


Open Source: Iceberg Topics is available as an experimental open-source project under the Apache-2.0 license. Explore the code and join the conversation on GitHub.
TL;DR:
Kafka and Iceberg is a costly marriage of inconvenience.
If you write code for a living you’ve probably heard of Apache Iceberg - but you might not realise the detour your Kafka events must take to get there. Typically a Kafka message written to an Iceberg table must take a journey via a connector, rack up transfer fees, and idle in a sidecar before it appears as an Iceberg table—hardly the friction‑free flow open table formats promise. That detour is expensive: every hop writes, ships, and stores the same byte up to four times, so a 1 GiB/s tiered cluster can burn ≈ $3.4 million a year before the first SELECT *.
Open‑source users are stuck between a rock and a paywall. The Iceberg community connector is free but brittle: you run a second system, tune flush windows, and accept the toil. The alternative is to buy a “native” service such as Tableflow or Redpanda Iceberg. These products do emit spec‑compliant files—Spark or Trino can read them natively—but only on their schedule, in their catalog, and behind their licence gate. Your data stays portable; your pipeline and budget do not.
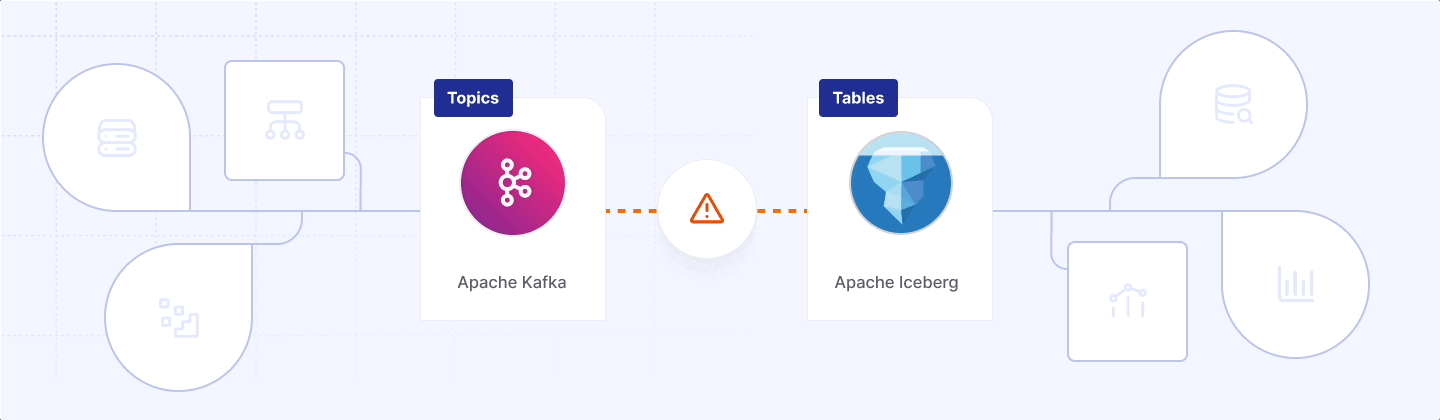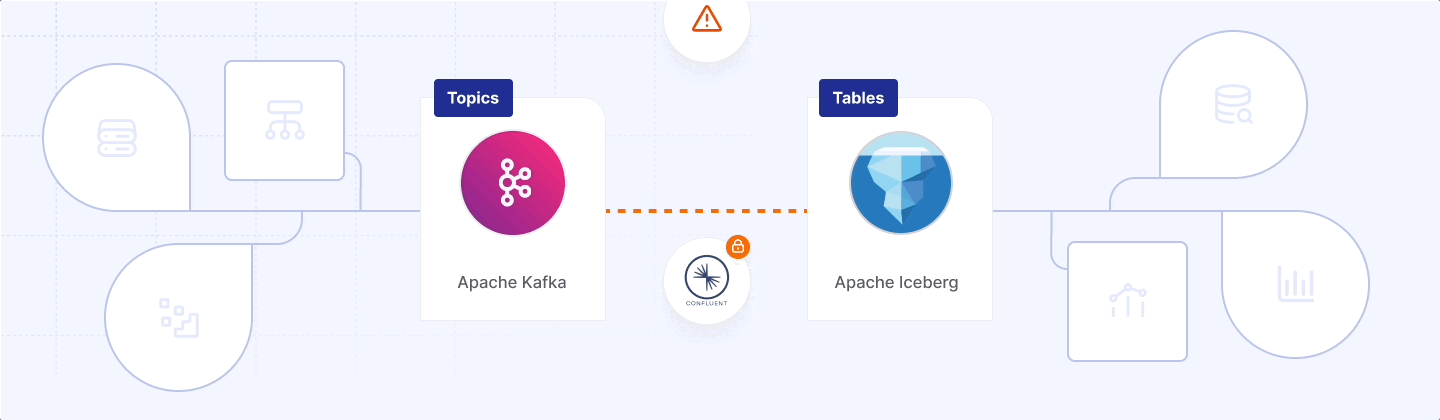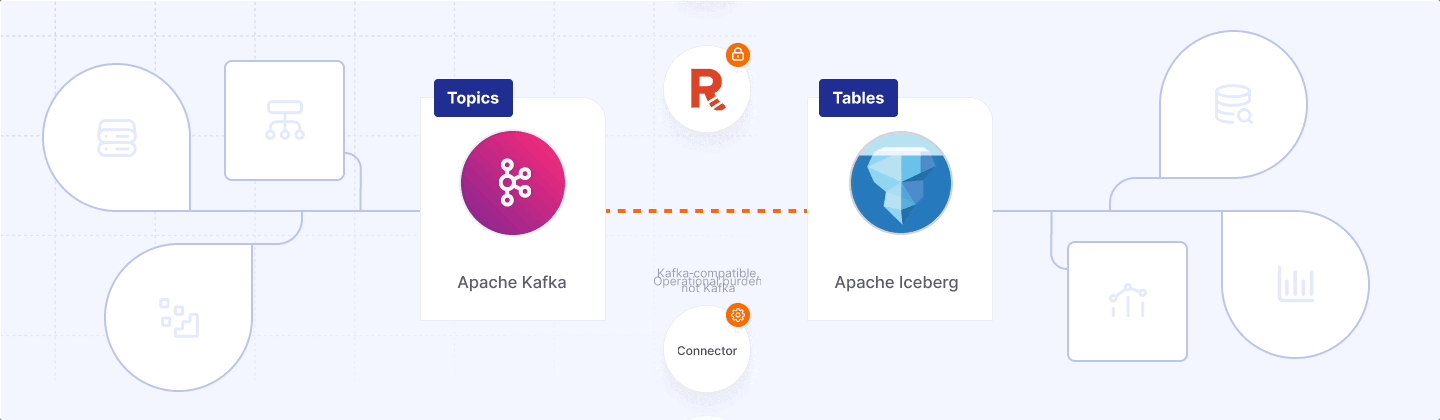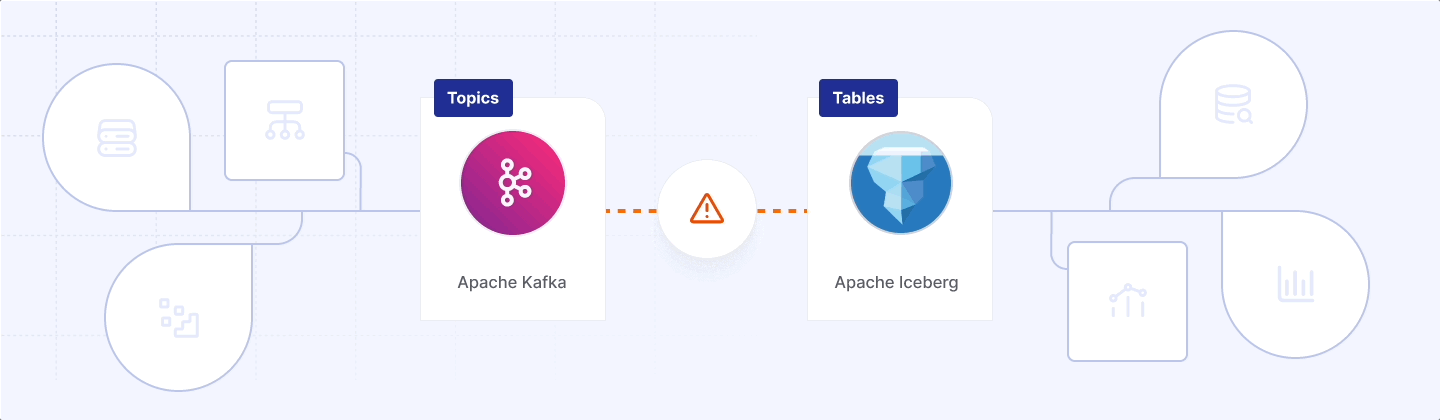
The cure is to unify the open source lake with the open source log. What we need is native, zero‑copy, open‑source Iceberg Kafka: as with Diskless Kafka, users just have to flip a topic config and—without connectors, licence keys, or extra storage bills—watch a table materialise in the same bucket Diskless Kafka already uses.
