Aug 6, 2024
Reverse your ETL: Stream BigQuery data to Aiven for Apache Kafka® with continuous queries
BigQuery continuous queries enable the reverse ETL pattern. You can now stream your enriched data from BigQuery back to the operational data layer using Aiven for Apache Kafka®.


BigQuery enables customers to quickly generate insights about their data. Its native integration with AI tools allows organizations to transform row assets into valuable information that can be used to generate more accurate decisions, streamlining companies' growth.
Traditionally, these insights would only have been available to operational workflows using a batch approach, causing a delay between when the insight is created and when it can be used. Now there's a native option to bring this enhanced data back to streaming workflows with BigQuery continuous queries.
This allows companies to benefit from curated and enriched BigQuery datasets in real time, feeding the data into streaming tools like Aiven for Apache Kafka®, which makes the enriched information available to downstream systems.
Aiven's data and AI platform provides unified solutions for handling data, and is a great complement to the use of Google BigQuery. Aiven for Apache Kafka is the natural choice for ingesting streaming data and delivering them to downstream data solutions in real time, including BigQuery. Until recently getting data from BigQuery back into the Aiven platform required batch techniques. Now, with continuous query, the loop is closed, and Aiven and BigQuery can act as fully integrated partners. You can start a free Aiven trial directly in the Google Marketplace.
With continuous queries, Google introduces the ability to extract real time data from Google Cloud BigQuery. The data can be written back out to Google Pub/Sub and then to Apache Kafka, enabling the Reverse ETL pattern and allowing users to get real-time insights into their BigQuery data.
What is Reverse ETL?
The ETL (extract, transform, load) pattern is a powerful approach used to take operational data and make it available in analytics storage such as Google Cloud BigQuery.
Aiven customers are familiar with using Apache Kafka® as a key component in this pattern. The Extract typically uses an Apache Kafka Connector to extract data from a data source such as Aiven for PostgreSQL®, Aiven for Opensearch® or Aiven for Valkey. Transform describes the schema and data refinement stage, adjusting the data to a form suitable for Load into BigQuery itself. BigQuery is chosen because of its sophisticated capabilities and scalability, and can be thought of acting as a data warehouse as well as a powerful analytics engine.
Typical use cases include Retail, E-commerce and Gaming. For more information, see last year’s article Shorten the path to insights with Aiven for Apache Kafka and Google BigQuery.
Reverse ETL is then the process that allows extracting information from analytics storage, generally into business applications, in order to feed downstream applications with the insights obtained from the analytics platform.
Reverse ETL is a powerful tool to leverage data in operational systems for enhanced decision making and improved customer experiences. It democratizes data and makes insights available to non-technical users directly in their operational tools, like CRMs, marketing automation platforms, or support ticketing systems, enabling them to make data-driven decisions without relying on data teams. For example, sales and marketing teams can access a 360-degree view of customers, including purchase history, website interactions, and demographic data, leading to more personalized campaigns and targeted communication.
What is BigQuery continuous queries?
BigQuery continuous queries provide customers with the ability to run continuously processing SQL statements that can analyze, transform, and externally replicate data as new events arrive into BigQuery in real time. This approach extends BigQuery’s real-time capabilities to handle continuous streams of input, analysis, and output; which can be leveraged to construct event-driven actionable insights, real-time machine learning inference, operational reverse ETL pipelines, and more. You can insert the output rows produced by a continuous query into a BigQuery table or export them to Pub/Sub or Bigtable.
This essentially transforms BigQuery from the analytical data sink at the end of data’s architectural journey into an operational and event-driven data processing engine in the middle of an application’s decision logic, all using the user-friendly language of SQL.
How Aiven users benefit from this integration
Aiven users already benefit from the Aiven platform’s stream, store and serve approach.
They are already using Kafka as a backbone to move data between systems, such as PostgreSQL, MySQL, OpenSearch and Valkey. Until now, it has been possible to stream data from Kafka to BigQuery, but not to stream it out. The new capability fills that gap, allowing Google BigQuery users to take full advantage of the Aiven Platform.
