


There are only two hard things in Computer Science: cache invalidation and naming things.
-- Phil Karlton
Luckily, in Kafka cache invalidation is not an issue, but we still need to name things. Let me tell you a story about naming things in Kafka.
A Name You Don’t Need is a Name You Don’t Have
LinkedIn created Kafka for on-premise data centers. The idea was to use servers with their local disks for data storage and achieve data durability by replicating each piece of data on multiple disks across multiple servers. The abstraction of how the data is stored was the key innovation: topics with partitions. These abstractions are the fundamental building blocks of how Kafka clients, producers and consumers interact with Kafka today. From day one, Kafka abstracted away from the client how exactly it physically stored data even though there was just one way to do that. There was no need for a name, so there was no name. There just were topics with partitions that Kafka somehow stored and managed. Kafka clients couldn’t affect the mechanism of how the data is stored.
As time passed, the world around Kafka changed, and issues caused by the design of the data storage in Kafka surfaced. In 2010 a dense server hard drive had a capacity of a terabyte, a decade later ten times more. Cloud became the go to model of deploying production systems, and cloud object storage became the place to store massive amounts of data. Out of these changes in the operating environment Kafka tiered storage emerged, allowing older data from partitions to be offloaded from the local disks to cloud object storage.
This meant there was now a mandatory local tier and an optional remote tier for all topics. The local tier is an alias for the original unnamed Kafka-way to store data. The data in the remote tier is typically stored in cloud object storage. The remote tier can be enabled and disabled per-topic by setting a topic config remote.storage.enable to true or false. This can be done on topic creation time or later. In order to use remote tier, the tiered storage functionality must be explicitly enabled at the Kafka cluster level.
There is no official name for a topic that has remote tier enabled. However, it’s commonly referenced as a tiered topic or a remote-enabled topic e.g. in Kafka documentation. And since there was no name originally for a topic that does not have remote tier enabled, there still is no name.
Now Kafka has tiered topics and topics with remote tier disabled with no name. Things are well in control. End of story. Oops, not really.
As the cloud became the de facto deployment model for Kafka, and the amount of data pumped in and out of Kafka increased by a magnitude or more, the cost of data ingress and egress became an issue for anyone picking up the bill. As Kafka relies on replication for data durability, all data pumped into Kafka is typically copied across availability zone boundaries, with networking costs often making up the majority of the cost of operating Kafka. For many this meant object storage became a lucrative option of a new way to organize *all* topic data, not only the remote tier as in tiered storage.
The need for such a new mode for Kafka became so evident that quick-moving startups such as Warpstream created a Kafka compatible, closed source, systems that used cloud object storage as the data store for all topic data. This validated the hypothesis that such systems can be built and operated.
Apache Kafka, the upstream Kafka, doesn’t yet have such an object storage based mechanism of storing all topic data, but things are moving fast. We in Aiven noticed the need for modernizing Kafka to fully leverage cloud object storage and authored KIP-1150. The KIP introduced the concept of a diskless topic that provides exactly this feature, and was adopted by the Apache Kafka project earlier this year.
Fifteen Years Later, the Classic Topic Gets Its Name
As a side-effect, KIP-1150 finally started naming things! It could have dodged naming by using the same trick tiered storage used, i.e. setting a topic level flag marking a topic diskless and calling it a day. But it went further. The object storage-based topics are so different from the original way of storing topic data that it just made sense to introduce some new names. The KIP explicitly talks about classic topics and diskless topics. And more importantly, these are commonly called topic types.
Finally, there is a name for the 15 years old way of storing data in Kafka 👏 Personally, I like the name “classic topic”. It gives the original data storage mechanism the honor it deserves after serving well for such a long time. Think of classic cars and classic topics.
Unfortunately, or luckily, history is not done yet. There’s one more direction Kafka could evolve towards: bridging the gap between operational and analytical data. There are commercial solutions for this already such as Confluent Tableflow proving the need for it. Kafka itself doesn’t have such a topic type, yet. There are ongoing initiatives for this, such as Iceberg Topics from Aiven.
