Ways to balance your data across Apache Kafka® partitions
When it comes to making a performant Apache Kafka® cluster, partitioning is crucial. Read this article to learn which tools you can use to partition your data.
When it comes to making a performant Apache Kafka® cluster, partitioning is crucial. Read this article to learn which tools you can use to partition your data.
Apache Kafka® is a distributed system. At its heart is a set of brokers that stores records persistently inside topics. Topics, in turn, are split into partitions. Dividing topics into such pieces allows storing and reading data in parallel. In this way producers and consumers can work with data simultaneously, achieving higher throughput and scalability.
This makes partitions crucial for a performant cluster. Reading data from distributed locations comes with two big challenges:
Below we look deeper into these challenges and mechanisms to balance load over partitions to make the best use of the cluster.
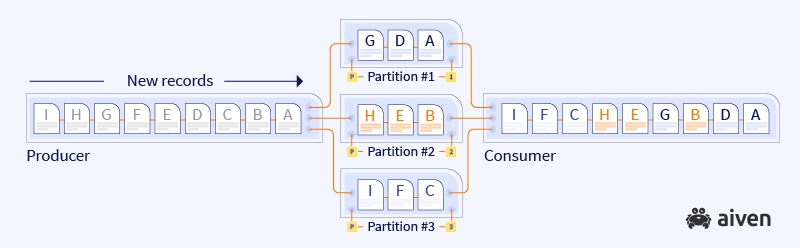
To understand what is happening with record ordering, take a look at the example visualized below. There you can see the data flow for a topic that is divided into three partitions. Messages are pushed by a producer and later retrieved by a consuming application one by one.
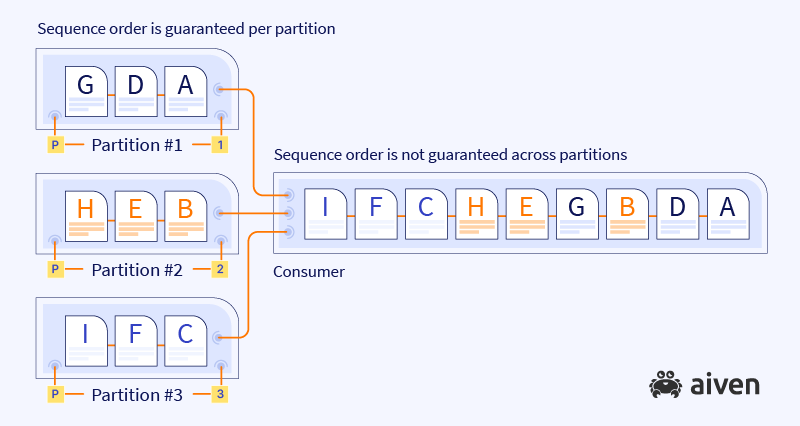
When consuming data from distributed partitions, we cannot guarantee the order in which consumers go through the list of partitions. That's why the sequence of the messages read by a consumer ends up different from the original order sent by the producer.
Reshuffling records can be totally fine for some scenarios, but for other cases you might want to read the messages in the same order as they were pushed by the producer.
The solution to this challenge is to rely on the order of the records within a single partition, where the data is guaranteed to maintain the original sequence.
And that's why, when building the product architecture, we should carefully weigh up the partitioning logic and mechanisms used to ensure that the sequence of the messages remains correct when consumers read the data.
The way messages are divided across partitions is always defined in the logic of the client, meaning that it is not the topic which specifies this logic, but the producers, who push the data into the cluster. In fact, if needed, different producers can have separate partitioning approaches.
There are a variety of tools you can use to distribute data across partitions. To understand these alternatives we'll look at several scenarios.
It's possible that, in your system, it is not necessary to preserve the order of messages. Lucky you! You can rely on the default partitioning mechanism provided by Apache Kafka and no additional logic is needed for the producers.
As an example of this scenario, imagine a service to send SMS messages. Your organization uses SMS to notify customers, and the messages are divided across multiple partitions so that they can be consumed by different processing applications in parallel. We want to distribute the work and process the messages as fast as possible. However, the order in which the SMS messages reach the recipients is not important.
