




TL;DR: We always wanted to make Aiven for Apache Kafka in the cloud free.
Today we made it possible:
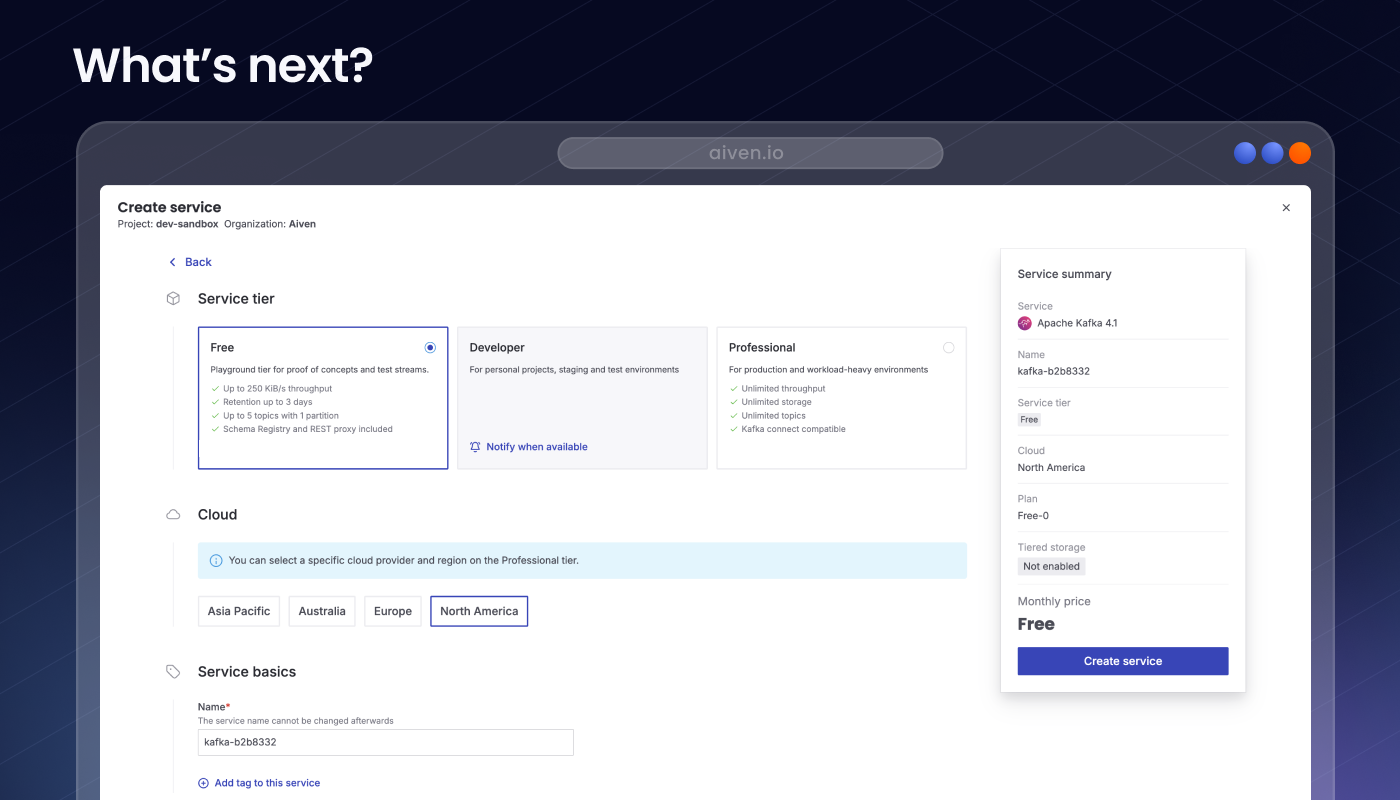
- Up 250 kb/s throughput
- Up to 3-day retention
- Free Schema Registry and REST proxy
- No credit card
We’re so excited to see what you’ll build that we’re offering a $5000 prize for the coolest project on the Free tier.
Kafka is not dead, but has an 80% problem
When the news broke that IBM is buying Kafka’s creators, a lot of people had the same reaction:
“Is this the end of Kafka as we know it?”
We see the opposite. You don’t spend $11B on a dying technology. You spend it on a fundamental primitive you want locked in for the next decade. Kafka has been quietly crossing the line from “exciting tech” to “boring critical infrastructure” for a while, this acquisition simply seals the transition, much like what happened with Postgres and Linux years ago.
The Kafka community now has a credible promise of long-term funding behind the core project.
