


TL;DR
Aiven's free-tier Kafka offers 5 topics with 1 partition each, 250 KiB/s throughput (in and out), 3-day retention on a 2-node cluster, and hibernates after 5 days of inactivity. This isn't a serious project, but can Kafka still be a useful tool? Absolutely.
Building a smart bird feeder
Over the past few months, my attempt to answer the question ‘is that robin on my bird feeder huge or just fluffy’ sparked a descent into over-engineered bird feeder madness. I did the natural thing and started building a Raspberry Pi powered custom bird feeder with a digital scale, webcam, and automatic species detection with image classification models.
I succeeded in answering the question, and presented my results at the 100th PyData London Meetup: the robin was 26g, that’s a massive robin (150% more than the average according to the RSPB)!

Before I could share the project with friends I had to fix the following issues:
- Scale calibration - the value read by the scale would drift over time and produce inaccurate results
- Uptime - the bird feeder would occasionally crash and go offline without me realising
- False positives - the thresholds for the system to log that it has detected a bird were initially too low so I was getting a lot of empty photos back of “birds” that weighed 4g
- Monitoring - my first prototype would produce an image with data in the filename every time it saw a bird, but that left long periods where I had no diagnostic data to troubleshoot the system
I wouldn't discover until later that I had a fifth, feathered problem: pigeons were crash-landing my bird feeder, throwing the delicate calibration out of whack. But more on that later.

I used to be an observability engineer (and also a data engineer), so I had a pretty good idea of how to solve this problem: if I instrumented my bird feeder to produce metrics in something like real-time I could spot issues as soon as they occurred and collect data for analysis to help improve the system.
There was one major problem with my plan. When I was working on observability before, I was doing it at enterprise scale. This meant replication, vendor walled gardens, disaster recovery, heaps of tooling and interconnected systems, and thousand dollar budgets a month chargeable to the client. I don’t have the pocket change to run production grade systems at home - and I was already spending $5 a month to store my images - so I was keen to find a cheaper solution.
When Aiven launched free-tier Kafka, I realized it was perfect for my observability problem, and without adding any new costs to my already rapidly growing bill of materials.

To get some visibility into my bird feeder problems I set up a quick and dirty data architecture which transmits metrics from the bird feeder to Grafana (an open-source visualization and dashboarding tool) via Kafka.
Why Kafka?
The free-tier specs are ideal for my project. While 250 KiB/s throughput might not seem like a lot of bandwidth to work with, if you consider that my bird feeder only produces around 1kb/s of message data it’s actually more than enough: hypothetically I could support up to 250 separate bird feeders! Also, because my data volumes are so small, I can use Kafka as my only data source, which dramatically simplifies my architecture.
If we look at the types of data I’m sending, 5 topics is also plenty to give me clean separation for weight data, motion data, processed bird visits, and system health (including Kafka message throughput) - with a topic to spare if I add another sensor in later. It’s also easy for me to re-use topics for data from separate bird feeders by filtering on location and username tags.
Durability is important in observability at enterprise scale but it still matters here: when the Pi crashes (and it does), the last N hours of metrics are still in Kafka for post-mortem analysis.
Finally, I can iterate on Grafana dashboards without touching the bird feeder code thanks to the decoupling Kafka provides to my architecture. It’s worth noting that managed connectors aren’t available through the Aiven platform for free tier but tools like Grafana that manage their own consumers will still work great.
There are, of course, some limitations to this approach: consuming data directly from Kafka in Grafana is inefficient as it requires rereading from the earliest offset each time the dashboard is reloaded, which makes it difficult to take advantage of the three day retention period. This can be mitigated by using a metrics database like Thanos to store historical data for more efficient retrieval. But for these low data volumes seen in the debugging process, we can get away without using a metric store for now.
Producing data to Kafka
Getting my various metric data from my Pi into Kafka was surprisingly straightforward thanks to the Python Quick Connect in the Aiven Kafka service. It produces ready-to-use Python code with all the connection details and SSL certificates configured, so I could focus on instrumenting my application rather than wrestling with configuration.
I structured my data with multiple bird feeders in mind from the start. Each message includes a userId and location field, which means the same Kafka topics can handle data from multiple bird feeders without mixing them up:
Loading code...
My bird feeder now streams weight readings and motion detection data continuously to separate Kafka topics. This gives me a complete timeline of what's happening at the feeder, not just snapshots when birds are detected, which made fixing the issues with my bird feeder a breeze.
Calibrating my sensors using real data
One big challenge in this project was picking a sensible activation threshold for triggering the camera and logging a bird sighting. The two sensors I am working with are a load cell which returns a value in grams, and a camera which I can use to detect motion (by measuring the difference between an image taken a few moments ago and what the camera is currently seeing) in pixels.
You could come across good values for these by doing some research - for example, the lightest bird in the UK is the Goldcrest, coming in at a teensy 5g. Alternatively, you could use trial and error, which is what I initially did for the motion sensing activation. I later took a better approach: I calculated the total area of the image in pixels of the camera sensor, and then experimented with values corresponding to different portions of the image before settling on 30kpx as a reasonable threshold.
As an approach this wasn’t horrible, but it was less than scientific. Crucially, it was impossible to know if I was missing birds by making my activation threshold too conservative without watching the bird feeder all day. Adding my little observability stack solved this issue by allowing me to compare the live reading of the sensors to the activation threshold in real time, easily identifying missed birds and visually comparing the performance of different values.

