


I’ve been active in technical communities like PyData and codebar across the UK for nearly a decade now and owe much of my career to meeting and learning from cool people at events. Now, as someone with a professional interest in community organising, I spend a lot of my time looking for events to sponsor or speak at. But whilst finding technical events and communities can be tricky, I think I’ve found a solution using Kafka that might be useful for you too.
The Problem
Communities are organised across a variety of platforms, and one of the most popular, Meetup, doesn’t allow very open-ended search: you’re effectively restricted to searching events in one city at a time, with no way to filter by activity or scale of communities. I have a history of complaining about Meetup, but, rather than do that again, a few months ago I decided to build a tool to solve my (and hopefully some other people’s) problem.
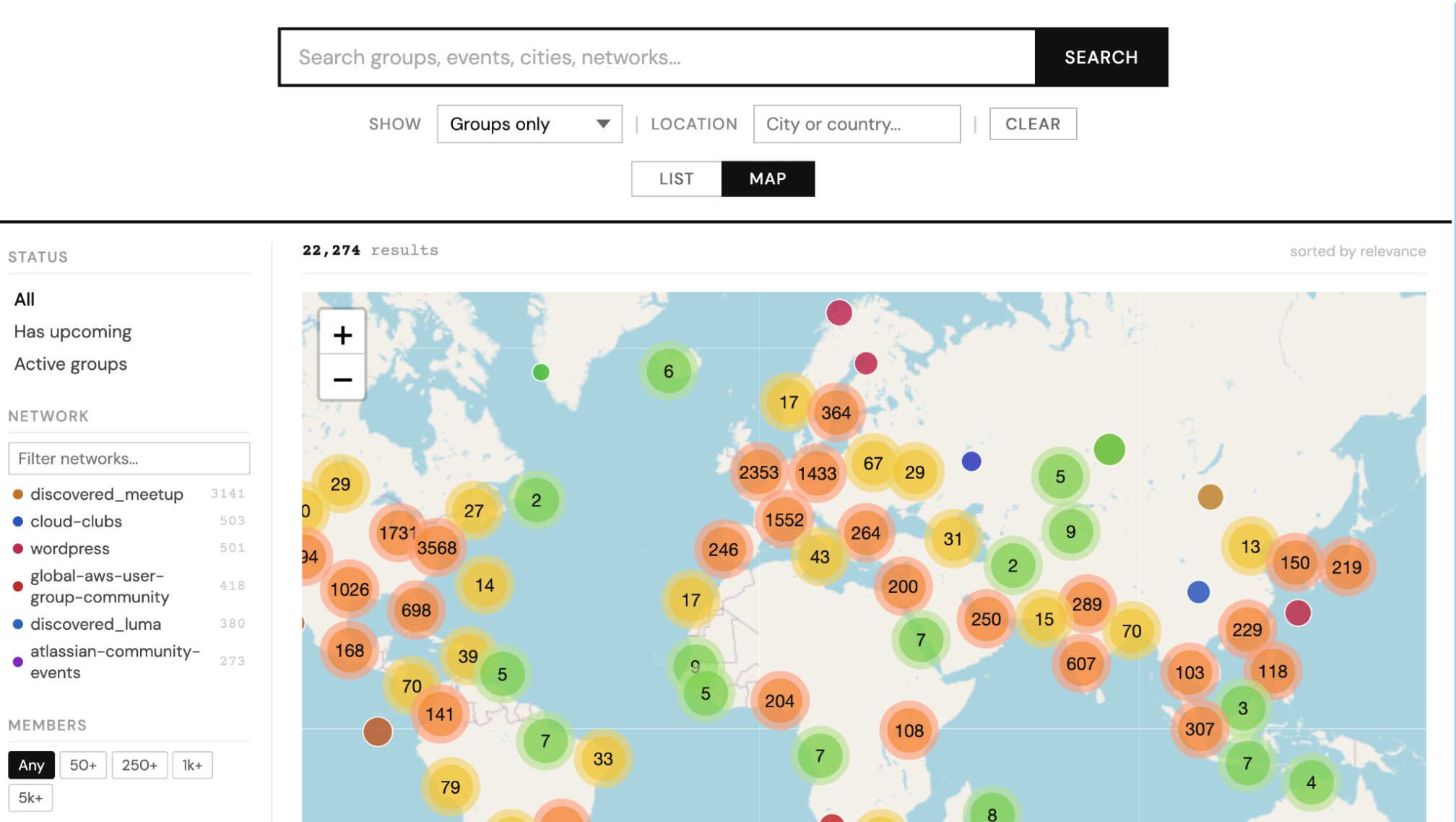
My goal was a search tool that lets you find events and groups across platforms like Meetup and Luma, with filters for locations, topics, and community size. To do this I needed to collect data on thousands of communities. This was no small ask: whilst the platforms in question don’t prohibit the collection of this data (both Meetup and Luma offer API access), they don’t exactly make it easy either.
