


According to an MIT study, 95% of AI projects fail to deliver value. I've been thinking about why that number is so stubbornly high, and I've come to believe the answer isn't about models,compute or even data quality in the traditional sense -It's about context.
We've gotten really good at collecting data. Petabytes of it. But when you ask a simple question - "who are our most profitable customers?" - things fall apart. The data exists in six different systems, nobody knows which table is the canonical one, the column called profit is actually revenue, and the business rules that matter live in someone's head or a Confluence page nobody's updated since 2023.
Now we're asking AI agents to navigate this same mess. And here's the thing, an AI agent is essentially a very smart intern on their first day. Brilliant, eager, and completely clueless about your organization. Without context, they make confident mistakes. Expensive ones.
Building context for data
Today we're announcing Aiven for DataHub - a fully managed, open source data catalog and the first product in our Context initiative, whose job is straightforward: give both humans and AI agents the context they need to find, understand, and reason with data across all your systems, on Aiven and beyond.
A few things that make this different:
- It's open source: DataHub Core, not a proprietary fork. Your metadata, your rules.
- Unlimited users, no per-seat licensing: Everyone in your organization can access the catalog. Data engineers, analysts, agents, your CEO. We don't believe context should be gated by seat count.
- Deployed in minutes, not months: Traditional data catalog rollouts take months and a serious upfront investment just to get started. We think that's backwards.
How it works under the hood
Aiven for DataHub isn't a single monolithic service, it's a stack of Aiven services working together, each doing what it does best.
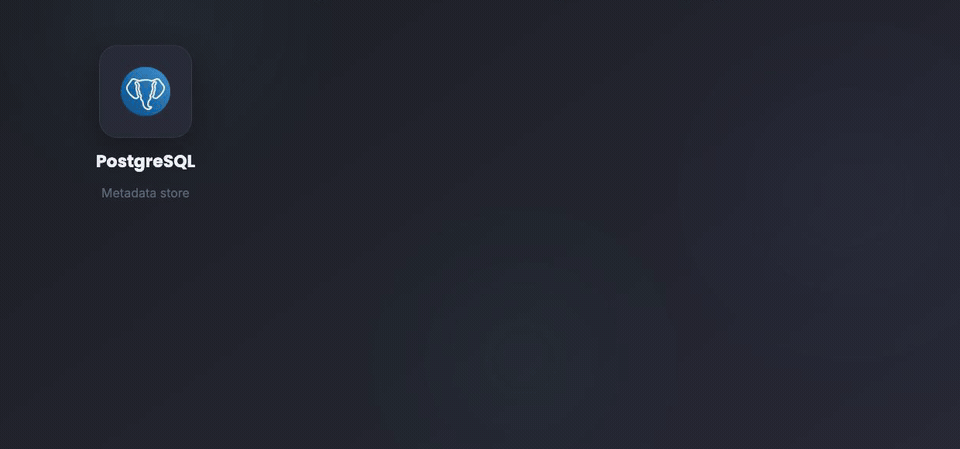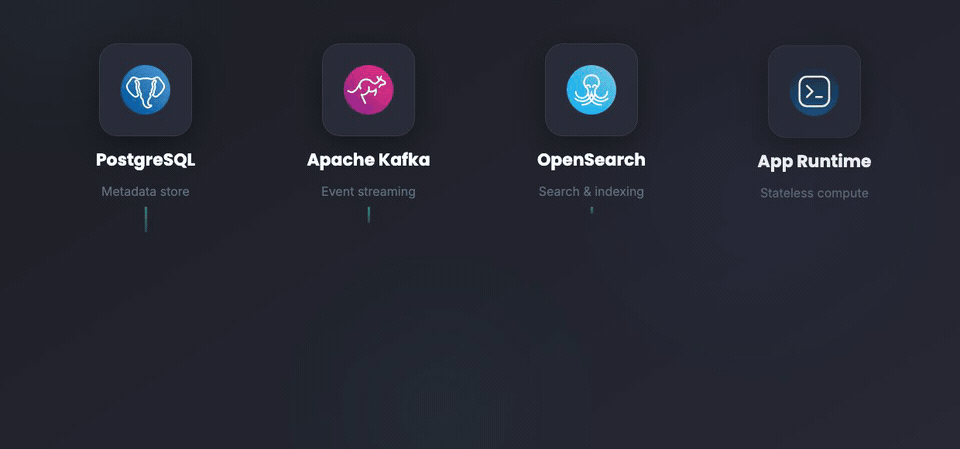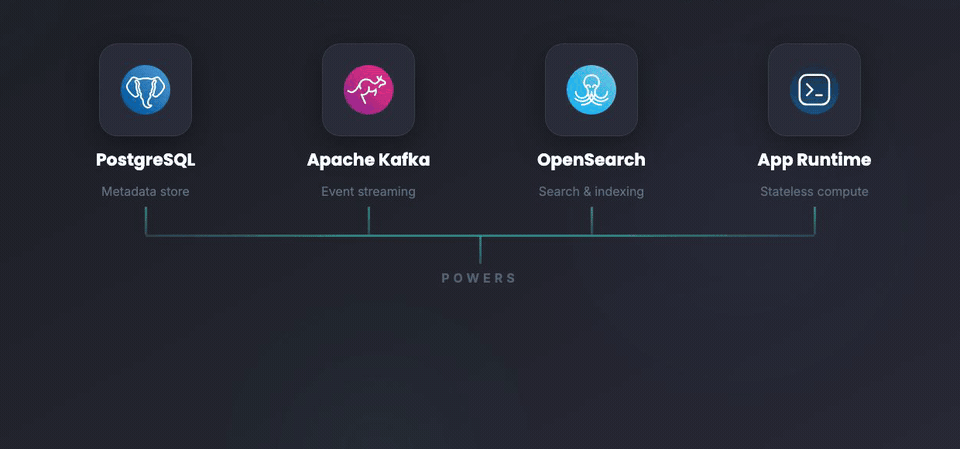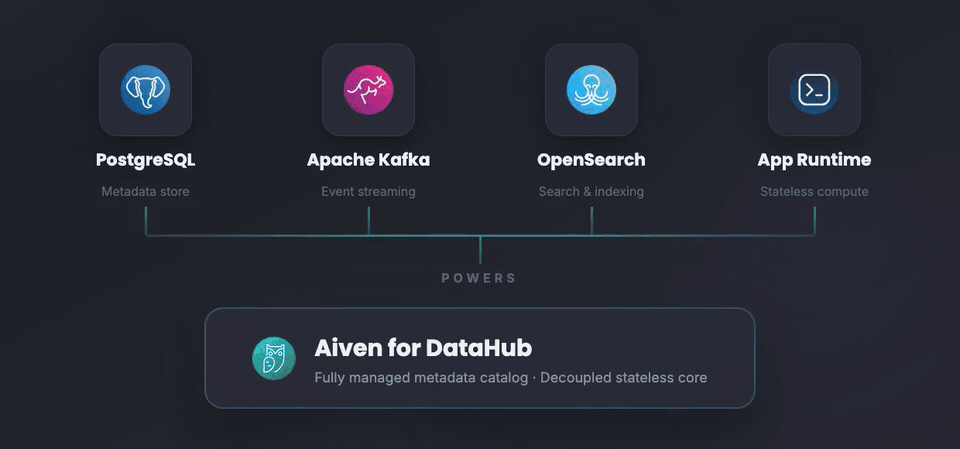
Aiven for DataHub architecture
When you create a DataHub instance in the Aiven Console, we automatically provision and wire together:
- Aiven for PostgreSQL® - stores all your metadata. Schemas, descriptions, ownership, tags. The durable source of truth.
- Aiven for Apache Kafka® - handles metadata ingestion and change events. When something changes in your data estate, Kafka propagates that context in real time.
- Aiven for OpenSearch® - powers search and discovery. When you type "customer data" into the search bar, OpenSearch is what makes it fast and relevant.
- Aiven Apps - stateless containers running the DataHub frontend, the General Metadata Service (GMS), etc. No state to lose, easy to scale.
The key insight here is that you already trust these services individually. We run PostgreSQL, Kafka, and OpenSearch for thousands of customers. Aiven for DataHub composes them into something greater than the sum of its parts.
You don't have to manage any of this. No Helm charts, no Kubernetes tuning, no late-night pages because your metadata store ran out of disk. We handle the infrastructure so you can focus on what actually matters - the context itself.
What you can actually do with it
Find your data in seconds
