
Data streaming is reshaping how we handle and process data in real time. In this post, we'll explore the fundamentals of data streaming, its key components, and the transformative impact it has across various industries.
Whether you're a seasoned data professional or just curious about the latest technological trends, this guide will provide you with a comprehensive understanding of data streaming and its growing significance in our digital world. Are you ready to dive in?
TL;DR — If you’re in a hurry
- Streaming data is a continuous, real-time flow of data, unlike batch ETL which involve periodic, pre-scheduled movement of data.
- It enables immediate insights for human decision making and automatic triggers for machine actions, giving businesses a significant competitive advantage.
- Real-world applications of data streaming range from fraud detection to personalized customer experiences.
- Emerging trends like AI and IoT integration are set to further revolutionize data streaming capabilities.
- Apache Kafka® and Apache Flink® are leading technologies that facilitate efficient data streaming and real-time stream processing.
- Aiven provides managed services that simplify the complexity of streaming, making it accessible for businesses of all sizes.
- Security and compliance are central to Aiven's data streaming services, ensuring data integrity and security.
- Aiven's platform allows for easy integration of data streaming into existing business processes, supporting real-time analytics and event-driven architecture.
- Streaming real-time data is essential for businesses who want to satisfy customer expectations and stay ahead of the competition.
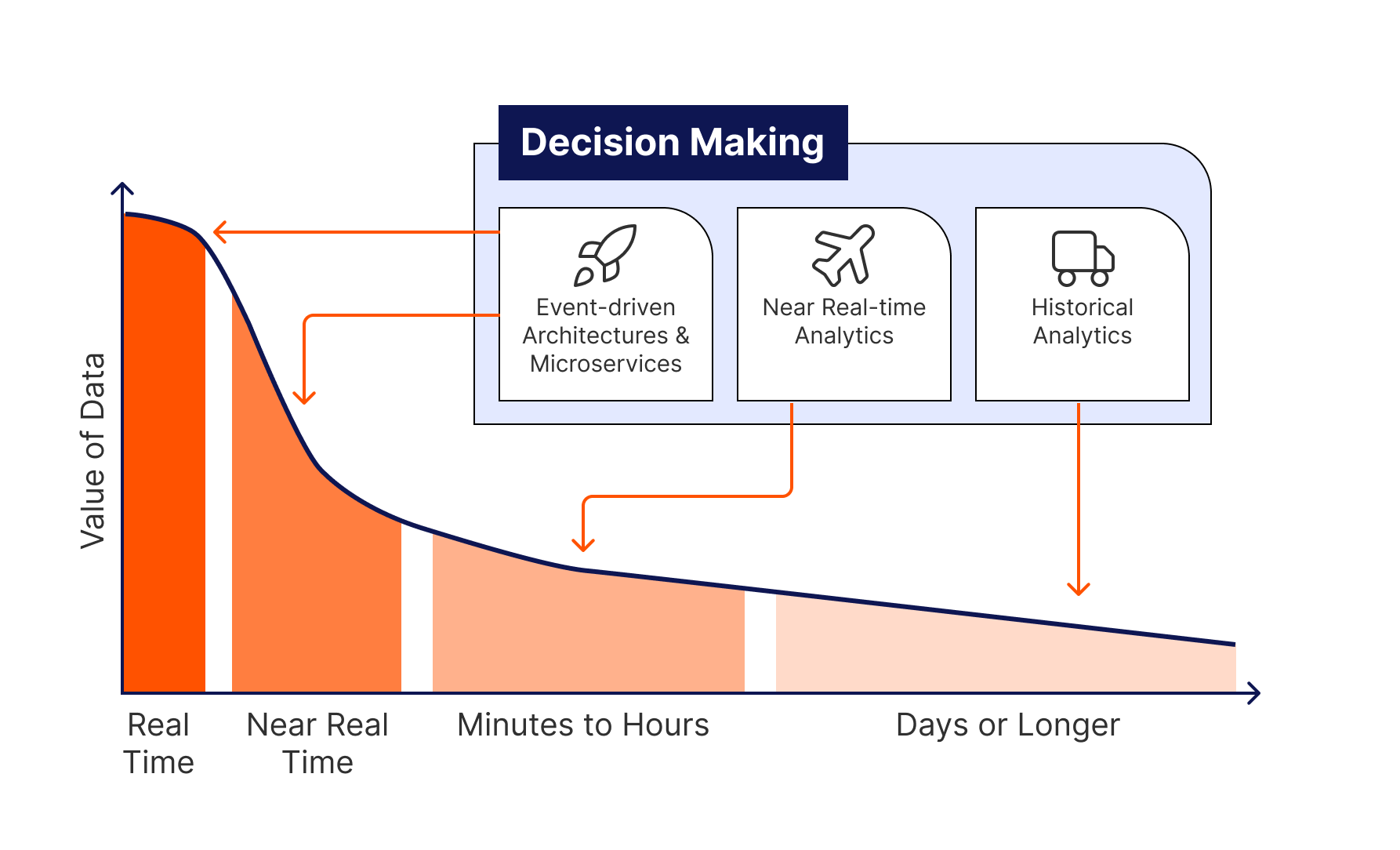
What is data streaming?
Data streaming is a method of continuously processing and transferring data in real time as it is generated. It involves the collection, processing, and analysis of data streams from various sources, such as databases, applications, systems, sensors, devices, websites, social media feeds, or online transactions. Unlike traditional batch workloads, which move data on fixed schedules, say every day or every hour, data streaming moves data immediately as it is created, allowing for real-time insights and actions.