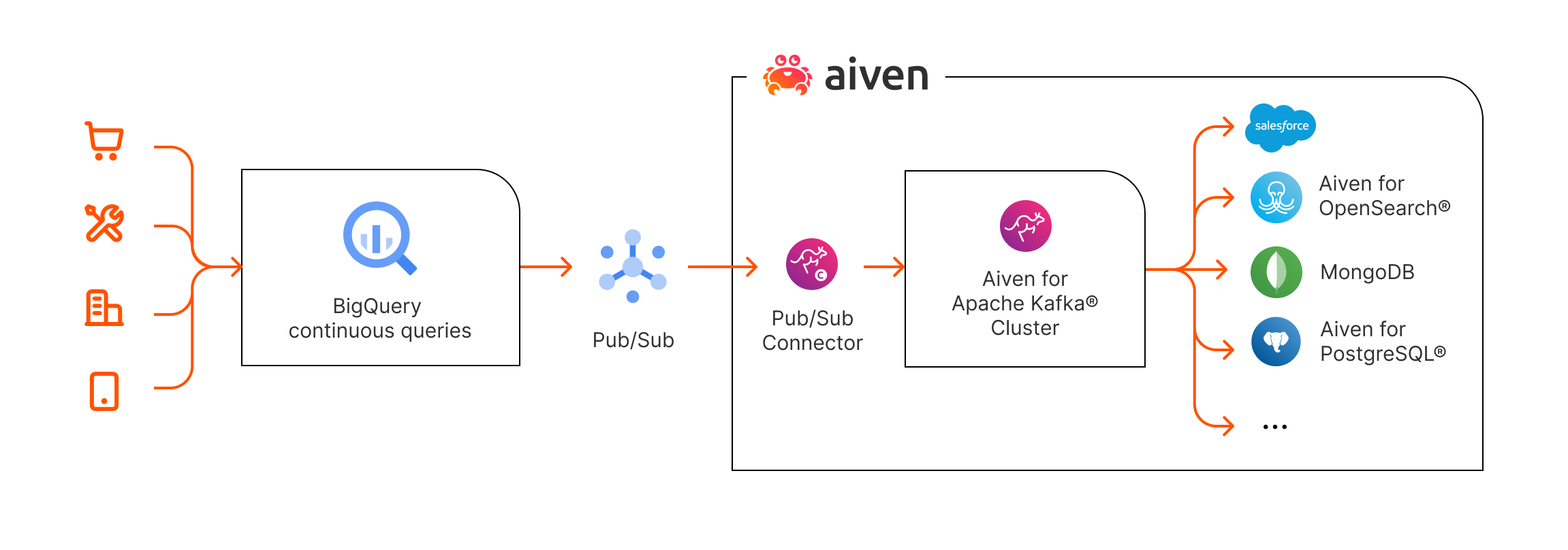
How BigQuery continuous query works with Aiven for Apache Kafka
-
Aiven for Apache Kafka Connect uses a service account to connect and consume data from Pub/Sub, you can configure a single service account for running continuous queries and consume from Pub/Sub by assigning relevant permissions to the user. You can configure the service account with permissions listed here. Make sure you create a JSON key to configure the connection in Aiven in the later step.
-
To run continuous queries, BigQuery requires a slot reservation with a “CONTINUOUS” assignment type. Follow steps here if you are not sure how to create a reservation.
-
Navigate to the Pub/Sub topic page and click on the “Create Topic” button on the top center of the page, and provide a name (say ‘continuous_query_topic’, also create a default subscription if needed).
