



Apache Kafka® has established itself as the integral component of data architectures requiring to stream data or events in real time. At Aiven, we have seen our customers use Apache Kafka in an increasingly diverse range of use cases, handling larger and larger volumes of data. As a result, customers are often searching for cost effective ways to store large volumes of data in Apache Kafka, while at the same time ensuring their growing workloads remain stable and production-grade.
To address the challenges posed by supporting large scale data storage within data and event streaming systems, Aiven has worked with the Open Source Apache Kafka community to add support for Tiered Storage to Apache Kafka. Starting with its public preview in Kafka 3.6, Tiered Storage allows Kafka users to seamlessly store older, less frequently accessed data in lower cost storage. This allows for a dual-tier storage setup, where the local storage tier continues to be used for storing log segments on the Kafka broker nodes, and the remote storage tier uses cloud object storage such as Amazon S3, Azure Blob Storage, or Google Cloud Storage. This allows broker node storage to be reduced in size, saving money and also improving upgrade and migration performance by eliminating the need for large node-to-node data replication operations.
We are excited to offer customers the capability to substantially reduce storage costs in Apache Kafka today by releasing Tiered Storage for Aiven for Apache Kafka. Tiered Storage for Aiven for Apache Kafka is in early availability for existing and new customers using Kafka 3.6.
If you’re interested in experimenting with Tiered Storage for Aiven for Apache Kafka during the early availability period, please contact your Aiven account team. They will provide support and guidance to help you set it up for the Kafka topics of your choice. Services in Early Availability are in beta and Aiven does not recommend their use for production workloads. As with all services launched in Early Availability, the team at Aiven will be collecting feedback and monitoring the stability and performance of Tiered Storage for Aiven for Apache Kafka prior to announcing General Availability and support for production workloads in the imminent future.
How much could you save?
As an example, consider a retailer is preparing to handle increased data volumes during November and December driven by global retail shopping events – Singles Day, Black Friday and the holiday shopping season. The retailer is running an Aiven Business-4 Kafka service on the google-europe-central2 region and their forecast indicates that they need to add 990GB of disk storage. Using on-node storage, this would cost $859 USD per month. In comparison, with Tiered Storage for Aiven for Apache Kafka, the same capacity would cost only $85.50 USD per month - a 90% reduction in storage costs. In addition, the retailer’s technical team no longer needs to operate based on a forecast, with the risk of under or over provisioning their capacity needs.
