Retrieval augmented generation with OpenAI and OpenSearch®
Use OpenSearch® as a vector database to generate responses to user queries using AI
Use OpenSearch® as a vector database to generate responses to user queries using AI
Retrieval augmented generation (RAG) is an AI technique for retrieving facts from an external knowledge base to provide large language models (LLMs) on the most accurate, up-to-date context to be able to craft better replies and reduce the risk of hallucination.
This tutorial guides you through an example of using Aiven for OpenSearch® as a backend vector database for OpenAI embeddings and how to perform text, semantic, or mixed search which can serve as basis for a RAG system. We'll use the set of Wikipedia articles as base knowledge to influence the replies of a chatbot.
OpenSearch is a widely adopted open source search/analytics engine. It allows to storing, querying and transforming of documents in a variety of shapes. It also provides fast and scalable functionality to perform both accurate and fuzzy text search. Using OpenSearch as vector database enables you to mix and match semantic and text search queries on top of a performant and scalable engine.
Before you begin, have the following:
hobbyist plan is enough for the notebook)pip installed locally.The tutorial requires the following Python packages:
openaipandaswgetpython-dotenvopensearch-pyYou can install the above packages with:
Loading code...
We'll use OpenAI to create embeddings starting from a set of documents, so we need an API key. You can get one from the OpenAI API Key page after logging in.
To avoid leaking the OpenAI key, you can store it as an environment variable named OPENAI_API_KEY.
Info
To store safely the information, create a .env file in the same folder where the notebook is located and add the following line, replacing the <INSERT_YOUR_API_KEY_HERE> with your OpenAI API Key.
Loading code...
Once the Aiven for OpenSearch service is in the RUNNING state, we can retrieve the connection string from the Aiven for OpenSearch service page.
Copy the Service URI paramete and store it in the same .env file created above, after replacing the https://USER:PASSWORD@HOST:PORT string with the Service URI.
Loading code...
We can now connect to Aiven for OpenSearch by adding the following code in Python:
Loading code...
