


Kafka is too expensive and complex for 80% of users. Most Kafka usage is small-data - ~60% of clusters are sub-1 MB/s, yet teams pay big-data prices. Diskless (KIP-1150), Tiered, and Iceberg topics give Apache Kafka multiple storage classes, but they’re advanced storage primitives. They are powerful in the hands of seasoned platform teams but too complex for beginners. Aiven Inkless productizes these primitives and makes them usable at virtually any scale and price point to turn the 80% problem into a 0% problem - so anyone who needs streaming has the right setup.
With Inkless Clusters, users can dial latency, durability, availability and TCO in a single, cloud-native, elastic Apache Kafka API that has:
- Classic 3-zone: <20 ms E2E latency with 99.99% SLA
- Classic 3-node (Single-AZ): <20ms E2E latency with 99.9% SLA, ~3× cheaper
- Diskless Standard: <2s E2E latency with 99.99% SLA with up to 90% savings
- (soon) Diskless Express: <1s E2E latency and 99.99% SLA with balanced savings
- (soon) Diskless Global: Replication for any diskless topic, 99.999% SLA
- (soon) Lakehouse: zero-copy or dual-copy analytics - tables from any topic type

Aiven Inkless is the first multi-modal cloud streaming service for Apache Kafka with built-in KRaft, Diskless Topics (KIP-1150), and Tiered Storage: 100% open-source, fully auto-balancing, and self-healing. And since Inkless is Apache Kafka (as it's a fork of the Apache Kafka project and 100% compatible with the Kafka API) it works with Aiven’s Open Source managed ecosystem of connectors, Mirror Maker and schema registry. This month OpsHelm cut streaming costs by ~5× (from >$50k/yr to <$10k/yr) by consolidating MSK+NATS into a single Inkless BYOC cluster.
Today our Inkless repo (implementing KIP-1150) and Inkless BYOC are generally Available. Inkless SaaS is coming soon.
Workload optimization is the future of Kafka. I’ll explain why below but if you’d rather see it than read about it, try Inkless BYOC.
Kafka's 80% Problem
Ask an engineer if they’re bullish on Kafka and you’ll hear a qualified yes. Adoption is broad, with thousands of companies, including 80%+ of the Fortune 100 and momentum remains strong.
If you’re not bullish enough on Kafka, let’s take a look at the last twelve months:
- Kafka 4.0 is shipping with Kraft as the default
- Tiered Storage makes infinite retention practical
- Queues for Kafka (KIP-932) entered early access
- Diskless Topics (KIP-1150) is outsourcing replication to object storage
The community has been pushing the ceiling higher (more use cases, simpler ops) and lowering the cost floor - a rare double in Open Source data infrastructure. That’s why the newest companies are all-in on Apache Kafka. A week ago OpenAI detailed a multi-cluster Kafka platform running at 80+ GB/s with ~80× YoY growth in traffic. The hottest AI-scale logos aren’t adopting a new streaming engine, they’re just choosing Kafka. And I couldn’t be more proud that at Aiven, we are helping solidify this accelerating trajectory.

Kafka was originally built exactly for this type of scale - to solve the hard problem of data integration. It was born at LinkedIn to replace a mess of point-to-point streams with a simpler shared commit log. Like many other big-data systems Kafka is distributed by default: replicated for fault tolerance and partitioned for horizontal scale, and O(1) access patterns so performance isn’t impacted even at terabyte scale. By contrast, OLTP databases (e.g., PostgreSQL) typically degrade as loads increase. Kafka is an engineering marvel that unlocked big data at unprecedented scale - its log-centric design is a 15+ year old idea that now powers many of the world’s largest systems.
Kafka is also intentionally unopinionated and flexible by design. It was built for dedicated experts inside digital-native giants with deep operational muscle and strong platform teams who can make hard trade-offs. For such SMEs, 300+ knobs are a feature, not a bug. But that’s not most teams. For the other 80% flexibility reads as ambiguity.