Tiered Storage for Apache Kafka benefits
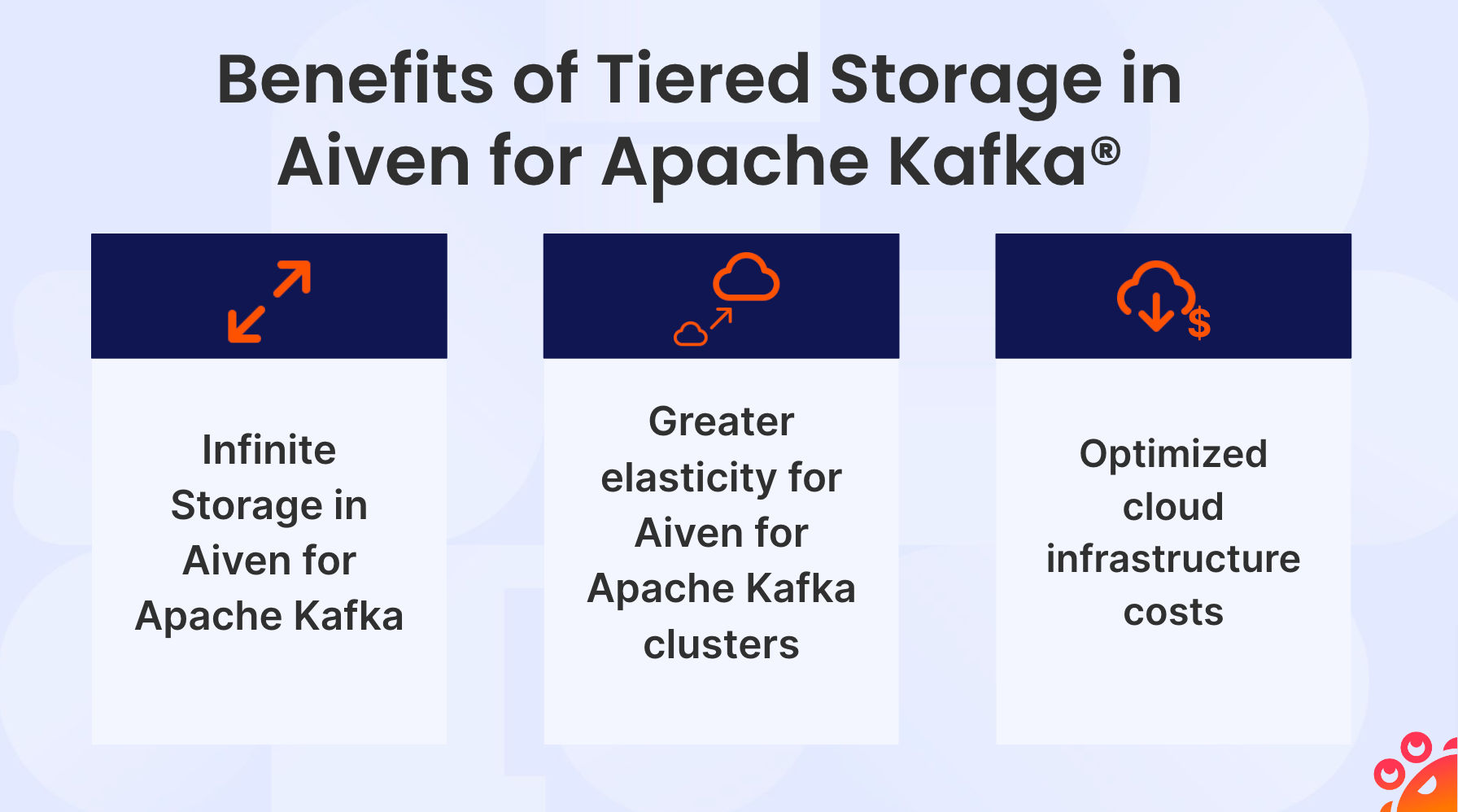
With Tiered Storage in Aiven for Apache Kafka, customers can benefit from:
-
Limitless storage in Aiven for Apache Kafka: Previously, Kafka was usually configured with a retention period (typically around days or a week) bounded by the local disk size. Data older than the retention time was either expired (deleted) or moved to a third-party system, often external storage, for long-term retention. In the first case, older data would be lost, and in the second, applications would need to support two entirely different retrieval mechanisms, depending on the age of the data. With Tiered Storage, Aiven for Apache Kafka becomes a comprehensive storage solution that effortlessly handles real-time and historical data, simplifying customers' application architecture and removing temporal limitations.
-
Greater elasticity for Aiven for Apache Kafka clusters: With all the data stored locally, any scaling or node replacement processes required the entire dataset to be copied from old to new nodes. This can result in time-consuming rebalancing for Kafka clusters. With Tiered Storage, replicating nodes only requires copying the data on the node itself. This means customers benefit from shorter upgrade times and quicker migration between cloud providers.
-
Optimized cloud infrastructure costs: With Tiered Storage for Apache Kafka, customers can decouple their computation from their data storage needs and achieve up to a 50% reduction in their Total Cost of Operation. Customers no longer need to add new Kafka nodes to allow greater data retention. They now only need to do so when they need greater horizontal scaling for performance or durability reasons.
Pricing & Availability
Tiered Storage pricing starts from $0.09 per GB/month, depending on the precise object storage system used. Costs for Tiered Storage are determined by the amount of remote storage used, measured in GB/hour, and will be confirmed when enabling Tiered Storage in the Aiven console. For a detailed explanation of Tiered Storage pricing please check the documentation. Tiered Storage supports cloud storage services from all three hyperscalers – Amazon S3, Google Cloud Storage and Azure Blob Storage.
Tiered Storage in other Aiven services
We're working on adding tiered storage capabilities across our platform. Customers using Aiven for Clickhouse® might be interested in testing out Tiered Storage in their Clickhouse instances right now. Tiered Storage in Clickhouse is currently in limited availability, but you can get in touch with our team today if you’re interested in early access.