-
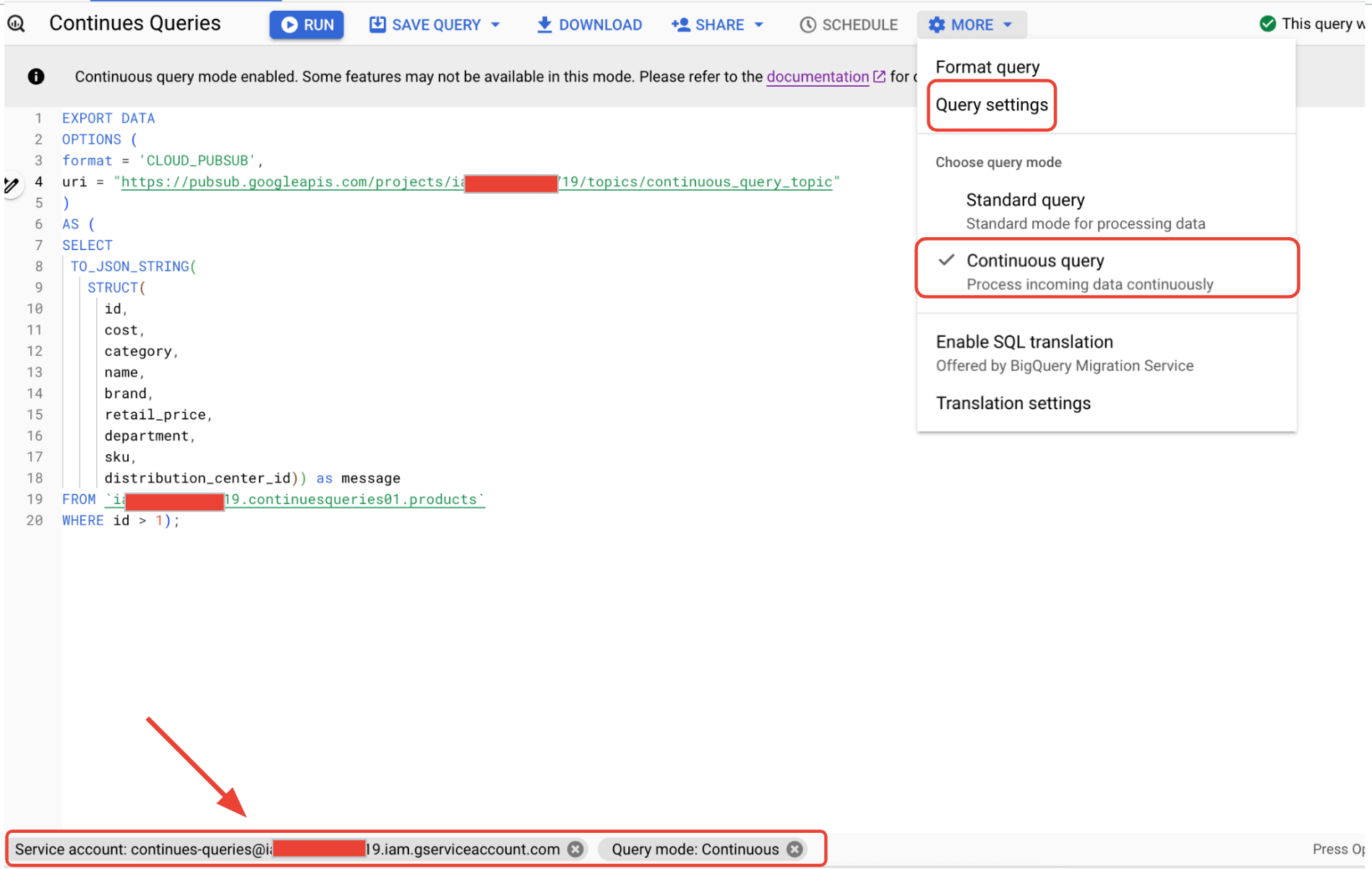
Navigate to the BigQuery service page and design the query as an export to pub/sub.
EXPORT DATA OPTIONS ( format = 'CLOUD_PUBSUB', uri = 'https://pubsub.googleapis.com/projects/<your project_id>/topics/continuous_query_topic' ) AS ( <Your Query> );In the More Settings as shown below, select the query mode as continuous query and in the query settings select the service account created above to run the query. You can also choose the timeout required, if any.
