


Open Source: Iceberg Topics is available as an experimental open-source project under the Apache-2.0 license. Explore the code and join the conversation on GitHub.
The streaming data landscape is evolving rapidly, and one of the most exciting developments is the integration between Apache Kafka and Apache Iceberg. While Kafka excels at real-time data streaming, organizations often struggle with the complexity of moving streaming data into analytical systems. Iceberg Topics for Apache Kafka promises to bridge this gap by enabling direct integration between Kafka streams and Iceberg tables, creating a seamless path from real-time ingestion to analytical workloads.
In this article, I'll share what Iceberg Topics are, walk you through a hands-on example you can run locally, and explore the potential this integration holds for modern data architectures. But first, let's understand what we're working with.
What is Apache Iceberg?
Apache Iceberg is an open table format designed for huge analytic datasets. Unlike traditional data formats, Iceberg provides features that make it ideal for data lakes and analytical workloads. It's become increasingly popular because it solves many of the pain points associated with managing large-scale analytical data, including:
- ACID transactions: Ensuring data consistency across concurrent operations
- Schema evolution: Adding, dropping, or renaming columns without breaking existing queries
- Time travel: Querying historical versions of your data
- Hidden partitioning: Automatic partition management without exposing partition details to users
What are Iceberg Topics?
Iceberg Topics represent a powerful integration between Kafka's streaming capabilities and Iceberg's analytical features. Instead of requiring complex ETL pipelines to move data from Kafka into analytical systems, Iceberg Topics allow Kafka to write data directly into Iceberg table format in object storage like S3 - all zero copy without unnecessary data replication across brokers, sink connectors, and sinks.
Before:
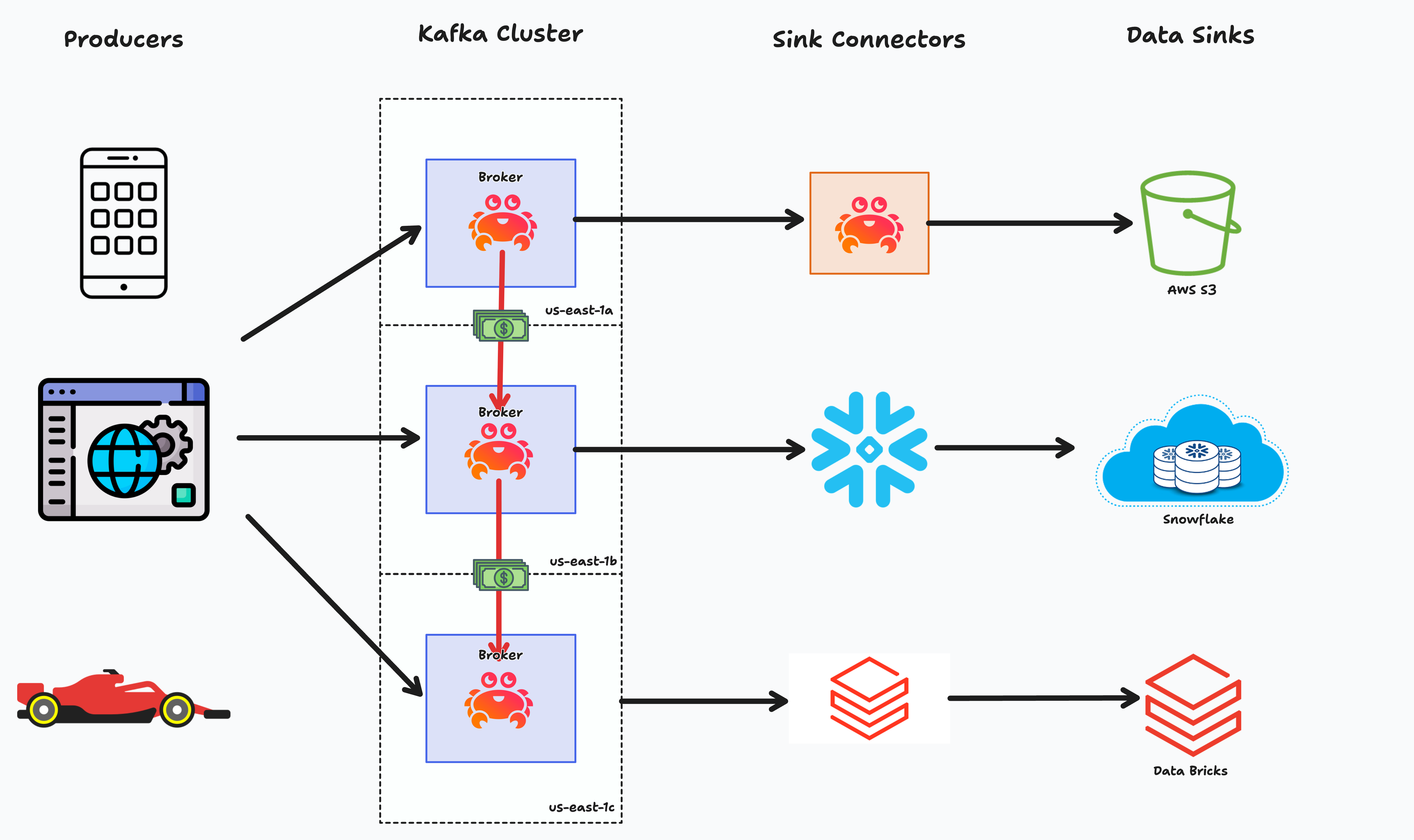
This integration leverages Kafka's Remote Storage Manager (RSM) plugin architecture to seamlessly transform streaming data into Iceberg tables. When you create a topic with Iceberg integration enabled, Kafka automatically:
- Streams data through standard Kafka topics as usual
- Transforms messages into Iceberg table format using schema registry integration
- Writes data directly to object storage as Iceberg tables
- Enables seamless querying through Spark, Trino, or other Iceberg-compatible engines once segments are written to the Iceberg table
After:
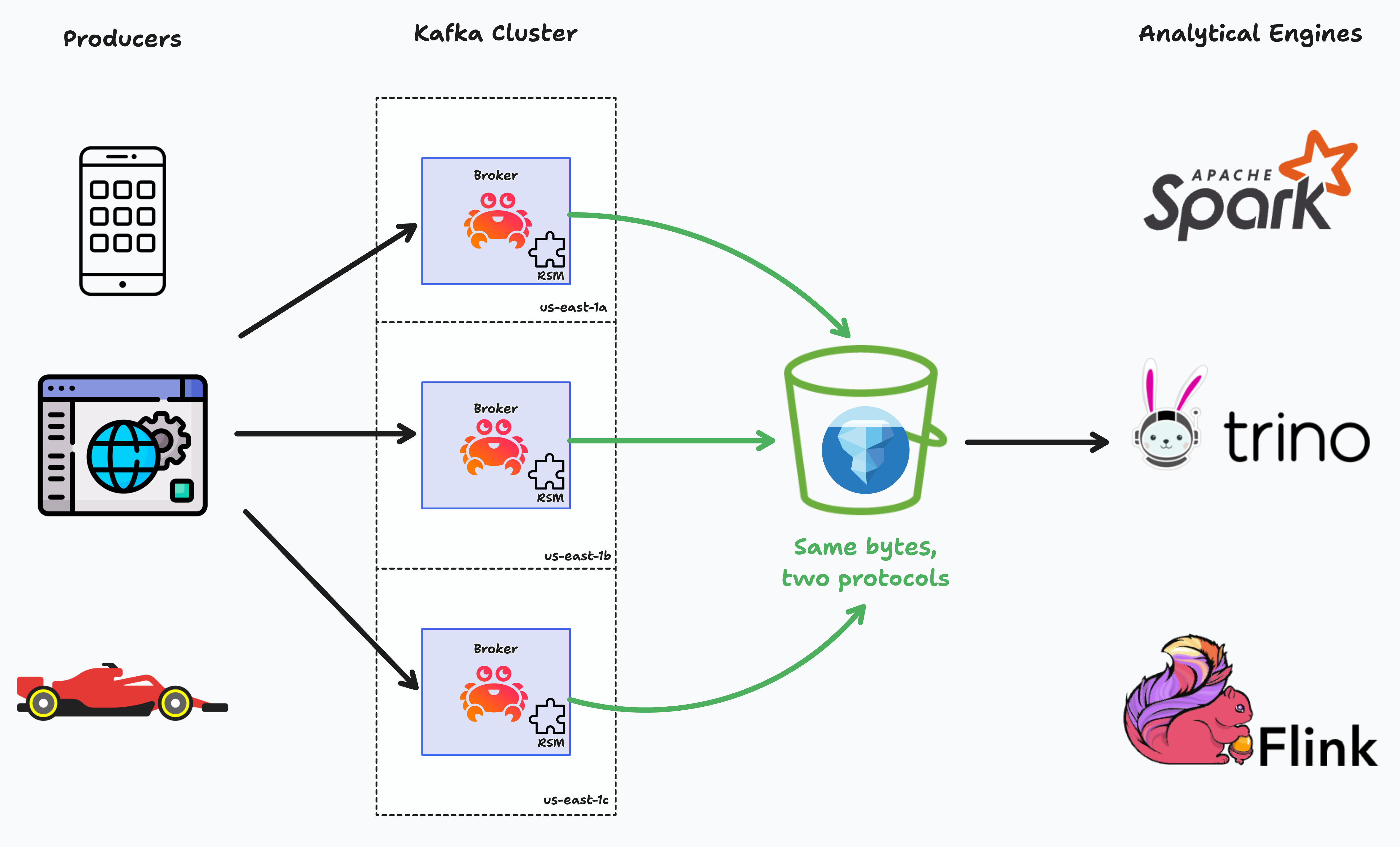
The beauty of this approach is that it maintains full Kafka API compatibility while adding analytical capabilities. Your existing producers and consumers continue to work unchanged, but now your streaming data is simultaneously available for real-time processing and analytical queries.
The Benefits of Iceberg Topics
Traditional architectures require separate systems for streaming and analytics, creating operational complexity and data duplication. With Iceberg Topics, you get:
Simplified Architecture: Eliminate complex ETL pipelines between streaming and analytical systems. Data flows directly from Kafka into queryable Iceberg tables.
Unified Data Model: Use the same schema for both streaming and analytical workloads, reducing inconsistencies and maintenance overhead.
Real-time Analytics: Query streaming data without waiting for batch processes to complete.
Cost Efficiency: Reduce infrastructure costs by eliminating duplicate storage and processing systems.
Operational Simplicity: Manage one system instead of coordinating between streaming platforms and data lakes.
Note: Iceberg Topics integration is still evolving in the Kafka ecosystem. The example in this article demonstrates the concept using Aiven's Remote Storage Manager plugin, which provides Iceberg integration capabilities for experimentation and development.
Run Iceberg Topics Locally with Docker
To understand how Iceberg Topics work, let's set up a complete local environment with Kafka, MinIO (for S3-compatible storage), Apache Iceberg REST catalog, and Spark for querying. This setup will let you see the entire data flow from Kafka streams to Iceberg tables.
Prerequisites
Before getting started, ensure you have the following installed:
- JDK version 17 or newer - Required for building the plugin
- Docker - For running the containerized services
- Make - For building the plugin code
Setting Up the Environment
First, you'll need to clone the Iceberg demo
Loading code...
Build the Remote Storage Manager plugin that handles the Iceberg integration:
Loading code...