Imagine data as water in a hose, continuously flowing and accessible at any point in time. This is the essence of what is streaming data—a relentless stream of information, constantly moving, as opposed to a static pool waiting for a batch job to start moving the data. It’s the difference between instant text messages on your smart phone vs. paper letters in the snail mail. This real-time flow allows for immediate insights and actions, making it the cornerstone of dynamic business environments where speed and agility are fundamental.
Characteristics: What makes streaming data special
The characteristics of streaming data go beyond mere velocity. Data streams are about volume, variety, and veracity as well. They demand robust handling because of their incessant volume, their varied nature coming from countless sources like sensors, users, and machines, as well as the need for the data to be accurate and timely. The real challenge comes not just in capturing this relentless flow of data but in making sense of it in real time, extracting actionable insights while the stream rushes on.
What is the difference between batch data and streaming data?
Batch data and streaming data represent two fundamentally different approaches to data handling. Batch processing involves collecting and processing data in batches at set intervals, such as daily or hourly. This method is suitable for scenarios where handling and making sense of the data in real time is not critical, and it excels in dealing with large volumes of data, allowing for comprehensive and complex analyses.
Imagine data as people at a party. Batch data is like having all your guests arrive all at once, precisely at 8:00 pm in a big group. They're pre-arranged, organized, and you can plan how to greet and entertain them. In technical terms, batch data is collected over a period of time and then moved all together at pre-configured schedules.
In contrast, streaming data is about handling data continuously and in real-time, as it is generated. This approach is essential for applications that require immediate data analysis and response, such as monitoring live digital interactions or real-time fraud detection. Data streaming is characterized by its ability to provide instant insights and actions, catering to high-velocity and high-volume data scenarios, but it demands more sophisticated and resource-intensive infrastructure.
Now, streaming data is more like having guests pop in unexpectedly, whenever they want to. Each guest demands immediate attention. In the data world, this means information is collected and processed instantly, as soon as it's generated.