The code above reads the OpenSearch connection string from the .env file (os.getenv("OPENSEARCH_URI")) and creates a client connection using SSL with a timeout of 100 seconds.
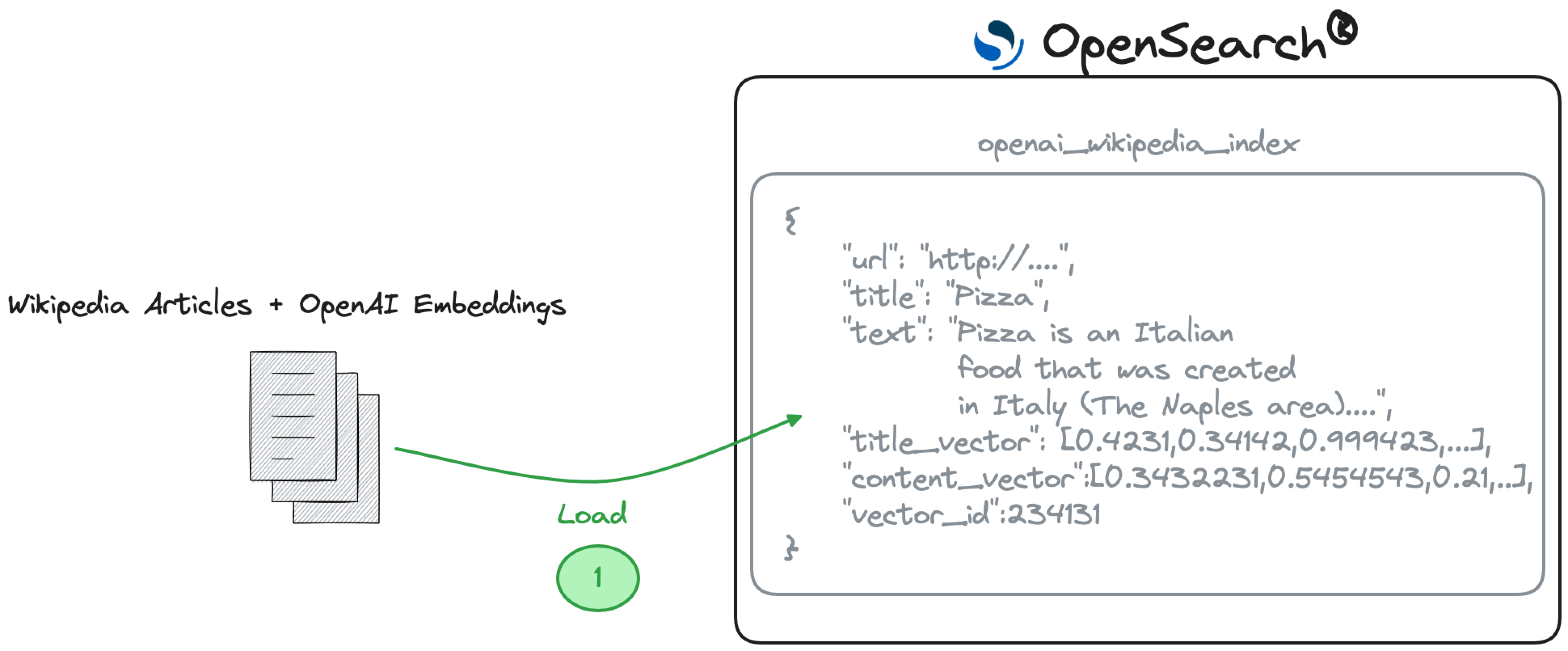
In theory we could use any dataset for this purpose, and you are more than welcome to bring your own. However, for simplicity's sake and to avoid the need to calculate embeddings on a huge dataset of documents, we'll use a set with pre-calculated OpenAI embeddings which score Wikipedia articles. We can get the file and unzip it with:
Loading code...
Let's load the file in a pandas dataframe and check its content with:
Loading code...
The file contains:
id a unique Wikipedia article identifierurl the Wikipedia article URLtitle the title of the Wikipedia pagetext the text of the articletitle_vector and content_vector the embedding calculated on the title and content of the wikipedia article respectivelyvector_id the id of the vectorTo properly store and query all the fields included in the dataset, we need to define an OpenSearch index settings and mapping optimized for the storage of the information, including the embeddings. For this purpose we can define the settings and the mappings via:
Loading code...
The code above:
knn search enabled. The k-nearest neighbors (k-NN) search searches a vector space (generated by embeddings) in order to retrieve the k closest vectors. You can read more in the OpenSearch k-NN documentation.title_vector and content_vector of type knn_vector and 1536 dimension (vector with 1536 entries)text, containing the article text as a text fieldtitle, containing the article title as a text fieldurl, containing the article text as a keyword fieldvector_id, containing the id of the vector as long fieldWith the settings and mappings defined, we can now create the openai_wikipedia_index index in Aiven for OpenSearch with:
Loading code...
With the index created, the next step is to parse the the pandas dataframe and load the data into OpenSearch using the Bulk APIs. The following function loads a set of rows in the dataframe:
Loading code...
To speed up ingestion we can load the data in batches of 200 rows.
Loading code...
Once all the documents are loaded, we can try a query to retrieve the documents containing Pizza:
Loading code...
The result is the Wikipedia article talking about Pizza:
Loading code...
