


Semantic routing: send the easy prompts to the cheap model
Benchmarks keep showing that picking the right LLM is hard. The easy answer is "just use the most powerful one." That works, but it is pricey. A small, cheap, or local model can handle many simple requests just as well as a frontier model, for a fraction of the cost.
That is what semantic routing is for. Use middleware that looks at an incoming request and decides which model should answer it. There are products that do this, but you probably already have a cache to pull back popular or recent responses fast. That same cache can store your routing examples and score how well each model is doing.
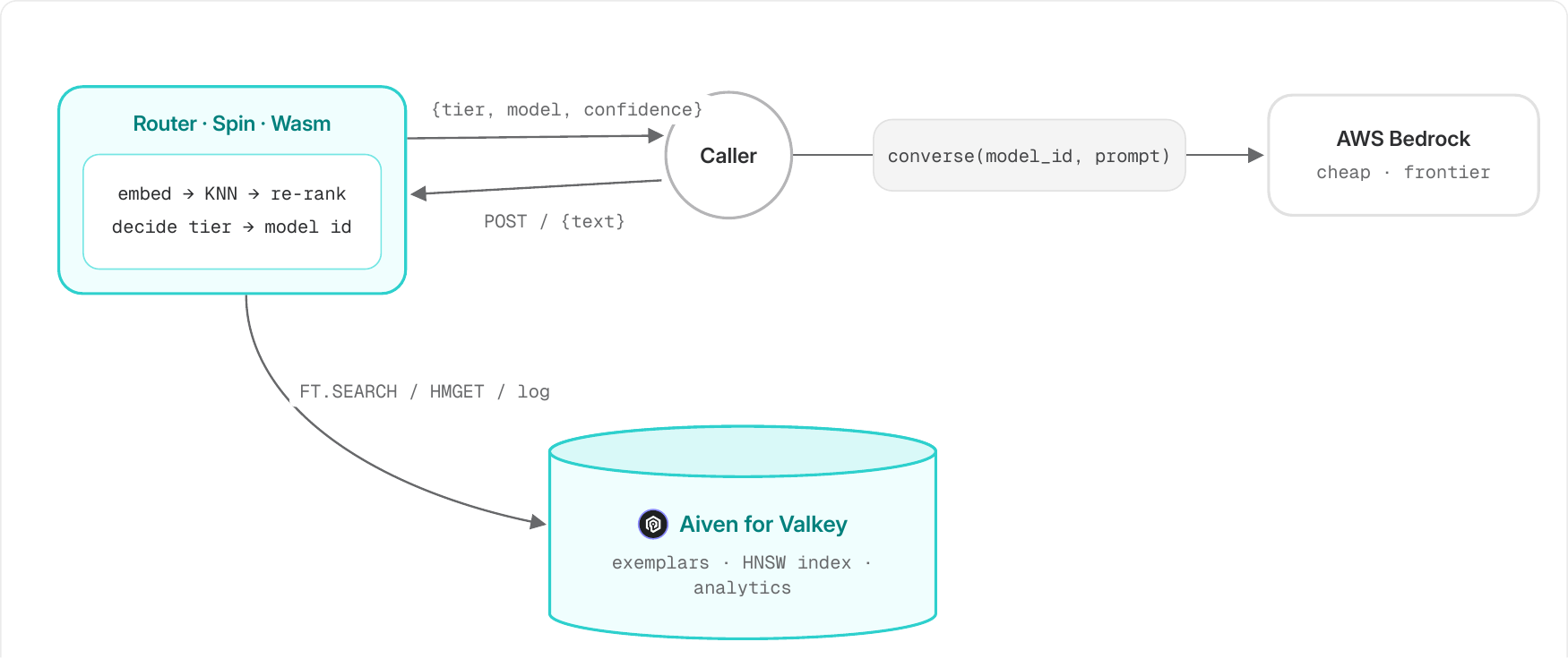
Let's talk about this using our demo, a Spin component that accepts an incoming prompt, and chooses a model based on similar prompts in our Aiven for Valkey instance. Hard prompts route to Claude Opus 4.8, a frontier model that on Bedrock runs about $75 USD per 1M output tokens. Easy prompts route to Amazon Nova Micro, which is 15 cents for the same output.