| Batch Data | Streaming Data | |
|---|---|---|
| Data Characteristics | Well-suited for moving any volume of data that doesn't require immediate action. The data is collected over a period of time and then moved all at once. | Ideal for scenarios with high-velocity and high-volume data that require immediate movement and processing, like financial transaction monitoring or live social media analytics. |
| Processing | Scheduled Processing: Batch processing handles data in large, discrete chunks at scheduled intervals. This could be hourly, daily, or even weekly, depending on the use case. | Real-Time Processing: Streaming data is processed continuously, in real time, as it is generated. This means there is minimal latency between data creation and data processing. |
| Complexity | Batch processing can efficiently manage complex computations on large datasets, as it doesn't need to deliver immediate results. | Data streaming can sometimes require more resource-intensive operations and complex infrastructure able to handle the constant flow of data and factor in potential spikes in data traffic that might occur. |
| Use Cases | Common in scenarios where real-time data is not critical, like monthly financial reports, daily sales reports, offline analytics, or historical data analysis. | Widely used in applications that rely on timely data insights, such as fraud detection, real-time recommendations, or monitoring systems. |
Why stream data? (Benefits)
Streaming data offers a multitude of benefits that are pivotal in the digital era, where real-time information and rapid decision making are crucial. Here are some of the key advantages:
- Real-Time Insights: Streaming data allows for the analysis and utilization of information as it is generated, enabling immediate response to emerging trends and issues. This real-time capability is essential for sectors like ecommerce, where online vendors analyze shopper actions and return near-real-time web experience personalization and shopping recommendations.
- Enhanced Decision Making: By providing up-to-date information, streaming data empowers organizations to make timely and well-informed decisions. It eliminates the lag inherent in batch processing, ensuring that decisions are based on the most current data available.
- Scalability and Flexibility: Streaming data solutions are inherently scalable, accommodating the ever-increasing volume of data generated by modern digital interactions. This scalability ensures that organizations can handle data from a few sources to millions, maintaining performance and reliability.
- Improved Customer Experience: In customer-centric industries, streaming data enables personalized and timely interactions with customers. This can lead to improved customer satisfaction and loyalty as businesses respond promptly to customer needs and preferences.
- Operational Efficiency: The continuous flow of data helps in optimizing operations, having access to the most up-to-date information, and predicting potential failures before they occur. For instance, in manufacturing, streaming data from sensors can be used for predictive maintenance, preventing costly equipment failures.
In summary, streaming data revolutionizes how organizations handle information, offering real-time insights, enhancing decision-making, providing scalability, improving customer experience, boosting operational efficiency, and being cost-effective.
The magic of data streaming: Use cases that transform businesses
Data streaming use cases span a wide array of industries, for example:
- Finance
- E-commerce
- Healthcare
- Supply chain and logistics
- Online gaming
- Media
- Traffic management
- Customer service
Overall, data streaming has become a crucial technology that empowers businesses to react quickly, stay competitive, and better meet customer needs by leveraging real-time insights.
Data streaming unpacked: How it works and its implementation
Let's take a look at how data streaming works.
1. Data generation
Data generation marks the inception of the data streaming process. Here, diverse sources continuously generate data in real time. Every user interaction on a digital platform, such as website clicks or social media engagements, and readings from various sensors contribute to a constant flow of data. This phase is crucial as it sets the foundation for the subsequent stages of data streaming.
2. Data capture and transmission
The second phase involves capturing and transmitting the generated data to a designated repository. This stage employs sophisticated tools and technologies, similar to a network of pipelines, ensuring the efficient and lossless transfer of large volumes of data. The objective is to deliver the data reliably and securely.
3. Data processing
In some scenarios, companies would also connect data streaming with a real-time data processing system (stream processing) for the continuous processing data in real time. This processing can be categorized into two primary forms:
- Real-Time Data Processing: Involves immediate and near-instantaneous processing of data, minimizing latency to milliseconds or microseconds for time-critical applications.
- Near Real-Time Data Processing: Introduces a slight delay, typically in the order of seconds to minutes, providing timely insights without the strict immediacy of real-time processing.
4. Data storage
In some scenarios, storing data for future use becomes necessary. The data is initially stored in Apache Kafka(R) and made immediately available to any system or application to consume the fresh data. Typically, Kafka has been used as a temporary storehouse for streaming data. Data is often moved out quickly to databases, data lakes, data warehouses, or cloud object storage like Amazon S3, Google Cloud Storage or Azure Blog Storage, where it can be accessed, reprocessed, and retained as historical data.
