



TL;DR;
We’ve added Tiered Storage to Diskless Kafka—using plain old KIP-405 as the read-optimizer, Diskless Kafka materializes fast-to-read segments—unifying Tiered and Diskless into a single path. This leverages production-grade Tiered Storage plugin, removes the need for bespoke components, and simplifies the community discussion. We’ve also upgraded KIP-1150 and KIP-1163 to address the community’s most pressing questions such as transactions and queues support.
Good news: Diskless topics (KIP-1150) made it practical to remove local disks from Kafka’s replication path and cut cloud costs by up to 90%. Bad news: three blockers dulled the impact:
- Forked estate: Tiered Storage and Diskless write different formats to object storage—no Tiered plugins/Iceberg, no clean per-partition deletes.
- Complexity: Fetches fan-out through a distributed cache with the Batch Coordinator on the hot path.
- Migration friction: Even after upgrading to Diskless, users still have to create new topics and move workloads to adopt Diskless.
NEW Diskless:
- Absorbs KIP-1176 feedback— offering best of Diskless and best of Tiered Storage.
- Inherits zero-copy Iceberg topics by default so we have Diskless Iceberg
- Cuts metadata overhead and simplifies the architecture dramatically
- Collapses the consume path into a single, predictable priority order.
- Enables zero-copy topic migration (classic ↔ diskless), Diskless is now zero migration.
As usual, if you’d rather skip the opinions, jump straight to the upgraded KIPs — and let us know what you think about it in the Apache Kafka mailing list.
Diskless is the future of Apache Kafka
The diskless architecture won—just not the way we imagined. We expected Diskless to stay an opt-in path alongside disk-backed topics but AWS moved the goalposts much faster than we thought: S3 Express cut prices by ~50% while delivering ~10 ms PUTs. Overnight, “cheap and cold” turned into a fast, economical hot path. The old plan—keep disks for the latency-sensitive 20% and run Diskless for the rest—now looks dated. We believe the default flipped: write to object storage first, keep Kafka semantics, and retire broker disks wherever they don’t deliver unmistakable value.
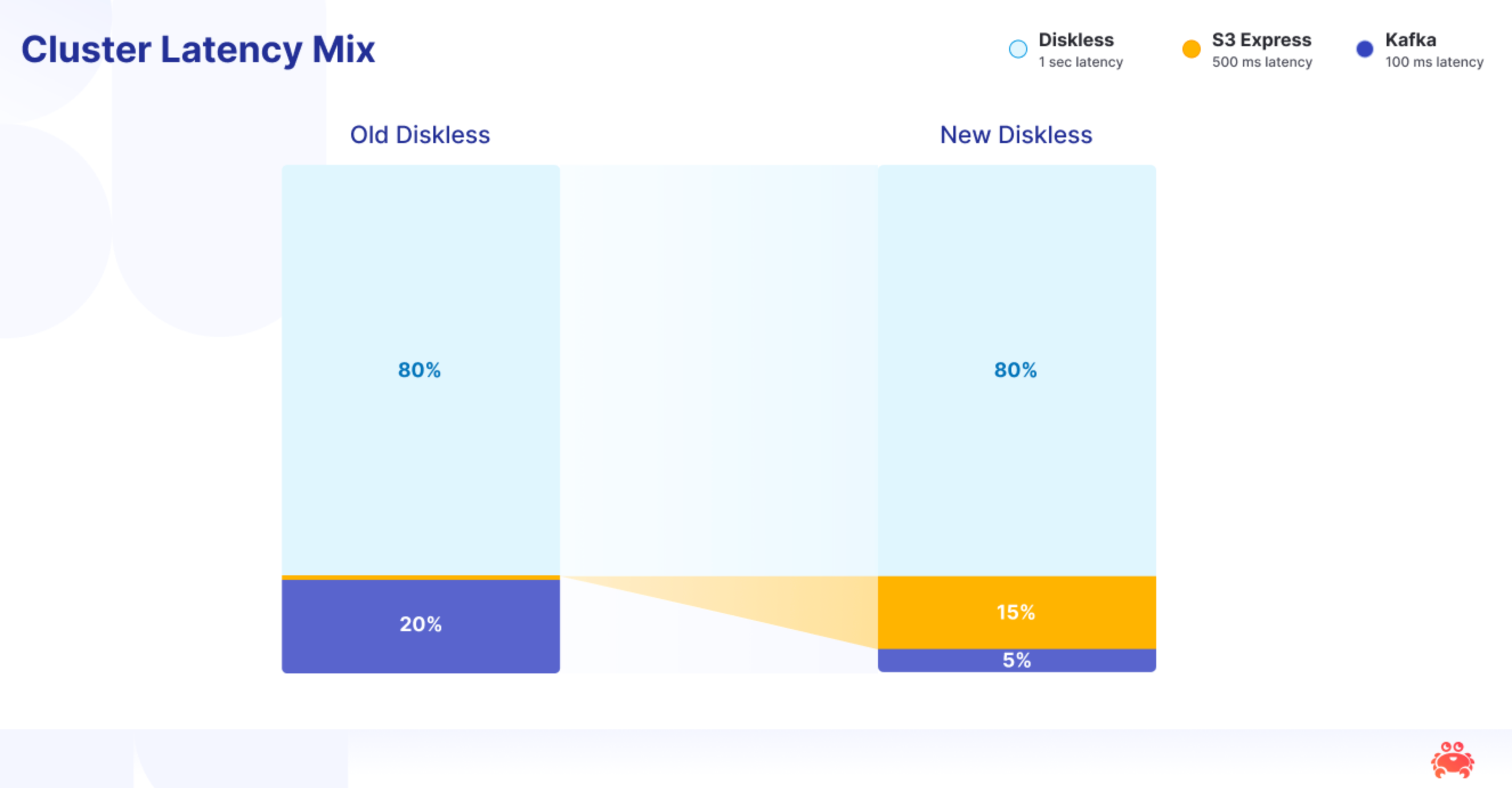