We'll introduce a primer on the underlying technology, identify logical integration steps, and lastly explore the actual cost savings that appeared while developing this post.
NOTE: I'm framing this decision around cost savings, but you can route this on whatever criteria based on model expertise or some other factor.
Understanding vector search and our corpus
The semantic part comes from vector search, also known as semantic search.
Vector search lets us compare texts based on a trained machine learning model. The Search Module is enabled by default on Aiven for Valkey, so there's no configuration.
Take the prompt How do you patch a hole in the drywall? The cheap model got picked to answer it. But the CLI showed us the reason wasn't great.
Loading code...
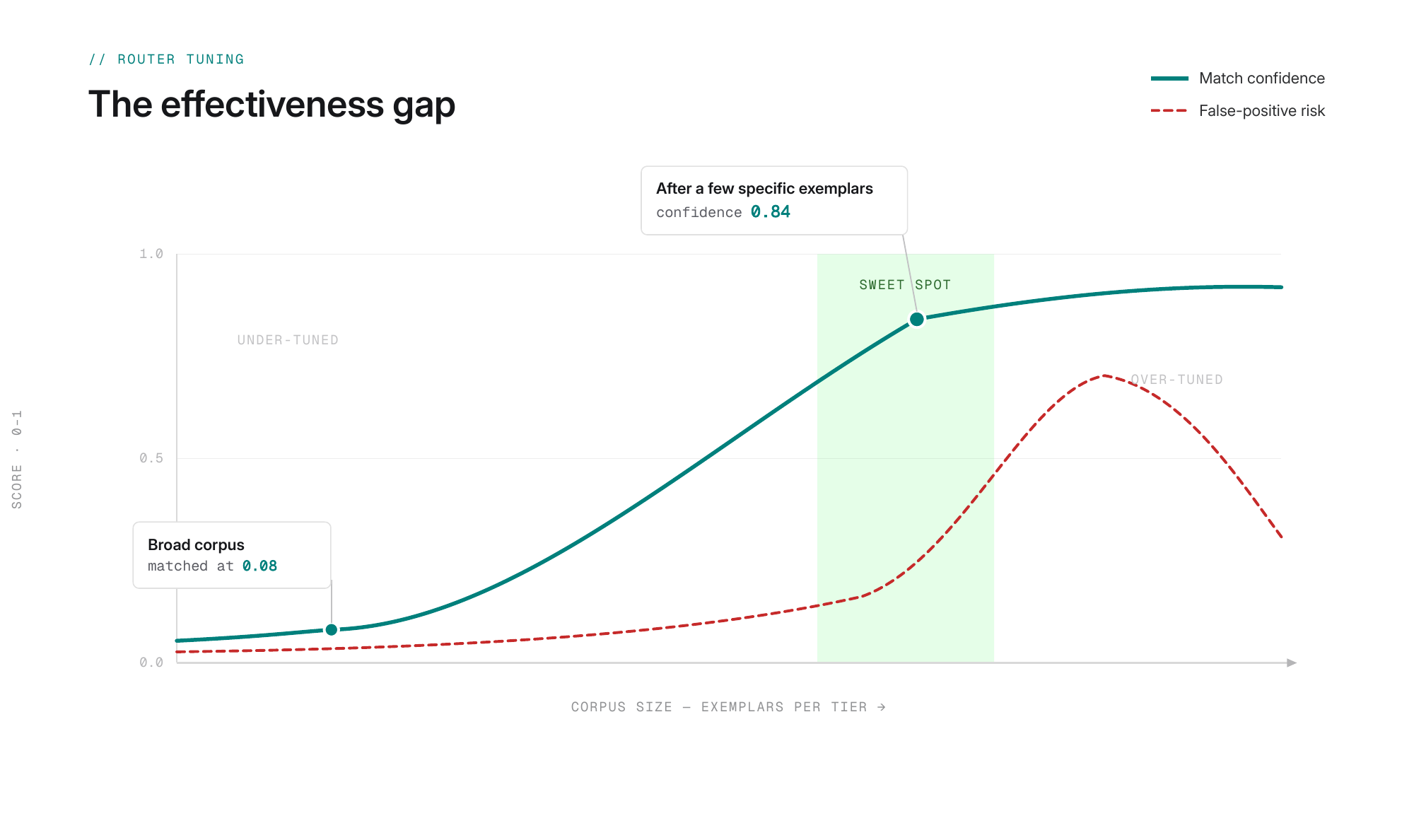
"Summarize this paragraph" isn't all that close to our question and the score shows. The confidence between the results back at 0.09. A perfect score is 1.0, so this match wasn't close, but it was the closest.
