Aug 29, 2025
How Failed Blog Posts and Over-Engineered Demos Revealed PostgreSQL Anonymizer's Secret Power
Beyond data masking, PostgreSQL Anonymizer's superpower is generating schema-accurate, privacy-compliant synthetic data.

Jay Miller
|RSS FeedJay is a Staff Developer Advocate at Aiven. Jay has served as a keynote speaker and an avid member of the Python Community. When away from the keyboard, Jay can often be found cheering on their favorite baseball team.
Set aside the data masking features of PostgreSQL Anonymizer. This plugin can save the day during development by simplifying your workflow and generating schema-accurate, privacy-compliant test data.
In a previous post, we discussed using static and dynamic masking to anonymize data.
I spent the last two weeks trying to write followups for the anonymization posts.
It's time to confess... I'm an over-engineerer. When I need to make a demo environment, I tend to go overboard and engineer a proof of concept that could be vibe-coded into your next startup idea.
With each attempted post, I used PostgreSQL Anonymizer to generate thousands of rows of fake data.
What I learned is this extension, great for masking data, is also fantastic at generating synthetic data from nothing.
It's better to not link to real data
When creating a development or staging environment, you usually don't need the real data. In fact, I would argue that the principle of least privilege (POLP) would require you don't use real data. Unless you change all the data, you can still connect information back to create a profile of actual customers. With just the schema you can generate the fake data. This allows you to develop realistic examples that fit your architecture.
Creating Fake Data and Building Examples
Let's build out a test environment for a school grading system.
My over-engineered example had tables and relationships for students, teachers, the year and semester, as well as classes and subjects, the class assignments, and the student test scores. This developed over time with each pause and the "Well, if I do X, I'll need Y" that easily scope-creeps its way into designs.
Here is a diagram of the setup I originally designed:
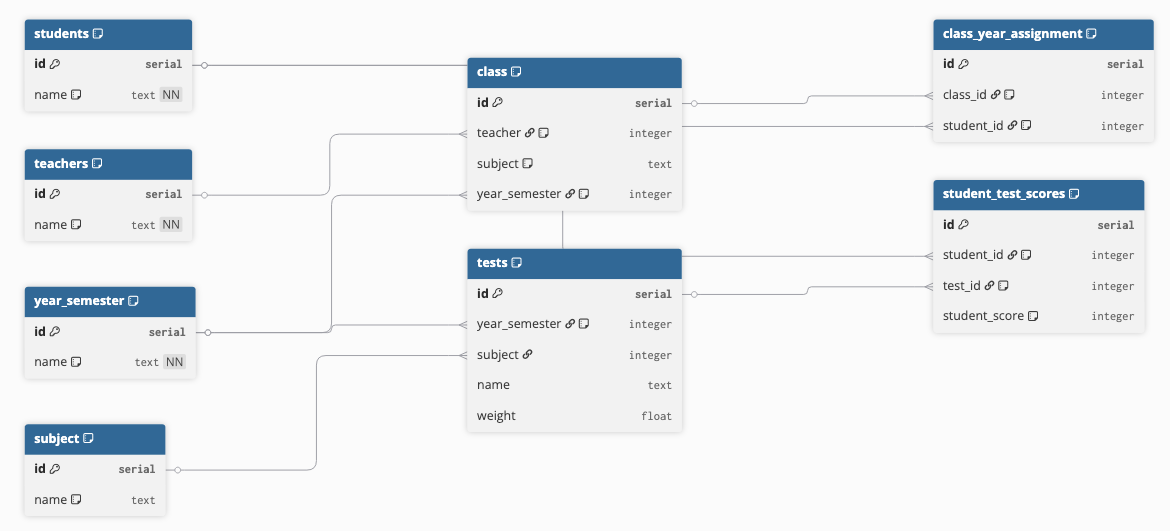
That's a lot. Let's simplify to a single teacher's class. This would be common for a developer only focused on a particular part of the platform. We can limit ourselves at this point to students, tests, and the student_test_scores of a particular class.
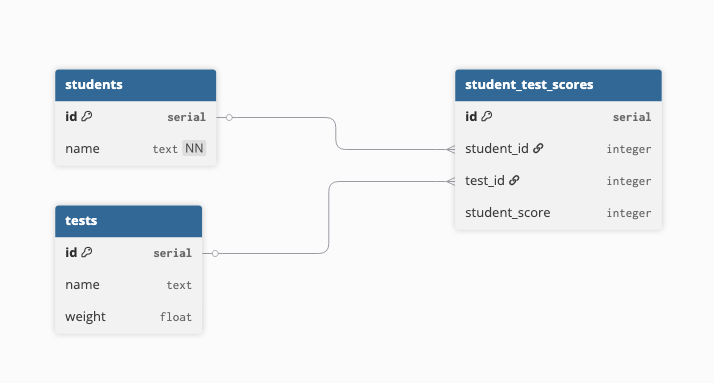
Perfect, the only thing we're missing in this schema design from the main is the year_semester. This information has no effect on what we'd be developing. Now, let's create this simpler design in a testing database.