It Won’t End There
With this evolution of topic types in Apache Kafka, a fair question to ask is whether this is the end or should we expect even more topic types to be introduced?
In response, I’d say it’s not only expected to have these, but it’s already happening. In addition to open-source Kafka, there are closed source topic types such as:
- Ursa: A Lakehouse-Native Data Streaming Engine for Kafka. This is from StreamNative and introduces their own table-format native topic type.
- WarpStream Express topics that persist to a quorum of multiple single-zone S3 Express buckets
- AutoMQ FSx topics that write to a FSx (a multi-AZ shared file system)
These are not available in the open source Kafka, and perhaps never will be. Each introduces a very different read, write and storage mechanism for Kafka, highlighting the need for the topic type concept.
Each topic type needs an engine or functionality to power it. This is a made up name used in this blog, as there is no official and consistent naming. An engine contains the piece of code implementing everything needed for the topic type.
Let’s have a look at what kind of engines are currently available in Kafka and how they are all named. First, as we’ve seen Kafka has the in-built engine that powers classic topics. This engine has no name which is similar to the naming of classic topic types that until KIP-1150 also didn’t have a name. Kafka documentation calls the engine powering tiered topics both “tiered storage functionality” and “tiered storage feature”. The documentation of remote.log.storage.system.enable broker config calls it ”tiered storage functionality”. In this blog we’ll stick to “tiered storage functionality”. I think the documentation should be updated to only use the name “tiered storage functionality”. That would be the first step towards clearer naming.
KIP-1163 that is under discussion describes the core functionality of diskless topics introduced in KIP-1150. It calls this functionality diskless support and proposes a broker config key diskless.system.enable to enable diskless support. In this blog, we’ll use the term diskless functionality to match the term tiered storage functionality.
Everything seems nice and clear so far, one engine powers one topic type 👍However, that’s not the case. Let’s have a deeper look at how it all actually works. Below is a simplified version of how older and newer data in each topic type is stored in Kafka:
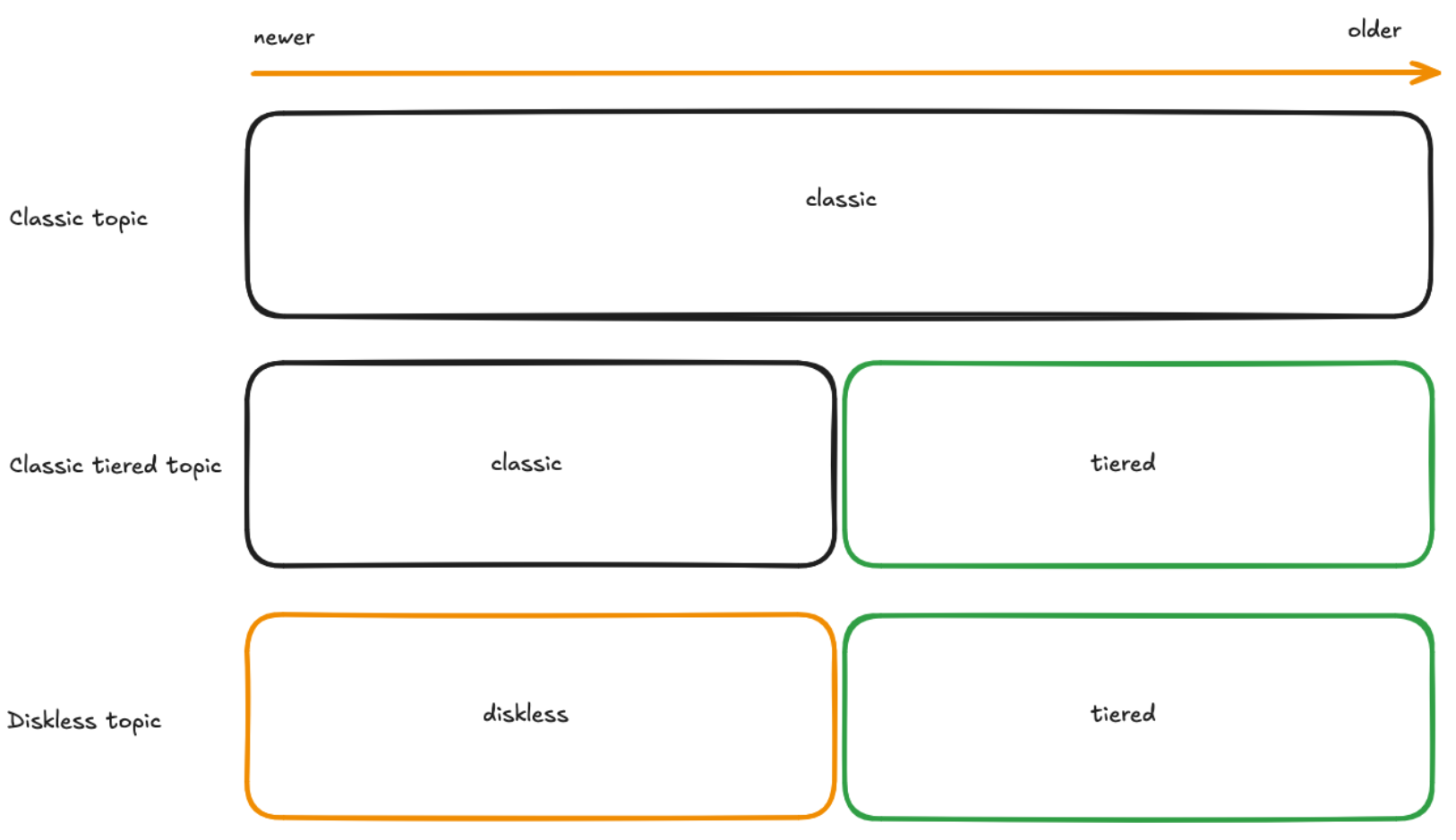
Kafka stores all the data of a classic topic using a single engine. With other topic types, Kafka uses multiple engines. Kafka places data produced to a classic tiered topic to the classic engine and in the background it moves older data from the classic engine to the tiered storage functionality. In the consume path, Kafka reads newer data from the classic engine and older data from tiered storage functionality. Similarly to a classic tiered topic, a diskless topic leverages two engines. When data is produced to a diskless topic, it lands in the diskless functionality. Later, exactly as with a tiered topic, Kafka offloads old data from the diskless functionality to the tiered storage functionality. The read path is the same, newer data is read from the diskless functionality and older data from the tiered storage functionality.
The key thing here is that a topic type does not map one to one to a topic engine.
Now that we have an understanding of what a topic type is, let’s have a look at what a topic type is not. Kafka by default deletes old data from a topic as defined in the documentation of cleanup.policy topic config. There’s another cleanup policy, compact. If specified for a topic, Kafka retains the last known value for each message key. Such a topic is informally called a compacted topic. This term is, however, problematic and I think it should be avoided. Or at least it will become problematic and should be avoided in the future. This is because the cleanup policy is a feature of Kafka that defines how old data is cleaned up in a topic and conceptually any cleanup policy could work on any topic type. Cleanup policy doesn’t define the mechanism of how the data is stored in Kafka. Thus, the term compacted topic is inaccurate if it refers to a topic type, since the topic could be e.g. a compacted classic topic or a compacted tiered topic. Currently, tiered storage functionality doesn’t support compaction and thus, a topic with compact cleanup policy is always a classic topic. But with KIP-1272: Support compacted topic in tiered storage, this will change as the compaction feature will be added to tiered storage functionality. So, how could such a topic be named then? One approach would be to introduce compact as a part of the type name, as a specifier: compacted classic topic, compacted diskless topic.