In such cases, Apache Kafka uses a sticky partitioning approach (introduced as a default partitioner from version 2.4.0). This default method batches records together before they're sent to the cluster. After the batch is full or the "linger time" linger.ms is reached, a batch is sent and a new one is created for a different partition. This approach helps decrease latency when producing messages.
Here's a code snippet written in Java which sends a single message into a randomly assigned partition. This is a default behavior and doesn't need any additional logic from your side.
Loading code...
Even though some scenarios do not require maintaining message sequence, the majority of cases do. Imagine, for example, that you run an online shop where customers trigger different events through your applications, and information about their activity is stored in a topic in an Apache Kafka cluster. In this scenario, the order of events for every single customer is important, while the order of events across the customers is irrelevant.
That's why our goal is to preserve the correct sequence of the messages related to every individual customer. We can achieve this if we store the records for every individual customer consistently in a dedicated partition.
The default partitioner can already do it for you, if you define a proper key for each of the messages.
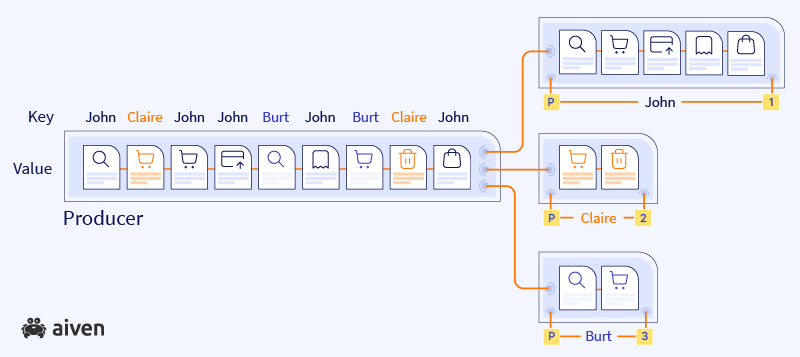
Every record body in an Apache Kafka topic consists of two parts - the value of the record and an optional key. The key plays a dramatic role in how messages are distributed across the partitions - all messages with the same key are added to the same partition.
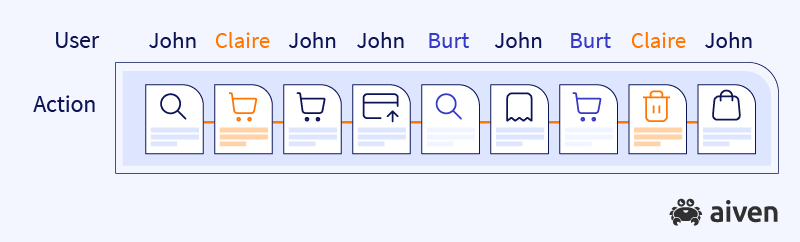
For our example, the most obvious choice for a key is the id of a customer, which we can use to partition the data. This is visualized below where, for simplicity, we assume that we have three customers (John, Claire and Burt) and three partitions.
Once the data with the key John is stored in a partition, Apache Kafka remembers to send all future messages with the identical key into the same partition.
This visualization includes just three customers, one for each partition. In real life you might need to store data for multiple customers (or devices, or vehicles, etc.) in a single partition.
The code snippet below shows how to use a key when creating a record:
Loading code...
What's important to note is that Apache Kafka doesn't use a string representation of the key. Instead it converts the key into a hash value, which means that there is a probability of a hash collision, when two different keys create the same hash resulting in data assigned to the same partition. Is this something you need to avoid? Scroll down to read about the custom partitioner!
Sometimes you want to control which message goes to which partition. For example, maybe the target partition depends on the day of the week when the data is generated. Assuming your system has seven partitions:
Loading code...
The tools we've looked at above will help in many use cases. In some situations, however, you might need higher flexibility and might want to customize the logic of partitioning even farther. For this, Apache Kafka provides a mechanism to plug in a custom partitioner, that divides the records across partitions based on the content of a message or some other conditions.