Another huge challenge for calibration was taring (setting it to zero when a bird left or when it first started up) the scale. It was hard to know how different approaches to taring i.e. taring after the bird left, taring every 60 seconds, performed. This made it hard to ensure the weights measured were accurate. Again, by using this lightweight observability setup with Kafka and Grafana, I could easily view the measured weight in real-time and immediately note the impact of different taring strategies.
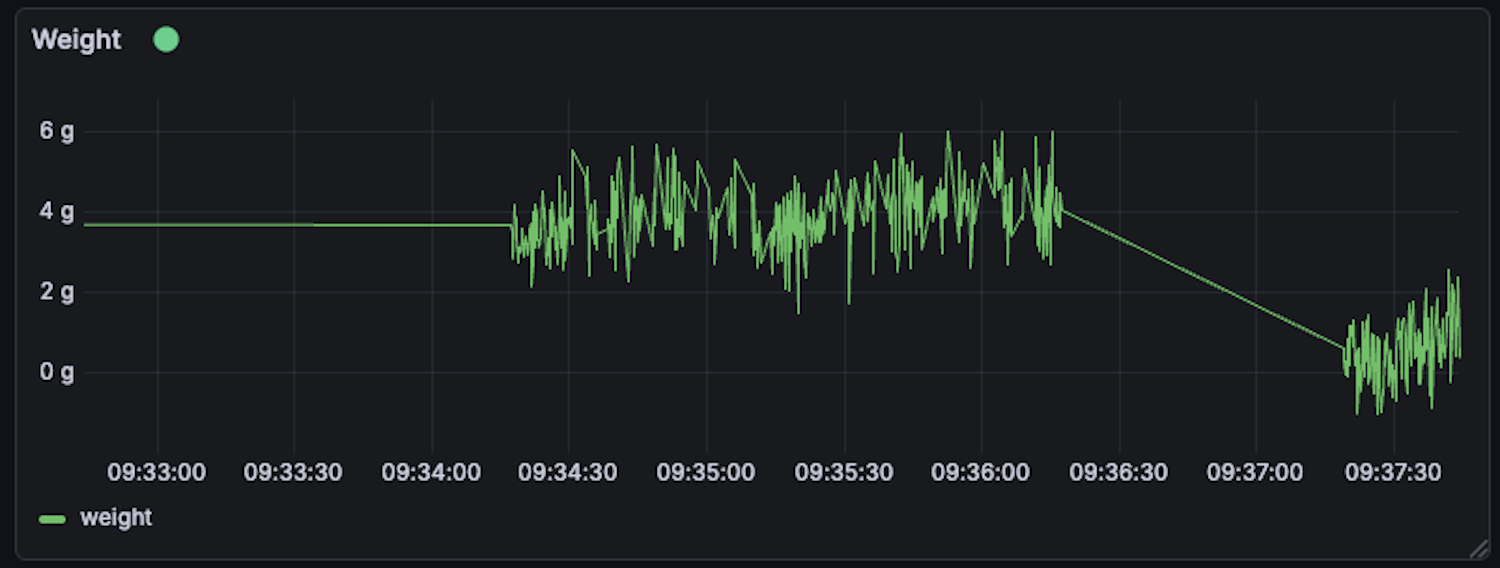
Pigeon problems
I could see in the data that sometimes the scale would get stuck reading 20g, and by comparing the data from Grafana to my images in Cloudflare I could immediately spot the culprit. Pigeons were landing on the roof of my bird feeder, gradually unsticking it from my window, and upsetting the calibration of the load cell.
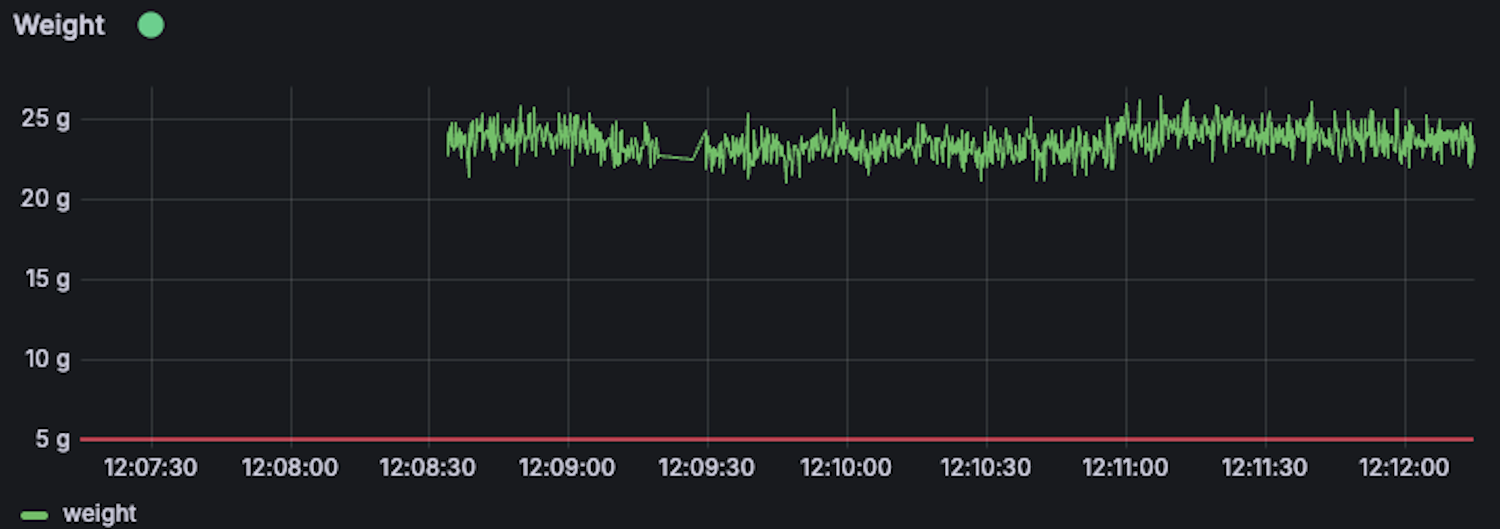
The more I looked into the data the more I could see the impact of my avian adversaries. Most of the birds visiting the feeder would fly in, grab a quick mouthful, and fly away. The pigeons, by contrast, would make themselves at home for as long as it took to eat every scrap of bird seed in the feeder. This was annoying enough when it came to having to frequently refill the feeder, but worse was that the pigeons would hang around through tare cycles causing my data to be polluted with hundreds of pictures of pigeons with inaccurate weights.

I may be too close to this but look at the pigeon's eyes in the last picture. They know they’re ruining my week.
Conclusion
Aiven free tier Kafka provides me with everything I need for my personal projects. I don't need five-nines uptime for bird watching; I need real-time visibility into why my scale keeps drifting. Aiven’s Apache Kafka gives me that for free.
This isn't production infrastructure—it's a 2-node cluster limited to 250KB/s of throughput but, if like me you’re working on hobby projects, it may well be exactly what you need.
Next up is pigeon proofing my setup: either by modifying my bird feeder or taking the more pigeon friendly approach of remounting the load cell such that pigeon landings stop messing up my readings. Then again maybe more drastic action is needed, look at the malice in those beady eyes. Until then my bird data is full of greedy pigeons, for now.
What would you build with free Kafka? We're running a competition with a $5,000 prize for the best project built with Aiven's free tier Kafka. Whether it's monitoring your sourdough starter or tracking your cat's patrol routes, I'd love to see what absurdly overengineered projects you build. Share your project on social media with #FreeTierKafka and tag @Aiven to enter (competition runs until January 31st, 2026).
Check out the competition details and Aiven free tier Kafka here.