The introduction of more topic types introduces the question whether it’s possible to change a topic type of a topic or is topic type an immutable topic config set in stone at topic creation time. Right now the topic type is an immutable topic config. In real life, there is a clear use case for being able to change the topic type of a classic tiered topic to a diskless topic. And likely other topic type changes also have a use case. The use case is that if the end user wants to change the Kafka cluster to have a diskless topic instead of a classic tiered topic, it’s much easier to change the topic type than to create a new diskless topic and coordinate all clients to start using the new topic. And if the topic type change can be done in that direction, why not support changing a diskless topic to a classic tiered topic? Conceptually and theoretically, both of these are doable. Once implemented, topic type is no longer an immutable topic config of a topic but becomes a dynamic one! This affects the mental model above. But if the topic type is not modified for a topic, the mental model is still valid. The mechanisms how the topic type change can be done in practise and what the updated mental model would look like are beyond this blog post. Stay tuned!
What if topic type was a first-class config?
Finally, let’s have a look at a quick thought experiment of what the concept of topic type could look like in practise in Kafka if it was introduced as an explicit topic config.
There could be a new topic config topic.type. Currently, nothing explicitly specifies in the topic config that a topic is a classic topic. Instead, a topic is a classic topic if it’s not configured to be another topic type. Let’s add topic.type=Classic to explicitly mark a topic a classic topic. A topic is currently a classic tiered topic if it has remote storage enabled and diskless not enabled. Let’s add topic.type=ClassicTiered. A topic is a diskless topic (according to KIP-1163) if diskless.enabled is configured for it. The KIP doesn’t state it aloud, but remote storage also needs to be enabled. We could simply say: topic.type=Diskless. Here’s a summary of how it all could look like:
| Topic type | Current config | Proposed config |
|---|---|---|
| Classic | topic.type=Classic | |
| Classic tiered | remote.storage.enable=true | topic.type=ClassicTiered |
| Diskless | diskless.enable=true and remote.storage.enable=true | topic.type=Diskless |
The keys remote.storage.enable and diskless.enable can also have value false that equals to the key being absent. Thus e.g. diskless.enable=false & remote.storage.enable=false indicates a classic topic and diskless.enable=false & remote.storage.enable=true indicates a classic tiered topic. Not very readable and nice. I’d argue topic.type that is an enumeration explicitly specifying the topic type would be easier to understand. Topic.type essentially is the namespace where new topic types could be added. The set of values for the topic.type specifies the topic types Kafka supports. This wouldn’t be static, but Kafka major versions could add new ones.
The next question is how could topic.type topic config be added to Kafka in a backwards-compatible manner. One way to add it would be to make it a documentation-only config. In this approach Kafka would automatically set the value of topic.type but it would be read-only. If the topic type is changed for a topic, Kafka would update topic.type. This approach would surface clearly to the end user what a topic type of each topic is, since the user only needs to look at one topic config key.
Another approach would be to add topic.type in a backwards-compatible way as a read-write topic config. It could co-exist with the current configs, and the combination of using the current configs and topic.type must always be valid and in sync. In this approach also Kafka could fill in the missing config, i.e. if the topic was created with topic.type=Diskless, Kafka would add the diskless.enable=true and remote.storage.enable=true configs and if the topic is created with diskless.enable=true and remote.storage.enable=true Kafka would add topic.type=Diskless. Kafka would ensure these configs are in sync also when altering topic config.
Naturally we’d need to think about scenarios where the cluster is migrated from an older version of Kafka to a version where topic.type is supported and even the case where a subset of the brokers support it and other brokers are older and don’t support it. A lot to think about for sure, but it should be possible.
Deprecation and eventual removal is current topic configs and moving to only topic.type would be the final step towards clearer naming. This would be a backwards incompatible change. Whether this is feasible is questionable, since the current topic configs are very widely used.
My first conclusion of all the above is that we in the Kafka community need to sharpen our terminology as new topic types appear. The second conclusion is that adding topic.type or some other mechanism of making topic type an explicit concept of Kafka is an idea worth exploring more. If there’s wide support for the idea, there should be a KIP for this. What do you think?