How to enable Tiered Storage in Aiven for Apache Kafka
To enable Tiered Storage in Aiven for Apache Kafka for your non-production workloads, please contact your Aiven account team and request that they enable support for Tiered Storage for Avien for Apache Kafka. Once Tiered Storage is enabled, follow these steps:
[1] Navigate to the Aiven console
[2] Access your ‘User Information’ from the top right-hand corner of the console
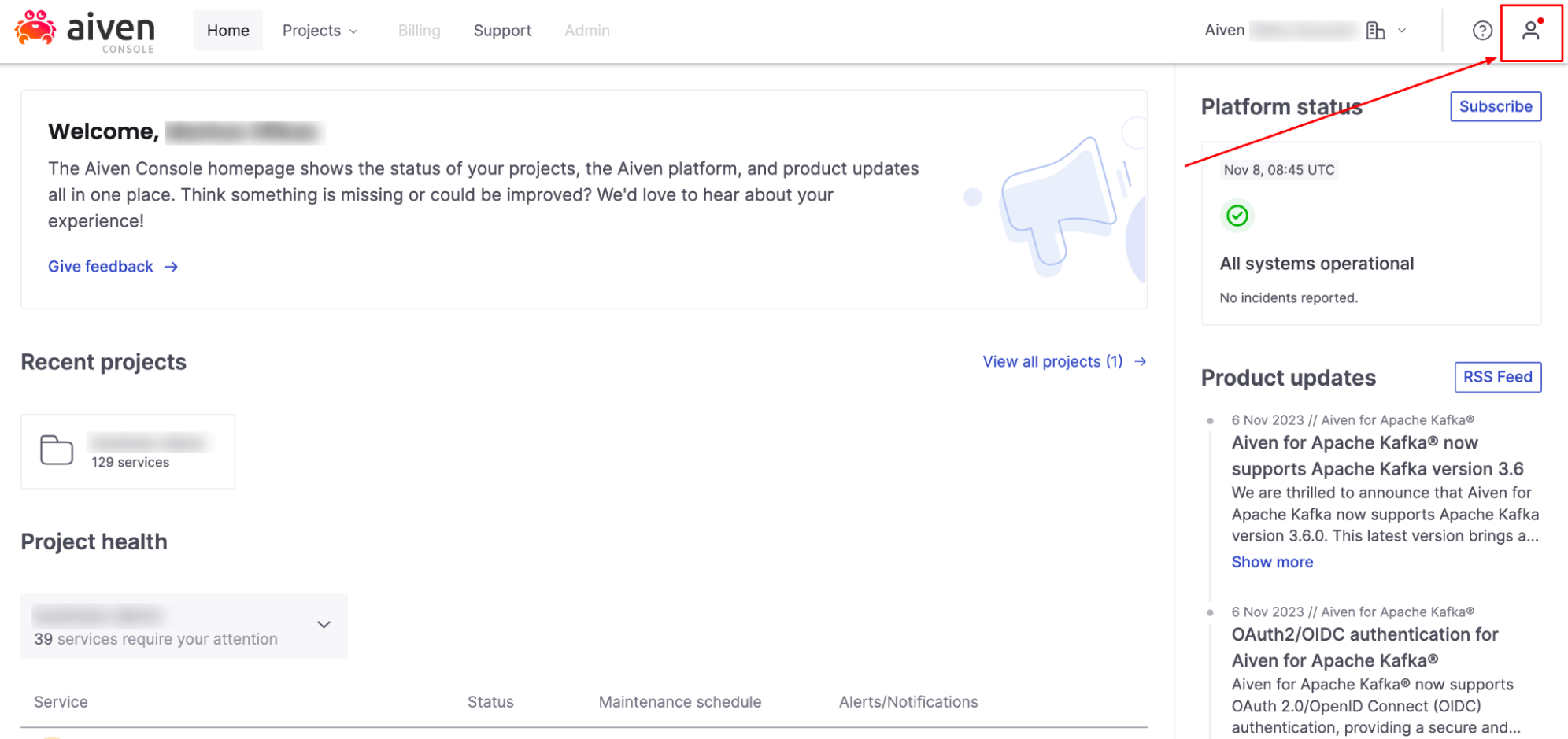
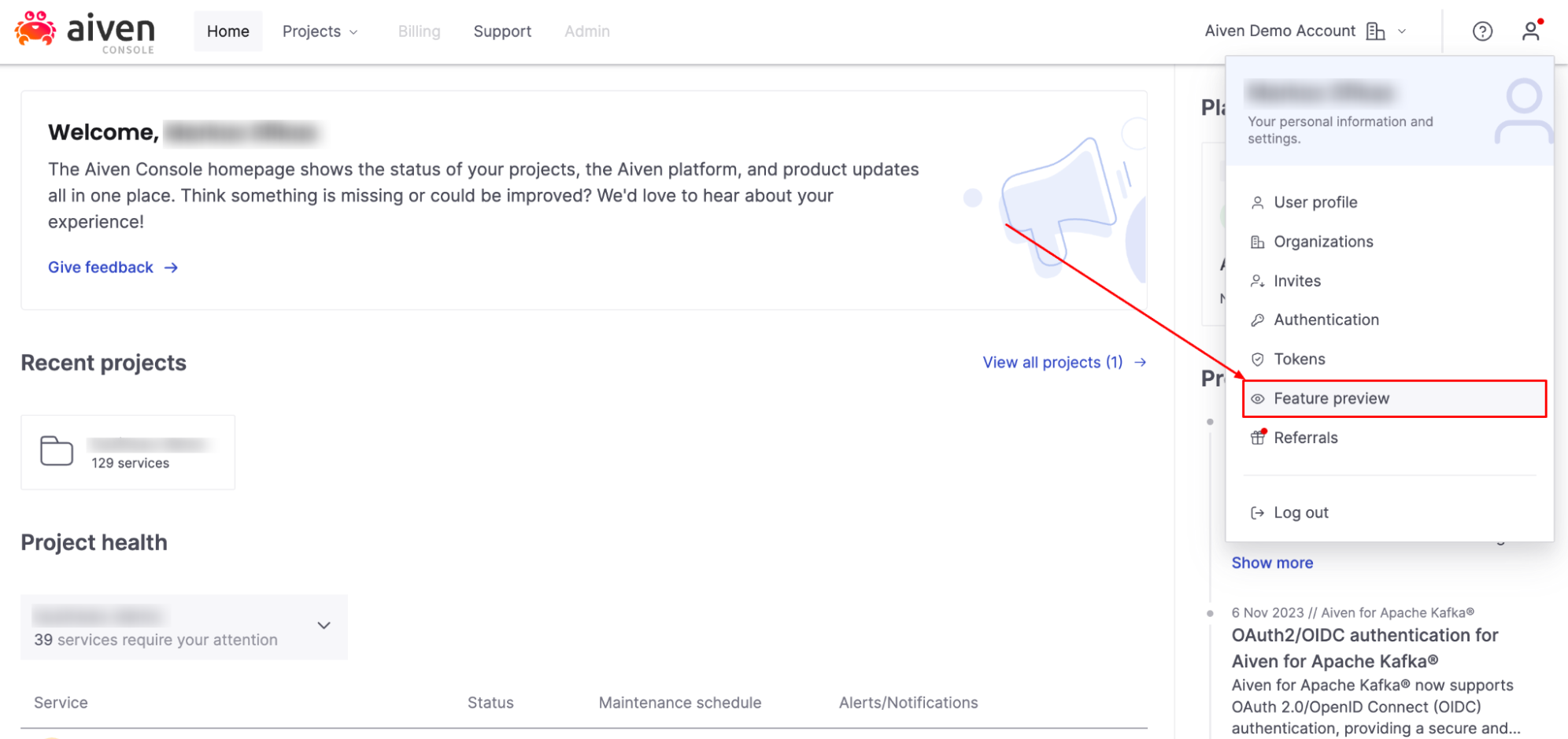