No hop, no fuss, just: topic = table
Ready to explore the world of open table formats? Grab an 🧊 Iced coffee and let’s get Kafka-nated!
The $25 billion in dormant Kafka stranded in SQL
Why did Apache Iceberg win? Seven years ago we had two ways to store analytics tables: Hive—whose behaviour lived in forgotten wiki pages and public forums—and everything else. Iceberg replaced that ambiguity with a formal, public spec, atomic commits, hidden common-sense partitioning, and safe schema evolution—then invited every engine to validate against an open test suite. Clear rules, open governance, and scale that actually works proved more compelling than any closed alternative. Like with Kafka, Iceberg won because it is open source.
(For a deep dive, see Brian Olson’s excellent history of the Iceberg vs. Delta.)
Databricks eventually wrote a billion‑dollar cheque for Tabular to buy into the community momentum its Delta Lake model couldn’t create. That watershed moment crowned Iceberg and signalled a larger pivot toward building directly on object‑store primitives. As we engineered Diskless Kafka to completely delegate storage on S3, the next question came naturally: what if an entire business could run on nothing but streaming topics, processing jobs, and lakehouse tables, all anchored in object storage?
Iceberg’s success shows that this vision is no fantasy. Its openness met a second tail‑wind: Cloud object stores are now the substrate of choice—AWS reported ≈ 220 000 data lakes on S3 at re:Invent. Those lakes already ingest through logs or soon will, because only streaming scales 100x vs. database replication: a Kafka topic can fan‑out to micro‑services, feature stores, and GPU clusters at once, while batch CDC chokes on row locks and bulk loads. If your lake isn’t fed by a log, it’s running on yesterday’s plumbing.
The industry’s wager follows naturally: whoever makes topic = table seamless becomes the bloodstream for those 220k lakes—and every one created tomorrow.
Ergonomics × Economics: Why Hype?
All major data infra vendors cling to this consolidation for two blunt reasons. First, ergonomics: an Iceberg-style streaming layer shrinks the skill gap between ops and the rest of the business. If every Kafka topic can be surfaced as an SQL table, suddenly sales, HR, even marketing teams that never touch GitHub can speak the same language as Data Engineers —SELECT and JOIN. That massively widens “what is streamable,” turning clickstreams, payroll events, and campaign metrics into a uniform, query-ready substrate. Second, sheer economics: Gartner’s latest market-share numbers peg the database-management sector at roughly $140 billion —and even a modest 20% carve-out for real-time lakehouse workloads represents an addressable pie north of $25 billion. No streaming platform serious about growth can afford to ignore a market that large.
The scramble is on. Each streaming vendor now touts its own Kafka ⇄ Iceberg converter, each crowning itself the “native” way to get from row logs to tables. The irony is we’ve eliminated the headache of ten open-table formats, only to inherit the new headache of ten catalogs and ten proprietary pipelines for shuttling Kafka data into Iceberg. The bottleneck has merely shifted downstream—from “Which file format?” to “Which catalog and solution do I now have to babysit?”
Kafka & Iceberg must fix two problems
One format, many dialects, no open source: Iceberg may have unified file formats, yet in streaming it has split into walled gardens. Confluent’s Tableflow, Redpanda’s Iceberg Topics, and a parade of sidecars each hard‑wire their own commit cadence and catalog service. They all market themselves as “native,” but try to migrate clouds, switch brokers, or federate two of these pipelines and you’re back to full rewrites and double storage—the antithesis of Iceberg’s open, efficient ideal.