This command compiles the necessary components that enable Kafka to write data directly to Iceberg format.
Next, start all the required services using Docker Compose:
Loading code...
This command starts several interconnected services:
- Kafka Broker: Configured with Remote Storage Manager for Iceberg integration
- Karapace Schema Registry: Manages Avro schemas for structured data
- MinIO: Provides S3-compatible object storage for Iceberg tables *
- Iceberg REST Catalog: Manages Iceberg table metadata
- Spark: Enables querying of Iceberg tables through notebooks
Wait for all containers to start completely. You can monitor the startup process by watching the Docker logs.
Creating and Populating Iceberg Topics
Once your environment is running, create a topic and populate it with sample data:
Loading code...
This demo script performs several important operations:
- Creates the
peopletopic with Iceberg integration enabled - Generates sample Avro records representing person data
- Produces messages to the Kafka topic using standard Kafka APIs
- Triggers automatic conversion of streaming data to Iceberg format
The magic happens behind the scenes - while your application produces and consumes data using standard Kafka APIs, the Remote Storage Manager plugin automatically converts the streaming data into Iceberg table format and stores it in MinIO.
Exploring Your Data
After the demo runs and Kafka uploads segments to remote storage, you can explore your data in multiple ways:
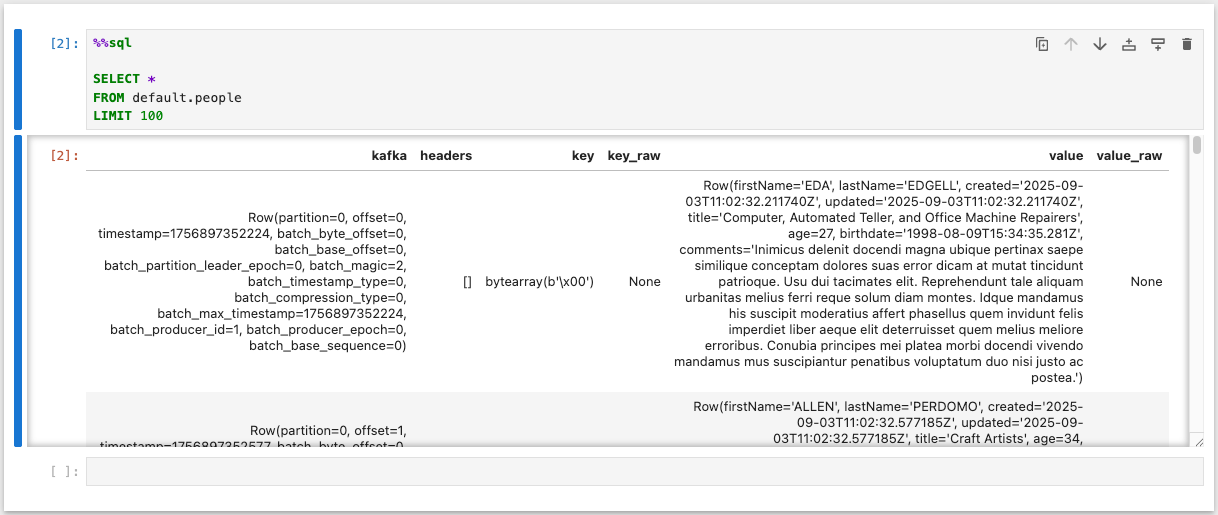
Query with Spark: Visit the Spark notebook at http://localhost:8888/notebooks/notebooks/Demo.ipynb to run SQL queries against your Iceberg tables. You'll be able to perform analytical queries on the streaming data using familiar SQL syntax.
