


TLDR; Aiven Stream Governance is our developer-centric approach to making trustworthy data the free and default experience, not a costly add-on.
- Available Now: The new Sample Data Generator gets you a live, governed Kafka topic with a schema applied - in just 30 seconds.
- Coming Soon: An Accelerated Onboarding wizard to connect your own applications with AI-enhanced tooling and a dedicated Topic Catalog to manage all your data streams at scale.
The cost? Nada. Because credible streaming is a right not a privilege.
The Best Stream Governance is No Governance
I'd be willing to bet that you're having one of two reactions to that title:
"No Governance? That's a future of pure chaos, broken pipelines, and zero traceability..."
"No Governance? Amazing! We can finally build cool stuff without getting sidetracked!"
Polarising? Absolutely. Worth exploring? Totally.
This tension exists because the very idea of ‘Governance’ has been pulled in different directions. On the one hand, Governance has always been about enabling safe collaboration so that teams can build reliable systems. On the other, it acts as a set of control gates that introduce friction, and cause developers delays and frustration. It’s this high-friction model that creates a pain developers know all too well: they routinely spend days, if not weeks, getting their Kafka service up and running.
The outcomes of Governance—trustworthy, reliable, and secure data streams—are not just valuable; they are essential. But developers want to build applications. Their job is to ship features and solve problems. They expect their data to just be there - safe, reliable, and available.
Simply put, engineers want to build applications, not become part-time Kafka administrators. They shouldn’t have to wrestle with topic configurations, or hunt for schemas just to do their job. That process forces them out of their workflow and to take their hands off the wheel. It presents a false choice between moving fast and building correctly and, to be honest, Aiven has been part of the problem.
The Kafka House: A Hall of Mirrors
Imagine, if you will, that Kafka is a house.
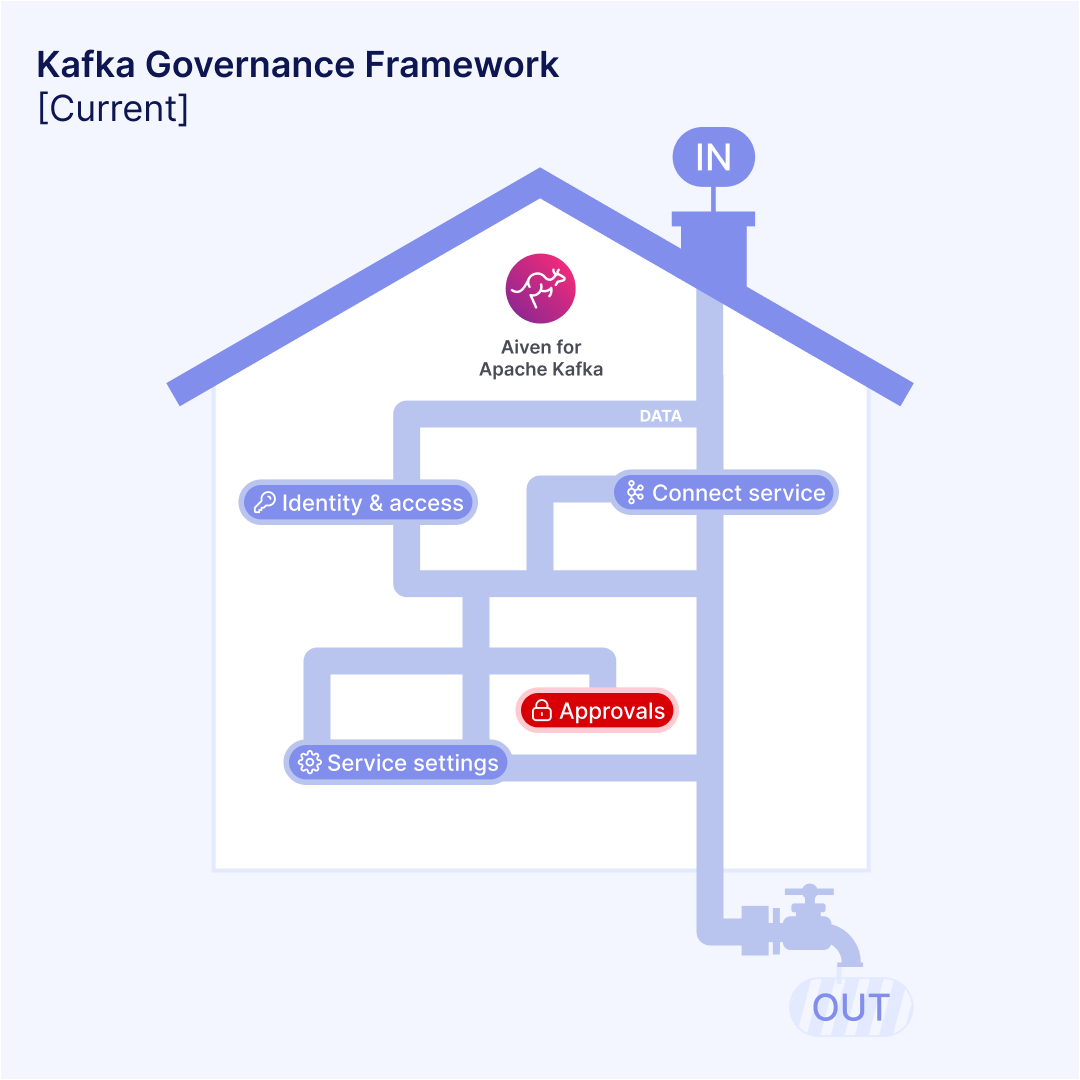
Every time a developer configures a Kafka Connect integration, for example, they must navigate through a set of rooms, starting with the ‘Connect Service’ room. Once here, they discover that a prerequisite to move on is missing. After some research and some digging, they realise they need to adjust a service-level configuration, like enabling Kafka REST proxy or setting up Schema Registry. So, off they go to the ‘Service Settings’ room. With that change made, they return, only to discover they now need to create a specific Service User with the right permissions, for which they need to visit the ‘Identity and Access’ room, all before they can even think about returning to their original task. For each task, they must make and remake each step to debug their setup until they finally have all the components ready.