That leaves open‑source practitioners in a bind: either run the aging community connector and babysit a second cluster, or pay a proprietary vendor and surrender portability. The very users who made Kafka and Iceberg successful are once again forced to choose between brittle DIY and closed‑door convenience.
Double-margin economics: Push a record through a pipeline and you pay first to store it on Kafka disks, again to ship it across AZs, a third time when a connector lands it in S3, and—if you picked a managed “zero‑ETL” service—a fourth time in vendor fees. Our cost breakdown shows a 1 GiB/s tiered Kafka cluster burning $3.4 M/year before an Iceberg copy is made. Scale that to petabytes and each byte can be billed three or four separate times before it ever reaches a dashboard.
> 🚨 Real‑world sting: One of our largest customers originally ran all analytics through Kafka streams. After several painful PoCs they concluded that none of the “native” Kafka ↔ Iceberg bridges felt native enough—so they scrapped the Kafka cluster, accepted overnight batches, and rebuilt directly on Iceberg’s own ecosystem. The pivot added $1 million‑plus in avoidable spend and stretched into months of migration toil for a result they thought they were buying on day one.
The worst sin of all is this splinters Kafka’s two compounding network effects. Inside an organisation the magic of Kafka is that every new service can tap an existing topic with a single subscribe call: no ETL, no glue jobs. Fork the log into vendor‑specific dialects and that flywheel stalls; engineers must first ask which cluster holds the truth. Across the industry, every company that standardises on upstream Kafka tends to send patches and features back, compounding quality and features for everyone. Splitting log‑to‑lake into proprietary solutions threatens to rerun Hive’s history: dozens of near‑miss implementations, no shared momentum, and a market that grows sideways instead of up. If we repeat that pattern we break the very thing that could unlock the $25 billion real‑time lakehouse opportunity.
Why fragmentation keeps winning, for now.
If you decide today that the Kafka topics in your stack must also be an Iceberg table, you effectively have three models to choose from, each revealing a different pressure that pushes platforms toward their own dialect.
- Bring‑your‑own‑plumbing (Apache Iceberg Sink Connector) – open, portable, but you run another cluster and accept 5‑minute freshness.
- Luxury express lane (Confluent Tableflow) – checkbox simple, seconds‑fresh, but locked-in Confluent’s cloud and pricing.
- Broker‑native, branded (Redpanda Iceberg Topics) – single hop, low latency, but proprietary and Kafka‑compatible, not Kafka.
Each model is a rational response to a real constraint—operational toil, time-to-insight, or end-to-end performance—but because they solve those constraints individually they pull the ecosystem into silos. The data lake has one open highway with Apache Iceberg; Open Source Kafka gets a maze of toll roads.
What If Apache Kafka published a one-page brief called “Iceberg Topics”
The key requirement will be to let any Kafka topic become an Iceberg table without a connector, licence key, or second copy of the data. Flip a config, keep producing, run SELECT on the same bytes already sitting in object storage.
Must-haves
- Zero-copy path – the tiered-storage write is the Iceberg write; no extra PUT, no duplicate bill.
- Exactly-once all the way – transactions that protect the log must also protect the table.
- Full schema evolution – adds, renames, even type promotions flow straight from Schema Registry into Iceberg metadata.
- Partition control, by topic – expose
iceberg.partition.specso you can tune file count and query pruning. - Catalog agnostic – Hive, Glue, REST, Nessie; pick one with a topic-level setting.
- Freshness knob – one parameter that trades commit latency for cloud-request cost (sub-second to five-minute windows).
- Low broker footprint – async writer off the leader thread; <10 % CPU and I/O overhead at 1 GiB/s ingest.
- Autopilot ops – default file sizing, manifest compaction, retention; day-to-day burden no higher than tiered storage.
- Apache 2.0, no lock-in – ships upstream; businesses build moat above the spec, not inside it.
Winter (Iceberg) is coming
If Kafka is to stay the beating heart of real-time data, it must absorb Iceberg the way it absorbed tiered storage: upstream, uniform, and licence-free. A zero-copy “Iceberg Topic” inside open-source Kafka would collapse today’s patchwork into a single standard and cut out duplicate storage bills.
