


TL;DR
Open Source: Iceberg Topics is available as an experimental open-source project under the Apache-2.0 license. Explore the code and join the conversation on GitHub.
We’re rolling out table-formatted topics for Apache Kafka, enabling open-source users to ingest, process, and emit data natively as Apache Iceberg tables. We’ve developed a new class of topics in Apache Kafka that stream data into lakehouse formats such as Apache Iceberg. The developer experience, similar to Diskless, is flexible, and the topics are opt-in via cluster configuration.
We’ve opened the door to Iceberg Kafka by adding just 3k lines of code to the RemoteStorageManager (RSM) — with no client API or Kafka broker changes. Iceberg Topics ships in our Apache-2.0 Tiered Storage (RSM) plugin—production-grade, upstream-aligned, and already moving hundreds of GB/s across some of the largest Kafka fleets in the cloud.
Open-source users can now run Kafka, Diskless, and Iceberg topics side-by-side in one cluster: Kafka for sub-100ms with optional Tiered Storage handoff, Diskless for cost-optimized object-store streams, and Iceberg Topics for native tables/SQL with seconds-level freshness— each opt-in per topic, no client API change, and no migrations.
While still in beta, this upgrade already:
- Reduces copying data from Kafka to Iceberg to zero
- Makes ~60% of Kafka sink connectors redundant, collapsing ETL costs
- Makes Apache Kafka speak native SQL for analytics and data engineering
Same as Diskless, getting Iceberg Topics is just a few configs: pick your Schema Registry and Iceberg catalog:
Loading code...
If you'd rather skip the blog post, check out the public technical whitepaper or just run the code. Let us know what you think.
The Open-Source Log Meets the Open-Source Lake
Kafka’s power comes from two compounding network effects: one inside your company, one across the ecosystem. Inside the org, it’s “publish once, reuse everywhere”. Push payments into a topic and the whole company can fan out on it: fraud scoring taps the stream, finance archives it, SREs trigger autoscaling, data science builds features, audit recovers the trail. No new ETL, no custom glue jobs, no permissions whack-a-mole—just point another consumer at the same stream where the truth flows. Each additional consumer amortizes the fixed ingest cost, so the marginal cost of the next use case keeps shrinking.
Across the industry, the effect doubles back: the more companies standardise on Apache Kafka, the more engineers learn it, the more patches, KIPs, docs and best practices flow back, the better Kafka gets—driving even more adoption. That compounding reuse is the flywheel. Many “Kafka-compatible” offerings force a split estate—one cluster for sub-100 ms streams, another object-store-backed for cheap history, with a mirror (or three) in between. Every copy adds latency and burns egress and— worse — it punctures both network effects: internally, reuse gets taxed; externally, the upstream OSS flywheel (more adopters → more contributors → better Kafka) loses momentum.
Kafka Connectors put additional brakes on streaming’s network effects. When a third-party system doesn’t speak Kafka, teams use a connector onto each topic. Our fleet telemetry shows ≈58% of sink Connectors already target Iceberg-compliant, object-store sinks (Databricks, Snowflake, S3, etc.), and ~85% of total sink throughput is lake-bound. The flywheel—publish once, reuse everywhere—is halted by detours through fleets of connectors: each lake-bound destination runs its own sink (e.g., S3 raw, Databricks, Snowflake). Every sink pulls from brokers (often cross-AZ), re-encodes, and does its own batch of object-store PUTs, so the same byte is shipped and stored 2–4X. Mirror a ~1 GiB/s stream to ~3 lake sinks and that multi-hop path can burn ≈ $3.4 M/year in cross-AZ + object-store charges.
Under those economics you can’t “stream everything,” so adoption stalls. Remove the ETL detour, collapse the copy tax to zero, and the flywheel spins again—topics show up as tables, SQL runs on the same bytes, and Iceberg Topics restores “publish once, reuse everywhere” with one durable copy, two first-class views.
There’s a bigger win than making Kafka cheap with Diskless and removing 60% of Kafka’s connectors: give the rest of the business the same “subscribe-and-go” experience—through SQL, without needing to know Kafka at all. If every topic surfaces as an Iceberg table, Sales, Finance, and Marketing can SELECT and JOIN without learning the Kafka protocol or dealing with partitions—and because Iceberg Topics is just a per-topic flag on already-schematized streams (Avro + Schema Registry) and reuses the tiered write, companies can afford to enable it broadly. In practice, we expect teams to flip it on by default, so the rest of the company gets query-ready Kafka “for free”.
That’s why Kafka ⇄ Iceberg matters: we preserve Kafka’s network effects while extending them to the lake.