Here’s the cost curve at a glance. For a 1 GiB/s, 7-day, 3× fan-out workload with tail reads, “slow” diskless (250 ms batching to S3 Standard) is ~$15.2k/mo at ~350 ms produced. Switch to S3 Express, shrink the batch to 50 ms, and you’re at ~$46.3k/mo with ~60 ms produce—still ≈3.4× cheaper than best-case classic Kafka at ~$159k/mo. The aha: Express’ recent ~48% price cut (old calc ~$84.5k → $46.3k) You now buy ~6× lower latency and stay ~71% cheaper than disk-and-replication Kafka.
Things get even better, as Stan wrote, most S3 Express spend is the per-GiB bandwidth (PUT/GET), not request counts—so you can push latency down further with only a modest bill bump. Drop the batch to 10 ms (provided you have a beefy enough coordinator) for a best case ~20 ms production target and the model rises to ~$53.7k/mo (vs. $46.3k at 50 ms). If the coordinator scales and brokers can sustain ~10 ms PUTs, you get super-low-latency Kafka that’s still ~2–3× cheaper than the retail, disk-based baseline—while staying stateless, simpler to operate, and squarely aligned with cloud economics. Needless to say the next evolution in Inkless is to enable support for S3 Express Diskless Topics.
At the end Disks didn’t lose to speed; they lost to cloud pricing.
Diskless is the future of the Community
We heard the community—operators, platform teams, and practitioners running Kafka at scale. In the cloud, Diskless shouldn’t be a vendor-only opt-in; it should be an open, first-class Apache Kafka capability. The asks are practical and precise: keep transactions (idempotence, commit/abort) rock-solid end-to-end; avoid complexity creep (no maze of sequencers and roles); and support queues cleanly, without client surprises.
Two follow-ups sharpened the Diskless conversation:
- Slack’s KIP-1176 showed how fast tiering can reduce cross-AZ traffic—under specific durability/topology settings (e.g., zone-local acks=1 ingest with early offload of active segments)—while fitting neatly with Tiered Storage.
- AutoMQ’s KIP-1183 pointed toward pluggable backends, though it remains too vendor-specific in its current form.
Rather than force a choice, we took the rational path: pull the best ideas together and refocus the community on a single, durable approach.