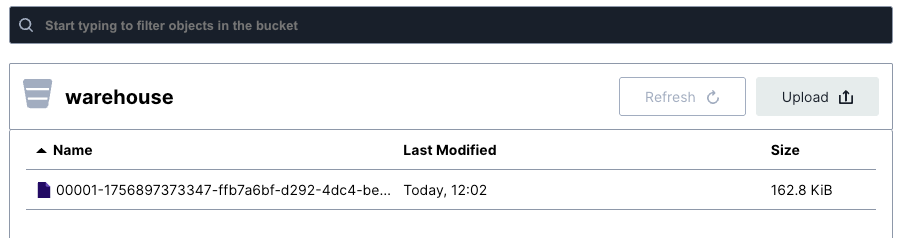
Inspect Storage: Browse the MinIO interface at http://localhost:9001/browser/warehouse to see the actual Iceberg table files and metadata stored in object storage.
What Makes This Powerful
This local setup demonstrates several key capabilities:
Immediate Querying: As soon as data is produced to Kafka, it becomes available for analytical queries through Spark - no batch processing delays.
Storage Efficiency: Iceberg's columnar format and compression provide efficient storage for analytical workloads while maintaining streaming performance.
ACID Compliance: Your streaming data benefits from Iceberg's ACID transaction support, ensuring consistency even with high-throughput streams.
Troubleshooting Common Issues
If you encounter problems during setup:
Build Issues: Ensure you have JDK 17+ installed and that your JAVA_HOME is set correctly before running make plugin.
Container Startup: Check Docker logs with docker compose logs [service-name] to identify startup issues. Services have dependencies, so ensure Kafka is healthy before other services start.
Schema Registry Connection: If you see schema-related errors, verify that Karapace is running and accessible at http://localhost:8081.
Storage Access: MinIO credentials are admin/password by default. If you see S3 access errors, check the MinIO service status and credentials.
Plugin Version Mismatch: If you see ClassNotFoundException: io.aiven.kafka.tieredstorage.RemoteStorageManager, the Makefile version doesn't match your build output. Check what version was built:
Loading code...
If you see a SNAPSHOT.tgz with a different version instead of core-0.0.1-SNAPSHOT.tgz, update the Makefile to match the version from the command above, for example:
bash
Loading code...
What Does Iceberg Topics Mean for Kafka?
The integration between Kafka and Iceberg represents a fundamental shift toward unified streaming and analytical architectures. Instead of maintaining separate systems for real-time and analytical workloads, organizations can now use Kafka as a single platform that serves both use cases.
For Stream Processing Teams: Continue using familiar Kafka APIs while automatically generating analytical datasets for data science and business intelligence teams.
For Data Engineering Teams: Eliminate complex ETL pipelines and reduce the operational overhead of maintaining separate streaming and analytical systems.
For Analytics Teams: Access streaming data immediately for real-time analytics without waiting for batch processes or dealing with data freshness issues.
For Organizations: Reduce total cost of ownership by consolidating infrastructure and eliminating data duplication across systems.
Ready to Explore Further?
The local example in this article provides a foundation for understanding Iceberg Topics, but the real value comes from experimenting with your own data and use cases. Consider how eliminating the boundary between streaming and analytical systems could simplify your data architecture and enable new capabilities.
The streaming analytics landscape is evolving rapidly, and integrations like Iceberg Topics are leading the way toward more unified, efficient, and capable data platforms. Whether you're processing IoT sensor data, financial transactions, or user activity streams, the ability to seamlessly bridge real-time and analytical workloads opens up exciting possibilities for your data-driven applications.
Learn More
Explore these resources to deepen your understanding of Kafka and Iceberg integration:
The future of streaming data is here - start building with Iceberg Topics today!

Table of contents
- What is Apache Iceberg?
- What are Iceberg Topics?
- The Benefits of Iceberg Topics
- Run Iceberg Topics Locally with Docker
- Prerequisites
- Setting Up the Environment
- Creating and Populating Iceberg Topics
- Exploring Your Data
- What Makes This Powerful
- Troubleshooting Common Issues
- What Does Iceberg Topics Mean for Kafka?
- Ready to Explore Further?
- Learn More