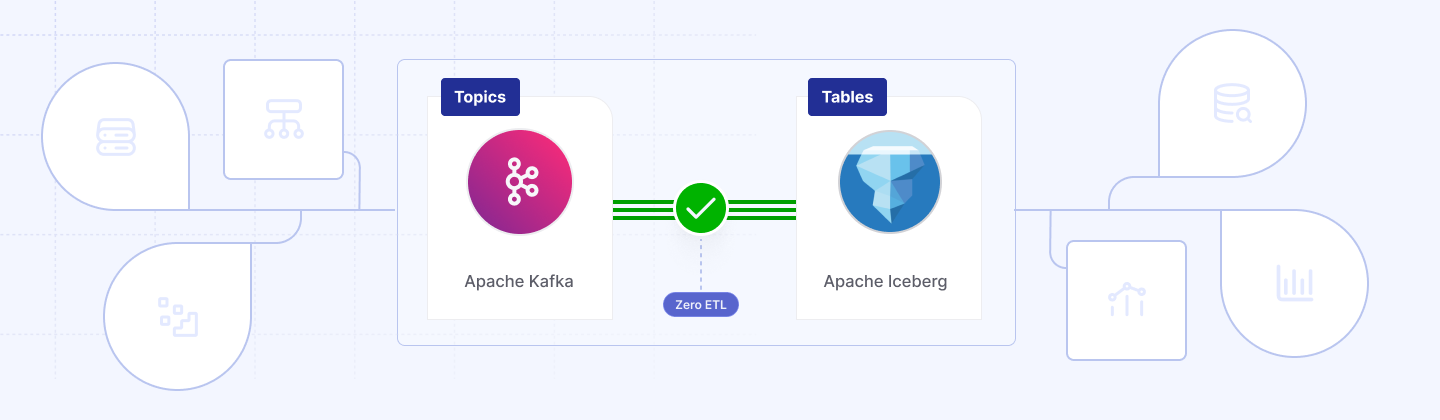
Iceberg Topics fixes two problems in Apache Kafka
Connector Economics: by design, Kafka’s Connect layer turns integrations into ETL and racks up a multi-hop “copy tax” while demanding teams to learn yet another system and shoulder the maintenance toil.
Missing primitive: Kafka lacks a topic = table path for the lake. Open-source teams are forced to either shoulder connector sprawl or pay for proprietary Kafka forks marketed as “native”.
Given the figures above—most sinks are lake-bound (58%)—those connectors were never the point; they’re just middlemen copying bytes to where they already live. Think about it—each of those connectors should have been just a table: flip the flag, surface the topic as Iceberg, and let downstream systems read, not copy.
So we asked ourselves: can we make integration boring by turning topics into governed, queryable tables by design? Can open-source users keep portability and get fresh analytics without a connector fleet? Can we deliver one durable copy that powers both replay and the lake?
Let’s dive into how Iceberg Topics makes it real.
Introducing Iceberg Topics for Apache Kafka
Iceberg Topics are the community’s Kafka-native path that makes any topic consumable as an Iceberg table— zero connectors, zero copies, no lock-in. Open-source users don’t need a Kafka Connect cluster or to learn its framework just to land data in the lake. On segment roll, the broker’s RSM writes Parquet and commits to your chosen Iceberg catalog; on fetch, brokers reconstruct valid Kafka batches from those same files. We get one durable copy, two first-class views: Kafka for replay, Iceberg for analytics.
100% Open Source (Apache-2.0): it ships as our RSM/Tiered Storage plugin - upstream-aligned, catalog-agnostic, S3-compatible. We follow Kafka’s practice of keeping third-party dependencies out of core, hence a plugin—the standard way to extend Tiered Storage. No proprietary control plane, no license gates, no lock-in.
