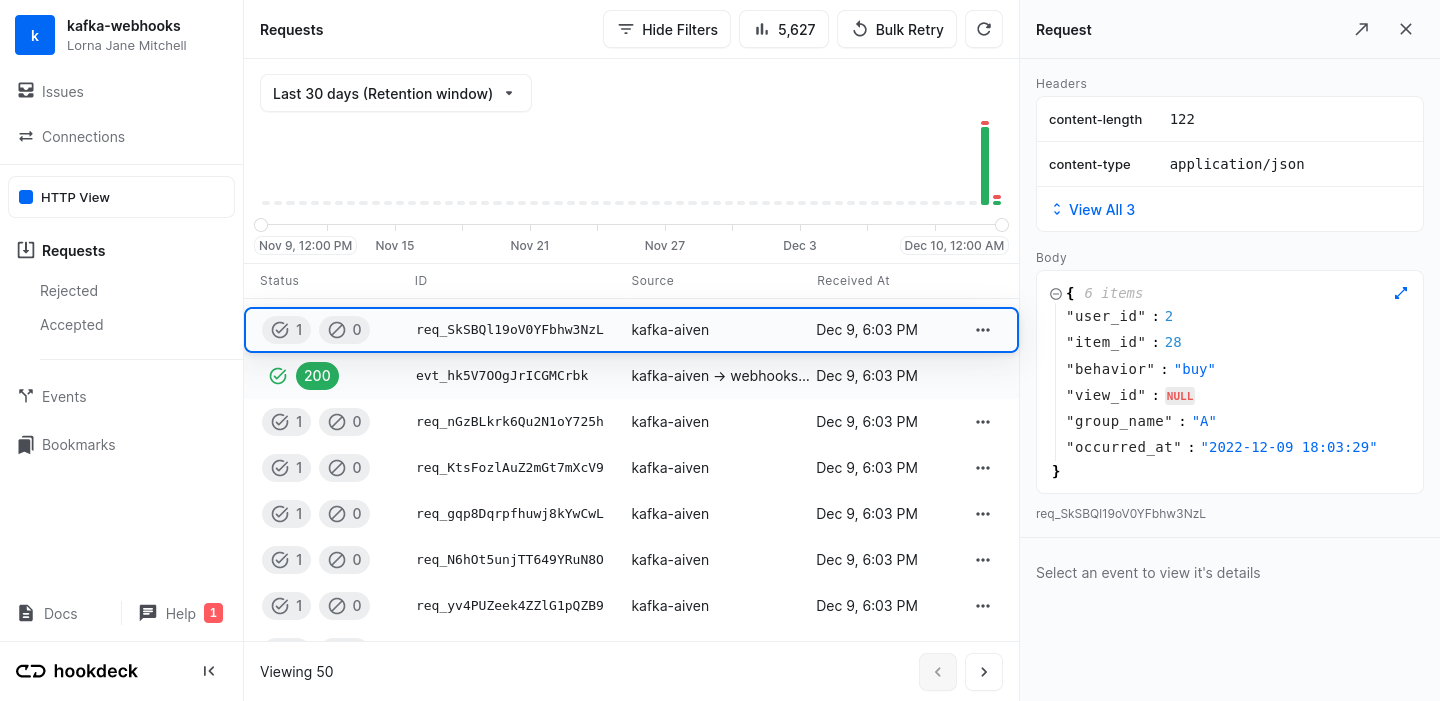
The message is in our topic, but did the connector send it over to Hookdeck? Visit the Hookdeck requests dashboard and check that your message arrived.
Producing one message at a time is hard work! Adding a data generator lets us see the connector in action.
To see the connector performing its work, get Aiven's fake data producer to give us something to look at.
Clone the GitHub repository and install the dependencies with:
Loading code...
To connect to our Aiven for Apache Kafka service, we'll need to download the certificates to a directory called certs/ in the newly-cloned project. Create the directory, then visit the Service overview page of the Apache Kafka service (note: not the Kafka Connect service) and download each of:
Place all three files in the certs/ directory.
Copy the Host and Port values from the same Service overview page, to the HOST` and PORTvalues in the command below. You can also configure--topic-namefor which topic to use,--nr-messagesfor how many messages to send, and--subjectfor the type of sample data to be generated; I'm usinguserbehaviourto get some sample user website data, and you can find out about the alternatives on the projectREADME`. Run this from the root of the cloned project to send data into the topic:
Loading code...
If everything went well, the Hookdeck requests dashboard shows the ten sample data messages have arrived as HTTP requests.
The data from the producer was sent to the topic, picked up by the connector and sent out as a webhook, and received by Hookdeck over HTTP.
HTTP is the universal data adapter: in this tutorial, using an HTTP sink gets your data from Apache Kafka and sends it somewhere that there isn't a Kafka Connector available for. You can send a webhook to any web endpoint, either in your own application or in another platform such as Zapier, then the webhook can trigger another event or make an easy integration with another platform.
In this example, Hookdeck was an excellent place to send the webhook to. It is a powerful gateway for webhooks whether using the mock server feature to inspect the requests as we did here, or using it to pass traffic either onwards to your application, or securely to a local development platform.
The HTTP sink connector is just one of the wide selection of connectors available for Apache Kafka, so take a look at the list of connectors and decide which one to try next!
As a final tip: if you have finished with the services you used, then it's good practice to power down or remove things you don't need. This avoids running up bills, or using up your trial credit.
For each of your Aiven services, visit the service overview page and either:
Some handy links to the tools used in this post and resources showing how to use them.
Table of contents
{
"user_id": 4,
"behavior": "buy"
}pip install -r requirements.txtpython main.py \
--security-protocol ssl \
--cert-folder certs/ \
--host $HOST \
--port $PORT \
--topic-name user_activity \
--nr-messages 10 \
--max-waiting-time 0 \
--subject userbehaviour