By moving data out of Kafka, users can reduce their Kafka costs substantially, as high-speed local disks are much more expensive than low-cost object storage. However, new technologies like Tiered Storage can move data from local disks to object storage within Kafka itself, lowering costs while maintaining a longer history of data in Kafka.
5. Data analysis and action
The final stage is where the true value of data streaming is realized. Businesses and organizations analyze the processed data to derive actionable insights and make informed decisions.
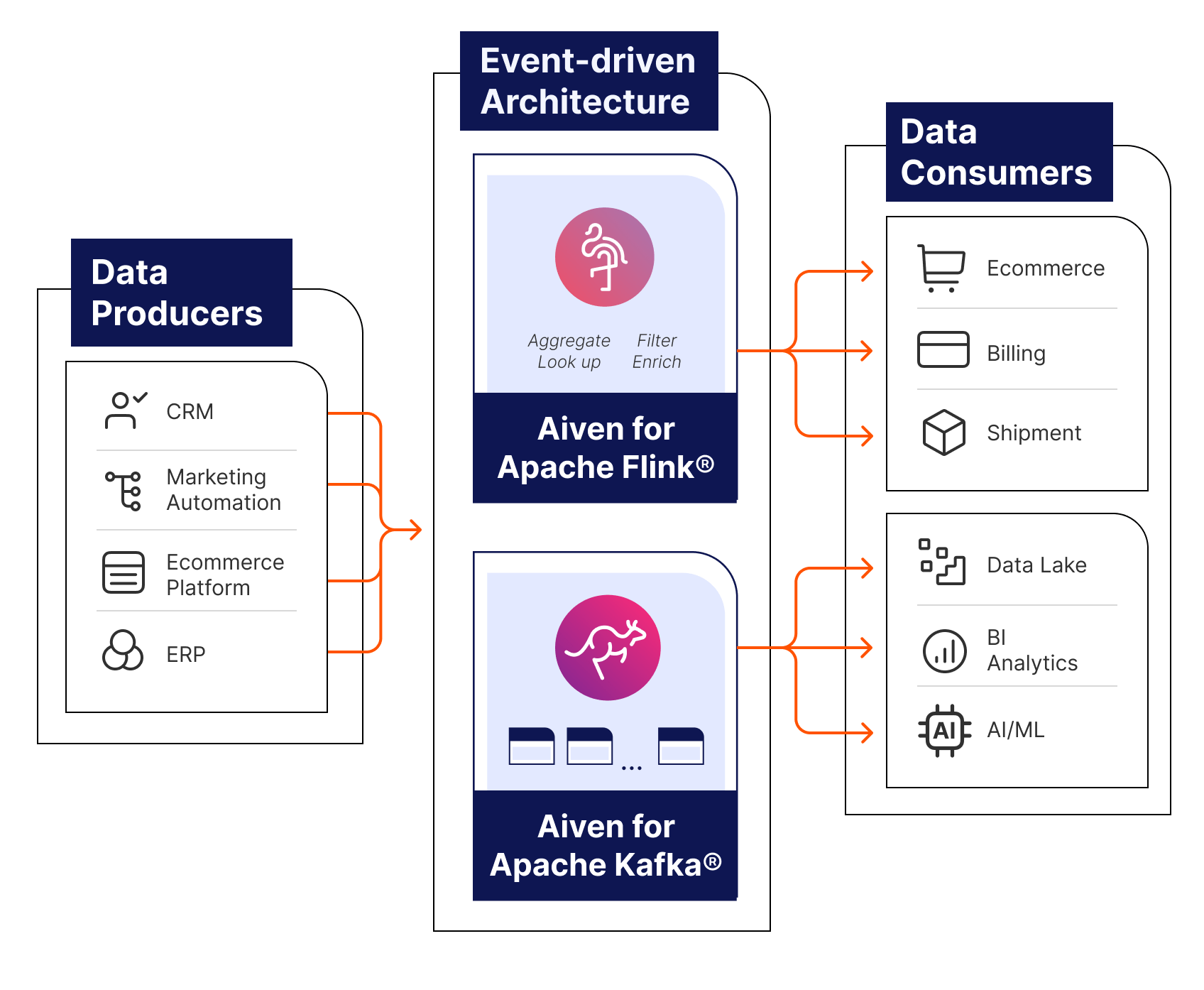
Data producers (e.g. Databases, CRM or Ecommerce platforms) generate raw data that is processed by Apache Kafka and Apache Flink. These tools then deliver real-time data to consumers such as microservices, analytics tools, and applications, ensuring they have access to the freshest information.
