Mar 30, 2017
Benchmarking Apache Kafka Performance Part 1: Write Throughput
Read our popular post that reviews Apache Kafka's raw write throughput performance in AWS, Azure, Google, and UpCloud.

Heikki Nousiainen
|RSS FeedChief Technology Officer at Aiven
We have offered a fully managed Kafka service for some time now, and we are quite often asked about just how many messages can you pipe through a given service plan tier on a selected cloud. So here's a benchmark we conducted to give you a rough idea on just how well Apache Kafka performs in the public cloud.
This is the first post in a series that explores Kafka performance on multiple public cloud providers.
What is Kafka?
Apache Kafka is a high-performance open-source stream processing platform for collecting and processing large numbers of messages in real-time. It enables you to accept streaming data such as website click streams, events, transactions or other telemetry in real-time and at scale, and serve it downstream to stream processing applications.
Kafka is built distributed for both scalability as well as fault tolerance. Adding more horizontal nodes to tackle growing loads is fairly straightforward and automatic replication of the data over more than one node maintains availability when nodes fail.
The basic concepts in Kafka are producers and consumers.
A producer is an application that generates data but only to provide it to some other application.
An example of a producer application could be a web server that produces "page hits" that tell when a web page was accessed, from which IP address, what the page was and how long it took to render the page by the web server.
On the consumer side there could be multiple systems interested in the same page hit data stream:
- A time series database that is used to plot the total number of page hits over time
- A reporting application collecting summaries of the pages accessed and sending them to a data warehouse database system
- A DDoS detection system trying to find abnormal access patterns
- A rate limiting monitor counting the number of hits from a specific source address
- And so on...
Kafka suits these kinds of applications very well: it provides a method of getting the data out of the hands of the producing application quickly and safely. Once the producer has written the message to Kafka, it can be sure that its part of the job is done. The producer application does not need to know how the data is used and by which applications, it just stores it in Kafka and moves on.
On the consumer side a powerful feature of Kafka is that it allows multiple consumers to read the same messages. In our web page hit example above, each of the consumer applications get their own read cursor to the data and they can process the messages at their own pace, all without causing any performance issues or delays for the producer application.
Here's what it roughly looks like:
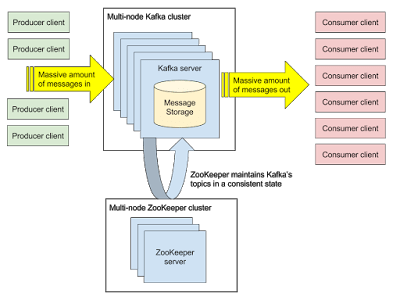
The Zookeeper cluster is a critical piece in keeping Kafka healthy and up and running. It maintains Kafka's metadata and most importantly, a consensus between the Kafka nodes of who is doing what.
Aiven Kafka as a Service
Aiven Kafka is a a fully managed service based on the Apache Kafka technology. Our aim is to make it as easy as possible to use Kafka clusters with the least amount of operational effort possible. We handle the Kafka and Zookeeper setup and operations for you, so you can focus on value-adding application logic instead of infrastructure maintenance. Aiven Kafka services can be launched in minutes, and we'll ensure they remain operational, well performing, up-to-date and secure at all times. Nodes are automatically distributed evenly across the available availability zones in order to minimize the impact of losing any of the zones.
Aiven Kafka is available in Amazon Web Services, Microsoft Azure, Google Cloud Platform, UpCloud and DigitalOcean with a total coverage of 53 cloud regions. In this performance comparison we ran the benchmark on all of these except DigitalOcean, where our Kafka offering is limited by the available plans.
Each Kafka service used in these tests is a regular Aiven-provided service with no alterations to its default settings.
Benchmark Setup
In this first Kafka benchmark post, we set out to estimate maximum write throughput rates for various Aiven Kafka plan tiers in different clouds. We wanted to use a typical customer message sizes and standard tools for producing load. We also wanted to generate the load from separate systems over the network to make sure the load could mimic the actual customer workloads as closely as possible.
High-level view of the test setup, a single Aiven Kafka service with five nodes, distributed evenly over the availability zones:
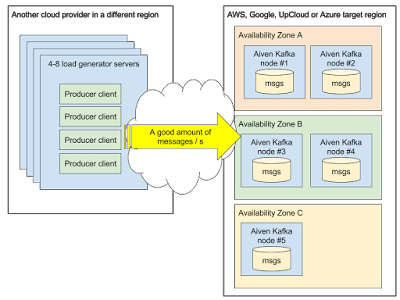
We picked message size of 512 bytes for our tests. Based on our experience, one of the most typical payloads is a JSON encoded message ranging somewhere between 100 bytes to 10 kilobytes in size.
In these tests, we use a single topic with the partition count matching the node count of each Aiven plan tier. For more complex topic/partition setups Aiven actively balances the placement of the partitions, trying to achieve a "perfect" distribution of partitions. In the case of this test there is just a single partition for each node, so this is rather simple. We set the replication factor to one (1) in the case of this test, meaning each of the messages only resides on a single Kafka node.