Before executing the query, make sure the below steps are done to ensure data continuously generated can be captured by the Aiven Pub/Sub connector.
-
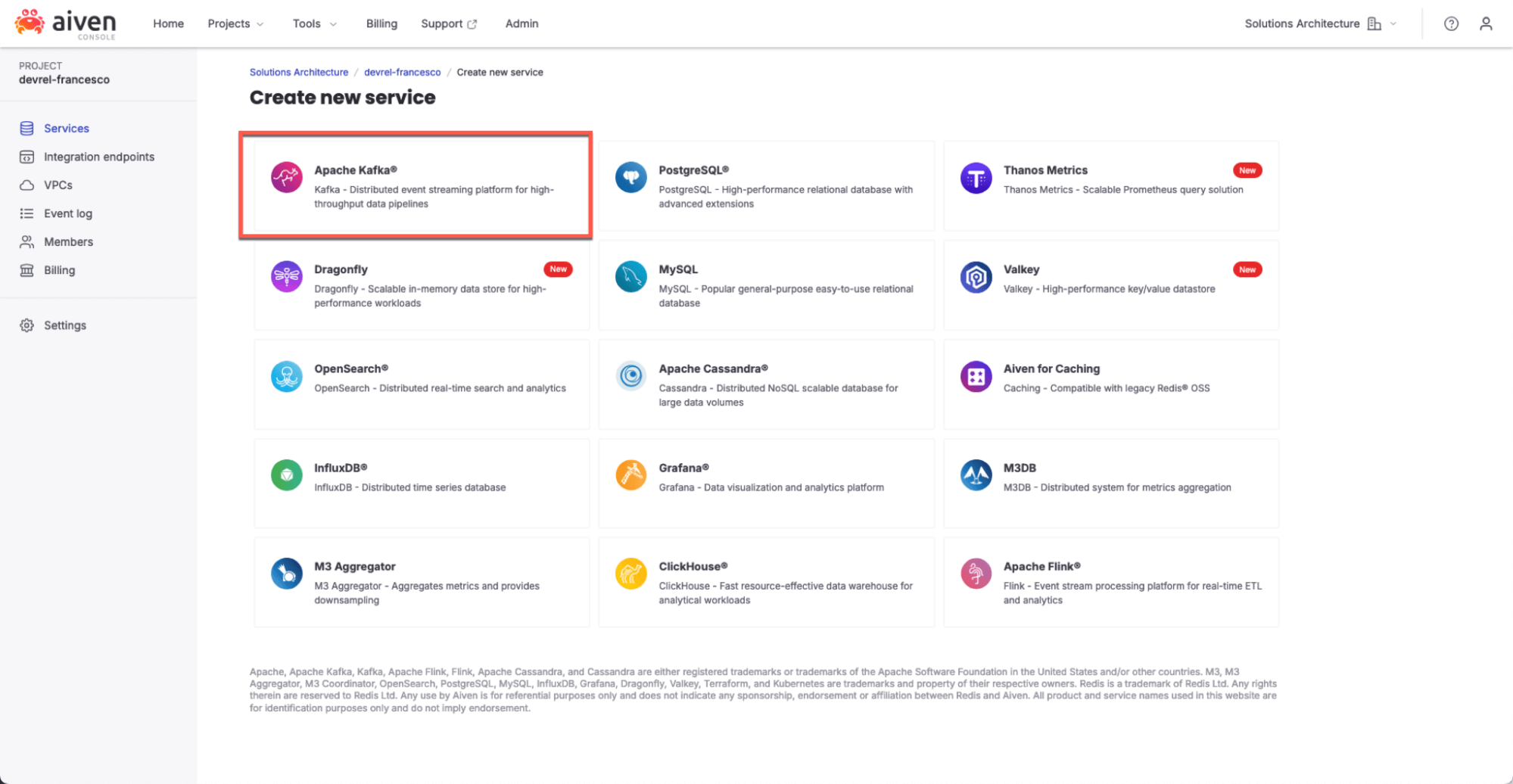
Once logged into the Aiven console, create an Aiven for Apache Kafka service.
