


In the modern data infrastructure stack, "Hybrid Search" has become the default answer for relevance. We know that Sparse Vectors (Lexical/BM25) are great for precision, and Dense Vectors (Embeddings) are unbeatable for semantic context.
The industry standard is to run these two searches in parallel and mash the results together using Reciprocal Rank Fusion (RRF).
But there is a flaw in this architectural pattern: It treats these vector spaces as disjointed silos. RRF doesn't combine the intelligence of your models; it simply interleaves their results.
In a recent deep-dive session hosted by Aiven’s Dima Kan and AI Powered Search author Trey Grainger, a new concept was introduced to solve this disconnect: Wormhole Vectors.
While this advanced architectural pattern is Trey Grainger’s brainchild, we at Aiven realized it offers a practical roadmap for developers using OpenSearch. Inspired by his research, we decided to break down exactly how you can implement this theory to traverse disjointed vector spaces.
Here is a technical breakdown of what Wormhole Vectors are, the graph theory behind them, and how they allow developers to traverse between sparse, dense, and behavioral spaces to uncover results that standard hybrid search misses.
The Problem: The "Black Box" of Embeddings
We often visualize vector spaces as orthogonal realities:
- Sparse Space (Inverted Index): High-dimensional (10^6+), discrete, explainable. (e.g., The token
postgresexists in Doc A). - Dense Space (Embeddings): Lower-dimensional (~768), continuous, abstract. (e.g., A floating point array representing "database").
Traversing from Sparse → Dense is computationally straightforward. You query for "Postgres," find the top k documents, take their pre-computed embeddings, and average them. You now have a "centroid" vector representing that keyword concept in dense space.
But traversing Dense → Sparse is much harder. If you start with a vector, how do you derive a keyword query that explains it? How do you turn a float array back into English (or code)?
This is where the Semantic Knowledge Graph comes in.
The Solution: The Semantic Knowledge Graph (SKG)
Trey Grainger posits that we don't need a massive LLM to translate vectors back to keywords. We can use the data structures we already have in engines like OpenSearch, specifically, the relationship between the Inverted Index and the Forward Index.
The Math: Foreground vs. Background Analysis
To traverse from a Dense Vector back to a Sparse representation (keywords), we treat the search engine as a graph.
- The Anchor: You run a dense vector query and retrieve a "Bag of Documents" (e.g., the top 50 results for a vector query). This is your Foreground Set.
- The Universe: The rest of your index is the Background Set.
- The Traversal: We are looking for terms that are statistically significant in the Foreground compared to the Background.
We aren't just looking for frequent terms (stopwords like "the" or "and" are frequent everywhere). We are looking for terms with a high probability of appearing in the Foreground set—P(t|F)—relative to their probability in the Background set—P(t|B).
The Scoring Function:
Score(t) = P(t|Foreground) / P(t|Background)
A Concrete Example: Disambiguation via Graph Traversal
Imagine a vector query lands in a region of documents containing the word "Java".
-
Scenario A: The document set also contains terms like Hibernate, Scala, VM, Backend.
- The SKG analysis sees these terms appear disproportionately high compared to the global index.
- Resulting Sparse Query:
Java AND (Hibernate OR Scala OR Backend)
-
Scenario B: The document set contains terms like Sumatra, Coffee, Roast, Island.
- Resulting Sparse Query:
Java AND (Coffee OR Sumatra)
- Resulting Sparse Query:
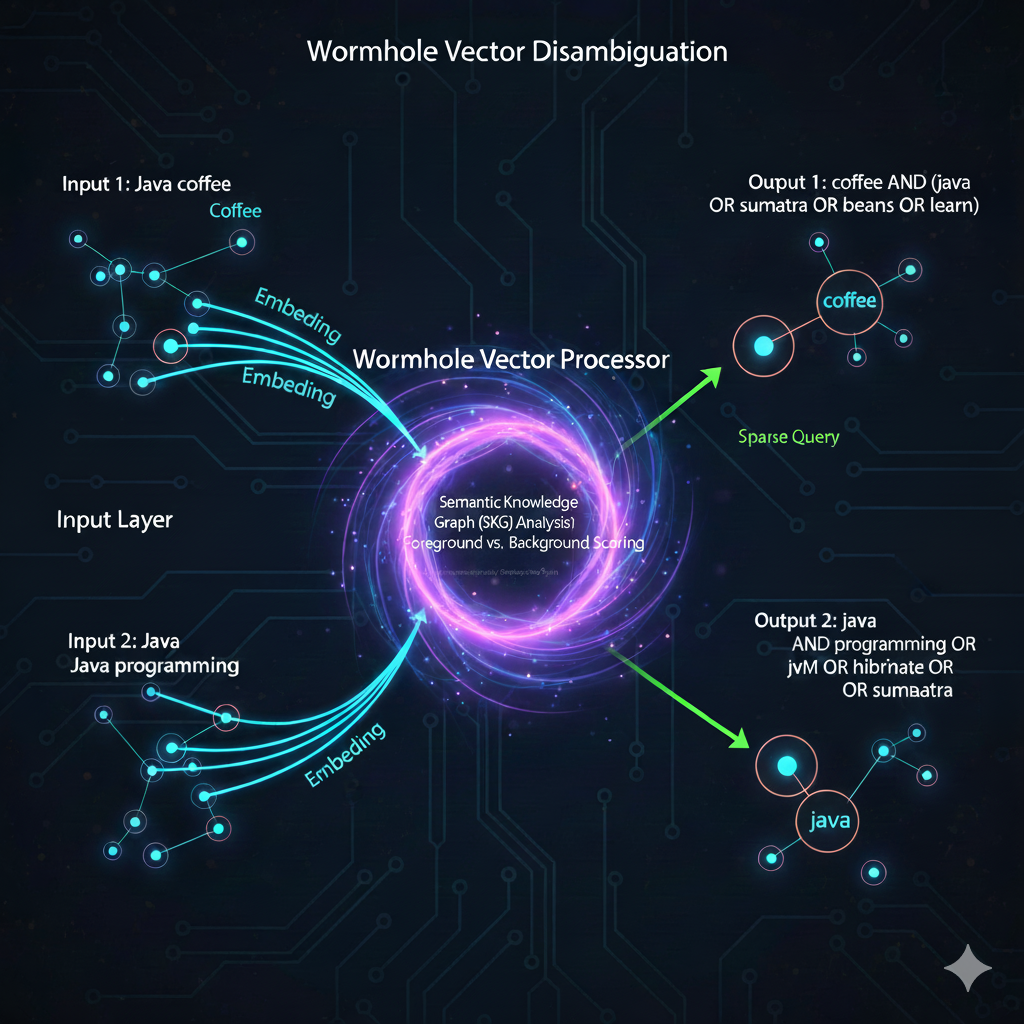