CREATE DATABASE class_demo; \c class_demo; -- Connect to the class demo database CREATE TABLE students ( id SERIAL PRIMARY KEY, name TEXT NOT NULL ); CREATE TABLE tests ( id SERIAL PRIMARY KEY, name TEXT, weight FLOAT ); CREATE TABLE student_test_scores ( id SERIAL PRIMARY KEY, student_id INTEGER REFERENCES students(id), test_id INTEGER REFERENCES tests(id), student_score INTEGER );
It's important to know that version 2 of PostgreSQL Anonymizer was completely rewritten in Rust. This means that we're able to create countless options ridiculously faster than the previous version which was written in C. In the example below we're generating data for 30 students, but in previous attempts to build a logistic portal for students selling chocolate, I generated 20,000 students in less than a second.
To create names for this we are going to use a dummy_* function. PostgreSQL Anonymizer creates random-but-plausible values. There are over 70 dummy functions that allow you to replace things like names, email address, phone_numbers and more. There are also some localizations for English and French.
We load the engine containing this functions with select anon.init(). When masking data we would utilize the function in a SECURITY LABEL but with generating fake data we will use it with a generate series function. Since our data model just uses name (and not first/last name) we will generate a complete name with the dummy_name() function.
-- Install and configure PostgreSQL Anonymizer CREATE EXTENSION IF NOT EXISTS anon CASCADE; SELECT anon.init(); INSERT INTO students (name) SELECT (anon.dummy_name()) -- creates a first name and family name FROM generate_series(1,30); -- this creates 30 iterations of anon.dummy_name()
We'll also make some tests for our students to take. We will weigh the tests similarly to what a high-school or college class may do. We'll call these tests "test-1, test-2, etc". Though if we had a list of topics we could use anon.random_in(ARRAY['LIST','OF','TOPICS']).
INSERT INTO tests (name, weight) SELECT CONCAT('test', '-', generate_series::TEXT), 0.05 -- usage of CONCAT is great FROM generate_series(1, 8); INSERT INTO tests (name, weight) VALUES ('midterm', 0.3), ('final', 0.3);
Now we need to populate the tests for each student.
Activate over-engineering mode
The simple idea is to generate the first 8 tests at random between 50 - 100. I wanted most students to pass so there is only a 10% chance of failing a test.
The midterms would be based on the average of tests 1-4 with a deviation of about 10%. The final would be the same but using tests 5-8 and the midterm.
Generating numbers in a range
INSERT INTO student_test_scores (student_id, test_id, student_score) SELECT s.id, t.id, CASE WHEN random() < 0.1 THEN anon.random_int_in_range(50, 69) ELSE anon.random_int_in_range(70, 100) END FROM students s CROSS JOIN tests t WHERE t.name LIKE 'test-%';
That function anon.random_int_in_range() is much more understandable than the 50 + random() * 19::INTEGER. I also analyzed the two commands running the commands 5 times, clearing the cache between each run. While the anon calls are usually slower, the difference is negligible, arguably even at scale.
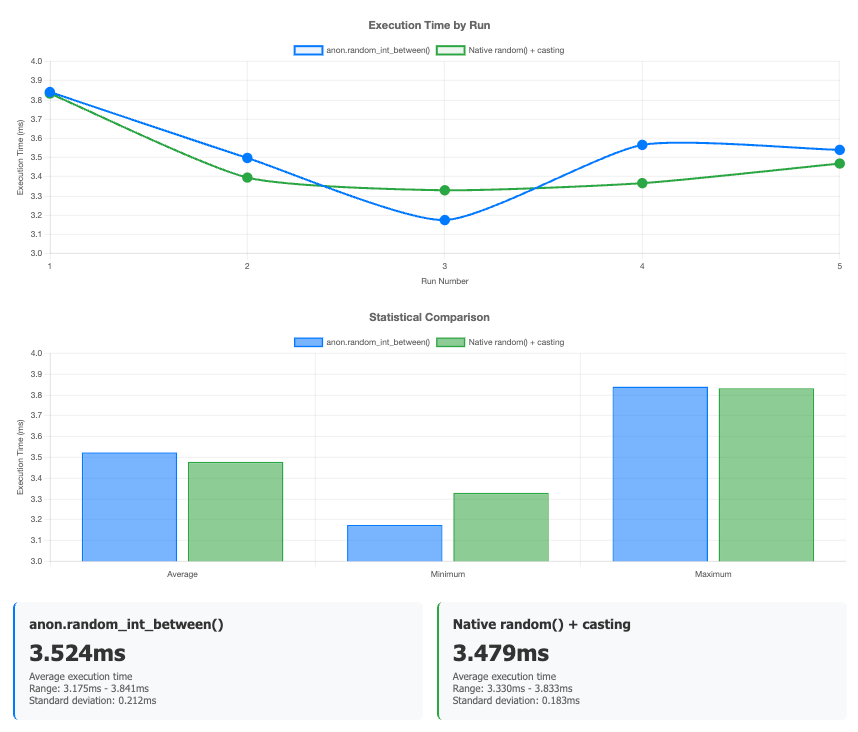
Adding noise
Now we need to generate the calculation of the midterms and finals as well. Let's do the midterm tests. We can use AVG and get the average of the tests. Then we need to add some noise to the average. We can use anon.noise() to accomplish this.