This constant jumping between pages (or rooms) for a single goal—getting a new data stream working—describes a laborious setup process. It creates a significant cognitive burden, where each detour breaks mental flow and causes frustration. Every minute spent traversing these disconnected spaces is a minute lost building tangible business value.
It’s important to stress that all elements of a secure and reliable data stream do need to exist to prevent data leaks, pipeline breaks, and low-credibility data. However, the fundamental issue lies in how the Kafka ecosystem presents itself. Configuring a connector to bridge a data stream requires explicit knowledge of the specific topic it needs to interact with. This mandates not only access rights and clear visibility of that topic, but also the crucial definition of its data structure via a schema. Furthermore, permissions are managed at the topic level through ACLs.
When the platform forces developers to manage these interconnected elements across disparate feature-based interfaces, it creates a bewildering Hall of Mirrors. Expecting users to unify schema, connectivity, and permissions without a cohesive, logically intuitive home for the data stream itself is to invite frustration. The system, designed by component, fails to reflect the developer's goal-oriented reality.
The Locked Door
If the Hall of Mirrors describes a frustrating assembly process, the Locked Door represents the challenge of validation. Navigating a maze of rooms is only half the problem; the deeper issue is that Kafka, by design, is unopinionated. It will happily let a developer configure every component across that entire journey, only to reveal a show-stopping and fatal flaw at the final moment.
This show-stopper is the equivalent of our user successfully navigating every room of the Kafka house, correctly assembling all the pipes, and turning on the ‘data’ tap, expecting a stream, but getting nothing out. The setup is complete, yet it fails. Why? A single overlooked ACL on a topic could have blocked everything. The system, which offered no proactive guidance, reveals the misconfiguration only at the point of execution. This is the Locked Door. At this point, our user is forced to abandon their hard-earned work and head straight to the ‘Approvals’ lounge—which, by the way, has a queue.