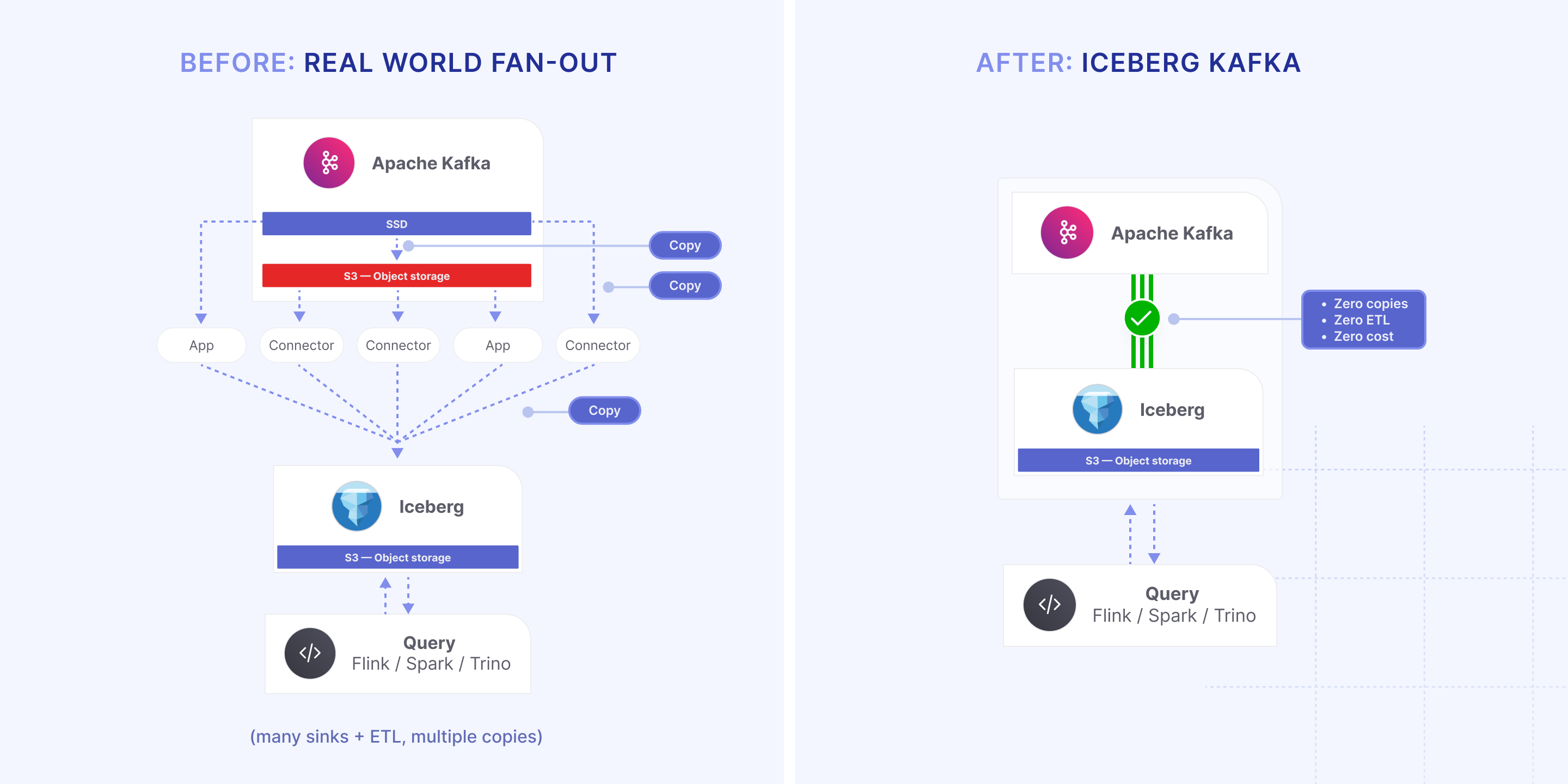
For operators, that means fewer moving parts (no connector fleets, no sidecars, no custom ETL), lower cloud spend (no duplicate storage or cross-AZ amplification), and rollout that is an upgrade, not a migration. For data teams, it means SQL on topics with snapshots, predicate pushdown, and parallelism that scales with files or splits—not with partitions.
Where is the KIP?
We didn’t file one—on purpose. Iceberg Topics lives entirely in Kafka’s Tiered Storage path and doesn't touch wire protocols or client APIs. By building here, we get speed and clean separation of concerns: the broker lands rolled segments as Iceberg or Parquet and reconstructs batches from those same files. Leaving core Kafka functionality unchanged means we can get Iceberg Topics into the hands of the Kafka community as quickly as possible—no committee work required to ship working code.
If we tried to KIP this today, we’d stall on schemas. To “standardize Iceberg in Kafka,” a proposal would immediately sprawl in a built-in schema story (or formal Schema Registry semantics), spawning adjacent KIPs and cross-project votes. Several KIPs have tried to tackle schemas/validation from different angles, but the work has largely stalled for objective reasons—see KIP-69 (2016). We don’t want perfect to be the enemy of good, so we’re taking the pragmatic route: ship working code now, then return with small, targeted increments once it’s battle-tested.
The implementation is upstream-aligned and designed to dovetail with focused proposals when the path is validated in production. We’ll come back with small, targeted KIPs informed by running it at scale — rather than theorizing in the abstract.
Skipping a KIP ≠ skipping design. Today we are also publishing the full technical whitepaper detailing the architecture, data model, and operational boundaries so reviewers can scrutinize the approach now and reference it later when standardizing. Similar to a KIP this design is a living document and will evolve with community feedback.
