Active-passive setup
In this setup, there are two Apache Kafka® clusters, the primary and secondary clusters. The primary cluster contains the topic topic. The "active" cluster serves all produce and consume requests, while the "passive" cluster serves as a replica of the "active" cluster without running any applications against it.
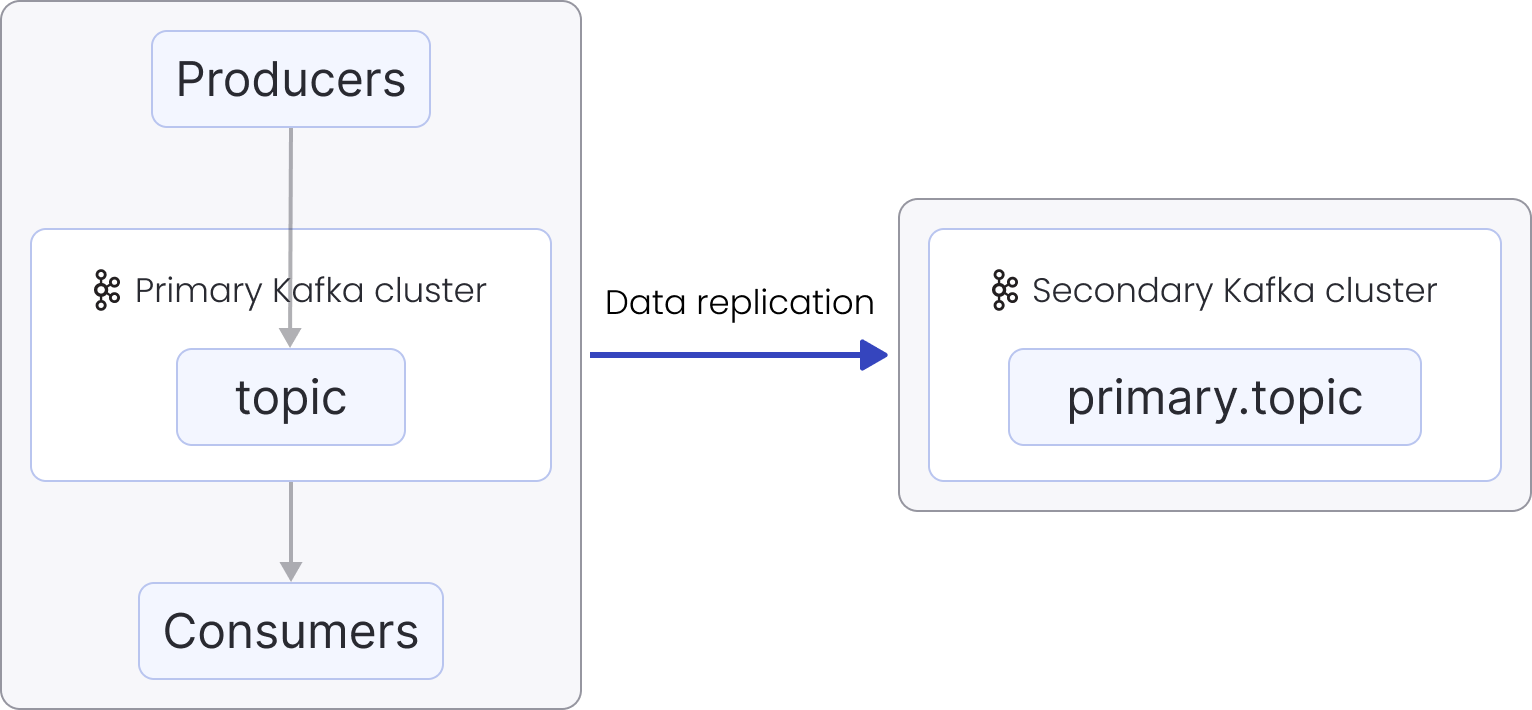
- All the clients (producers and consumers) work with primary.
MirrorMaker 2 replicates the topic from primary to secondary (the
remote topic name is
primary_alias.topic_namewhereprimary_aliasis remote topic name). - In case a disaster happens to the primary cluster and it becomes inaccessible for a long time for all the clients as well as MirrorMaker 2, the replication stops and some data may remain un-replicated in the primary cluster. It may not reach the secondary cluster before the disaster.
- The clients switch to the secondary cluster. Consumers continue
consuming from the replicated topic
primary.topic, and the producers start producing into this topic. - Alternatively, identical topics can be created in both primary and secondary clusters by setting replication flow to use IdentityReplicationPolicy replication policy. The producers start producing into it directly, and consumers switch to it when they are done processing remote primary.topic. This approach might be more convenient when a future fallback to the primary cluster is needed.
Disaster Recovery
To enable a DR scenario, the backup cluster (Cluster B) must have topics with the same name as the primary cluster (Cluster A). By default, this is not the case, so all replication flows must use the IdentityReplicationPolicy replication policy to guarantee this.
When a replication flow is created, it will mirror all topics based upon
the allow list or deny list configuration of the replication flow. The
allow list should be set to .* to guarantee that all internal topics such
as consumer offsets for Apache Kafka® Connectors and consumer groups,
and schemas for
Karapace.
Failover
When a cluster is replicated using MM2, it will have a different service URI and certificates that need to be considered when transitioning applications to the backup cluster instead of the primary one.
Given that Cluster B is designed for DR failover, promoting Cluster A as the primary cluster after a failover scenario requires recreating the data in Cluster A from Cluster B using MM2, but in reverse. Existing topic data in Cluster A must be deleted to avoid duplicates since all data from Cluster B would be replicated.