At Aiven we run 4000+ Kafka clusters for 1000+ companies and we know that most users want sane defaults and reasonable guardrails that get the job done. Many of their workloads don’t even need a full distributed system for kilobytes-per-second streams with seconds-to-minutes SLOs. They are perfectly fine in a single AZ with Tiered Storage for object-store durability. Asking those users to pay the unnecessary quorum/replication tax is how open-source Kafka got its name as an expensive and cumbersome system to manage. So I wanted to look closer at this problem. Is it Kafka’s fault that it was only built for a huge scale or just the usage didn’t fit the system design?
What if the "big data" revolution was a myth for most teams?
What if 80% of Kafka clusters are small data?
Glossy vendor surveys by Confluent and Redpanda tell us that’s exactly the case: about 56% of all clusters run at or below ~1 MB/s.
More than half of the Kafka clusters surveyed were at <1MB/s!
Confluent’s 2025 survey also shows that only ~9% report enterprise-wide streaming. Meaning ~91% are still anywhere between experimenting or running a few production siloed systems.
I know you may be skeptical of industry surveys: Aiven’s fleet data confirms a similar pattern: median ingest across 4k services is ~9.81 MB/s, with ~20% of clusters driving >80% of total throughput.
Kafka thrives inside elite engineering orgs because they have big data problems and add missing pieces like proxies, balancers, guardrails, dashboards, and on-call muscle. Outside those walls, flexibility turns into chaos. Heavy “defaults” calcify into expensive dogma - you must have 3 AZs, RF=3, add lots of partitions. Schemas stay second-class. Rebalancing, placement, metrics, and alerting get pushed to a sprawl of third-party tools and tribal scripts. The outcome is painfully familiar: a Frankenstack of sidecars, controllers, dashboards, and bespoke configs that costs real money even at ~1 MB/s. Organisations inherited the reality of running Kafka without the playbook or the expertise.
But let's make the 80% problem concrete. 1 MB/s is 86 GB/day. With 2.5KB events, that's ~390 msg/s. A typical e-commerce flow - say 5 orders/sec - is 12.5 KB/s. With 1KB events, it's ~1,000 msgs/sec; with 5 KB events, ~200 msgs/sec. To reach 1 MB/s you’d need ~80x more growth. Most businesses aren’t big-data, and that’s okay.
Then why not just run a one-broker Kafka (or even PostgreSQL) if throughput is small? Because a single node can’t offer durability or availability. If the disk dies, you lose data; if the node dies, you lose the availability. Distributed systems add replication to survive failures. They also need a consensus quorum to decide who’s alive (historically ZooKeeper; now the controller quorum). Those are the right mechanisms - but they create a minimum ticket price and complexity even at sub-MB/s scale. And that's exactly Kafka’s Achilles heel - its high entry threshold. At a few MB/s (≈300-400 GB/day), most teams face a tough choice: self-manage a three-AZ, RF=3 posture that rounds to at least $300,000/yr once infra + people are counted, or buy managed service that is priced around $50,000/yr while persisting the same data in plain S3 can be easily done <$5k/yr - streaming data is “premium data” to say the least.
And yet, most of the industry keeps working at the top of the funnel—faster brokers, shinier features, more connectors, bigger benchmarks. Important work…no doubt, but it doesn’t change the small-cluster reality: ~1 MB/s deployments still hit the same high economic floor. Users get nicer features, not cheaper or easier Kafka. After 15+ years getting production-ready Kafka costs relatively the same and still means five to six-figure annual spend once infra + people even at a tiny scale.
Our challenge is to keep Apache Kafka boringly reliable from the lowest scale, lowering the minimum entry costs, while steering it back to its roots: a single, commit log everything plugs into. Make the central log cheap to start and safe to scale.
This is where Aiven comes in, we are solving Kafka’s 80% problem.