Overcoming challenges and distinctions in data streaming
While data streaming offers numerous benefits, it also presents several obstacles that organizations must address.
- Managing the high volume, velocity, and timing of incoming data.
- Ensuring the quality and consistency of streaming data.
- Minimizing latency in data processing and delivery.
- Integrating streaming data with existing systems and data stores.
- Streaming data often involves sensitive information, making security and privacy a major concern.
- Data streaming can be resource-intensive and expensive, especially when scaling up.
- Analyzing and responding to complex patterns in real-time data streams.
- Ensuring continuous operation and data integrity in the face of system failures or anomalies.
- Extracting meaningful insights and making decisions in real-time.
- Adhering to regulatory requirements and ensuring proper data governance in real-time environments.
Each of these data streaming challenges requires a specific strategy, whether it's deploying sophisticated monitoring tools or utilizing a robust platform.
Architecting the future: Data streaming with Apache Kafka
Apache Kafka is an open-source distributed data streaming platform and community project under the Apache Software Foundation, written in Scala and Java. It is designed to provide a unified, high-throughput, low-latency platform for handling real-time data feeds. Its robustness and scalability make it an ideal choice for large-scale data streaming tasks.
Kafka operates on the principle of a distributed commit log. It allows for the publication (writing) and subscription (reading) of streams of records, including continuous import/export of your data. One of Kafka's strengths is its durability and fault tolerance, achieved through replicating data across a cluster of servers. This ensures that data is not lost and is accessible even in the event of single server failure.
The Kafka architecture is such that it can handle multiple, decoupled data producers and consumers, enabling a high degree of concurrency and parallelism. This makes it particularly well suited for applications requiring real-time analytics and monitoring, event sourcing, log aggregation, and event-driven architecture.
Data streaming architecture, exemplified by tools like Apache Kafka, is pivotal in managing the relentless flow of data in today's fast-paced digital environments. Kafka's efficient processing capabilities, fault tolerance, and scalability make it a cornerstone in the field of real-time data streaming and processing.
Read more: Data streaming made easy with Apache Kafka
The road ahead: Emerging trends in data streaming
The future of data streaming is as exciting as it is boundless. Here are some emerging trends to watch:
- Artificial Intelligence and Machine Learning Integration: The integration of AI and ML with data streaming technologies is revolutionizing how data is analyzed and utilized in real-time. AI and ML algorithms can process and analyze streaming data to predict trends, detect anomalies, and automate decision-making processes. This integration is particularly impactful in areas like predictive maintenance, real-time personalization in marketing, and advanced fraud detection, where immediate data analysis and response are crucial. For more information on how streaming is used in real-time AI recommendation engines, visit the Aiven for Streaming solutions web page.
- The 5G Revolution: The rollout of 5G technology is significantly enhancing data streaming capabilities due to its higher speed and lower latency compared to previous generations of mobile networks. This advancement is enabling more efficient and faster data transmission, which is crucial for applications requiring real-time data processing, such as autonomous vehicles, augmented reality, and enhanced mobile streaming experiences.
- IoT Advancements: The Internet of Things (IoT) is rapidly expanding, and with it, the volume of data generated by connected devices. This surge in data is driving advancements in data streaming technologies to efficiently handle, process, and analyze data from myriad IoT devices. These advancements are pivotal in sectors like smart cities, where real-time data from sensors and devices are used for traffic management, environmental monitoring, and public safety.