This is more than just a bad user journey; it's a symptom of a deeper philosophical mismatch. Kafka is indifferent to the developer. It's a powerful engine that does exactly what it's told, but offers no guidance. And the developer? The feeling is mutual. They don't care about Kafka; they care about building an application that uses real-time data. To them, Kafka is just an implementation detail they wish they could ignore.
This is the central dissonance of modern data streaming: a platform that is ignorant of the users’ needs and a user who wants to be ignorant of the platform's complexities. And right in the middle is Governance: forcing a confrontation between a system that won't 'do things right' unless explicitly told to and a user who just needs things to be right. The result is that the developer who only wants the data is forced to become an expert in plumbing.
This isn't a theoretical problem. We see developers vote with their feet every day. Faced with a choice between speed and a high-friction Governance model, they will almost always choose speed, relying on infrastructure-as-code and GitOps frameworks to bypass complexity. They choose to incur governance debt, pushing the problem down the road. The tragedy is that when they eventually scale and need to pay back that debt by retrofitting the controls they skipped, the process is painful and expensive. The current model doesn't just present a bad workflow; it forces a terrible long-term trade-off.
“Without strong governance in place, things start to break down as usage grows. You end up with inconsistent data, duplicate topics, and a lot of technical debt. By the time you realize you need structure, it’s much harder to retrofit. If you really want to unlock the long-term value of streaming data, governance has to be part of the foundation from day one.”