Our broad set of general-knowledge examples is meant to cover a wide range of questions. I asked a bunch of home improvement questions and got mostly reasonable picks. The one miss was "patching a drywall hole," which it decided was complicated enough to need a frontier model.
Let's add 30 specific prompts focused on home improvement, 16 cheap and 14 frontier.
Now when we run it again.
Loading code...
Now we still get the result we want, but the confidence is much stronger: 0.84 versus 0.08.
You don't have to write a definition for every prompt. There's a tradeoff in tuning the corpus. The more specific your examples, the more confident the results, but you also invite more false positives when certain words and phrases pull the distance the wrong way. Later in the post I'll cover ways to automate some of this with human-in-the-loop training.
The technical details
The whole routing decision lives in spin, our WebAssembly component built in Rust. This is the kind of app you push out to an edge node alongside Valkey and send its results to your main application, which means your setup can take advantage of regional pricing differences and availability. You can also run multiple systems alongside one another, each with their own corpus.
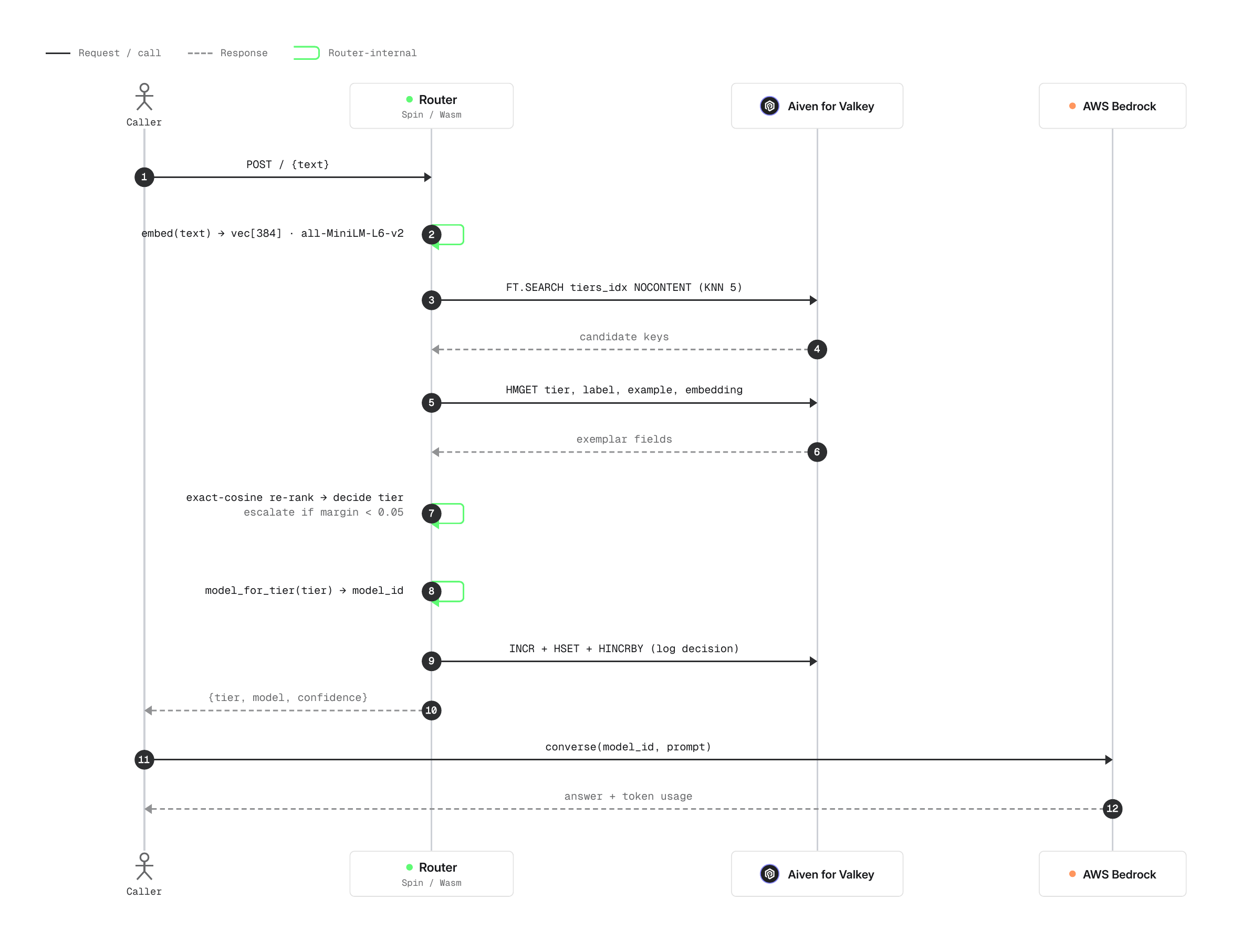
The text gets embedded with AllMiniLmL6V2, the same model we used to embed the corpus. Then Valkey's Search Module runs a semantic search over that embedding.