- Edge Computing: Edge computing involves processing data near the source of data generation rather than in a centralized cloud-based system. This trend is becoming increasingly relevant in data streaming, as it allows for quicker data processing and response times, which are vital for time-sensitive applications. Edge computing is particularly useful in scenarios where sending data to the cloud would be too slow or costly, such as in manufacturing processes or remote monitoring systems.
- Hybrid and Multi-Cloud Streaming Architectures: Organizations are increasingly adopting hybrid and multi-cloud environments for their data streaming architectures. This approach allows businesses to leverage the strengths of different cloud providers and on-premises solutions, enhancing flexibility, scalability, and redundancy. Hybrid and multi-cloud strategies ensure that data streaming processes are more resilient and adaptable to varying workloads and requirements.
These trends indicate a future where data streaming becomes more integrated with advanced technologies, faster and more reliable through improved connectivity, and more versatile and robust due to emerging architectural paradigms. As these trends continue to develop, they are set to unlock new possibilities and efficiencies in how we process and utilize real-time data.
Elevating your data streaming strategy with Aiven
When it comes to actualizing your data streaming needs, Aiven emerges as a formidable ally. Offering services that simplify and enhance the data streaming process, it’s like the wizard in the world of data, making complex processes seem almost magical. With offerings like fully-managed Apache Kafka and managed Apache Flink, Aiven removes the complexities of data streaming, allowing businesses to focus on deriving value from their real-time data.
Aiven's platforms are designed to seamlessly fit into your business, enabling:
- Real-time analytics – Immediate insights to inform business decisions.
- Event-driven architecture – Responsive systems that act on data in real-time.
- Change Data Capture (CDC) – Streaming data changes into Kafka as they happen.
- AI-driven recommendation engines – Streaming capabilities capture user behavior in real time, validate any request or AI prompt in a Trust Layer, combine real-time and historical data, and generate a response that also goes through the Trust Layer to validate responses.