Graph showcasing how wormhole vector disambiguates queries on the sparse / keyword level.
By traversing the edges of this graph, mapping Terms → Documents → Related Terms, we can dynamically generate a sparse lexical query that "explains" the dense vector region.
The "Wormhole" Workflow
A "Wormhole Vector" is essentially a derived vector that allows you to hop between these spaces using the Document Set as the bridge.
Here is how a developer might implement a "Wormhole" traversal loop:
- Start in Space A (Lexical): User searches for
server.- Result: A mixed bag of documents (computer servers and restaurant servers).
- Traverse to Space B (Dense): You create a wormhole vector by averaging the embeddings of the top results.
- Result: The vector lands in a "mushy" middle ground.
- Refine via Knowledge Graph: You perform the SKG analysis described above on the document set. You discover two distinct clusters of significant terms:
{linux, devops, rack}and{tip, waiter, food}. - Hop to Space C (Behavioral): You utilize a third space, Behavioral Embeddings derived from matrix factorization of clickstream data.
- You query the behavioral space with the
{linux, devops}concept. - Result: You find that users who click on "Linux Servers" also click on "Raspberry Pi," even if the term "Server" never appears in the Raspberry Pi description.
- You query the behavioral space with the
Why This Matters for Engineers
This isn't just academic theory. It solves two massive production problems:
- The "Zero Result" Problem: If a user searches for a concept that has zero keyword overlap (e.g., searching "sweet dough ring" but the item is indexed as "Donut"), a standard lexical search fails. A Wormhole traversal bridges the vocabulary gap without manual synonyms.
- Explainability: Vector search is often a "black box." By using the SKG traversal to map dense vectors back to sparse keywords, you can show the user why a result appeared (e.g., "Matched on concept: Pastry").
Implementation with Aiven for OpenSearch®
You can build this architecture today using Aiven's free OpenSearch.
- Sparse Layer: Standard text indices.
- Dense Layer: The k-NN plugin.
- The Wormhole: Use
significant_termsaggregations to perform the SKG traversal.
Pseudo-code for the "Wormhole Hop":
Loading code...
Note: For the complete, production-ready queries (including the exact aggregation syntax and "final query" construction), check out the examples in the GitHub repository.
Summary
Most hybrid search implementations hit a ceiling because they treat keywords and vectors as separate silos. Wormhole Vectors break that ceiling by using your document set as a universal translator.
This gives you two massive advantages. First, you can recommend products based on behavior (like showing phone cases to phone buyers) without manual rules. Second, you gain explainability. Instead of trusting a vector's "black box," you can generate the exact keywords that define a cluster, making debugging significantly easier.
Don't just mix your search results, connect them.
Ready to build your own Wormhole?
Get started by spinning up a fully managed Aiven for OpenSearch® service and start experimenting with high-dimensional vector traversals today.
Watch the Full Episode
Catch the full discussion between Trey Grainger and Dima Kan, including a technical Q&A: Watch: Beyond Hybrid Search with Wormhole Vectors

Table of contents
- The Problem: The "Black Box" of Embeddings
- The Solution: The Semantic Knowledge Graph (SKG)
- The Math: Foreground vs. Background Analysis
- A Concrete Example: Disambiguation via Graph Traversal
- The "Wormhole" Workflow
- Why This Matters for Engineers
- Implementation with Aiven for OpenSearch®
- Summary
- Ready to build your own Wormhole?
- Watch the Full Episode