Prototyping with Aiven
Architecting data products can be challenging, especially when starting from scratch. There are tools to select, ways of working to agree upon, SLAs to consider, components to name, and foot guns to avoid. It was no different when I set about building my own Community Event Search tool.
I started with local Python scripts and a Postgres instance running in Docker. This was straightforward enough to pull groups from the APIs, geocode venue addresses, store everything in Postgres, and build a map on top with Folium. It worked fine for a few hundred groups, and once I moved from running it locally to GitHub Actions for scheduled daily runs, and shifted my Postgres from my laptop to Aiven Free Tier Postgres, I could host the resulting map on GitHub Pages and share it publicly.
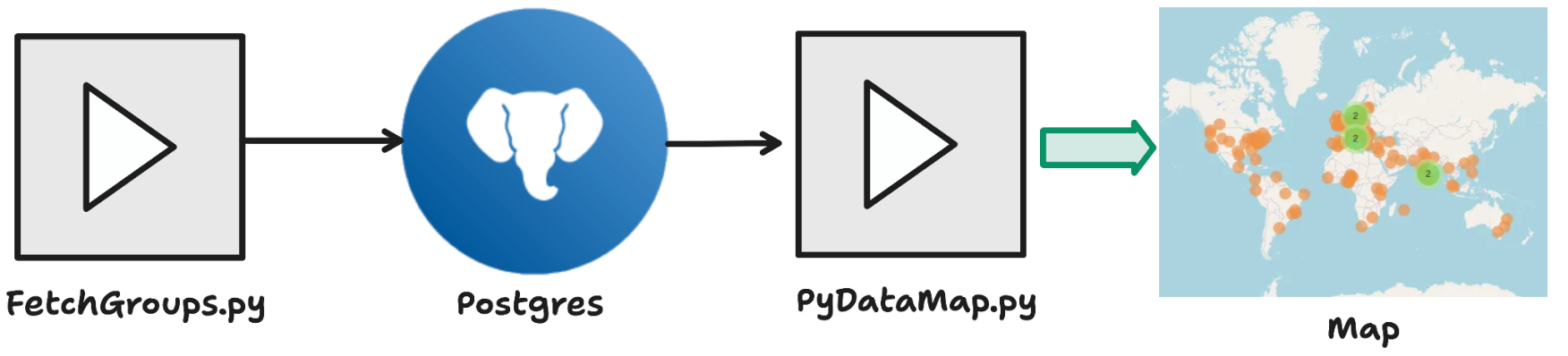
From there I wanted to keep adding more groups, but ran into my first real constraint: storage. The volume of events, venues, and groups quickly exceeded the 1GB cap on a free Aiven Postgres service. Upgrading to the Developer plan (currently $5/month) gave me an extra 7GB, and dropping the description field brought the total footprint down significantly. This solved my storage problem, but to collect data on the tens or hundreds of thousands of communities I was interested in would require a complete rethink of my architecture.
Scaling with Aiven
With storage sorted, the rate at which I could collect group data was now the limit . Specifically: the network speed of the GitHub Actions container running my fetch scripts. Large groups with hundreds of past events would also block the whole process as it was single-threaded. The obvious fix was to make the fetching distributed: deploy multiple workers pulling group URLs off a queue in parallel.
I moved to Aiven Apps (currently in preview) for stateless, horizontally scalable fetch workers, and used Aiven Free Tier Kafka to distribute the group URLs across them. To keep the fetch workers truly stateless I pulled the geocoding logic into a separate sink process (also an Aiven Apps), which handled Postgres ingestion and enforced Pydantic data contracts to guard against upstream API changes quietly corrupting the database.
This architecture was straightforward to set up directly with Terraform, and with Free Tier Kafka I could get through around 24,000 groups in roughly 7 hours after adding a second fetch worker - which was a satisfying jump from my prototype to something more closely resembling a production environment.