Kafka has no marketing team, but it has something everyone envies: the largest streaming community on the planet—100k+ companies and more than 80% of the Fortune 100.
That gravity has turned good ideas into new features before; it can do it again.
After Diskless made Kafka 80% cheaper, the next leap is clear: native, zero‑copy, open‑source Iceberg Kafka. Spin up a topic and—without connectors, licences, or second storage bills—see a table appear in the same bucket, governed by the same commit log.
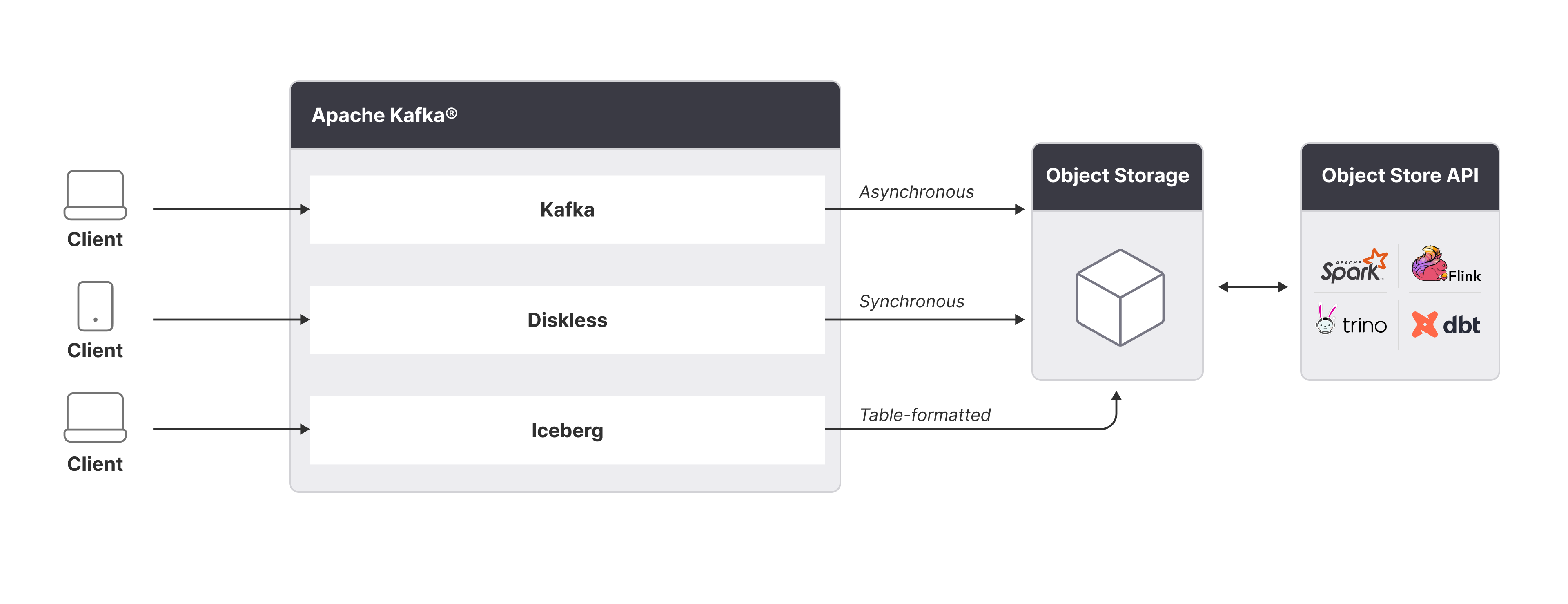
That single act would erase today’s copy tax, stop schema roulette at the source, and replace a patchwork of vendor toll roads with one open highway.
When the world’s biggest user base moves, unification becomes inevitable.
Let’s Get Kafka-Nated!
If this post resonated with you, there’s more brewing. After the last Get Kafka‑Nated webinar drew over 1000 sign‑ups, we’re expanding the project into a dedicated Substack for everything open‑source Kafka—deep dives, OSS release notes, war stories, and the same vendor‑neutral honesty you hear on the podcast. Subscribe, and each week a fresh cup of Kafka insight will land in your inbox—no paywalls, no sales pitch, just the community’s best ideas percolating in one place.
Let’s keep getting Kafka‑nated—see you down the log.

Table of contents