[3] Select ‘Feature preview’ from the drop-down menu
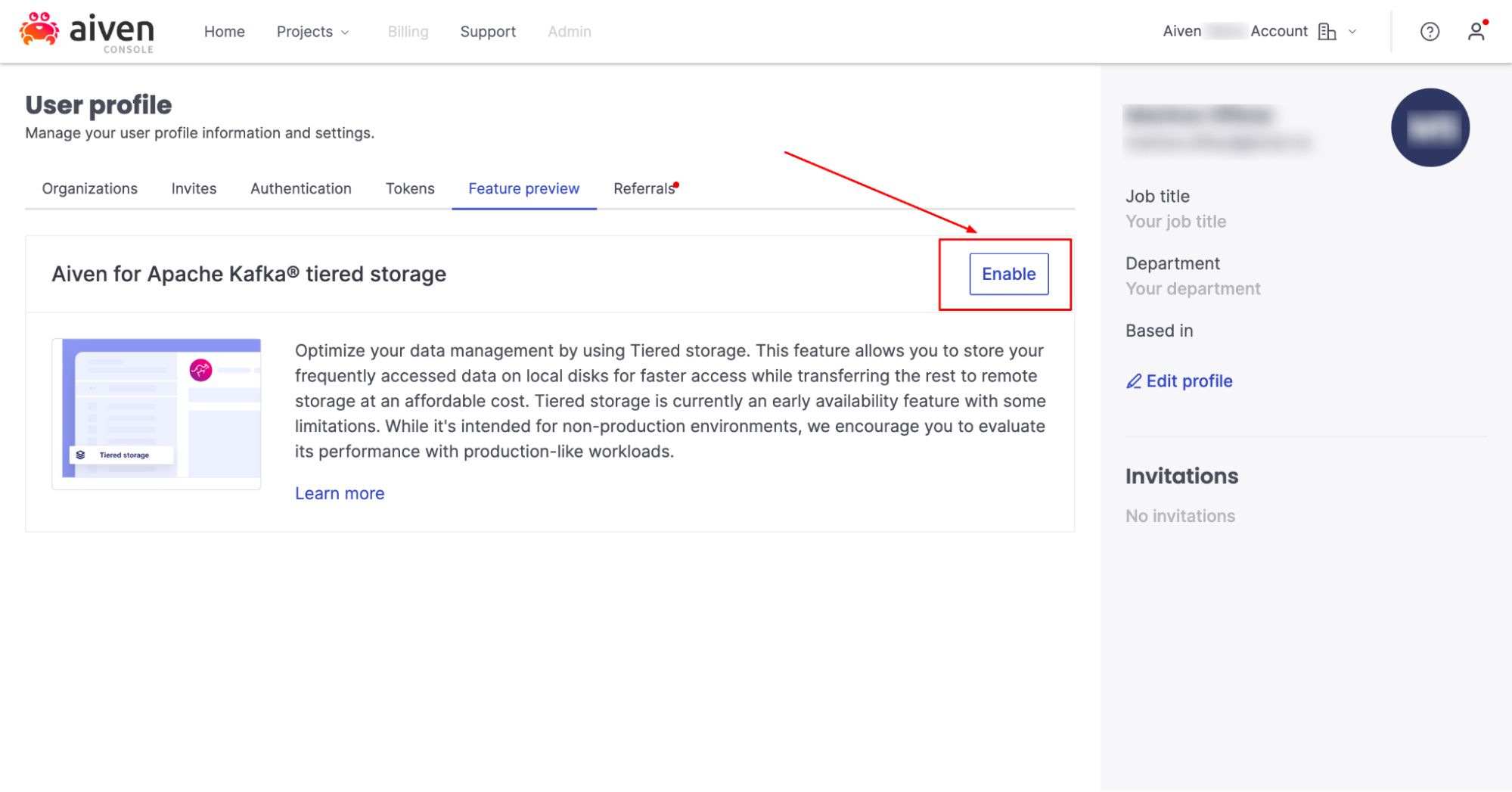
[4] In the ‘Feature Preview’ section click ‘Enable’ in the Aiven for Apache Kafka® tiered storage section
[5] Navigate back to the Aiven Console Home
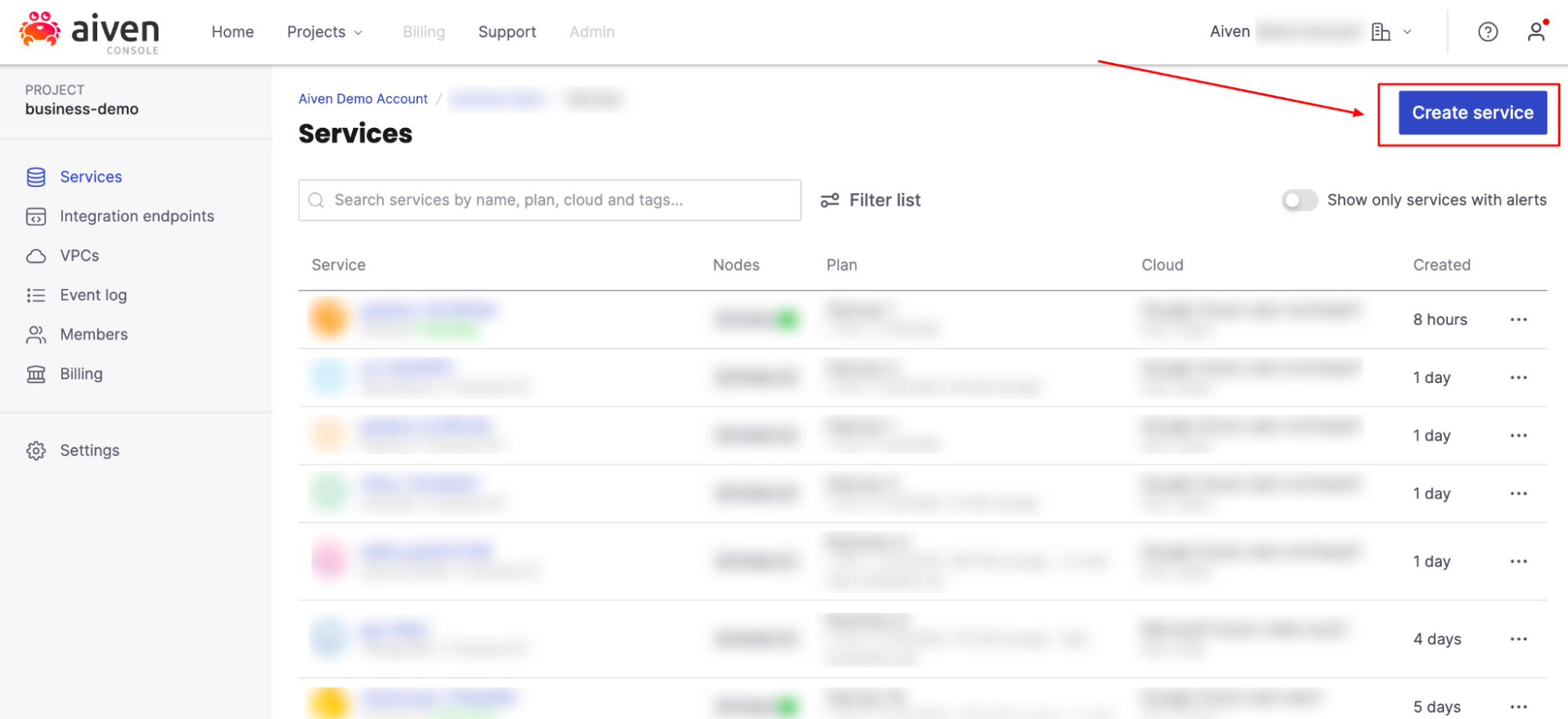