- Muralidhar Basani, Founder of Klaw, Staff Software Engineer at Aiven
What if Kafka Had an Opinion?
So we asked ourselves: What would Kafka look like if it was redesigned from the ground up today to be an expert, opinionated helper obsessed with developer workflows and goals?
The answer is that it would look less like a collection of features and more like a reflection of the developer's mind. A developer thinks in terms of goals and workflows, not UI tabs. Their mental journey is centered around the data stream itself. So when we say ‘developer-centric’ we really mean ‘topic-centric’.
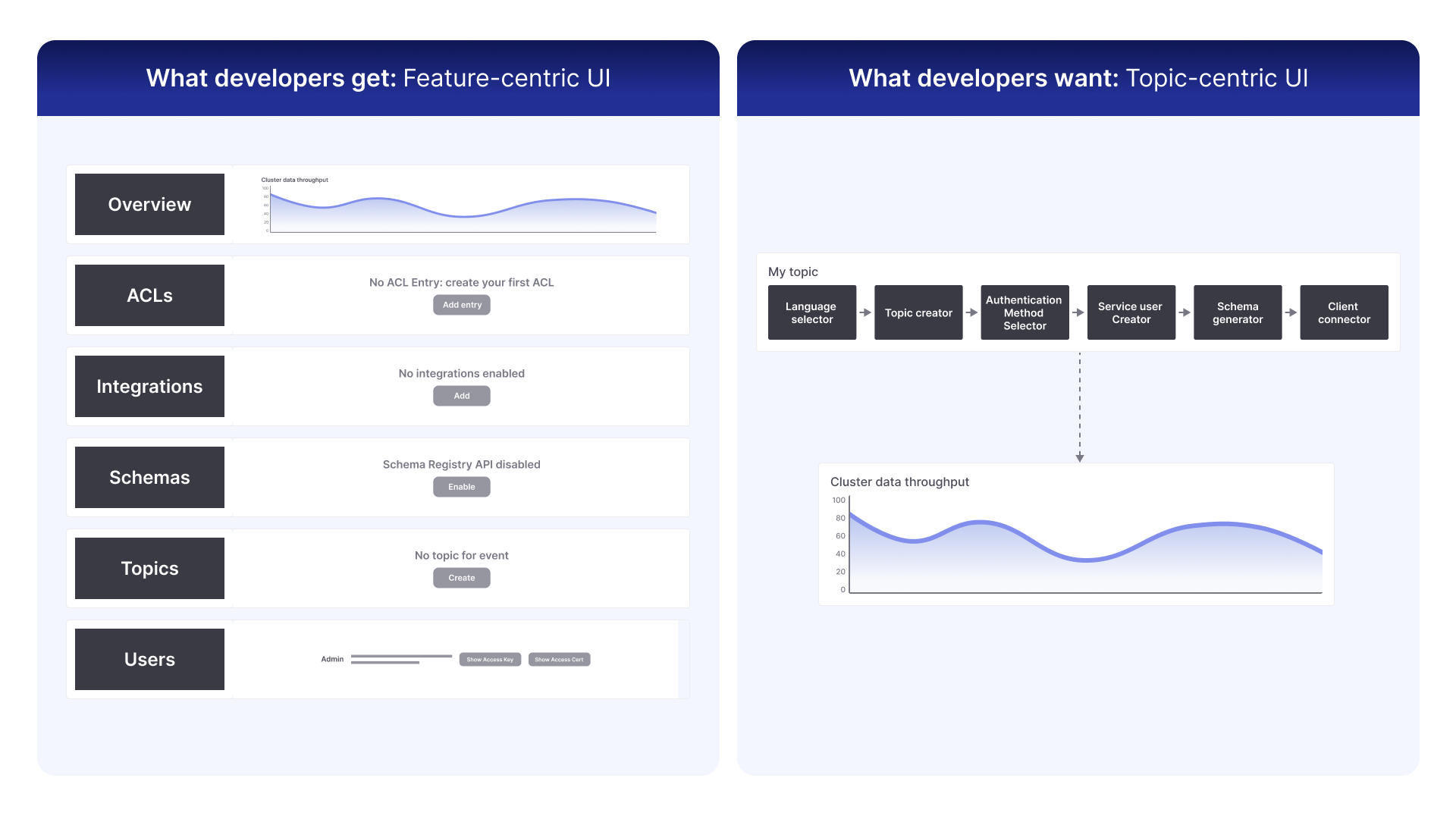
This is the core philosophy of Aiven Stream Governance.
Introducing Aiven Stream Governance
Aiven Stream Governance transforms the user experience via a topic-centric hub where schemas, connectors and permissions are all managed from one logical place. No more Hall of Mirrors.
Today, we’re taking the first step by targeting the most painful moment for new users—the ‘blank slate’—with our new Sample Data Generator. It’s the first proof point of an opinionated Governance roadmap that anticipates a developer's needs and guides them to success.
What was a 20-minute journey through documentation and UI tabs is now a guided, 30-second experience. That’s 40x faster!
In 30 seconds you get:
- A created topic
- A generated schema, applied to the topic
- Live traffic on your cluster
- Real-time visualisations of your new message stream
From zero to a live, governed data stream in half a minute. We’re proud of 30 seconds, but we’re not stopping. Our goal is to get down to 10 seconds.
But don’t just take our word for it - see for yourself:
A new standard for streaming data at Aiven
Our commitment is to build a data platform where the easiest path is also the correct path, embedding good governance as an automatic outcome of a great developer experience.