OK, but Aiven is a vendor, you want expensive Kafka, right?
Wrong. If we solve for the 80%, the pie gets bigger. When small-data streaming is cheap to start and safe to scale, more teams adopt it; more workloads cross the chasm from project to platform; and yes - more of them choose managed Kafka later.
Here’s the blunt truth: for 80% of use cases, Kafka is currently overkill. You pay big-data taxes for small-data streams. Why deploy 3AZs, RF=3 to move kilobytes per second? In what world do you need 3 brokers + 3 controllers + Schema Registry (a 6-7 node starter) just to push kilobytes? Why sign up for ~$300k/year all-in when it barely moves the needle?
This isn’t a knock on Kafka’s design, it’s a knock on the deployment model we’ve normalized. Over the years we got boxed-in on certain “truths” such as 3AZs, replication, partitioning, second class schemas which were optimisations for scale. As we discussed Kafka was made for big data durability and throughput. While almost no one invests in small-data Kafka economics.
Let's zoom out to see how the market looks today - roughly 80% are small-data clusters by default and shouldn’t have to deploy big-data machinery to get value. Another ~15% are savvy self-managers (Datadog, Uber scale) for whom Kafka is product-critical - they run it in-house to avoid locking their core into a vendor, using managed services only for leverage. The final ~5% are true big-data buyers, this 5% is a knife-fight crowded with hyperscalers, the original creators (Confluent), and hungry newcomer startups. At Aiven, our long-term goal is to elbow into the 15%. But our immediate goal is more ambitious: turn the 80% into 50% by lowering the entry barrier, making Kafka simpler and flattening the cost curve so small and medium data streams actually work out.
Turning the 80% problem into a <50% problem
We’ve established the uncomfortable truth: most companies don’t need Kafka-of-the-past. The cloud reordered the stack: extreme durability is outsourced to object storage (up to 10x cheaper!) and coordination lives in managed Kubernetes for pennies. We think that Kafka doesn’t need to be “premium”, it needs to be everywhere. And for that it needs to be made easier and cheaper. The move isn’t “add more features” but rather put the options in a single cluster with sane defaults, built on open source primitives. Allow each stream to pick its trade-off for cost, latency, throughput, and durability. That’s the spirit of KIP-1150 (Diskless Topics): do less on the hot path, lean on the battle-tested object store for durability, keep the same Kafka API.