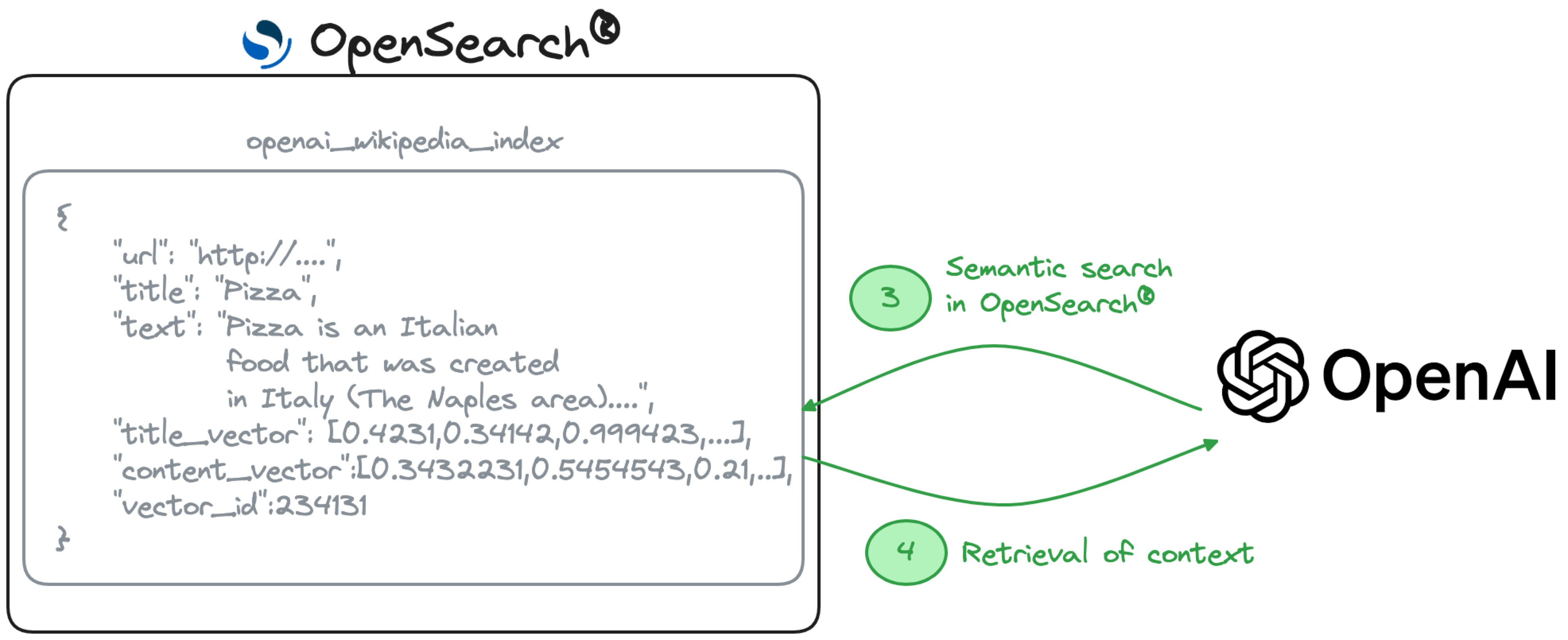
To perform a semantic search, we need to calculate question encodings with the same embedding model used to encode the documents at index time. In this example, we need to use the text-embedding-ada-002 model.
Loading code...
With the above embedding calculated, we can now run semantic searches against the OpenSearch index to retrieve the necessary context for the retrieval-augmented generation. We're using knn as query type and scan the content of the content_vector field.
Loading code...
The result is the list of articles ranked by score:
Loading code...