The answer is Diskless 2.0. We listened to KIP-1150 and KIP-1176 feedback and paired Diskless with Tiered Storage, letting Kafka write once to object storage and present classic segments with minimal new surface area. Crucially, unlike general Tiered Storage, Diskless 2.0 configures no local data disks for durability: all writes land directly in object storage. Local segments are ephemeral, read-optimized materializations —not authoritative hot partitions—so there’s no cross-AZ mirroring of active segments. You avoid the inter-AZ tax, while keeping durability and classic compatibility. The result: unified formats, existing plugins (Iceberg, etc.) preserved, and zero-copy topic migration—flip a topic, not a cluster.
Perfect isn’t the enemy of good. We spent the summer closing 1150’s open questions and folding community input into a path the project can rally behind: unified format, simpler paths, zero-copy adoption. No false choices, no parallel estates—just a cleaner Kafka that’s ready for the next decade.
Introducing Tiered Diskless
In Tiered Diskless, the tiered path is the diskless path. Producers append to the diskless, write-optimized WAL (mixed partitions per object). Replicas then materialize those same bytes into classic, single-partition tiered segments. No second pipeline, no duplicate truth, no bespoke optimiser. Tiered Storage is the Optimiser..
The write-optimized WAL is fantastic when everyone reads the tail. It’s less great when consumers spread out across history—each fetch pulls a lot of irrelevant bytes. We used to solve this with a bespoke “object compactor” (KIP-1165). We’ve retired that idea. Tiered becomes this role, so we reuse mature code, keep the format unified, and leave downstream plugins (Iceberg, etc.) untouched.
At runtime, all replicas assemble per-partition local segments from the write ahead log, but a single designated replica uploads them to Tiered via tiering (leadership can rotate). Fetches follow a single, predictable priority order—Local → Tiered—and the Batch Coordinator stays off the hot read path, which steadies tail latencies and simplifies capacity planning.
Zero-copy migrations come for free
Switching Kafka to Diskless topics becomes real-time - users will be able to flip the topic type, inactivate and upload the active segment, and let new messages flow through the Diskless path. Consumers keep reading at the right offsets; once the last segments drain, on-disk partitions just disappear.
Switching Diskless → Classic is the reverse: flip back, actively tier any fresh WAL batches, and resume the classic path—writes land on the local active segment first, then tier to object storage—while background uploads continue as usual. No reprocessing, no second storage estate—just a clean handoff.
The result is a simpler system with fewer moving parts: write-optimized ingest, read-optimized history, and a single format everywhere. It scales with throughput, not history, and it’s adoptable in place—as we discussed - flip a topic, not a cluster.
New Diskless vs. Old Diskless