The repo is Apache-2.0. The code lives in our Tiered Storage (RSM) plugin you already run, PRs and comments are welcomed!
All You Need Is Tiered Storage
Here’s the twist: the Tiered Storage path is the Iceberg path. We didn’t bolt on a sidecar; we taught the RemoteStorageManager to land rolled segments as Iceberg/Parquet—and to read those same objects when brokers fetch. One path in, one path out. Flip a topic setting and a table appears in your lake; producers/consumers stay exactly as they are.
✅ Performance note: hot reads aren’t touched. Kafka’s Tiered Storage keeps recent segments on local disks, so sub-100 ms workloads continue to hit local I/O. Segment roll happens locally first (you just close the file); the Iceberg path only kicks in when that closed segment is tiered—RSM asynchronously materializes Parquet and commits to the catalog. For historical reads, brokers reconstruct batches from Parquet via manifest-driven fetch; even if remote fetch adds a few extra milliseconds, it’s on cold data, where throughput and correctness matter more than tail latency. We’ll dive deep on performance and benchmarking in upcoming posts.
That single move has outsized effects:
- Same bytes, two protocols: the files your engines (Trino/Spark/Flink) scan are the files brokers use to reconstruct batches—no second pipeline, no re-encode, no “eventual table” lag.
- Parallelism without partitions: analytics plans over Iceberg splits, so backfills and ML jobs fan out at object-store speed—closer to “blast the bucket” than “tune the consumer group.”
- Resilient by design: reads are manifest-driven—a small index file stored in your object store (e.g., S3) outside the Iceberg table, as part of Kafka’s Tiered Storage path. The manifest maps each Kafka segment to the Parquet files and byte offsets, so brokers can reconstruct batches even if the Iceberg catalog blips.
- Mixed mode lets classic and Iceberg segments coexist in one topic for painless rollout.
Governance improves, too. Retention is decoupled: Kafka hides the deleted data from the log while the table can retain it for audits and time travel. Lineage is built-in: kafka meta-data rides along as columns, making deduplication and audits boring. In short: Tiered Storage does double duty—your log is your lake—and the lake becomes the read path you already have.
⭐️ Scalability Bonus: Kafka Connect is inefficient for lake-bound sinks—it consumes via the Kafka protocol, adding extra connections and fetch requests, and replays history through the brokers, taxing the cluster. With Iceberg Topics, there’s no extra “convert to Parquet” job—the Parquet write is the tiering step. At segment roll, RSM materializes Parquet on the same Tiered Storage path that would upload remote segments anyway; scans then flow over the object-store (S3) API, and brokers only reconstruct batches on demand—they’re not in the hot loop. Even without caching or low-level read-side optimizations, our early tests point to solid scalability that keeps the additional broker CPU in the single digits. Parallelism comes from Iceberg splits/segments, not partitions, so you get high-throughput reads without hammering the cluster.
Shall we see Kafka Iceberg in action?
First Principles of Iceberg Topics
Kafka and Iceberg segments coexist in one topic during rollout, and the manifest-driven fetch lets brokers reconstruct batches from Parquet even if the catalog blips. If you don’t like what you see, you flip the switch back—no migrations, no second estate.
The design follows similar first principles that guided Diskless Kafka:
- Built-in. Iceberg Topics rides the RSM path already in Kafka. Users flip a per-topic switch; producers/consumers remain unchanged.
- Upgrade, don’t migrate. Enable Iceberg on new topics and run mixed mode beside existing streams. No big-bang cutover, no parallel estates.
- Zero copy. The tiered write is the table write. No duplicate bytes, no connector fleets, no extra PUTs.
- Open by default. Catalog-agnostic (REST/JDBC/Hadoop), S3-compatible today; Avro values validated via a (Confluent-compatible) Schema Registry. Keys stay opaque to preserve partitioning.
- Upstream-friendly path. Designed to align with Kafka improvements and any upcoming Kafka releases.
- Safety and lineage. Brokers preserve correctness; tables carry meta-data for reconstruction, audits, and simple deduplication.
- Explicit boundaries. Kafka writes, the lake maintains: schema evolution & transactions are near-term; while data is under local+remote retention the broker (RSM) is the sole writer (append-only, large Parquet files), and after hand-off compaction/snapshot expiration run outside Kafka, keeping broker overhead low.
If most of your sink traffic is already lake-bound, this is the missing Kafka primitive: topics that are tables—collapsing ETL into the platform while keeping the log’s replay guarantees.