- Data compliance – Adherence to global data protection regulations.
- Security measures – State-of-the-art encryption and security protocols to safeguard data streams.
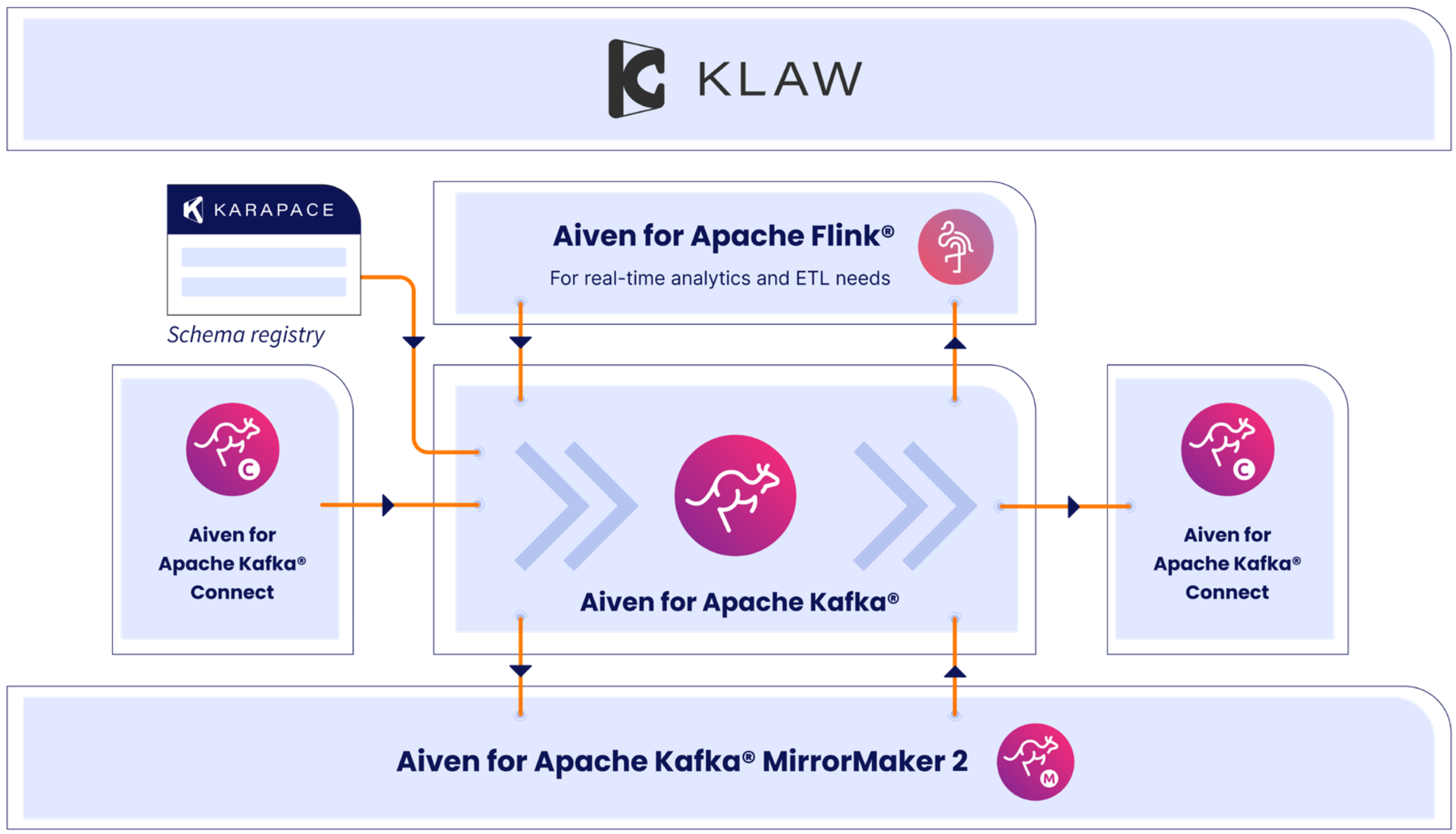
However, it takes a complete open-source streaming ecosystem build around Apache Kafka to really take your data game to the next level.
- Aiven for Apache Kafka – For building real-time data pipelines and event-driven architectures with ease.
- Aiven for Apache Kafka Connect – For simplifying data integration by moving data in and out of Kafka clusters.
- Aiven for Apache Kafka MirrorMaker 2 – For managing cross-cluster Kafka data replication, keeping topics in sync across different regions, clouds.
- Aiven for Apache Flink – For building and deploying powerful, real-time, stateful stream processing applications.
- Karapace – For providing essential schema management capabilities for your Apache Kafka clusters, ensuring data compatibility and governance.
- Klaw – For streamlining Apache Kafka governance.
See some of the top use cases on the Aiven for Streaming solutions web page.
Ready to dive into data streaming with Aiven? Here’s how to get started:
- Learn more: Have a poke around Aiven's developer documentation to take your first steps in the Kafka or Flink world, or sign up for a free trial and start playing around.
- Consultation: Contact our experts to identify your needs or book a demo
Further Reading
- Why you should think about moving analytics from batch to real-time (Blog article)
- [Move from batch to streaming with Apache Kafka® and Apache Flink® (https://aiven.io/blog/build-a-streaming-sql-pipeline-with-flink-and-kafka)
- Build a real-time analytics pipeline in less time than your morning bus ride (Blog article)
Table of contents
- TL;DR — If you’re in a hurry
- What is data streaming?
- Characteristics: What makes streaming data special
- What is the difference between batch data and streaming data?
- Why stream data? (Benefits)
- The magic of data streaming: Use cases that transform businesses
- Data streaming unpacked: How it works and its implementation
- 1. Data generation
- 2. Data capture and transmission
- 3. Data processing
- 4. Data storage
- 5. Data analysis and action
- Overcoming challenges and distinctions in data streaming
- Architecting the future: Data streaming with Apache Kafka
- The road ahead: Emerging trends in data streaming
- Elevating your data streaming strategy with Aiven
- Further Reading