A minor gotcha: NOCONTENT and scalar-only results
A normal FT.SEARCH returns a nested array with the result documents, their fields, and scores all bundled together. But Spin's outbound Redis/Valkey interface only returns scalar replies (nil, status, int, bytes) and flat arrays. It can't read the nested structure vector search normally hands back.
The fix is two steps. Run the KNN with NOCONTENT, which makes Valkey reply with a flat [count, key, key, ...] array the scalar interface can read cleanly. Then fetch each candidate's stored vector with HMGET and re-rank that small handful of keys with an exact cosine, computed locally in the component. That rerank has an average call time 16µs (microseconds), so it isn't slowing the system down.
The router only decides. It returns a model id and stops. In our app, a thin boto3 client reads the results and makes the actual Bedrock Converse call. We use Bedrock's Converse API because it allows us to use the same code across a wide range of models Bedrock offers. Changing the model is just swapping the id string. The cheap model and the frontier model go through the exact same call.
Human in the Loop feedback
Misroutes will happen, and you need a way to fix them. That's where human-in-the-loop (HITL) feedback comes in. You can override the model for a single call, and if you want the fix to stick, teach it a new example. The active corpus then grows from real traffic instead of from a fixed list someone guessed at up front.
There is a natural integration into your systems. Many services have "Are you satisfied with this response" feedback options. Based on the feedback you could update the corpus with the given example.
Proving the savings
The routing and code is only worth it if it actually saves money, so the router logs every decision and adds them up. GET /analytics reports actual cost against a "frontier-everything" baseline.
Since the router is decision-only, it never sees Bedrock's real token counts. So it prices every call with the same assumed token profile against a pricing table in config, with assumed_tokens_per_call set to 800. The cost uses the model each prompt was actually routed to. The baseline is what that same call would have cost on the frontier model, and savings is the difference summed across all calls. GET /breakdown rolls the same data up per model. On a realistic mix where most traffic is easy, the savings land in the high tens of percent.
| tier | model | prompts | est cost | est savings | savings / 1M tok |
|---|---|---|---|---|---|
| cheap | eu.amazon.nova-micro-v1:0 | 15 | $0.000892 | $0.449108 | $37.43 |
| frontier | eu.anthropic.claude-opus-4-8 | 12 | $0.360000 | $0.000000 | $0.00 |
What to take away
Semantic routing is a quick way to right-size your costs. You don't need a classifier you have to train or a rules engine you have to maintain. You need a handful of example prompts per tier, an embedding model, and a vector search, and the routing decision falls out of nearest-neighbour similarity. When it's wrong, you teach it a new example and move on.
The pieces in this demo are deliberately boring, in the best way. The embedding model is built into the runtime, the vector store is the Valkey you might already have, and the routing logic is one Wasm component small enough to run at the edge. Swapping which model a tier maps to is a config change. Adding a third "balanced" tier means appending a TaskClass and re-running the loader.
The code is all in the semantic-router-demo repo. loader/ seeds the corpus, router/ is the Wasm component, and client/ closes the loop to Bedrock. The docs/phase-3-workshop.md guide walks you through building it yourself in about an hour.