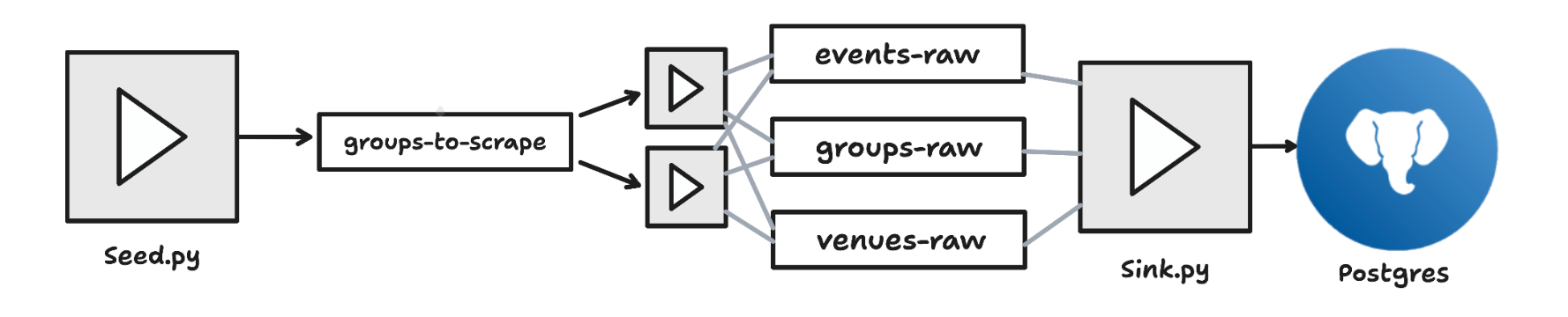
Limits of Free Tier Kafka
Free Tier Kafka gives you 5 topics and 2 partitions. Because at least one partition per topic is required per active producer or consumer, that 2-partition limit is a hard stop. The design literally cannot grow: you cannot add more workers without more partitions, and you cannot get more partitions without upgrading. So I upgraded to Dev Tier Kafka.
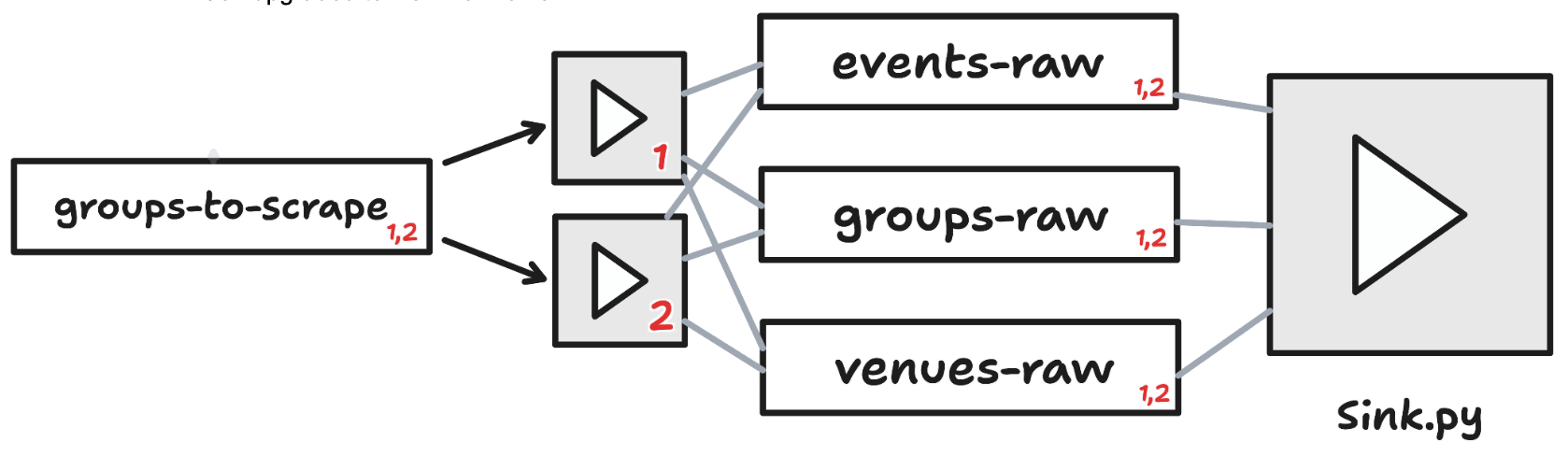
What you get with Dev Tier Kafka
Upgrading to dev tier is one click and after my Kafka cluster rebalanced I had 100 partitions and 20 topics to work with, which gave me the headroom for up to 100 fetch workers. This was what my pipeline needed: room to grow.