Search across every dataset, table, column, dashboard, and pipeline in your organization. DataHub indexes metadata from your connected systems and makes it searchable instantly. No more Slack-hunting to find out which database has the customer orders table.
Connecting your Aiven services is a few clicks. Connecting external systems - dbt, Databricks, Snowflake, and more - is straightforward through DataHub's ingestion framework.
See how data flows
Lineage is where things get really powerful. You can trace how data moves from a PostgreSQL table, through Kafka, into ClickHouse®, and out to a Superset dashboard - column by column.
This matters when someone asks you to rename a database column and you need to know what breaks downstream.
Give your AI agents a brain
DataHub supports a Model Context Protocol (MCP) server, which means your AI agents can use the catalog as a context layer. Instead of guessing which table to query or what a column name means, the agent asks DataHub.
You can connect DataHub's MCP server to an AI agent, ask "what data can I use to calculate the average order value from our e-commerce store?", and watch the agent search through DataHub, find the right datasets, understand the business rules, and propose a correct query.
Without the catalog? The same agent picked the wrong dataset from a completely wrong system, used revenue and called it profit, and exposed customer PII. Very confident, yet very wrong.
With a data catalog as the context layer? The agent found the right table, respected the documented rules, correctly identified all the fields, and didn't output sensitive data. Same model, same prompt, wildly different outcomes.
I like to think of it as: context quality² × LLM = outcome. The model matters, but the context matters exponentially more. If you want a deeper take on this, I made a whole talk explaining why your data catalog is your AI's brain.
Why managed?
You can absolutely self-host DataHub. It's a great open source project, and the community around it led by Acryl Data is excellent. We chose DataHub specifically because of its maturity, and its active ecosystem, and we are committed to contributing to the open-source.
But self-hosting a data catalog means you're now in the business of running PostgreSQL, Kafka, OpenSearch, and a set of applications. You need to handle upgrades, encryption, VPC integration, backup strategies, and the inevitable incident where the search index falls over.
For teams that want to focus on data governance and context rather than infrastructure operations, a managed offering makes sense. Deploy in minutes, connect your services with a few clicks, and start seeing value immediately.
We believe that infrastructure should be managed. Full stop. That's a core Aiven principle, and it applies here too.
Getting started
Aiven for DataHub is available now in Limited Availability. We're onboarding teams through guided PoCs so we can make sure the experience is right for your data estate.
Check out our short walkthrough showing the full setup - data discovery, lineage, and an AI agent using the MCP server to reason across a real data estate.
If you’re ready to give your data and your agents the context they deserve, then reach out through our DataHub page or talk to your Aiven customer representative, and we'll get a PoC set up for you.
