


Our latest Kafka meetup was co-hosted with Zalando at their Helsinki office. Zalando’s numbers are impressive: their microservices architecture handles several terabytes of data per day across over 2,000 events.
More than an eCommerce company, they are unmistakably a tech powerhouse that employs over 1,600 tech workers who not only manage an impressive mission critical infrastructure, but are also actively contributing their tooling and solutions to open source.
In short, a great organization and talent to co-host with; now let’s get to the who and what of the meetup. Representing Zalando was Dmitriy Sorokin, a senior java developer. For Aiven, our very own Head of Product, Hannu Valtonen.
It started with Nakadi
The event started with Dmitriy discussing Nakadi and Bubuku, the former a distributed event bus with RESTful API built on top of Kafka and the latter a Zalando-built supervisor for operating Kafka on AWS.
Nakadi, a RESTful API on top of Kafka-like queues
Download the slide deckFor Nakadi, one of the most interesting features is Timelines. Essentially, Timelines allow you to efficiently move topics and events around Kafka clusters and their brokers without interrupting producers or consumers.
For instance, moving topics between clusters requires data to be copied between them to ensure consistency. If the cluster is large enough, like Zalando clusters, this can take a lot of time during which performance is degraded.
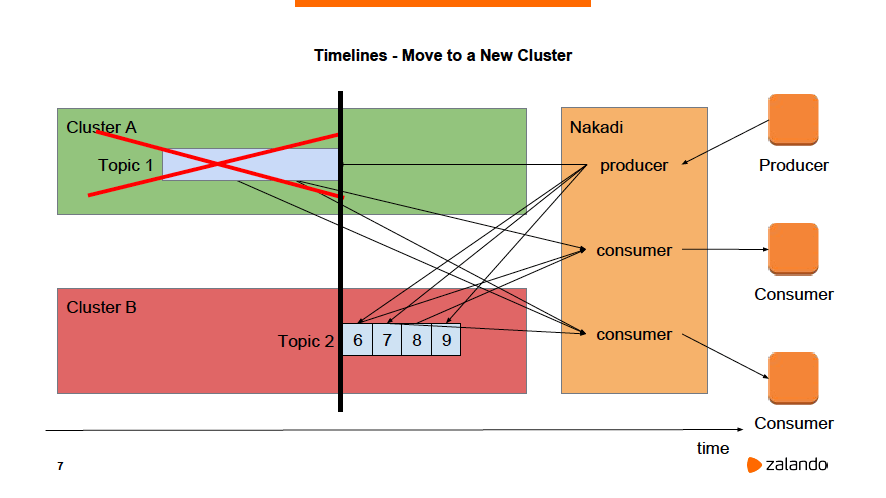
By using Timelines, you can begin writing to a second cluster while letting the consumers continue reading from the first. The consumers eventually catch up to the producer and begin reading from the second: all of this happens with no interruption in service.
Similar patterns can be used to perform other tasks, e.g. repartitioning. With Nakadi abstraction, it is possible to utilize other Kafka-like queues, e.g. AWS Kinesis or Apache Pulsar. For even more examples and diagrams, download the slide deck!
Continued with Bubuku
Bubuku, a tool that Zalando created for making their operations of Kafka easier
Download the slide deckDmitriy then moved onto discuss Bubuku, a tool that Zalando created for making their operations of Kafka easier.
Bubuku allows users to coordinate Kafka instances, such as starting and restarting them in controlled sequences, detect and restart misbehaving Kafka processes, as well as perform balancing partition distribution.
Dmitry’s number one rule for creating a supervisor like Bubuku?
Don’t, search for an existing one!
This is perhaps the fundamental dilemma with tech organizations, to build or to buy, and one to always balance.
And ended with PG CDC with Debezium
Hannu closed the evening’s field with his discussion on Change Data Capture in PostgreSQL, specifically the issues with how it used to be done and how can be done much more easily using Kafka via Debezium.
PG change data capture with Debezium
Download the slide deckIn the early 2000s, or the age of the dinosaur as he put it, CDC was a batch-based process where you might do a nightly database dump of some or all tables and perform ETLs from multiple databases to a single system.
Luckily, this was about to change in 2014 thanks to logical decoding.
Logical decoding allows PostgreSQL to keep track of all changes within the database and decodes WAL to a desired output format.
BUT, there are some things that it can't do, such as replicate DDL. It also doesn’t handle failovers exceptionally well because the replication slots exist only on master nodes.
So where does Debezium come in?
Simple, it uses logical replication to replicate a stream of changes to a Kafka topic. Its primary benefit is that it turns what was once a batch process into a streaming one, allowing users to get data in real-time.
As great as it is, there is a gotcha or two like logical decoding. For example, it has limited data type support and if a PostgreSQL master failover occurs, the PG replication slot disappears; forcing users to recreate state.
Wrapping up
As I hope you’ve seen, our last Kafka meetup was jam-packed with information on tools to manage and get even more out of Apache Kafka. It also provided fertile ground for participation from our 30+ attendees.
It’s been a busy spring, hence the delay in this post. Nonetheless, our next meetup is definitely in the works! Make sure you don’t miss out and join the Helsinki Apache Kafka Meetup group to get notified when we schedule it.
In the meantime, you can review the slide decks from the presentations and join the Aiven blog's RSS feed or follow us on Twitter to stay up-to-date with the latest Aiven for Apache Kafka updates.