[6] Create a new Kafka service,
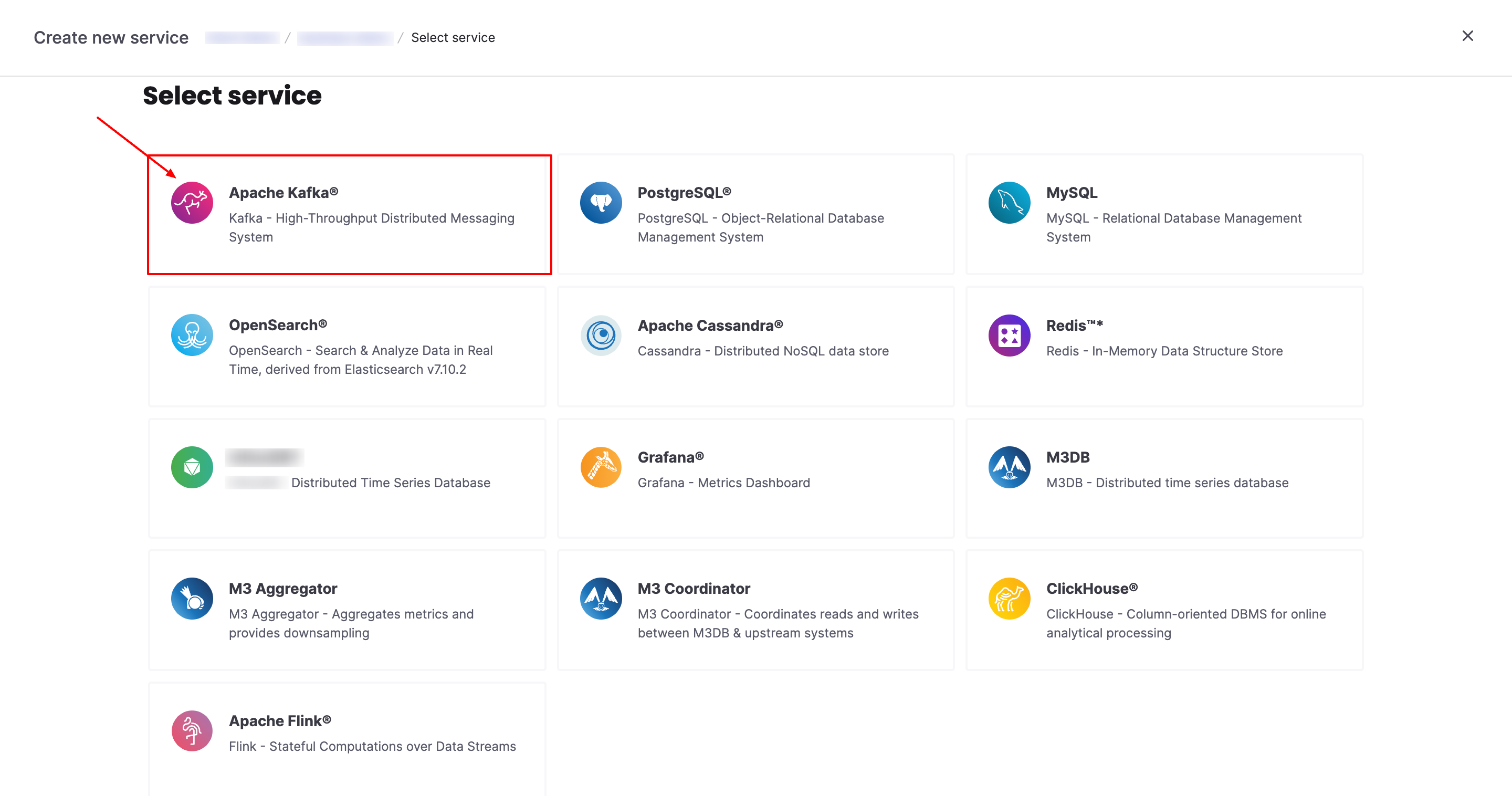
[7] Select Apache Kafka
[8] Select Kafka version 3.6 to be able to use Tiered Storage in Aiven for Apache Kafka:
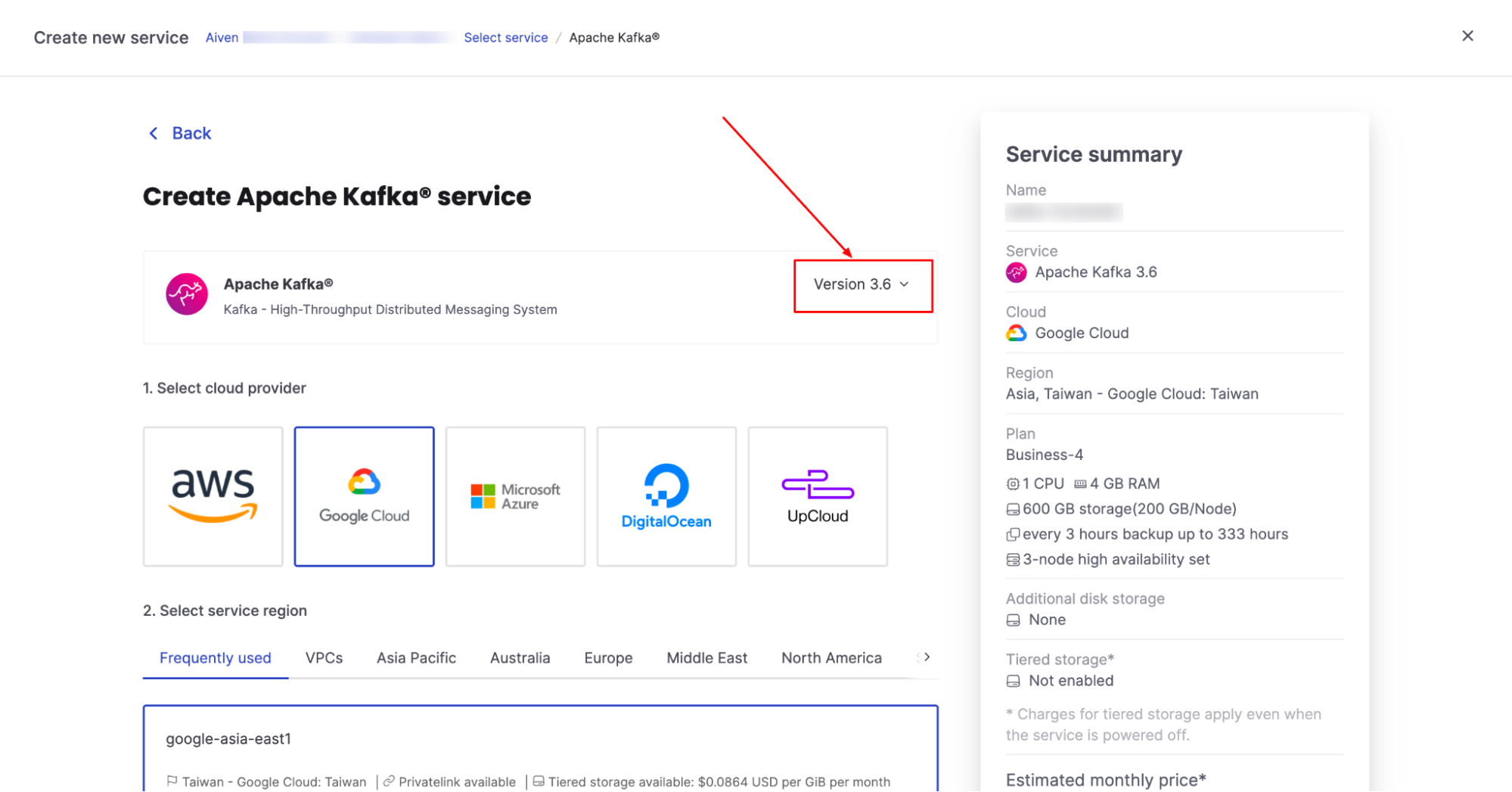
[9] Select your cloud provider, service region, and service plan as normal
[10] As you enabled the Tiered Storage feature preview, there is now an extra option to enable it for this new service. Once activated, the pricing for Tiered Storage is automatically shown in the right-hand column of the Aiven console.