Noise generation is used to add variance to a value. You provide the original value and the percentage noise to add. We will standardize the noise to 10%. That means with an average of 80 your new value would be between 72 and 88.
-- Calculate midterm scores based on first 4 tests with that 10% range INSERT INTO student_test_scores (student_id, test_id, student_score) SELECT s.id, (SELECT id FROM tests WHERE name = 'midterm'), ROUND(anon.noise(avg_score, 0.10)) -- round the average and add noise FROM students s JOIN ( SELECT student_id, AVG(student_score) AS avg_score FROM student_test_scores sts JOIN tests t ON sts.test_id = t.id WHERE t.name IN ('test-1', 'test-2', 'test-3', 'test-4') GROUP BY student_id ) test_averages ON s.id = test_averages.student_id;
We'll do the same for the final exam based on tests 5-8 plus the midterm:
-- Calculate final scores based on tests 5-8 and midterm with noise INSERT INTO student_test_scores (student_id, test_id, student_score) SELECT s.id, (SELECT id FROM tests WHERE name = 'final'), ROUND(anon.noise(avg_score, 0.10)) FROM students s JOIN ( SELECT student_id, AVG(student_score) AS avg_score FROM student_test_scores sts JOIN tests t ON sts.test_id = t.id WHERE t.name IN ('test-5', 'test-6', 'test-7', 'test-8', 'midterm') GROUP BY student_id ) final_averages ON s.id = final_averages.student_id;
If we were making a web application or we needed to give this data to some other platform we could export these results into CSV, or some other data.
We could also create a materialized view based on all the tests of the teachers.
Finally, we can then create a materialized view that shows the final scores.
CREATE MATERIALIZED VIEW student_grades AS SELECT s.name, -- Calculate weighted final grade using actual weights from tests table ROUND( SUM( COALESCE(sts.student_score, 0) * t.weight )::NUMERIC, 2 ) AS final_grade, -- Now Show the test scores from each test MAX(CASE WHEN t.name = 'test-1' THEN sts.student_score END) AS test_1, MAX(CASE WHEN t.name = 'test-2' THEN sts.student_score END) AS test_2, MAX(CASE WHEN t.name = 'test-3' THEN sts.student_score END) AS test_3, MAX(CASE WHEN t.name = 'test-4' THEN sts.student_score END) AS test_4, MAX(CASE WHEN t.name = 'midterm' THEN sts.student_score END) AS midterm, MAX(CASE WHEN t.name = 'test-5' THEN sts.student_score END) AS test_5, MAX(CASE WHEN t.name = 'test-6' THEN sts.student_score END) AS test_6, MAX(CASE WHEN t.name = 'test-7' THEN sts.student_score END) AS test_7, MAX(CASE WHEN t.name = 'test-8' THEN sts.student_score END) AS test_8, MAX(CASE WHEN t.name = 'final' THEN sts.student_score END) AS final FROM student_test_scores sts JOIN students s ON s.id = sts.student_id JOIN tests t ON t.id = sts.test_id GROUP BY s.id, s.name ORDER BY final_grade DESC, s.name;
What I learned from over-engineering
So what started as a simple example turned into complex data generation that models realistic student performance patterns. This is exactly the kind of over-engineering I was trying to avoid, but it taught me something important: PostgreSQL Anonymizer isn't just good at masking existing data--it excels at creating realistic synthetic datasets from scratch.
Also as I mentioned in the previous post, much of this work is to make sure that I can use tools like large language models (LLMs) to receive coding help. Using anon.dummy_name() quickly created our users out of thin air. The anon.random_int_in_range() gave us the ability to create realistic test scores. Lastly, the anon.noise() function created midterms and finals scores that reflected the knowledge from previous tests as well as a boost or boon to simulate studying habits. PostgreSQL Anonymizer, powered by Rust, made our code simpler, more effective without sacrificing performance.
This only scratches the surface as there are many other ways to generate partial and completely synthetic data PostgreSQL Anonymizer.
The real lesson
My failed experiments weren't really failures. With my attempt to build a school fundraiser program, I was able to generate thousands of schools with a formula of
concat(anon.random_in(ARRAY['North', 'South', 'East', 'West', 'Central']), city, school_level, 'School')
and create sales simulations across multiple flavors of chocolate. In my logging example, I made thousands of logs spanning across a day using the anon.dnoise() which is the same as anon.noise(), but allows for datetimes and variations of time intervals.
The principle of least privilege applies here: if you can develop and test with completely synthetic but fitting data that has no connection to real customers, why take the privacy risk of using masked production data at all?
Next time you're setting up a development environment, consider generating your test data rather than copying and masking production data. Your privacy team will thank you, and you might discover that synthetic data gives you more control over testing edge cases than real data ever could.
Plus, you'll have a lot more fun building it, even if you do end up over-engineering it like I did.
Stay updated with Aiven
Subscribe for the latest news and insights on open source, Aiven offerings, and more.