You can use this approach if you want to group the data within a partition according to a custom logic. For example, if you know that some sources of data bring more records than others, you can group them so that no single partition is significantly bigger or smaller than others. Alternatively, you might want to use this approach if you want to base partitioning on a group of fields, but prefer to keep the key untouched.
In a custom partitioner you have access to both key and value of the record before deciding into which partition you want to put the message. To create a custom partitioner you'll need to implement a partitioner class and define the logic of its methods. Here is an example of a custom partitioner written in Java:
Loading code...
Once you've defined the custom partitioner, reference it in your producer:
Loading code...
Now every arriving record is analyzed by a custom partitioner before it is put into a designated partition.
There are two more built-in partitioners that you can consider. The first is RoundRobinPartitioner which acts according to its name - iterating over all partitions and distributing items one by one ignoring any provided key values. Round robin, unfortunately, is known to cause uneven distribution of records across partitions. Furthermore, it is less performant compared to the default sticky mechanism, where records are combined into batches to speed up producing time.
Another built-in partitioner is UniformStickyPartitioner, which acts similarly to DefaultPartitioner but ignores the key value.
When defining partitioning logic, carefully evaluate how your partitions will be growing over time. You need to understand if there is a risk that a selected mechanism will result in uneven message distribution.
There are a variety of scenarios when uneven distribution can happen.
For example, when the default partitioner sends a huge batch of data to a single partition. When using the default partitioner, consider the proper settings for "linger time" and a maximum size of the batch that fits your particular scenarios. For example, if your product is frequently used during the day, but almost no records come in at night, it is common to set "linger time" low and batch size high. However, with these settings there is a probability that if you have an unexpected surge of data, this influx of records is added to a single batch and sent to a single partition, leading to uneven message distribution.
Another case of uneven message distribution can happen when you distribute records by keys, but the amount of data related to some keys is significantly bigger than for others. For instance, imagine that you run an image gallery service and divide data across partitions by user id. If some of your users use the service significantly more frequently, they produce significantly more records, increasing the size of some partitions.
Similar to the scenario above, if you rely on days and times to distribute the data, some dates - such as Black Friday or Christmastime - can generate considerably more records.
Additionally, uneven distribution can happen when you move data from other data sources with the help of Kafka Connect. Make sure that the data is not heavily written to a single partition, but distributed evenly.
Overall, uneven message distribution is a complex problem that's easier to prevent than to solve later. Rebalancing messages across partitions is a challenging task because in many scenarios partitions preserve the necessary order of the messages, and rebalancing can destroy the correct sequence.
How does this happen, what is the impact, and how to avoid it?
Watch the Helsinki developer meetup recordingApache Kafka provides a set of tools to distribute records across multiple partitions. However, the responsibility for a durable architecture, and selection of the strategy to distribute the messages, lies on the shoulders of the engineers building the system.
If you'd like to learn more about Apache Kafka, check out these articles:
Or poke around our Apache Kafka documentation and try Aiven for Apache Kafka® 30 days for free.
Table of contents
// add necessary properties to connect
// to the cluster and set up security protocols
Properties properties = new Properties();
// create a producer
KafkaProducer<String,String> producer =
new KafkaProducer<String, String>(properties);
String topicName = "topic-name";
// generate new message
String message = "A message";
// create a producer record
ProducerRecord<String, String> record =
new ProducerRecord<>(topicName, message);
// send data
producer.send(record);
logger.info("Sent: " + message);
// create a producer record
String key = message.get("customerId").toString();
String value = message.toString();
ProducerRecord<String, String> record = new ProducerRecord<>(topicName, key, value); // create a producer record
String key = message.get("customer").toString();
String value = message.toString();
LocalDate today = LocalDate.now();
Integer partitionNumber = today.getDayOfWeek().getValue();
ProducerRecord<String, String> record = new ProducerRecord<>(topicName, partitionNumber, key, value);public class customPartitioner implements Partitioner {
public void configure(Map<String, ?> configs) {
}
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// get the list of available partitions
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
int partition = ...;
return partition;
}
public void close() {
}
} Properties properties = new Properties();
properties.put("partitioner.class", "customPartitioner");
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);