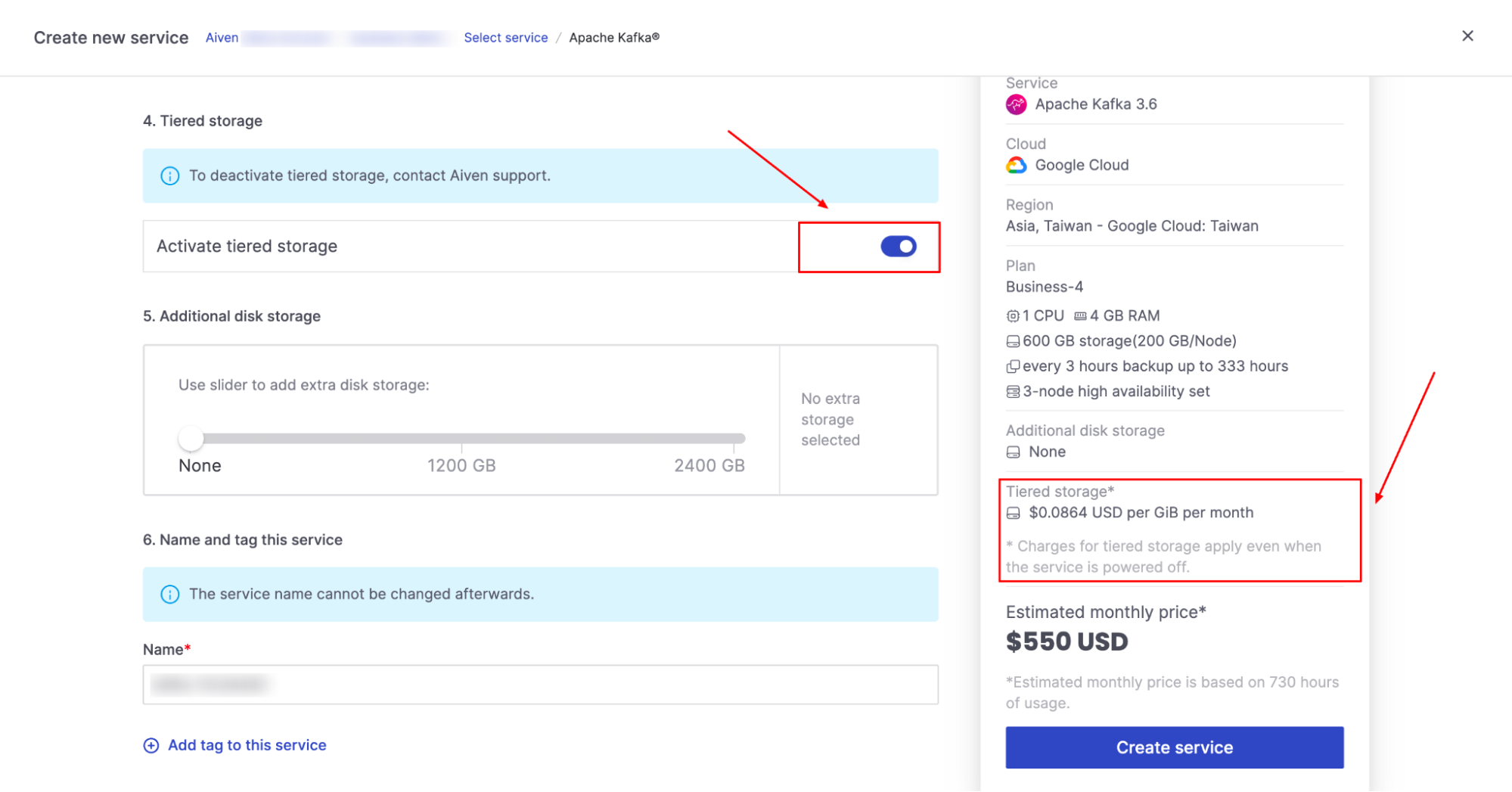
[11] Click ‘Create Service’ and you are all set.
Once activated, deactivating Tiered Storage will cause any data in the cloud storage tier to be lost. To deactivate Tiered Storage while in Early Availability, you need to contact Aiven Support.
Customers trying the feature today will be able to choose tiered data per topic in their Kafka instances and offload older data to Amazon S3, Google Cloud Storage or Azure Blob Storage. You can find out more about how Tiered Storage in Aiven for Apache Kafka works in the corresponding documentation.
If you are new to Aiven, be sure to sign up for a free trial and get first-hand experience using Tiered Storage in Aiven for Apache Kafka. Follow our changelog for the full list of updates on the Aiven platform and future additions to Tiered Storage in the months to come!