Excited? Let’s see what topics we can do on a single Inkless cluster:
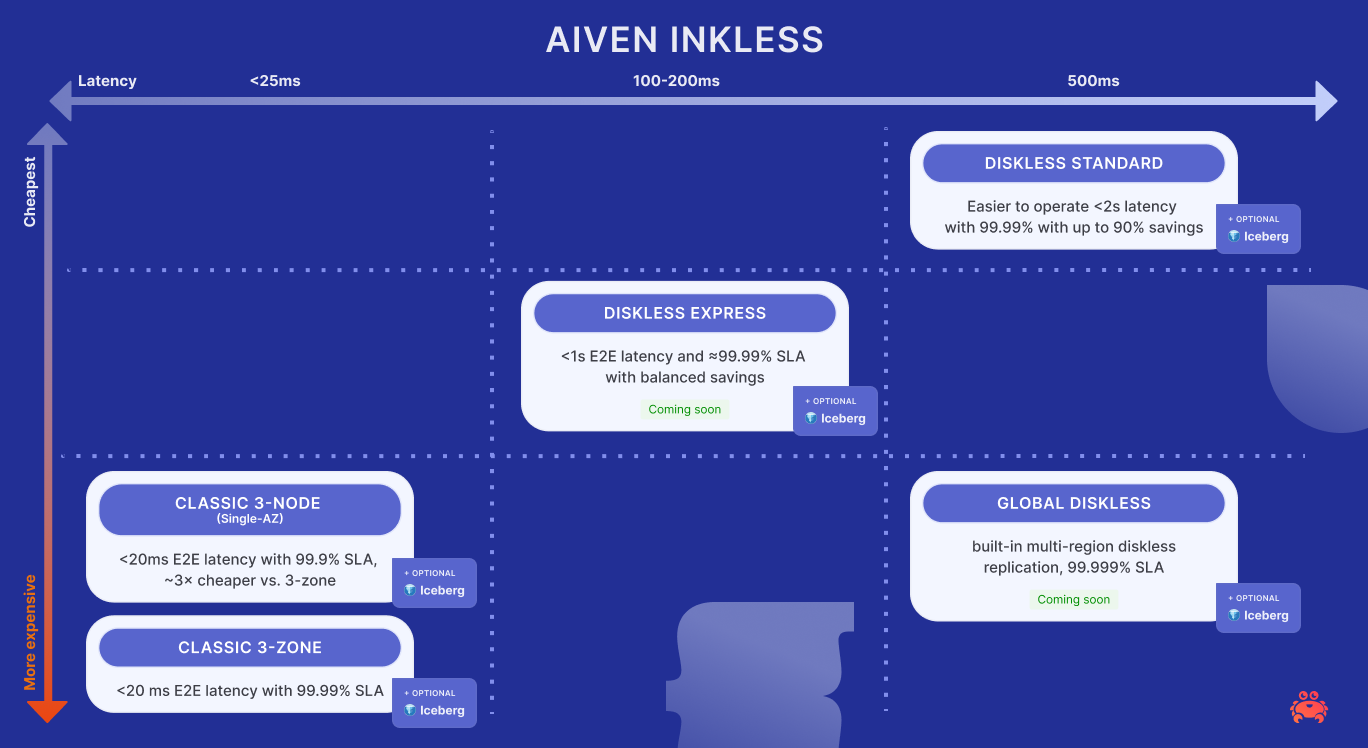
- Replicated, 3-AZ for low latency and enterprise-grade reliability ≈99.99%
- Replicated, single-AZ (3-node): ≈99.9% SLA; pragmatic default when a rare zonal blip is acceptable - the last big AWS issue was US-EAST-2 in 2022
- Diskless Standard with ≈99.99% SLA and maximum savings when seconds of E2E latency are fine (≈1.5–2s)
- (soon) Diskless Express: object-store durability with sub-second E2E latency and ≈99.99% SLA
- (soon) Global Diskless: built-in multi-region diskless replication, 99.999% SLA.
- (soon) Lakehouse via tiered storage - open-table analytics on the very same streams, with zero-copy or dual-copy depending on economics/latency.
With per-topic choice, the overprovisioning starts to fade. A stream at 100 KB/s no longer needs a three-AZ flight deck, and a team at 100 MB/s still has room to run, with both on the same Kafka. The goal is simple: make the central log cheap to start and safe to grow.
🤚 Reality check: we don’t yet solve for the tiniest single-node footprints. If you truly don’t need coordination or HA, Inkless isn’t there (yet). We’re cooking a path for that tier as well, when it’s ready, it’ll get its own post.
Launching Inkless
We practice what we preach. We’re announcing Inkless Cloud - a platform that offers multiple storage classes on a single, elastic, open-source Kafka cluster. The vision for Inkless Cloud is simple - sign up, choose BYOC or SaaS, use the Kafka API, pay for what you use, Aiven does the rest.
The reasoning is to offer the right entry point for tiny workloads without big-data taxes with unconstrained scalability to tens of GB/s when you need it. Users are to have an extremely trivial way to dial latency, durability, and cost per topic inside the same service. Small data will stop feeling like overkill for Kafka, big data gets a flat cost curve.
Today Inkless in self-service BYOC is generally available. Inkless SaaS is coming soon. So if you don't want to run Apache Kafka yourself, give Inkless BYOC a try.
Further reading
- Not sure which tool fits your stack? Compare streaming technologies: Kafka vs. Nats