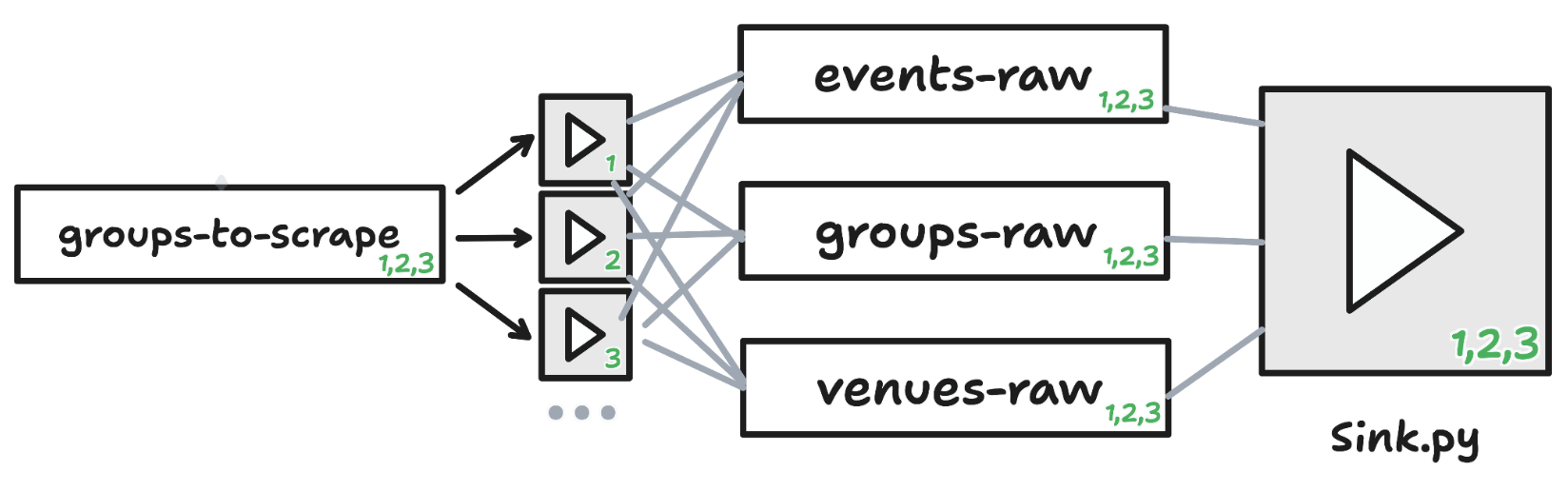
Adding one more fetch worker after the upgrade got me to 50,000 groups in 6 hours. The pipeline didn't need any code changes; it had room to breathe.
Dev Tier costs $35/month for managed Kafka. It also supports 1MB/s ingest, 2MB/s egress, 1–7 day retention (I only need one day of retention as my script runs daily and data is persisted in Postgres), Karapace included for Schema management, full TLS, and automation via CLI, API, or Terraform. Kafka Connect is available as a $20/month add-on, which would be very tempting if I swapped out Postgres for ClickHouse (I hate manually configuring Kafka to CH writes), but for now my hand-cranked sink service works great.
That’s more than fast enough for me as right now I’m only targeting a freshness of <24hrs on the data, so Dev Tier will be more than enough for me to collect data on every Luma and Meetup group every day with room to spare. And with that data I have everything I need to find the groups and events I’m interested in.
The Solution
The pipeline now indexes groups from Meetup and Luma, and you can explore the results at search.notanother.pizza. I've found communities I'd never have stumbled across through Meetup's city-by-city search, and events worth travelling for that simply don't appear when you're locked to a single city view. All as a result of building my own solution with an event driven architecture that can be applied to a variety of use cases. That's the problem I set out to solve, and I think this solution at least partially addresses it.
If you're building data pipelines, the approach holds regardless of scale: prototype on a free tier, upgrade when the constraint becomes real, and let managed services do the heavy lifting for the cost of a couple of pizzas. What problems could you solve with an approach like this?
You can find out more about Aiven's Developer Tier services including Kafka and Postgres here.
Aiven Apps is currently in preview. If you're interested in experimenting with it, get in touch.