The real issue is elsewhere. Most Kafka clusters move tiny amounts of data - 60% of clusters are under 1 mb/s but are forced to pay and operate as if they were an internet-scale system. In practice, ~80% of Kafka usage is “small data” (low MB/s), yet inherits the full big-data tax in infra, complexity, and engineers.
The problem is that Kafka doesn’t really care whether you’re sending 10 KB/s or 100 MB/s. Under the hood you still have distributed system and 2 brokers that talk to each other. It's that for 80% of clusters, the economics and experience are wildly out of proportion to the workload.
At Aiven, we want to be the cloud for Apache Kafka - and the cloud of Kafka has been missing its most vital component: a true entry point at zero cost.
Historically, this comes with two “entry ramps” that both suck for small workloads. Either you get free credits that expire just when you’ve finally wired everything up, or you DIY a single-node Kafka on your laptop or Kubernetes cluster, knowing full well it’s nothing like production.
Our bet is that market share follows accessibility. If you want Kafka to thrive and you don’t make it more “premium” - you put a high-quality, fully managed service into as many hands as possible, at the exact moment people are deciding what to build on.
Today, we are opening the gates.
Nerfing Kafka (without making it feel like 240p)
Designing a free tier for Apache Kafka is a balancing act. If you make it too generous, you burn money and complicate upgrade paths to paid tiers. A few vendors have already launched free or ultra-low-cost Kafka tiers, only to shut them down a year later and force everyone to migrate. If you make it too weak, it feels like watching a YouTube video buffer at 240p on a 4K screen – technically works, but not an experience anyone enjoys.
We decided to “nerf” Kafka in a deliberate way: keep the feeling of a proper, production-grade cluster, while constraining it so that we can offer it for free, sustainably.
We wanted the Aiven Free Tier to feel like HD with stereo sound.
So here’s what we optimised for:
- Up to 250 kb/s throughput
- Free Schema Registry and REST proxy included
- Up to 3 days retention
- Kafka 4.1 with Kraft
- Full support in Terraform and CLI
- Self-balancing cluster that is basically a scaled-down production
- Free
Of course, “free” doesn’t mean “unlimited.” To keep the experience sustainable, we established specific limits. Throughput is capped at 250 kb/s per second (IN+OUT) – think a few hundred events per second (even at 500 events/s you’re looking at 43.2 million events per day). You get 5 topics with 2 partitions each so you can model a few well-chosen streams, not replicate your entire data platform.
Retention is kept reasonable at up to 3 days so you’re encouraged to move growing workloads to a higher, 99.99% available tier before your backlog grows into a data lake. Underneath all of this are the same controls we use for our paid clusters: pluggable policies for creating topics and altering configs, strict rules around which settings you can touch, built-in throttling to protect the infrastructure.
The 1080p Kafka: what comes after free
If the free tier is 720p – surprisingly good for something you’re not paying for – then our upcoming Developer tier is going to be 1080p Kafka.
When you outgrow the free tier, it shouldn’t feel like switching platforms or renegotiating your relationship with Kafka. It should feel like tapping a “Continue watching in HD” button.
Our upcoming Developer tier is designed to give you everything you need for serious, ongoing workloads that haven’t yet reached “enterprise” scale. Roughly 50% of Kafka use cases live here: not trivial, not gigantic, but important enough that you care deeply about reliability and ergonomics.
Where the free tier focuses on getting you from zero to “hello, events” in minutes, the Developer tier focuses on making Kafka satisfying to use day after day. Better observability. More generous throughput and retention. More topics and partitions. Deeper integrations. All the quality-of-life details that turn Kafka from “this incredibly powerful system” into “the critical messaging backbone I don’t have to think about.”
And because both tiers are built on the same foundation, the move from free → developer → production is just one click.
Cloud Kafka has been powerful for a long time. Today, we’re making it accessible.
We’re excited to see what you build!
And we really mean it when we say we’re excited. To put some skin in the game, we’re launching a competition to find the best project built on the Aiven for Apache Kafka Free Tier.
The Prize: $5,000 cash award for one winner.
How to Win (Merit, not Lottery)
We’re not drawing names out of a hat. A jury of Aiven judges will select the winner based on two factors:
- The Build: We’re looking for quality, creativity, and usability. Show us what "small data" can actually do.
- The Story: We want to see your social media activation. Document the journey, engage with the community, and show off your solution.
Next Steps
Build something cool, share the story, and we just send you $5k. The winner will be contacted within 7 days of the competition closing (31-Jan 2026).