-
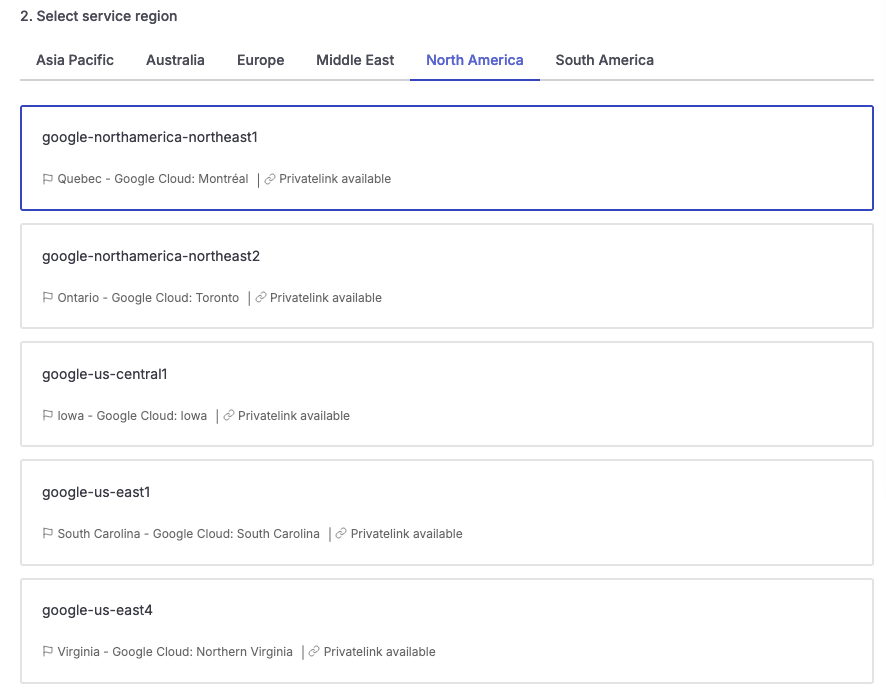
Select the Google Cloud region most convenient for your use case.
-
Choose a suitable service plan. For the purposes of this blog we are using a
business-4plan since it will allow us to start Kafka Connect on the same nodes. -
Click on “Create Service”.
-
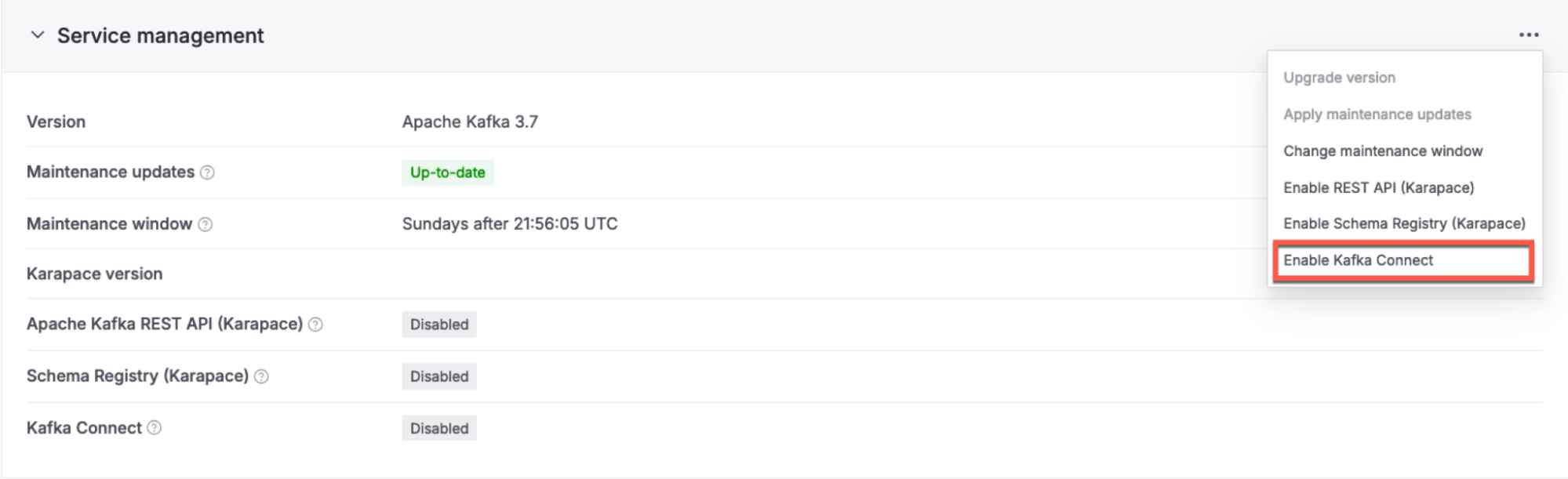
Enable Kafka Connect on the same nodes where Kafka is running:
- Navigate to the “Service Settings”
- Locate the “Service Management” section
- Click on the hamburger menu on the top right and select “Enable Kafka Connect”
-
Enable Kafka REST API (Karapace) in the same “Service Management” section as step 9. This will allow us to browse the data landing in Apache Kafka directly from the Aiven Console.
-
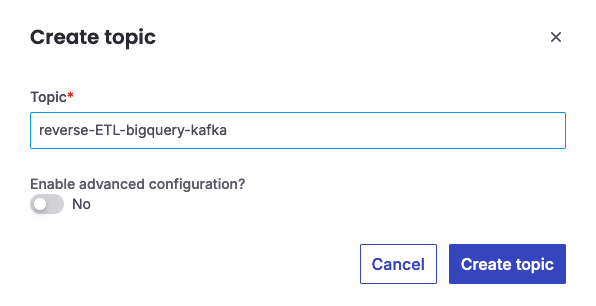
Verify the service is in
RUNNINGstate and navigate to the Topics section to create a topic calledreverse-ETL-bigquery-kafka. -
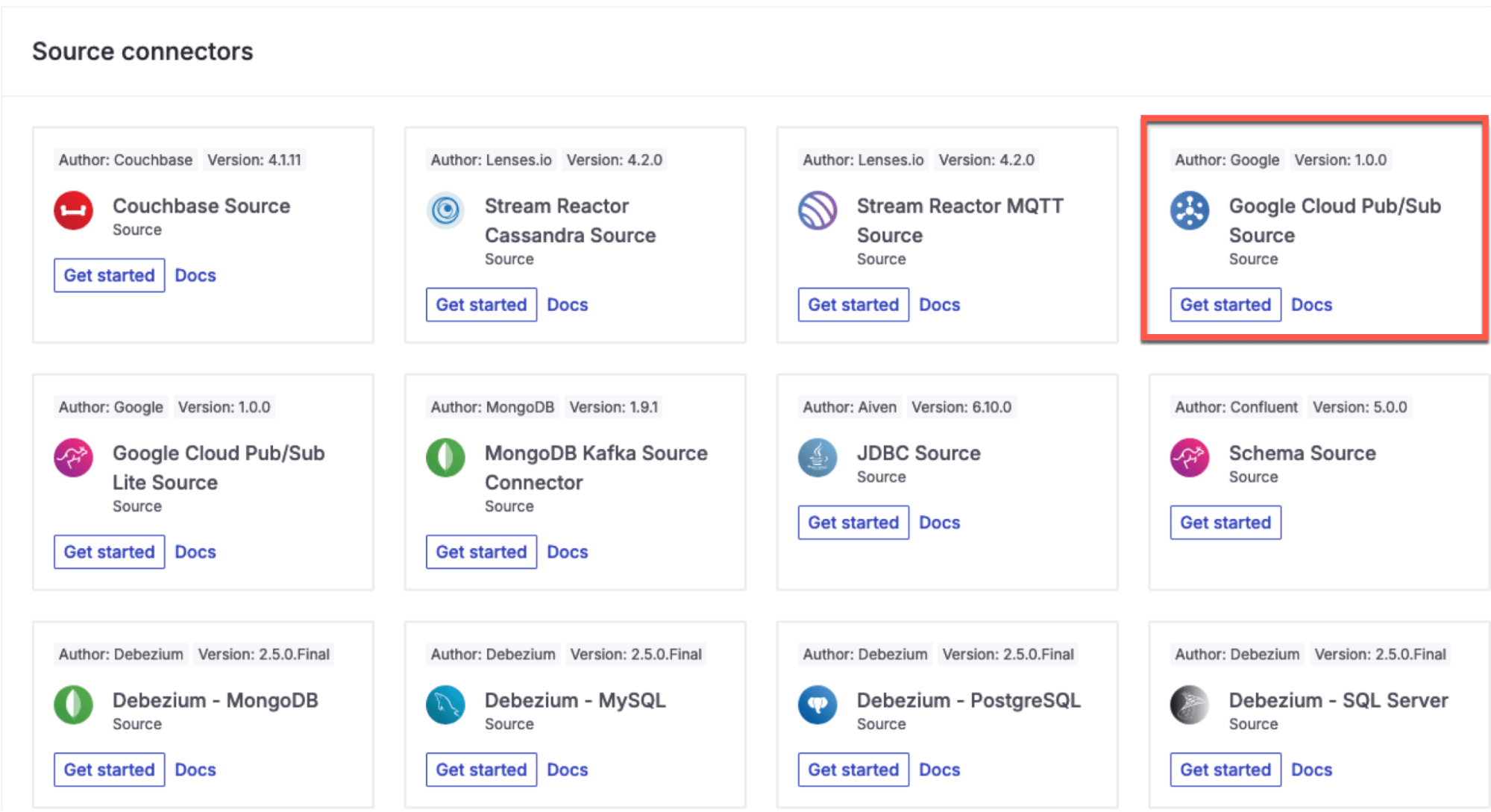