Towards the Diskless Lake
It feels like day one again. With Iceberg Topics, a Kafka topic doubles as an Iceberg table—one durable copy for replay and SQL—expanding what’s possible while boosting scalability, stability, and reach. Flip a setting and the broker writes Parquet at segment roll; once those files land in object storage, both the consumer protocol and your query engine read the same bytes. No sidecars, no second pipeline, no “eventual table” gap. This is how Kafka becomes a central nervous system.
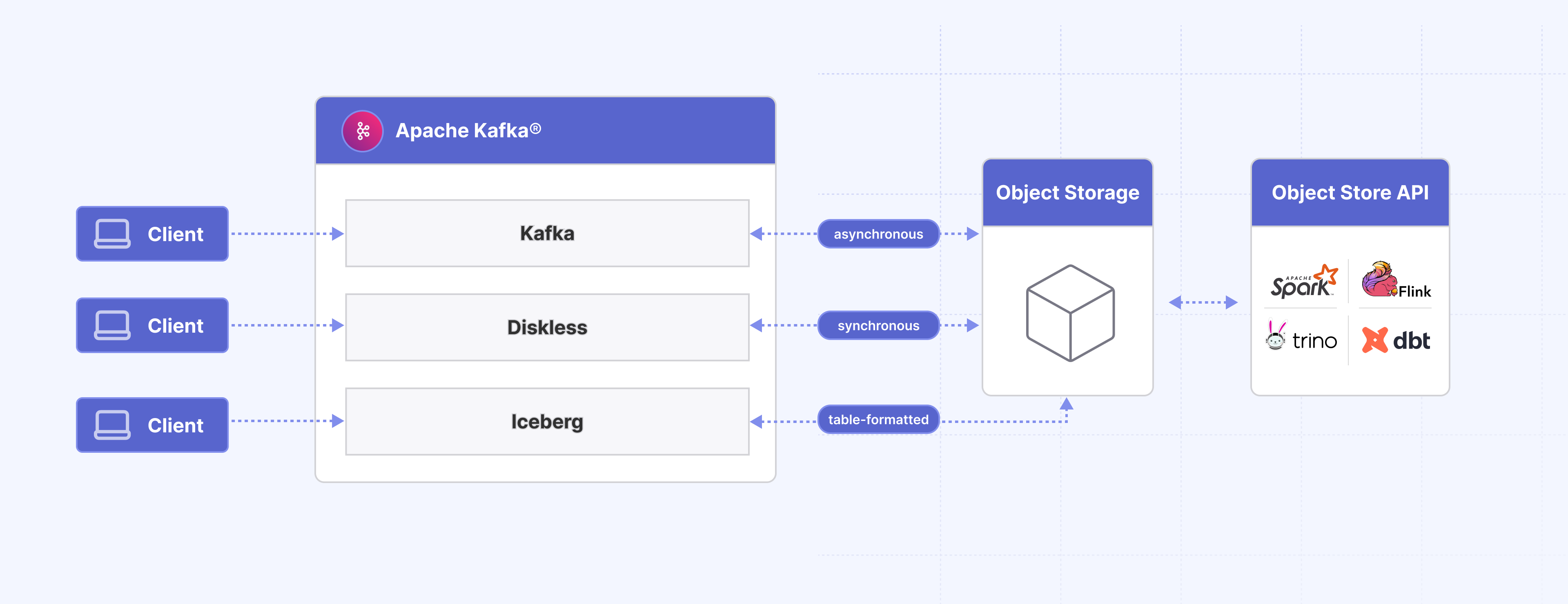
The experience gets even better when you treat the lake as the Kafka read path:
- Parallelism without partitions. Readers scale on splits, not partition count. Backfills and batch jobs fan out at object-store speed, independent of how many partitions you provisioned months ago.
- Simple access beats complex clients. Most teams don’t want to learn rebalances and offset commits. Give them SQL and a tiny HTTP/SDK that does three things—Create Snapshot → List Splits → Scan—and they can build a working reader in hours, not weeks.
- Zero-ETL by design. Analytics engines and brokers read the same files. No duplication, no re-encode, no glue to babysit.
As Diskless matures, the Iceberg path will come along for the ride—the tiered write is the table write. Storage lives wholly in the lake; compute fans out elastically as Kafka consumers or SQL engines. Turning it on looks like enabling a mode, not rebuilding a pipeline.
That’s the next-generation, cloud-native Kafka: Diskless Lake.
And that’s the bet: with Iceberg Topics as a new Kafka primitive, we open the next decade—governed Change Data Capture (CDC) at scale, SQL-first analytics on real-time streams, reproducible time travel and audits, and ML features without connector gymnastics.