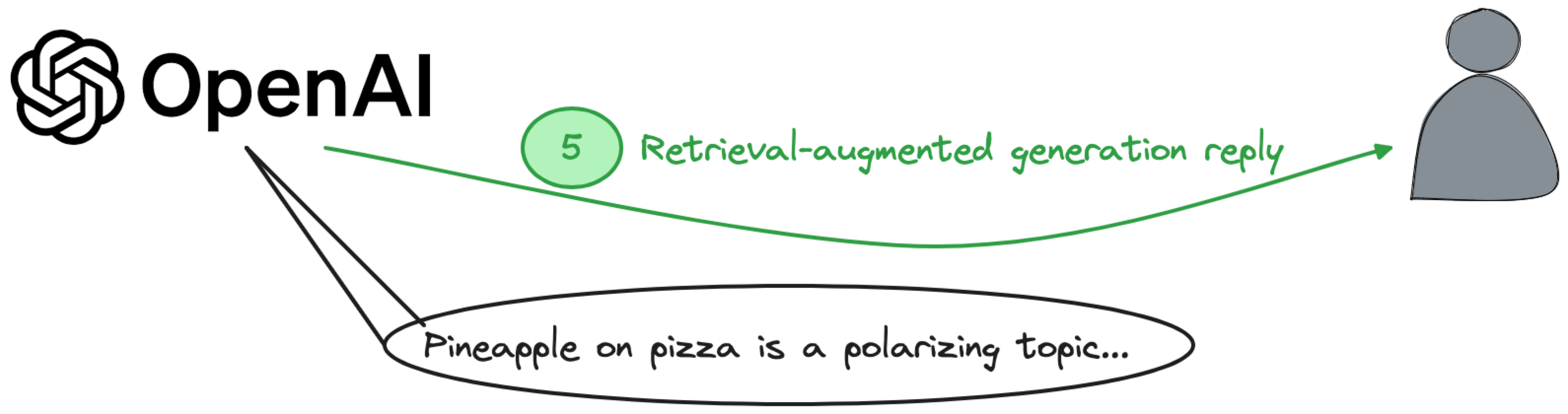
The step above retrieves the content semantically similar to the question. Now let's use OpenAI chat completions function to return a retrieval-augmented generated reply based on the information retrieved.
Loading code...
The result is going to be similar to the below:
Loading code...
OpenSearch is a powerful tool providing both text and vector search capabilities. Used alongside OpenAI APIs allows you to craft personalized AI applications able to augment the context based on semantic search, and return responses to queries that are augmented by AI. A logical next step would be to pair OpenSearch with another storage system to, for example, store the responses that your customers find useful and train the model further. Building an end to end system including a databases like PostgreSQL® and a streaming integration with Apache Kafka® could provide the resiliency of a relational database and the hybrid search capability of OpenSearch with data feeding in near real time.
You can try Aiven for OpenSearch, or any of the other Open Source tools, in the Aiven platform free trial by signing up.
Table of contents
pip install openai pandas wget python-dotenv opensearch-pyOPENAI_API_KEY=<INSERT_YOUR_API_KEY_HERE>OPENSEARCH_URI=https://USER:PASSWORD@HOST:PORTimport os
from opensearchpy import OpenSearch
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv()
connection_string = os.getenv("OPENSEARCH_URI")
# Create the client with SSL/TLS enabled, but hostname verification disabled.
client = OpenSearch(connection_string, use_ssl=True, timeout=100)import wget
import zipfile
embeddings_url = 'https://cdn.openai.com/API/examples/data/vector_database_wikipedia_articles_embedded.zip'
wget.download(embeddings_url)
with zipfile.ZipFile("vector_database_wikipedia_articles_embedded.zip",
"r") as zip_ref:
zip_ref.extractall("data")import pandas as pd
wikipedia_dataframe = pd.read_csv("data/vector_database_wikipedia_articles_embedded.csv")
wikipedia_dataframe.head()index_settings ={
"index": {
"knn": True,
"knn.algo_param.ef_search": 100
}
}
index_mapping= {
"properties": {
"title_vector": {
"type": "knn_vector",
"dimension": 1536,
"method": {
"name": "hnsw",
"space_type": "l2",
"engine": "faiss"
}
},
"content_vector": {
"type": "knn_vector",
"dimension": 1536,
"method": {
"name": "hnsw",
"space_type": "l2",
"engine": "faiss"
},
},
"text": {"type": "text"},
"title": {"type": "text"},
"url": { "type": "keyword"},
"vector_id": {"type": "long"}
}
}index_name = "openai_wikipedia_index"
client.indices.create(
index=index_name,
body={"settings": index_settings, "mappings":index_mapping}
)def dataframe_to_bulk_actions(df):
for index, row in df.iterrows():
yield {
"_index": index_name,
"_id": row['id'],
"_source": {
'url' : row["url"],
'title' : row["title"],
'text' : row["text"],
'title_vector' : json.loads(row["title_vector"]),
'content_vector' : json.loads(row["content_vector"]),
'vector_id' : row["vector_id"]
}
}from opensearchpy import helpers
import json
start = 0
end = len(wikipedia_dataframe)
batch_size = 200
for batch_start in range(start, end, batch_size):
batch_end = min(batch_start + batch_size, end)
batch_dataframe = wikipedia_dataframe.iloc[batch_start:batch_end]
actions = dataframe_to_bulk_actions(batch_dataframe)
helpers.bulk(client, actions)res = client.search(index=index_name, body={
"_source": {
"excludes": ["title_vector", "content_vector"]
},
"query": {
"match": {