First, the diskless promise stays the same. You still get zone-local ingress/egress (no cross-AZ tax), write-to-object-store first, and a Batch Coordinator that assigns order logically without shuffling bytes. You still batch produce (>1 MB by default, tunable for latency vs. cost), and you can still pick your storage class (e.g., S3 Standard vs. S3 Express) to hit your price/latency point.
What changes is where reads come from, how replicas are used, and what happens to metadata and formats.
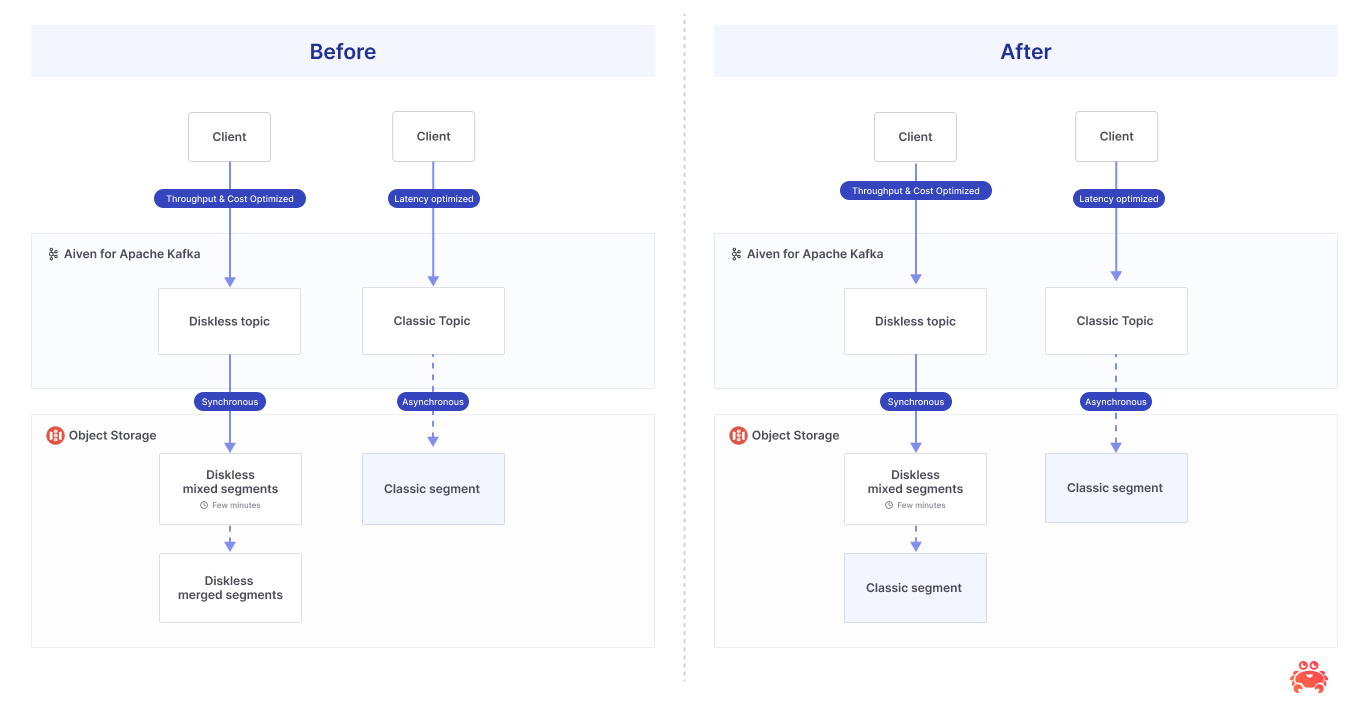
Reads move home.
Old Diskless fanned fetches through a distributed in-memory cache; any broker could serve any partition, and the Batch Coordinator sat on the hot path—noisy capacity planning, jittery tails. New Diskless has replicas that assemble per-partition local segments (disk + page cache) from the WAL and serve fetches themselves. Fetches try local segments first; if the offset has rolled, they go to tiered segments. The coordinator is off the read path, and tail latencies settle down.
Replicas matter again.
Old Diskless ignored KRaft: replicas and elections didn’t affect diskless partitions. In New Diskless, all replicas assemble local per-partition segments and serve reads; leadership is only used to pick the single broker that uploads that partition’s segments to Tiered via RLMM (and that role can rotate).
Metadata stops growing without bound.
Old Diskless let the coordinator’s state grow with history; “shared segments” were re-merged into bigger shared files, so you couldn’t delete one partition independently. New Diskless caps the coordinator to approximately two segments’ worth of metadata per partition before hand-off to Tiered; WAL objects are deleted once drained, and tiered segments are single-partition, so retention and deletion are clean and independent.
Formats unify; the ecosystem lights up.
Old Diskless wrote a different format from Tiered and couldn’t use Tiered plugins—no Iceberg, no RLMM reuse—forking your storage estate. New Diskless makes Tiered the compactor: one durable copy, two first-class views, and plugins (including Iceberg) work unchanged.
Diskless 2.0 is Kafka’s Completed Vision
OLD Diskless was an imitation of designs pioneered outside the project such as Warpstream’s architecture, NEW Diskless is innovation inside Apache Kafka—combining community feedback with cutting-edge design. By making Tiered Storage the optimiser, Kafka keeps one durable copy and exposes two first-class views (hot WAL and classic tiered segments). Formats unify, plugins stay unchanged, reads get saner, and operators just tweak topic configurations.
The original idea behind diskless was conservative: let Kafka absorb an opt-in replication path to object storage while preserving 100% of Kafka’s functionality in the same cluster. That idea is on its way out. With modern object storage, the hot path is object storage; disks are the exception, not the rule.
What this delivers: zero-copy topic migration, bounded metadata, replica-led fetches with predictable tail latency, and a storage model that scales with throughput, not history—all while staying Apache Kafka and ecosystem-ready.
At Aiven, we’re ready for a diskless future. Are you?