Apache Kafka version used was 0.10.1.1.
For load generation, we chose to use librdkafka and rdkafka_performance from the provided examples. We are using default settings for the most part, but bumped up single request timeout to 60 seconds as we expect the Kafka brokers to be under extreme load and request processing to take longer than under a normal healthy load level. Also, since Aiven Kafka services are offered only over encrypted TLS connections, we included the configuration for these, namely the required certificates and keys.
librdkafka defaults to a maximum batch size of 10000 messages or to a maximun request size of one million bytes per request, whichever is met first. In these tests, we did not employ compression.
producer.props configuration:
metadata.broker.list=target-kafka.benchmark.aivencloud.com:10947 security.protocol=ssl ssl.key.location=client.key ssl.certificate.location=client.crt ssl.ca.location=ca.crt request.timeout.ms=60000
We ran several instances of rdkafka_performance on multiple VMs on a different cloud provider from the one being tested. So all of the test load was coming from the internet thru the nodes' public network interfaces.
We kept increasing the number of instances until we could find the saturation point and the maximum message rates for each plan.
Each rdkafka_performance instance was started on the command line with:
rdkafka_performance -P -s 512 -t target-topic -X file=producer.props
Benchmark Results
First set of tests was run on an Aiven Kafka Business-4 plan, which is a three node cluster and a common starting point for many of our customers. Each node in this plan has 4 gigabytes of RAM, a single CPU core and 200 gigabytes of disk on each node, providing a total 600 gigabytes of raw Kafka storage capacity in the cluster.
Write performance (3 nodes @ 4 GB RAM, 1 CPU, 200 GB disk each):
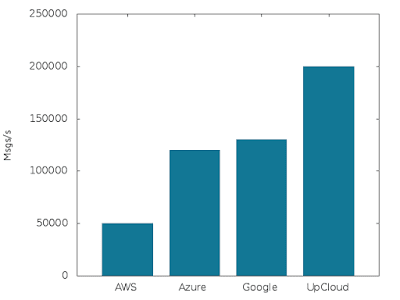
On UpCloud, we hit 200,000 messages per second. Azure and Google plans saturated at 120,000 and 130,000 messages per second and the Amazon deployment reached 50,000 messages per second.
The performance is pretty respectable. The performance on Amazon is a bit behind the others because of the node types available and we will be looking at ways to optimize that in the future. As you will see in the next graph for the test with the bigger plan, the AWS performance is already more in line with the other providers.
Next, we tested three node clusters but with larger underlying instances using the Business-8 plan. This plan has nodes with 8 gigabytes of RAM, two CPU cores and 400 gigabytes of disk per node, i.e. all the primary resources are doubled when compared to the Business-4 plan. This test indicates how well Kafka scales vertically with increased resources.
Write performance (3 nodes @ 8 GB RAM, 2 CPU, 400 GB disk each):
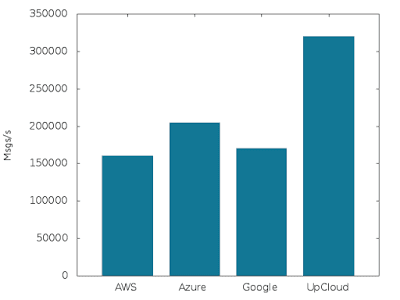
We see a nice increase in performance, with 320,000 messages per second on UpCloud, 205,000 on Azure, 170,000 on Google and 160,000 messages per second on AWS.
In the last test, we wanted to verify how well Kafka scales horizontally. With this test, we went from the Business plan tier to the Premium tier, which bumps the node count from three to five, while keeping the node specs otherwise identical. Also the test setup was updated to utilize a partition count of five (vs. three) for this test.
Write performance (5 nodes @ 8 GB RAM, 2 CPU, 400 GB disk each):
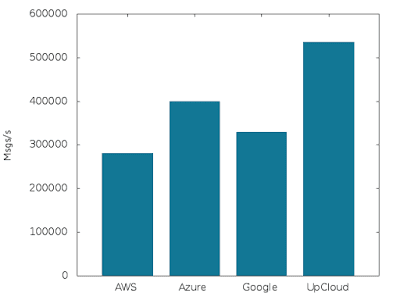
The results here are solid for Kafka: a two-thirds increase in the number of nodes resulted in a straight 2/3 increase in write performance. Awesome!
Aiven Kafka Premium-8 on UpCloud handled 535,000 messages per second, Azure 400,000, Google 330,000 and Amazon 280,000 messages / second.
Benchmark Conclusions
Apache Kafka performs just as well as we expected and scales nicely with added resources and increased cluster size. We welcome you to benchmark your own workloads with Aiven and to share your results.
We utilize Kafka as a message broker within Aiven as well as use it as a medium for piping all of our telemetry metrics and logs. We are happy with with our technical choice, and can recommend Apache Kafka for handling all kinds of streaming data.
Find out more about Aiven Kafka at aiven.io/kafka.
Further reading
Stay updated with Aiven
Subscribe for the latest news and insights on open source, Aiven offerings, and more.