"text": {
"query": "Pizza"
}
}
}
})
print(res["hits"]["hits"][0]["_source"]["text"])Pizza is an Italian food that was created in Italy (The Naples area). It is made with different toppings. Some of the most common toppings are cheese, sausages, pepperoni, vegetables, tomatoes, spices and herbs and basil. These toppings are added over a piece of bread covered with sauce. The sauce is most often tomato-based, but butter-based sauces are used, too. The piece of bread is usually called a "pizza crust". Almost any kind of topping can be put over a pizza. The toppings used are different in different parts of the world. Pizza comes from Italy from Neapolitan cuisine. However, it has become popular in many parts of the world.
History
The origin of the word Pizza is uncertain. The food was invented in Naples about 200 years ago. It is the name for a special type of flatbread, made with special dough. The pizza enjoyed a second birth as it was taken to the United States in the late 19th century.
...from openai import OpenAI
# Define model
EMBEDDING_MODEL = "text-embedding-ada-002"
# Define the Client
openaiclient = OpenAI(
# This is the default and can be omitted
api_key=os.getenv("OPENAI_API_KEY"),
)
# Define question
question = 'is Pineapple a good ingredient for Pizza?'
# Create embedding
question_embedding = openaiclient.embeddings.create(input=question, model=EMBEDDING_MODEL)response = client.search(
index = index_name,
body = {
"size": 15,
"query" : {
"knn" : {
"content_vector":{
"vector": question_embedding.data[0].embedding,
"k": 3
}
}
}
}
)
for result in response["hits"]["hits"]:
print("Id:" + str(result['_id']))
print("Score: " + str(result["_score"]))
print("Title: " + str(result["_source"]["title"]))
print("Text: " + result["_source"]["text"][0:100])Id:13967
Score: 13.94602
Title: Pizza
Text: Pizza is an Italian food that was created in Italy (The Naples area). It is made with different topp
Id:90918
Score: 13.754393
Title: Pizza Hut
Text: Pizza Hut is an American pizza restaurant, or pizza parlor. Pizza Hut also serves salads, pastas and
Id:66079
Score: 13.634726
Title: Pizza Pizza
Text: Pizza Pizza Limited (PPL), doing business as Pizza Pizza (), is a franchised Canadian pizza fast foo
Id:85932
Score: 11.388243
Title: Margarita
Text: Margarita may mean:
The margarita, a cocktail made with tequila and triple sec
Margarita Island, a
Id:13968
Score: 10.576359
Title: Pepperoni
Text: Pepperoni is a meat food that is sometimes sliced thin and put on pizza. It is a kind of salami, whi
Id:87088
Score: 9.424156
Title: Margherita of Savoy
...# Retrieve the text of the first result in the above dataset
top_hit_summary = response['hits']['hits'][0]['_source']['text']
# Craft a reply
response = openaiclient.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Answer the following question:"
+ question
+ "by using the following text:"
+ top_hit_summary
}
]
)
choices = response.choices
for choice in choices:
print(choice.message.content)Pineapple is a contentious ingredient for pizza, and it is commonly used at Pizza Pizza Limited (PPL), a Canadian fast-food restaurant with locations throughout Ontario. The menu includes a variety of toppings such as pepperoni, pineapples, mushrooms, and other non-exotic produce. Pizza Pizza has been a staple in the area for over 30 years, with over 500 locations in Ontario and expanding across the nation, including recent openings in Montreal and British Columbia.