Navigate to the “Connectors” section and Click on See all connectors. Then locate the Google Cloud Pub/Sub Source connector and click on Get Started.
-
In the Connection configuration section, substitute the JSON with the following:
{ "name": "reverse-ETL-bigquery-kafka", "kafka.topic": "topic-name", "cps.project": "gcp-project-name", "cps.subscription": "continuous_query_topic-sub", "gcp.credentials.json": "KEY" }Where:
name: is the Kafka Connect connector namekafka.topic: is the target topic namecps.project: is the GCP project namecps.subscription: is the Google Pub/Sub subscription namegcp.credential.json: is the GCP credential file in JSON format
-
Once the Apache Kafka Pub/Sub connector starts up, you can navigate to BigQuery and run the continuous query defined above. You should start seeing the messages arriving in the Kafka topic defined in the connector.
-
Once the data lands in the Apache Kafka topic, you can read it in streaming mode with dedicated consumers or create sink connectors to push the events into downstream applications as your use case demands.
Conclusion and Next Steps
The ability to extract data from BigQuery in near real time, and combine it with the streaming capabilities of Apache Kafka, allows customers to maximize the impact of using BigQuery for insights and effect.
For those already using Kafka and BigQuery in an ETL workflow, the additional capabilities provide Reverse ETL, closing the data loop.
Learn more about Google Cloud BigQuery, continuous queries and exporting data to Pub/Sub.
If you would like to experience this for yourself, click here to check out Aiven’s listing on Google Cloud Marketplace or sign in to your Google account.
You can also visit Aiven for Apache Kafka to discover the features, plans, and options available for a managed Apache Kafka service.
Stay updated with Aiven
Subscribe for the latest news and insights on open source, Aiven offerings, and more.