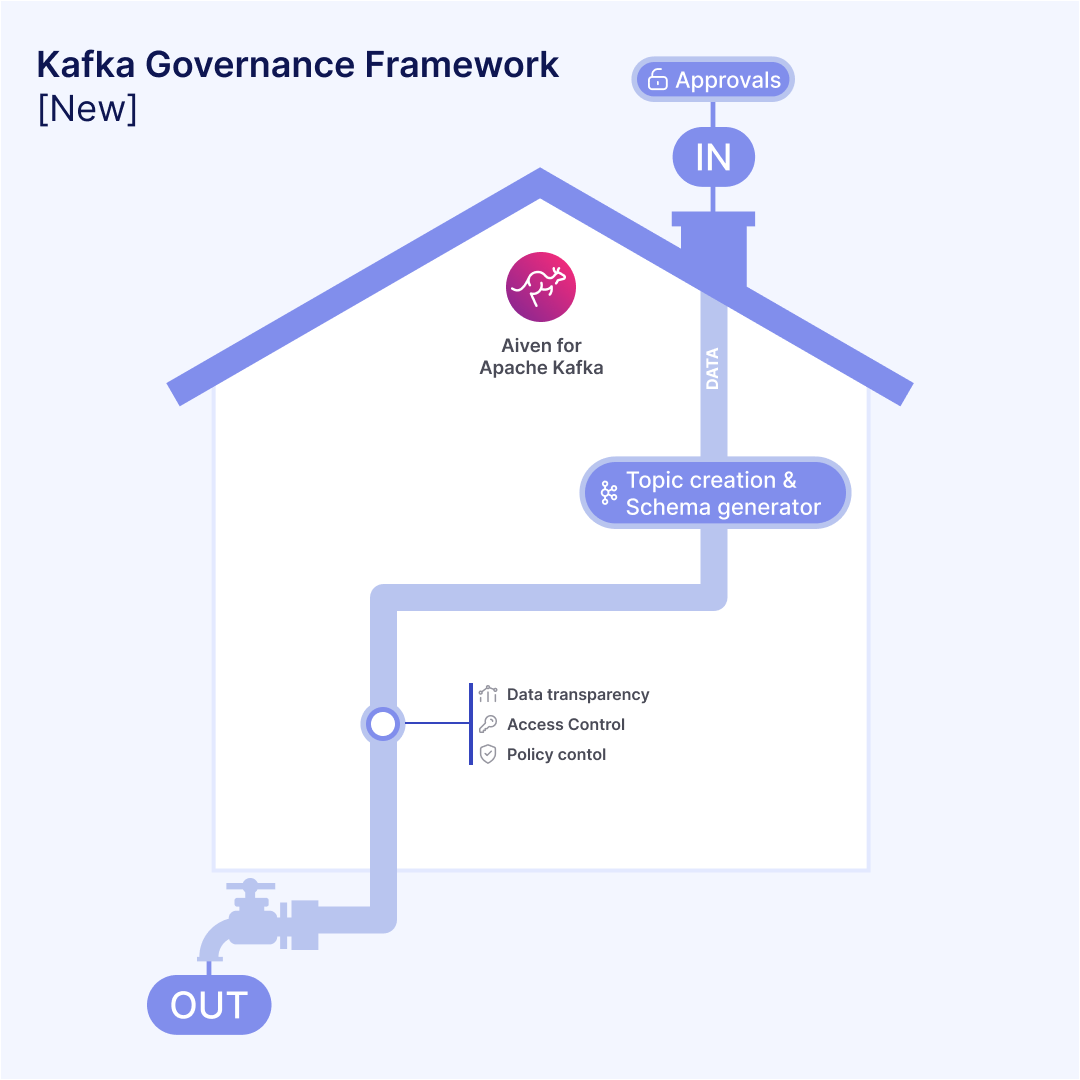
Here’s how we’re making that vision a reality:
Available Now
- The Sample Data Generator: A guided, 30 second experience to create a live, governed and observable data stream. You can access it today from your service’s overview page.
Coming Soon
-
Accelerated Onboarding Wizard. For connecting your own application, this wizard will provide step-by-step guidance for creating service users, offer an AI-enhanced Schema Generator, and provide secure, pre-configured code snippets for your producer and consumer clients.
-
The Aiven Topic Catalog. To help you manage data at scale, this dedicated catalog will transform the UI into a topic-centric hub, providing a single source of truth for all your data streams - with powerful search, filtering, tagging, and lifecycle management tools.
Experience a new default - for free
Finally, did we mention that it’s completely free? Well, it is. Because we don’t believe that trust, reliability and security - the bedrock of data streaming - should have to be bought for a premium. ‘Governed’ is simply the way we do data at Aiven.
Ready to see it in action? Launch your first data stream in seconds with Aiven. Start your Aiven Free Trial | Start Streaming with Aiven Kafka
